 2023, Vol. 34
2023, Vol. 34



2. 南宁师范大学 计算机与信息工程学院, 广西 南宁 530100;
3. 湖南科技大学 计算机科学与工程学院, 湖南 湘潭 411202
2. College of Computer and Information Engineering, Nanning Normal University, Nanning 530100, China;
3. School of Computer Science and Engineering, Hunan University of Science and Technology, Xiangtan 411201, China
科学计算与工程实践中, 存在大量需要同时优化多个目标的问题, 即多目标优化问题(multi-objective optimization problem, MOP). MOP各目标之间通常是相互冲突的, 即改善其中一个目标, 会引起其他一个或多个目标性能恶化. 因此, MOP一般并不存在唯一的最优解, 使各目标同时得以最优化, 其求解的结果往往是一组折中解, 即Pareto解集或非劣解集[1]. 由于MOP模型高度复杂, 使得一般的数学解析方法难以有效求解, 研究者通常利用计算机算法来获得其Pareto解集的一个逼近. 基于群体搜索的进化算法(evolutionary algorithm, EA)在优化/搜索过程中不要求待解问题满足连续、可微等数学性质, 而且它运行一次可获得一组近似解, 这些特点使得EA算法在求解各类MOP中获得了长足发展, 并涌现出大量经典的多目标进化算法(multi-objective evolutionary algorithm, MOEA). 根据这些算法的主要特点, 可将它们粗略地分成基于Pareto占优、基于性能指标和基于分解等几种主要的类型[2]. 不仅如此, 这些算法在求解目标数较少的MOP (比如含有2−3个目标)时表现出良好的性能, 并获得了令人鼓舞的结果.
近年来, 现实应用中不断出现要求同时优化更多目标的问题, 如车联网中车载控制网络所面临的入侵检测问题[3]和救灾物资的选择与分配问题[4]等. 这些问题的目标数通常超过3, 多目标优化领域的研究者一般将目标数大于等于4的MOP称为高维多目标优化问题(many-objective optimization problem, MaOP). 作为一类重要的MOP, MaOP对传统的基于Pareto占优的MOEA提出了严峻挑战[5], 究其原因: 首先, 有限规模的种群中, 非支配解的占比随目标数呈指数级增长, 这样就严重削弱了利用Pareto支配进行选择的压力, 导致算法最终退化成完全随机算法; 其次, 高维目标种群中极易产生支配抵触解(dominance resistance solutions, DRS), 而DRS是一些远离Pareto前沿的非支配解, 它们会显著地恶化算法收敛性能; 其三, 当Pareto占优无法区分解个体优劣时, 一些MOEA会利用辅助的基于密度的方法择优个体, 亦即采用ADP (active density promotion)机制进行环境选择. 因此, 在DRS和ADP的共同作用下, 这些算法获得的近似解集将难以收敛到待解问题真实的Pareto前沿上.
鉴于传统的Pareto占优是一种颇为严格的支配关系, 其在高维目标空间中可扩展性差, 为了有效求解MaOP, 研究者从不同角度研究如何利用进化算法求解MaOP问题. 例如, Gong等人[6]利用元-目标(meta- objective, MeO)方法求解高维多目优化问题. MeO分开度量解个体的收敛性和多样性, 它为基于Pareto支配的MOEA求解MaOP提供了一般性的方法. 还有一些研究者从改进支配关系的角度出发, 提出若干改进的支配方法, 以改善MOEA求解MaOP的性能. 根据已有改进支配关系的主要思想, 可将它们大致划分为如下几类.
(1) 修改个体目标函数值: 这类方法通过改变个体的目标函数值来扩大个体的支配区域, 从而达到修改Pareto支配关系之目的. Yang等人[7]提出了grid支配关系, 该支配关系根据个体的目标值, 自适应地确定网格的坐标点, 然后利用网格坐标而非目标值来确定支配关系. 但grid支配以个体为中心的网格计算方式无法保证种群收敛, 而且基于grid支配的算法性能往往对目标空间划分参数div较敏感, 需要反复实验确定合适的div值. 必须指出: 修改目标值的方法虽然能扩大解个体支配区域和降低种群中非支配解的比例, 但这类方法一般需要设置参数, 而且算法性能对参数敏感; 其次, 修改个体目标值实际上改变了个体在目标空间中的位置, 影响了支配关系判别的准确性, 容易导致种群无法收敛到真实Pareto前沿.
(2) 目标计数方法: 这类方法在确定个体占优关系时, 考虑个体的目标值优于、劣于或等于对方的目标数. Zou等人[8]提出一种L-支配关系, 该支配关系考虑两个解分别优于对方的目标数之差以及它们在目标空间与原点的距离. 当个体x优于y的目标数比y优于x的目标数多, 且x与原点的距离比y与原点的距离更近, 则认为x L-支配y. L-支配不仅考虑了目标优劣的相对计数, 而且考虑了个体与理想点之间的距离, 进一步强化了收敛性, 但L-支配没有考虑解群的分布性. 总体上, 目标计数的方法仅考虑个体的目标数目而非目标值, 因而无需执行规范化操作, 这样不仅降低了算法的复杂性, 还能简化算法设计. 但必须指出: 在这类方法中, 有一些支配关系并不满足传递性, 在其个体支配关系图中可能存在环结构, 从而影响了支配关系的有效性.
(3) 改进Pareto最优性的方法: 这类方法的主要思想是对传统的Pareto支配关系松弛化, 以扩大个体支配区域. 在这类方法中, GPO (generalized Pareto optimality)最优性[9]是其中的典型范例之一. GPO是传统Pareto最优性的一般形式, 它的基本思想是: 随着MaOP问题目标数的增加, 逐渐扩大解个体的支配区域, 使它能在较大范围的目标维度上获得一致水平的支配关系区分能力. GPO利用参数ϕ控制个体在各个目标方向上扩大支配区域的程度, 以改善算法的收敛性, 但它在多样性保持方面仍有待提高.
(4) 利用角度的方法: 近年来, 在多目标进化优化中, 利用角度信息实施环境选择已屡见不鲜. 例如: Gong等人[10]利用目标向量之间夹角的余弦定义余弦相似度, 并基于余弦相似度定义种群个体的分布性. 但这种基于目标向量之间的角度来定义分布性的方法关注的是种群的分布性而非收敛性. Li等人[11]利用角度来确定两个解之间的支配关系, 即: 如果两个体间的夹角大于给定的阈值, 那么它们视为彼此非支配的. Jiang等人[12]在进化种群的搜索方向上, 利用解个体的角度和权重信息判断它们的相似性, 即个体间的角度越大, 相似性越低. 文献[13]利用最大向量角度优先的原则保持解群分布的宽广性和均匀性, 并通过有条件地剔除较差解来增强种群的收敛性. 最近, 文献[14]提出一种基于角度的支配关系, 即AD支配关系. 该支配利用参数k控制解个体支配区域, 且k值越小, 个体的支配区域越大. 需要指出: 利用角度的方法较适于维持高维目标解群的分布性, 且对一些具有不规则Pareto前沿的问题亦有效, 但基于角度的方法强调多样性而非收敛性. Xie等人[15]提出一种动态角度向量支配关系, 以动态地刻画进化种群在高维目标空间的分布状况, 实验表明了该支配方法具有明显的优势.
