 2019, Vol. 30
2019, Vol. 30



2. 中南大学 信息科学与工程学院, 湖南 长沙 410083;
3. 湖南大学 信息科学与工程学院, 湖南 长沙 410082
2. School of Information Science and Engineering, Central South University, Changsha 410083, China;
3. College of Computer Science and Electronic Engineering, Hu'nan University, Changsha 410082, China
移动社交网络(mobile social network, 简称MSN)为用户提供了更多的机会与其周围的移动用户进行社会交往, 例如, 彼此之间可以互相分享照片、视频、游戏以及进行交流等[1].此外, 多样化的移动应用APP软件也为用户提供了更多的机会去拓展新的社会关系与商业机会[2](例如, 微信应用中“附近的人”“微商”等).
利用用户个性化配置文件进行相似度匹配, 是当前移动社交网络中发现新朋友的一个有效手段.例如, 用户可以通过APP应用与智能设备的Wi-Fi接口来发现附近具有某种特征属性的朋友, 进而发起交友请求.但是在交友过程中, 用户之间共享信息也无形中增加了个人隐私泄漏的风险[3].例如:通过观察对方购物的爱好, 可以分析用户的消费能力; 通过对用户朋友圈的分析, 可以确定用户的身份等.而这些隐私信息一旦被非法利用, 极有可能导致被恶意用户利用进行商业欺骗或者从事其他非法活动.
因此, 如何在用户之间提供良好交友匹配服务的同时, 又能够保护用户个人隐私, 是当前交友隐私保护中亟待解决的一个热点问题, 也是移动应用服务提供商未来的研究方向.
1 相关工作 1.1 研究背景目前, 针对移动社交网络交友隐私保护的研究主要分为依靠可信服务第三方(trusted third party, 简称TTP)参与的方案和不依靠TTP参与的方案.
● 在有TTP参与的方案中[4-6], 用户需要将他们的特征属性配置文件提交给TTP, 由TTP作为匹配中心来计算用户之间的相似度.这种方案虽然在一定程度上解放了智能终端的计算能力, 提高了用户的匹配效率, 但是依然存在以下安全风险:第一, 一旦TTP攻击者被攻破, 攻击者可以很容易地获取TTP上用户的信息, 从而造成用户隐私泄漏; 第二, 事实上, 真正意义上完全可信的第三方并不存在, 因此有可能存在TTP因为商业利益驱动或者其他原因, 出现TTP非法访问或者出售用户隐私数据的风险; 第三, 所有用户特征匹配计算均在TTP服务器上进行, 在服务高峰时期, 极有可能会造成TTP服务器的计算和服务瓶颈;
● 而不依靠TTP参与的方案大多采用复杂的密码计算来保证用户隐私安全, 这主要包括对称加密运算与非对称加密运算[7-12].在这类方案中, 虽然加密计算提高了对用户隐私的保护, 但是在计算用户属性之间的私有交集(private set intersection, 简称PSI)时, 需要对加密文件先进行解密, 再进行匹配.因此在增加智能终端的计算开销的同时, 也直接影响了用户体验.
为解决这个问题, 后继工作中, 文献[13]提出了一种基于Paillier加密算法的保密计算协议, 可以有效保证用户隐私不被泄露.但是Paillier密码体制是一种具有语义安全的同态密码算法, 在密钥的生成和加解密上, 计算效率不高.文献[14]提出了一种基于同态加密算法的多服务器的用户特征属性的匹配方案, 可以有效地保证用户的隐私不被泄露.但是该方案在表示用户特征时使用了一维向量, 只考虑用户共同的属性个数, 因此无法细粒度地描述用户对某种特征的偏好程度.
1.2 本文贡献为降低现有方案的性能瓶颈以及对复杂加解密技术的依赖, 同时又可以细粒度地描述用户之间特征属性的相似程度, 本文在吸取了以往研究者的经验后, 提出一种不依赖可信中心与复杂的加密算法, 而是利用矩阵混淆变换与安全内积计算来保证交友用户的隐私安全.
1) 利用轻量级的混淆矩阵变换和向量拆分方法代替复杂的加密运算, 不仅可保证用户特征属性隐私, 而且能提高匹配过程的效率;
2) 利用安全内积计算用户特征属性的相似度, 不需要交友用户频繁解密特征匹配文件, 降低用户隐私泄露风险;
3) 利用多跳代理朋友发现机制, 可以更精确地找到相同或相似特征用户, 更具有可用性.
1.3 本文组织结构本文第2节为方案的预备知识.第3节给出方案的系统模型与安全模型.第4节对方案进行详细设计.第5节讨论安全性证明与交友机会分析.性能分析和详细的实验验证在第6节中进行体现.
2 预备知识 2.1 大整数分解困难问题在数论中, 对于给定大于1的一个足够大的正整数N, 存在正整数p, q, 计算乘积N=p×q是非常容易的.相反地, 求出p, q, 使得p×q=N, 也就是求出N的分解式
为了提高分解N的难度, 安全素数p, q的选择应满足以下条件.
1) p, q的差值很大, 但是位数相差不大;
2) p-1, q-1, p+1, q+1均有大素数因子;
3) (p-1, q-1)的最大公约数很小.
2.2 基于Paillier加密算法的基本内积计算内积加密计算作为安全多方计算基础协议之一, 主要应用于保密计算中, 具体描述如下.
1) 假设发起者持有私有向量X=(x1, x2, …, xn), 应答者持有私有向量Y=(y1, y2, …, yn), 令
2) 发起者为向量X的每一个元素生成一个随机数ri, 并利用
3) 应答者接受到发起者的消息后, 利用自身向量元素yi与
4) 应答者生成新的随机数r', 利用
5) 发起者利用自己的私钥解密w'计算得到两者的交集.
2.3 安全内积加密计算1) 假设发起者持有私有向量X=(x1, x2, …, xn), 应答者持有私有向量Y=(y1, y2, …, yn), 发起者如果想知道与应答者之间的相似度