(5) 利用小生境的方法: 这类方法通过在目标空间定义适当形式的小生境, 并在小生境内强调个体的收敛性, 而其中, 小生境的大小一般通过权重向量、参考点集或自适应等方式确定. Tian等人[16]提出一种增强的支配关系SDR (strengthened dominance relation), SDR采用基于目标向量角度的小生境技术来判断解个体之间的支配关系, 并自适应地确定小生境大小(即
综上, 已有的支配方法尚存不足. 首先, 一些支配方法强调收敛性而多样性不足; 一些支配方法偏重多样性而收敛性较差. 然而, 在高维多目标进化优化中, 如何有效地平衡种群的收敛性和多样性至关重要, 能够显著地影响算法性能. 其次, 已有的支配方法大多需要设置参数, 而且算法性能通常对参数敏感. 针对不同的待解问题和应用场景, 使用者需要反复实验以寻找合适的参数.
基于惩罚的边界相交方法(penalty-based boundary intersection, PBI)[19]可以利用其d1距离表征解个体的收敛性, 运用其d2距离表征解个体的多样性, 而高效的高维多目标进化算法一般能较好地平衡收敛性和多样性.有鉴于此, 通过恰当地运用PBI函数的d1和d2距离构造满足高维多目标进化算法要求的支配关系及其多样性保持方法, 具有合理性和创新性.
具体地, 首先提出一种结合双距离的支配关系CDD (dominance relation combing double distances). CDD-支配关系利用PBI函数的d1, d2距离构造, 并采用惩罚参数1/m (m表示MaOP目标数)自适应地平衡高维目标解群的收敛性和多样性. 由于参数1/m仅取决于MaOP的目标数目, 其并未引入额外参数. 不仅如此, 还利用PBI函数的d1, d2距离构造一种多样性保持方法DM-DD (diversity maintenance based on double distances), 并将其应用于高维多目标进化算法环境选择. 在上述基础上, 将CDD-支配和DM-DD方法嵌入到NSGA-II算法[20]框架, 以分别替代原始算法的Pareto支配和拥挤距离度量, 构造一种基于双距离的高维多目标进化算法MaOEA/d2 (many-objective evolutionary algorithm based on double distances). 新算法与5种高效的高维多目标进化算法一同在DTLZ[21]和WFG[22]系列测试问题上测试其IGD (inverted generational distance)[23]和HV (hypervolume)[24]指标性能. 结果表明, MaOEA/d2算法具有显著较优的收敛性与多样性.
本文的第1节是预备知识. 第2节描述CDD-支配关系及其性质. 第3节介绍DM-DD方法. 第4节是MaOEA/d2流程及时间复杂性分析. 第5节是本文的实验部分. 最后是结论.
1 预备知识以最小化MOP问题规范化目标空间为例, 利用PBI方法求解MOP需要提供一组均匀分布的权值向量λ1, λ2, …, λN (N为权值向量的数目), 它们从原点出发, 沿着各自的方向延伸, 并与可达目标空间(attainable objective set)的最左下边界相交. 如此产生的一组相交点可视为对Pareto前沿(Pareto front, PF)的逼近, 如图 1所示.

|
图 1 基于惩罚的边界相交法示意图 |
通常, 如果权值向量的数目设置较大且合理, 那么PBI方法能够产生一组分布可能不均匀但能很好逼近真实PF的目标解向量. 具体地, PBI方法采用式(1)的方式计算:
| $ \left\{ {\begin{array}{*{20}{l}} {\min {\text{ }}{g^{pbi}}(x|\lambda , {z^*}) = {d_1} + \theta {d_2}} \\ {{\text{s}}{\text{.t}}{\text{. }}x \in \mathit{\Omega} } \end{array}} \right. $ | (1) |
其中, θ > 0是预设的惩罚参数, λ和z*分别为权值向量和参考点. 对于最小化MOP规范目标空间而言, z*一般为原点, 而d1和d2则采用下面的方式计算:
| $ \left\{ {\begin{array}{*{20}{l}} {{d_1} = ||F{{(x)}^T}\lambda ||/||\lambda ||} \\ {{d_2} = \left\| {F(x) - {d_1}\left( {\frac{\lambda }{{||\lambda ||}}} \right)} \right\|} \end{array}} \right. $ | (2) |
图 1以2-目标的最小化MOP为例来解释PBI函数的原理, 其中, F(x)=(f1(x), f2(x))为可达目标空间内任意一点. λ=(λ1, λ2)为从原点出发、方向为λ的权值向量. 可达目标空间的最左下方的粗线表示MOP规范的PF. 点y为F(x)在权值向量λ上的投影, d1表示点y与原点之间的距离, d2表示F(x)与权值向量λ之间的距离.
从图 1可知: 较小的d1表示解个体距离PF更近, 意味着个体的收敛性越好; 较小的d2表示解个体越靠近权值向量, 意味着目标解点的分布性越好, 而当d2=0时, 则表示目标解位于权值向量的方向上. 如果θ参数设置得合适, 则PBI方法可以获得较好的收敛性与多样性; 而太大或太小的θ值通常会恶化PBI方法的性能[17].因此, 设置合适的θ值对PBI方法的性能十分重要.
2 结合双距离的支配关系 2.1 CDD-支配关系由于已有改进的支配关系在平衡收敛性和多样性方面尚存不足, 而且它们一般需要设置合适的参数以获得较好性能, 使用不方便. 鉴于此, 在PBI效用函数的启发下, 提出一种结合双距离的CDD-支配关系. 与现存的支配关系相比, CDD-支配关系具有如下特点: (1) 利用PBI函数的d1和d2距离构造支配关系, 显式地考虑了多目标/高维多目标进化算法的收敛性和多样性; (2) CDD-支配根据MaOP的目标数自适应地平衡收敛性与多样性, 无需额外设置参数; (3) CDD-支配关系满足反自反、反对称和传递性, 其能在目标空间解群上建立起严格的偏序关系. 下面给出CDD-支配的定义及其性质.
定义1(CDD-支配). 给定种群P和权值向量集合A, 将P中各个体关联到A中与其最邻近的权值向量, 并根据PBI函数计算各个体的d1和d2距离. 称个体i CDD-支配个体j(记为i≺CDDj), 当且仅当满足下列条件之一.
1) 个体i Pareto支配j;
2) 个体i和j彼此Pareto非支配, 但i和j关联到同一权值向量, 且它们的d1, d2距离满足d1(i) < d1(j)且d1(j)−d1(i)≥1/m[d2(i)−d2(j)], 或d1(i) > d1(j)且d1(i)−d1(j) < 1/m[d2(j)−d2(i)], 或d1(i)=d1(j)且d2(i) < d2(j). 这里, m表示MaOP目标数目.
定义2(CDD-非支配). 设个体i和j是种群P中任意两个个体, 若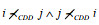
为直观地理解CDD-支配方法, 图 2以2-目标空间为例(即m=2), 解释CDD-支配中的第2种情形, 即两个体是Pareto非支配关系, 但它们关联到相同的权值向量.

|
图 2 关联到相同权值向量的Pareto非支配个体能否满足CDD-支配关系的示例 |
在图 2(a)中, 个体i, j1和j2彼此为Pareto非支配关系, 判断j1≺CDDi过程如下: 首先考察个体i, j1的d1距离, 这里, d1(i) < d1(j1); 随后, 进一步考察个体i和j1的d2距离, 不难发现, 它们满足如下关系, 即d1(j1)−d1(i) < 1/m[d2(i)−d2(j1)]. 根据定义1, 可判定j1≺CDDi. 同理, 可判定i≺CDDj2成立. 图 2(b)示意了当两个Pareto非支配个体i和j的d1距离相等时, 由于j的d2距离小于i的d2距离, 因此, j≺CDDi成立.
由于CDD-支配既考虑了个体的双距离值(d1和d2), 还考虑了个体间双距离的差值, 其有利于进一步提高该支配关系区分Pareto非劣解的能力, 可增强种群的选择压力.
2.2 CDD-支配关系的性质根据CDD-支配的定义, 可证明其满足反自反、反对称、传递性和严格偏序关系等性质. 鉴于Pareto支配是一种严格偏序关系, 因此, 这里只证明CDD-支配在满足条件2)时, 其亦具有上述性质.
性质1(反自反). 设个体i是种群P的任意个体, 在CDD-支配意义下, 其满足反自反性, 即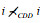
证明: 反证法. 假设iπCDDi, 根据CDD-支配定义, 有d1(i) < d1(i), 或d1(i) > d1(i), 或d1(i)=d1(i)且d2(i) < d2(i)三者之一得以满足. 但对于个体i的d1和d2距离而言, 其显然不满足上述3种情形中的任一种情形, 因而假设不成立, 故CDD-支配关系满足反自反性.
性质2(反对称). 设个体i和j是种群P中任意两个解, 如果i≺CDDj, 则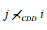
证明:
1) 若i≺CDDj, 根据CDD-支配定义, 有d1(i) < d1(j)且d1(j)−d1(i)≥1/m[d2(i)−d2(j)], 或d1(i) > d1(j)且d1(i)−d1(j) < 1/m[d2(j)−d2(i)], 或d1(i)=d1(j)且d2(i) < d2(j)三者之一得以满足;
2) 若j≺CDDi, 根据CDD-支配定义, 有d1(j) < d1(i)且d1(i)−d1(j)≥1/m[d2(j)−d2(i)], 或d1(j) > d1(i)且d1(j)−d1(i) < 1/m[d2(i)−d2(j)], 或d1(j)=d1(i)且d2(j) < d2(i)三者之一成立.
显然, 情形1)和情形2)相悖.
因此, 如果i≺CDDj, 则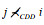
性质3(传递性). 设个体i, j和k是种群P中任意的3个个体, 若i≺CDDj且j≺CDDk, 则i≺CDDk成立.
证明: 由于个体的d1距离在CDD-支配定义之条件2)中可能出现大于、小于和等于另一个体d1距离之情形, 因而证明个体i, j和k之间的传递性则会出现9种组合. 下面以d1(i) < d1(j)为例给出证明过程, 其余情形可类推之. 若i≺CDDj, 则有d1(i) < d1(j)且d1(j)−d1(i)≥1/m[d2(i)−d2(j)], 或d1(i) > d1(j)且d1(i)−d1(j) < 1/m[d2(j)−d2(i)], 或d1(i)=d1(j)且d2(i) < d2(j)这3种情形之一得以满足. 若j≺CDDk, 则类似. 现证明其中一种情形: 若d1(i) < d1(j)且d1(j) < d1(k), 则有d1(i) < d1(k)成立; 同时, 若d1(j)−d1(i)≥1/m[d2(i)−d2(j)]且d1(k)−d1(j)≥1/m[d2(j)−d2(k)]成立, 两式相加可得d1(k)−d1(i)≥1/m[d2(i)−d2(k)]. 因而j≺CDDk成立. 其余8种情形可用类似方法证明j≺CDDk成立.综上, CDD-支配关系满足传递性.
性质4(严格偏序关系). CDD-支配定义了一种严格偏序关系.
证明: 根据上述论证可知, CDD-支配关系满足反自反、反对称和传递性, 因此, CDD-支配关系是一种建立在种群P上的严格偏序关系.
由于CDD-支配是一种严格偏序关系, 因此, 利用基于CDD-支配的非支配排序方法对种群进行分层后, 可保证层级较高的非支配层上个体要优于层级较低的非支配层上的个体.
3 利用双距离构造的多样性保持方法当前, 一些MOEA利用非支配排序方法对种群进化划分, 然后依照非支配层的等级从高到低选择一定数目的个体进入下一代, 且保持种群规模不变. 而当某个非支配层只能从中择优部分个体时, 算法需要利用某种环境选择策略进行选择. 例如: NSGA-II[20]利用2-近邻拥挤距离策略选择较稀疏个体; NSGA-III[25]在小生境(通过均匀分布的参考点构造)内选择个体; RPD-NSGA-II[18]通过计算PBI函数中的d2距离选择个体. 需要指出: 上述多样性保持方法大都强调分布性, 而很少考虑收敛性, 这种择优方式不利于改善收敛性. 进一步地, 这里利用PBI函数的双距离(即d1和d2)构造一种多样性保持方法DM-DD. 该方法在所考虑的最末非支配层中选择个体时, 将计算个体的双距离值dd, 且个体的dd值越小, 则个体进入下一代的概率就越大. 具体地, 设i为所考虑最末非支配层上的任意个体, 则i的双距离值dd(i)可计算如下:
| $ d d(i)=d_1(i)+d_2(i) / m $ | (3) |
这里的m为MaOP目标数.
DM-DD方法考虑了个体的d1和d2距离, 其环境选择的方式要比RPD-NSGA-II算法仅考虑d2距离来筛选个体的粒度更细. 图 3解释了结合双距离的方法择优个体的优势. 假设个体i和j是所考虑最末非支配层上个体, 如果仅计算个体的d2距离, 则i胜出; 但如果按照公式(3)的方式考虑个体的dd值, 若dd(j) < dd(i), 则j胜出.

|
图 3 考虑双距离比仅考虑d2距离选择个体的粒度更细 |
需要指出, 公式(3)计算个体dd值的方法体现了在高维目标空间中自适应地平衡收敛性与多样性的思想.其原因在于: 有限规模的种群个体分布在高维目标空间中, 其分布的稀疏性将随目标空间维度的增加而急剧扩大. 因而在维度越高的目标空间中, 种群个体的分布性将更易于自然地获得. 在这种情况下, 需要更多地强调收敛性而降低多样性占比. 基于此, 这里定性地将方程(3)右边第2项多样性部分的占比考虑随目标维度m增大而降低, 实质上也自动增大了收敛性的比重. 此外, m越大, 意味着多样性占比越低, 收敛性比重越大, 从而起到了自适应调整的作用.
4 MaOEA/d2算法 4.1 MaOEA/d2算法流程为较好地平衡高维多目标进化算法的收敛性和多样性, 改善算法的综合性能, 这里将CDD-支配关系和DM-DD多样性方法嵌入到NSGA-II算法框架, 分别替代其原有的Pareto支配关系和拥挤距离度量方法, 设计一种基于双距离构造的高维多目标进化算法MaOEA/d2. 图 4以MaOEA/d2算法第t代为例, 直观地描述了算法的运行机制.

|
图 4 MaOEA/d2算法运行机制 |
如图 4所示: MaOEA/d2算法运行第t代时, 将第t代父种群Pt与其子代种群Qt进行合并, 以产生联合种群Rt; 然后对种群Rt执行基于CDD-非支配排序, 由此产生从高到低的若干非支配层F1, F2, F3, .... 通常, 非支配层级高的个体要优于层级低的个体. 随后, 算法进入环境选择阶段, 假设种群规模为N(其值在算法执行过程中保持不变), 根据非支配层级从高到低的顺序依次选择F1, F2, F3, …中的个体进入下一代种群Pt+1中. 在此过程中, 如果出现了全部选择某个非支配层, 比如Fk层, 则种群规模超过N, 因而只能在Fk层选择部分个体进入下一代. 此时需要对Fk层上的个体计算它们的dd值, 然后按dd值从小到大的顺序选部分个体置于下一代种群Pt+1中. 如此反复, 直至算法满足终止条件.
以下是MaOEA/d2算法的流程.
算法. MaOEA/d2算法.
输入: 种群规模N, 决策变量数目D, MaOP问题的目标数目m, 最大迭代次数Tmaxgen;
输出: 最末代种群Pmaxgen.
1. 初始化
1.1 初始化迭代计数器t=0;
1.2 在待解问题的可行决策空间内随机产生N个初始点, 形成初始化种群P0, 并计算P0中各解点的目标值向量{F1(0), …, FN(0)};
1.3 利用两层参考向量方法产生一定数目的权值向量(参考点):
| $ \mathit{\Lambda} \leftarrow two\_layered\_generation\_method\left( {m,{H_1},{H_2}} \right);$ |
2. WHILE (t < Tmaxgen)
3. 构建交配池:
4. 重组运算:
5. 变异运算:
6. 合并子种群和父种群:
7. 计算最小目标值向量Fmin;
8. 计算最大目标值向量Fmax;
9. 归一化处理: Rt←(Rt, Fmin, Fmax);
10. 计算个体的d1距离;
11. 计算各个体的d2距离;
12. 利用d2距离将各个体与它的最近参考向量相关联;
13. 保留Rt中的边界点;
14. 利用基于CDD-支配的非支配排序方法划分Rt以获得若干非支配层: [F1, F2, ...]←CDD-based_nondomination_sorting(Rt); //Fi表示第i层CDD非劣支配层.
15. 确定最小的k值, 使其满足|F1∪F2∪…∪Fk|≥N;
16. IF |F1∪F2∪…∪Fk| > N THEN
17. 计算最末CDD非劣支配层Fk上各个体的dd值, 并从Fk层上删除(|F1∪F2∪…∪Fk|−N)个具有较大dd值的个体;
18. END IF
20. Pi+1=F1∪F2∪…∪Fk;
21. 更新迭代计数器: t=t+1;
22. END WHILE
23. 输出最末代种群Pmaxgen.
MaOEA/d2算法第1步产生规模为N的初始种群P0, 并利用两层参考向量产生方法[18, 25]生成有限规模的参考向量集合Λ. 算法从第2步开始进入循环阶段, 第3−5步利用仿二进制交叉和多项式变异方法产生子代种群, 第6步合并父代和子代种群, 组成联合种群Rt. 第7−9步对Rt实施归一化处理. 第10步、第11步计算各个体的双距离, 并将它们关联至相应的参考向量. 第13步保留边界解, 以增强算法的多样性. 第14 −19步利用基于CDD-支配的非支配排序方法对Rt进行划分, 以获得若干非劣支配层. 然后, 根据非劣层的等级以及利用DM-DD方法择优一定数目的个体组成下一代Pt+1. 算法的第23步输出最末代种群Pmaxgen, 并将其视为算法获得的近似解集.
下面对MaOEA/d2算法的时间复杂度进行分析: 设N表示种群规模, m表示MaOP的目标数, 决策空间维度为n, 算法最大的迭代次数为Tmaxgen, 则MaOEA/d2算法的时间复杂性分析如下.
1. 步骤1的初始化阶段包括3个子步, 其中, 初始化迭代器的时间为O(1), 生成初始群体P0的时间复杂度为O(Nn), 计算各个体目标函数值向量的时间是O(Nm). 因此, 第1步时间复杂度为
| $ \mathrm{O}(1)+\mathrm{O}(Nn)+\mathrm{O}(Nm)=\max (\mathrm{O}(Nn), \mathrm{O}(Nm)); $ |
2. 算法从第2步进入循环, 循环体内构建交配池、重组运算、变异运算以及合并父代和子代种群的时间复杂度均为O(Nn). 步骤7−步骤9计算最小和最大的目标函数值向量以及归一化过程的时间均为O(Nm). 步骤10−步骤12的时间复杂度为O(N2), 步骤13保留边界点的时间为O(Nm). 步骤14利用基于CDD-支配的非支配排序方法对Rt进行分层的时间复杂度为O(N2m). 步骤15−步骤21的时间复杂度为O(Nm). 由于算法最多迭代Tmaxgen次, 因此循环体内的时间复杂度为O(mN2Tmaxgen);
3. 第23步输出最末代种群的时间复杂度为O(Nm).
综上, MaOEA/d2算法的时间复杂度为max(O(Nn), O(Nm))+O(mN2Tmaxgen)+O(Nm)=O(mN2Tmaxgen). 不难看出, MaOEA/d2算法时间复杂度取决于其所采用的非支配排序方法. 因此, 设计更高效的非支配排序算法对种群实施有效分层值得深入研究.
5 实验与分析 5.1 对比算法为验证MaOEA/d2算法的性能, 这里选取5种高效的高维多目标进化算法, 如RPD-NSGA- II[18]、NSGA-III[25]、RVEA[26]、MaOEA/IGD[27]和NSGA-II/SDR[16], 作为对比算法以检验本文算法的性能. 选择上述算法作为对比算法的主要原因在于:
1) RPD-NAGA-II算法与MaOEA/d2算法同属改进支配关系的一种算法类型, 前者利用PBI函数的d1距离设计支配关系, 并运用d2距离构造多样性保持方法; 后者同时利用PBI函数的d1, d2距离构造支配关系和多样性策略. 两种算法的设计思想较类似, 且均未引入额外参数;
2) NSGA-III作为经典的高维多目标进化算法, 其核心在于利用Pareto支配关系和运用参考点(参考向量)方法生成小生境, 其在求解MaOP中表现了显著较优的性能, 而且亦未引入额外参数;
3) RVEA利用基于角度惩罚距离(angle-penalized distance, APD)的方法平衡高维目标空间中解个体的收敛性与多样性. RVEA与MaOEA/d2算法相类似的是, 它们都将无法区分优劣的个体通过标量化方法进行转化后实现比较;
4) MaOEA/IGD算法是一种基于性能指标的高维多目标进化算法, 其核心在于利用基于分解的最差点估计方法(DNPE)估计最差点. 与MaOEA/d2算法类似, MaOEA/IGD利用一种兼容Pareto支配的非支配排序方法对种群进化划分. 这里选用MaOEA/IGD算法作为基于性能指标类型算法的典型范例;
5) NSGA-II/SDR算法通过设计一种增强支配关系和一种自适应小生境策略平衡算法的收敛性和多样性, 且亦未引入额外参数. 其与MaOEA/d2算法在设计动机上具有一定的相似之处.
5.2 测试问题实验利用5-, 10-, 15-和20-目标的DTLZ1~DTLZ7[21]以及WFG1~WFG9[22]等测试实例作为基准测试函数, 考察算法的性能. 采用DTLZ和WFG系列函数的原因是: (1) 这两个系列测试问题的目标数和决策变量数是可扩展的; (2) DTLZ和WFG系列问题的真实PF是已知的, 而且它们的PF具有不同的难度特征, 因而对算法逼近真实PF构成了巨大挑战. 表 1列出了这两个系列测试问题的难度特征.
| 表 1 DTLZ和WFG系列测试问题的难度特征 |
5.3 性能指标
为评估MOEA算法的收敛性和多样性, 这里采用两个常用的性能指标, 即超体积指标(hypervolume, HV)[24]和反转世代距离(inverted generational distance, IGD)[23]来评估它们的性能, 其原因在于, HV和IGD均能同时度量近似解集的收敛性和多样性.
HV指标通过计算目标空间中被非劣解集覆盖区域的大小来评估算法的性能. HV指标也称为Lebesgue测度, 它在理论上具有良好的数学性质, 即: 在所有的一元指标中, HV是一种能够判定非支配解集X不比另一个非支配解集Y要差的方法, 而且它能与Pareto支配保持一致. 对于一个近似的Pareto解集A, 其HV值计算如下:
| $ HV(A) = \mathit{\Lambda} (\mathop \cup \limits_{p \in A} \{ x|p \succ x \succ {x_{ref}}\} ) $ | (4) |
其中, Λ为Lebesgue测度, xref为参照点. 对于2-目标问题, HV是坐标区域的面积; 对于3-目标问题, HV是三维空间构成的体积; 对于4维及以上目标的问题, HV表示超体值. 通常, HV值越大, 表示解集的质量越高, 亦即解集的收敛性与多样性就越好.
IGD指标度量了真实Pareto前沿到所获近似Pareto前沿之间的距离. 由于实验中的测试问题的真实PF是已知的, 通过在真实PF上均匀采样多样性的解点, 计算这些采样点到算法获得的近似Pareto解点之间的距离则既能反映解集的收敛性, 又能反映多样性. 一般而言, IGD指标值越小, 表示近似解集的收敛性和多样性越好. 假设P是MOP问题真实PF的代表解集, A是算法获得的近似Pareto解集, IGD指标可利用公式(5)进行计算:
| $ IGD(A, P) = \frac{1}{{|P|}}\sum\limits_{i = 1}^{|P|} {Dis{t_i}} $ | (5) |
其中,
为减少随机因素对性能评估的影响, 实验中各算法在每一个测试实例中均独立执行30次(每次使用不同的随机数种子)以获得IGD或HV指标的均值和方差. 另外, 实验利用显著水平为0.05的Wilcoxon秩和检验来分析各算法获得近似解集的性能在统计意义上的差异.
5.5 实验环境本文所有实验均在ThinkPad E565计算机上运行, 计算机配置是CPU: AMD A10-8700P; 1.8 GHz主频; 8.0 GB内存; Windows 10 64位操作系统. 实验中, 各算法均在PlatEMO[28]平台上实现.
5.6 实验参数设置实验中所涉及的参数包括各算法的共有参数和特有的参数, 具体如下.
(1) 共有参数方面: 为公平比较起见, 不同算法在相同测试实例上执行相同的评估次数(evaluation number, EN), 各算法在不同测试实例上执行的代数(T)取决于评估次数和种群规模(N), 且满足T=EN/N. 对于5-, 10-, 15-和20-目标的测试实例, 实验均分配50 000次函数评估. 另外, 由于RVEA[26], NSGA-III[25], RPD-NSGA-II[18]和MaOEA/d2算法均利用两层生成方法产生一定数目的权重向量, 因此它们的种群规模需与权重向量数目保持一致. 实验中, 对于5-目标、10-目标、15-目标和20-目标的测试实例, 各算法种群规模均分别设为212, 276, 136和232. 此外, MaOEA/d2和NSGA- II/SDR都利用仿二进制交叉(SBX)和多项式变异(PM)产生新个体, 其中: SBX和PM算子的参数按表 2设置; 而RPD-NSGA-II, RVEA, NSGA-III中的变化算子除交叉分布指数ηc取值为30外, 其余参数值仍按表 2设置.
| 表 2 实验中SBX和PM算子的参数设置 |
(2) 特有参数方面: 各对比算法特有的参数按它们原始文献中的建议值设置. 比如: 在RVEA算法中, APD的惩罚参数α取值为2, 控制参考向量调整频度的参数δ设为0.1; 在MaOEA/IGD中, 基于分解的最差点估计法(DNPE)的参数λ设为100.
5.7 实验结果与分析为验证MaOEA/d2算法的有效性, 这里将MaOEA/d2与RPD-NSGA-II, NSGA-III, RVEA, MaOEA/IGD和NSGA-II/SDR算法一同在5-, 10-, 15-和20-目标的DTLZ和WFG系列测试函数上进行IGD和HV性能的比较.表 3和表 4分别列出了6种算法在DTLZ和WFG系列测试问题上所获得的IGD均值和方差. 表内各行最佳结果用粗体突显(下同).
| 表 3 各算法在4种目标维度的DTLZ系列测试问题上获得的IGD均值与方差 |
| 表 4 各算法在4种目标维度的WFG系列问题上获得的IGD均值与方差 |
表 3给出了6个算法在28个DTLZ测试实例上的所获得的IGD均值与方差, 其中, MaOEA/d2, RPD- NSGA-II, NSGA-III, RVEA和NSGA-II/SDR算法在这些测试实例上获得最佳IGD均值的个数分别为7, 1, 1, 8, 11, 而MaOEA/IGD无一能获得最佳的IGD均值. 另外, 从表 3的Wilcoxon秩和检验结果来看, MaOEA/d2相对于RPD-NSGA-II, NSGA-III, RVEA, MaOEA/IGD和NSGA-II/SDR的净胜得分(即得“+”的数目减去得“−”的数目, 下同)分别为21, 9, 3, 1和−3. 综合来看, MaOEA/d2算法在求解DTLZ系列问题时, 除NSGA-II/SDR算法外, 相较其他4种对比算法具有显著较优的IGD性能.
表 4列出了6个算法在36个WFG测试实例上获得的IGD均值和方差, 其中, MaOEA/d2, RPD-NSGA-II, NSGA-III, RVEA和NSGA-II/SDR获得最佳IGD均值的个数分别为7, 6, 8, 11, 4, 而MaOEA/IGD算法均未能获得任何最佳IGD均值. 从表 4的Wilcoxon秩和检验结果来看, MaOEA/d2相对于RPD-NSGA-II, NSGA-III, RVEA, MaOEA/IGD和NSGA-II/SDR所获得的净胜得分分别为4, −6, −7, 21和9. 因此, MaOEA/d2算法在求解WFG系列问题时的性能次于NSGA-III与RVEA算法, 而优于其他的3种对比算法, 总体上的性能处于中上游位置.
另外, 为直观显示算法的解题结果, 图 5和图 6分别展示了6种算法在10-目标的DTLZ4(简记为DTLZ4 (10))和10-目标的WFG5(简记为WFG5(10))测试实例上所获得的非支配解集的平行坐标. 这里给出的非支配解集均为各算法在30次运行中获得的最接近于IGD均值的近似解集.

|
图 5 6种算法在10-目标的DTLZ4测试实例上获得的近似解集 |

|
图 6 6种MOEA算法在10-目标的WFG5测试问题上获得的近似解集 |
从图 5可以看出, MaOEA/d2, RPD-NSGA-II, NSGA-III, RVEA, MaOEA/IGD和NSGA-II/SDR这6个算法在DTLZ4(10)测试实例上获得解群的收敛性均较好, MaOEA/d2, RPD-NSGA-II, RVEA, MaOEA/IGD和NSGA-II/SDR算法在DTLZ4(10)测试实例上获得的解群分布性也较好, 而NSGA-III在第5目标、第8目标上分布性差, NSGA-II/SDR算法获得有效解的数量较少. 从图 5来看, MaOEA/d2算法在DTLZ4(10)测试实例上具有较好的收敛性与多样性, 与表 3的结果相一致.
从图 6可以看出: MaOEA/d2, RPD-NSGA-II, NSGA-III, RVEA和NSGA-II/SDR算法在WFG5(10)测试例上所获得的近似解集具有较好收敛性和多样性; 而MaOEA/IGD算法在求解该测试实例时, 在不同的目标上, 其收敛性和多样性的表现不均衡. 究其原因, WFG5测试问题具有欺骗性, 其MaOEA/IGD算法可能构成了较大的挑战; 而MaOEA/d2等则能较好地求解具有欺骗性的MaOP问题, 其与表 4的结果相吻合.
不仅如此, 为了直观地比较6种算法的收敛速度, 图 7和图 8分别描绘了各算法在10-目标的DTLZ6 (DTLZ6(10))和10-目标的WFG9(WFG9(10))测试实例上获得的IGD均值随评估次数(EN)增长而变化的轨迹.为了获得稳定且可靠的结果, 这里, 各算法在测试实例上均独立执行30次, 每次运行所需的评估次数设为100 000.

|
图 7 6种算法在10-目标的DTLZ6测试问题上获得的IGD均值的变化曲线 |

|
图 8 6种算法在10-目标的WFG9测试问题上获得的IGD均值的变化曲线 |
从图 7可以看出: 6种算法随着评估次数EN的增大, 它们所获得的IGD均值总体上表现出变小的趋势.但相对而言, MaOEA/d2算法获得的IGD均值下降最快, 其次是RVEA算法, 之后为NSGA-II/SDR和RPD- NSGA-II, 而NSGA-III, MaOEA/IGD相对较差. MaOEA/d2, RVEA和NSGA-II/SDR算法在经历初始约2×104次评估后, 它们的IGD均值能较快下降至一个相对较小的值, 而在后期进化过程中, 它们的IGD均值呈现出缓慢变小的趋势. 而MaOEA/IGD在经历4×104次左右的评估后, 其IGD值趋于平稳. 由于IGD指标能够表征近似解集的收敛性和多样性, 且IGD值越小, 表明算法获得的近似解集的质量越高, 因此, 图 7的IGD曲线的变化轨迹直观地表明了MaOEA/d2算法相比其他几种算法, 其在DTLZ6(10)测试实例上能较快地获得高质量的近似解集.
从图 8可以看出: 6种算法所获得的IGD均值总体上均随评估次数EN的增大而表现出变小的趋势. 但相对而言, MaOEA/d2算法获得的IGD均值下降最快; 其次是NSGA-III, NSGA-II/SDR与RPD-NSGA-II算法; RVEA呈现出了先快速下降, 而后缓慢上升再下降的波折; MaOEA/IGD曲线波动较大, 在经历6×104次评估后趋于收敛. 总体上, MaOEA/d2, NSGA-III, RPD-NSGA-II和NSGA-II/SDR算法在经历初始阶段约1×104次评估后, 它们的IGD均值能较快下降至一个相对较低的水平, 而在后期进化过程中, 它们的IGD均值呈现出缓慢变小的趋势. 因此, 从图 8的IGD曲线轨迹可直观上获知, MaOEA/d2算法在该测试实例上能较快地获得高质量的近似解集.
此外, 为考察MaOEA/d2算法在WFG系列测试问题上的HV性能, 将MaOEA/d2与RPD-NSGA-II, NSGA- III, RVEA, MaOEA/IGD和NSGA-II/SDR算法在5-, 10-, 15-和20-目标的WFG1~WFG9测试实例上进行实验, 表 5给出了6种算法在5-, 10-, 15-和20-目标的WFG1−WFG9测试问题上获得的HV均值与方差. 需要说明的是, 这里计算HV值所使用的参考点r设置为(1.1×Znad). 这里, Znad表示MaOP问题的理想点.
| 表 5 各算法在4种目标维度的WFG系列问题上获得的HV均值与方差 |
表 5给出了MaOEA/d2, RPD-NSGA-II, NSGA-III, RVEA, MaOEA/IGD和NSGA-II/SDR算法在36个WFG测试实例上获得的HV均值与方差, 其中, MaOEA/d2, NSGA-III, RVEA和NSGA-II/SDR算法分别获得12, 6, 1和14个最佳的HV均值结果, 而RPD-NSGA-II和MaOEA/IGD无一能获得最佳的HV值. 另外, 从表 5的Wilcoxon秩和检验结果来看, MaOEA/d2相对于RPD-NSGA-II, NSGA-III, RVEA, MaOEA/IGD和NSGA-II/ SDR算法的净胜得分分别为30, 4, 8, 19和−9. 除了NSGA-II/SDR算法外, MaOEA/d2对于其他对比算法具有较优的HV性能.
总体上, 从上述实验结果来看, MaOEA/d2相对其他几种新近发展的高维多目标进化算法, 其具有相对较好的收敛性和多样性. 究其原因, MaOEA/d2利用PBI函数的双距离(d1和d2)定义和构造了CDD-支配关系和DM-DD方法, 不仅能细粒度区分高维目标空间中解个体的优劣, 而且能自适应地调整高维目标解个体收敛性与多样性之间的占比, 以更好地平衡收敛性和多样性. 另外, CDD-支配关系和DM-DD方法在MaOEA/d2算法执行的不同阶段发挥作用并相互协同, 使得算法在求解各类具有不同难度特征的MaOP中表现出较好的性能.
进一步地, 为检验DM-DD多样性方法在保持高维目标解群多样性上的性能, 这里设计将DM-DD方法与NSGA-II中的拥挤距离度量方法(简记为CD)以及RPD-NSGA-II算法中利用d2的择优个体的方法(简记为D2)一同在5-, 10-, 15-和20-目标的DTLZ1-DTLZ7测试实例上进行IGD性能比较. 具体地, 将DM-DD和D2这两种方法分别嵌入到NSGA-II算法, 以分别替代算法原有的拥挤距离方法, 而保持算法其他部分不变. 由此构造出NSGA-II/DM-DD和NSGA-II/D2这两种算法变种. 实验方案设计如下: 将NSGA-II/DM-DD, NSGA-II/ D2和NSGA-II这3种算法在5-, 10-, 15-和20-目标的DTLZ1−DTLZ7测试实例上进行IGD性能比较. 实验中, 对于5-, 10-, 15-和20-目标的测试问题, 各算法的种群规模分别设为212, 276, 136和232. 各算法所需的函数评估次数统一设为50 000. 实验中, 算法使用的SBX交叉和PM变异算子的参数设置同表 2. 表 6给出了3种算法在5-, 10-, 15-和20-目标的DTLZ系列测试实例上所获得的IGD均值与方差.
| 表 6 各算法在4种目标维度的DTLZ系列问题上获得的IGD均值与方差 |
表 6给出了3种算法在28个DTLZ测试实例上的获得的IGD均值与方差, 其中, NSGA-II/DM-DD, NSGA- II和NSGA-II/D2算法在这些测试实例上获得最佳IGD均值的数目分别为19, 6, 3. 另外, 从表 6的Wilcoxon秩和检验结果来看, NSGA-II/DM-DD相对于NSGA-II和NSGA-II/D2的净胜得分分别为15和17. 综合来看, NSGA-II/DM-DD算法在求解DTLZ系列问题时具有显著较优的性能, 由此表明DM-DD多样性保持方法具有显著较优的性能. 究其原因, DM-DD方法不仅能够考虑高维目标空间中解个体的收敛性与多样性, 还随着目标空间维度的变化, 自适应地调整多样性的占比. 这种机制较好地平衡算法的收敛性与多样性, 从而改善算法的性能. 相比之下, D2方法仅考虑解个体的d2距离, 未能将收敛性和多样性综合考虑, 且缺乏自适应机制, 因而未能较好平衡解群的收敛性与多样性. NSGA-II算法中的CD方法基于欧氏距离度量目标空间中的拥挤度, 但由于欧氏距离在高维目标空间中不能有效地度量解点之间的拥挤距离, 使得多样性保持策略的效果较差.
6 总结为克服Pareto支配在高维目标空间中的不足, 本文从改进支配关系着手, 提出一种结合双距离的支配关系, 即CDD-支配关系. 该支配方法不仅具有良好的性质, 而且无需引入额外的参数; 其次, 利用双距离构造了一种多样性保持方法, 即DM-DD方法. DM-DD方法不仅考虑了高维目标空间中解个体的收敛性与多样性, 而且还能根据待解问题的目标数的变化, 自适应地调整多样性所占的比重, 较好地平衡了高维多目标算法的收敛性与多样性. 进一步地, 将CDD-支配和DM-DD方法嵌入NSGA-II算法框架, 设计了一种利用双距离构造支配关系和多样性方法的高维多目标进化算法MaOEA/d2. 实验将MaOEA/d2与5种高效的高维多目标进化算法一同在DTLZ和WFG系列测试问题进行性能测试, 结果表明, MaOEA/d2算法具有显著较优的收敛性与多样性. 因此, 本文算法是一种颇具前景的高维多目标进化算法. 未来将利用一些更加复杂的MaOP问题检验本文算法的性能, 并利用MaOEA/d2算法求解现实应用中的一些MaOP问题. 另外, 设计一些高效的非支配排序方法对种群实施有效划分, 也是未来的努力方向之一.
| [1] |
Falcón-Cardona JG, Coello CAC. Indicator-based multi-objective evolutionary algorithms: A comprehensive survey. ACM Computing Surveys, 2020, 53(2): 1-35.
|
| [2] |
Xie CW, Yu WW, Bi YZ, et al. Many-objective evolutionary algorithm based on decomposition and coevolution. Ruan Jian Xue Bao/Journal of Software, 2020, 31(2): 356-373(in Chinese with English abstract).
http://www.jos.org.cn/jos/article/abstract/5617?st=search [doi:10.13328/j.cnki.jos.005617] |
| [3] |
Zhang ZX, Cao Y, Cui ZH, et al. A many-objective optimization based intelligent intrusion detection algorithm for enhancing security of vehicular networks in 6G. IEEE Trans. on Vehicular Technology, 2021. [doi: 10.1109/TVT.2021.3057074]
|
| [4] |
Zhu ZH. A hybrid indicator many-objective optimization algorithm for selection and delivery of disaster relief materials problem. Concurrency Computation, 2021, 33(6): e5948.
|
| [5] |
Pan LQ, Li LH, He C, et al. A subregion division-based evolutionary algorithm with effective mating selection for many-objective optimization. IEEE Trans. on Cybernetics, 2020, 50(8): 3477-3490.
[doi:10.1109/TCYB.2019.2906679] |
| [6] |
Gong D, Liu Y, Yen GG. A meta-objective approach for many-objective evolutionary optimization. Evolutionary Computation, 2020, 28(1): 1-25.
[doi:10.1162/evco_a_00243] |
| [7] |
Yang S, Li M, Liu X, et al. A grid-based evolutionary algorithm for many-objective optimization. IEEE Trans. on Evolutionary Computation, 2013, 17(5): 721-736.
[doi:10.1109/TEVC.2012.2227145] |
| [8] |
Zou X, Chen Y, Liu M, et al. A new evolutionary algorithm for solving many-objective optimization problems. IEEE Trans. on Systems, Man, and Cybernetics, Part B (Cybernetics), 2008, 38(5): 1402-1412.
[doi:10.1109/TSMCB.2008.926329] |
| [9] |
Zhu C, Xu L, Goodman ED. Generalization of Pareto-optimality for many-objective evolutionary optimization. IEEE Trans. on Evolutionary Computation, 2016, 20(2): 299-315.
[doi:10.1109/TEVC.2015.2457245] |
| [10] |
Liu Y, Gong D, Sun J, et al. A many-objective evolutionary algorithm using a one-by-one selection strategy. IEEE Trans. on Cybernetics, 2017, 47(9): 2689-2702.
[doi:10.1109/TCYB.2016.2638902] |
| [11] |
Fan Z, Fang Y, Li W, et al. MOEA/D with angle-based constrained dominance principle for constrained multi-objective optimization problems. Applied Soft Computing, 2019, 74: 621-633.
[doi:10.1016/j.asoc.2018.10.027] |
| [12] |
Jiang S, Yang S. A strength Pareto evolutionary algorithm based on reference direction for multi-objective and many-objective optimization. IEEE Trans. on Evolutionary Computation, 2017, 21(3): 329-346.
[doi:10.1109/TEVC.2016.2592479] |
| [13] |
Xiang Y, Zhou Y, Li M, et al. A vector angle-based evolutionary algorithm for unconstrained many-objective optimization. IEEE Trans. on Evolutionary Computation, 2017, 21(1): 131-152.
[doi:10.1109/TEVC.2016.2587808] |
| [14] |
Liu Y, Zhu N, Li K, et al. An angle dominance criterion for evolutionary many-objective optimization. Information Sciences, 2020, 509: 376-399.
[doi:10.1016/j.ins.2018.12.078] |
| [15] |
Xie CW, Yu WW, Guo H, et al. DAV-MOEA: A many-objective evolutionary algorithm adopting dynamic angle vector based dominance relation. Chinese Journal of Computers, 2022, 45(2): 317-333(in Chinese with English abstract).
https://www.cnki.com.cn/Article/CJFDTOTAL-JSJX202202005.htm |
| [16] |
Tian Y, Cheng R, Zhang X, et al. A strengthened dominance relation considering convergence and diversity for evolutionary many-objective optimization. IEEE Trans. on Evolutionary Computation, 2019, 23(2): 331-345.
[doi:10.1109/TEVC.2018.2866854] |
| [17] |
Yuan Y, Xu H, Wang B, et al. A new dominance relation-based evolutionary algorithm for many-objective optimization. IEEE Trans. on Evolutionary Computation, 2016, 20(1): 16-37.
[doi:10.1109/TEVC.2015.2420112] |
| [18] |
Elarbi M, Bechikh S, Gupta A, et al. A new decomposition-based NSGA-II for many-objective optimization. IEEE Trans. on Systems, Man and Cybernetics: Systems, 2018, 48(7): 1191-1210.
[doi:10.1109/TSMC.2017.2654301] |
| [19] |
Ma X, Yu Y, Li X, et al. A survey of weight vector adjustment methods for decomposition based multi-objective evolutionary algorithms. IEEE Trans. on Evolutionary Computation, 2020, 24(4): 634-649.
[doi:10.1109/TEVC.2020.2978158] |
| [20] |
Deb K, Pratap A, Agarwal S, et al. A fast and elitist multi-objective genetic algorithm: NSGA-II. IEEE Trans. on Computation, 2002, 6(2): 182-197.
[doi:10.1109/4235.996017] |
| [21] |
Deb K, Thiele L, Laumanns M, et al. Scalable multi-objective optimization test problems. In: Proc. of the 2002 Congress on Evolutionary Computation. 2002. 825-830.
|
| [22] |
Huband S, Barone L, While L, et al. A scalable multi-objective test problem toolkit. In: Proc. of the Int'l Conf. on Evolutionary Multi-Criterion Optimization. 2005. 280-295.
|
| [23] |
Ishibuchi H, Masuda H, Tanigaki Y, et al. Modified distance calculation in the generational distance and inverted generational distance. In: Proc. of the Int'l Conf. on Evolutionary Multi-Criterion Optimization. 2015. 110-125.
|
| [24] |
Jiang S, Ong YS, Zhang J, et al. Consistencies and contradictions of performance metrics in multiobjective optimization. IEEE Trans. on Cybernetics, 2014, 44(12): 2391-2404.
[doi:10.1109/TCYB.2014.2307319] |
| [25] |
Deb K, Jain H. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints. IEEE Trans. on Evolutionary Computation, 2014, 18(4): 577-601.
[doi:10.1109/TEVC.2013.2281535] |
| [26] |
Cheng R, Jin Y, Olhofer M, et al. A reference vector guided evolutionary algorithm for many-objective optimization. IEEE Trans. on Evolutionary Computation, 2016, 20(5): 773-791.
[doi:10.1109/TEVC.2016.2519378] |
| [27] |
Sun Y, Yen GG, Yi Z. IGD indicator-based evolutionary algorithm for many-objective optimization problems. IEEE Trans. on Evolutionary Computation, 2019, 23(2): 173-187.
[doi:10.1109/TEVC.2018.2791283] |
| [28] |
Tian Y, Cheng R, Zhang X, et al. PlatEMO: A MATLAB platform for evolutionary multi-objective optimization. IEEE Computational Intelligence Magazine, 2017, 12(4): 73-87.
[doi:10.1109/MCI.2017.2742868] |
| [2] |
谢承旺, 余伟伟, 闭应洲, 汪慎文, 胡玉荣. 一种基于分解和协同的高维多目标进化算法. 软件学报, 2020, 31(2): 356-373.
http://www.jos.org.cn/jos/article/abstract/5617?st=search [doi:10.13328/j.cnki.jos.005617] |
| [15] |
谢承旺, 余伟伟, 郭华, 张伟, 张琼冰. DAV-MOEA: 一种采用动态角度向量支配关系的高维多目标进化算法. 计算机学报, 2022, 45(2): 317-333.
https://www.cnki.com.cn/Article/CJFDTOTAL-JSJX202202005.htm |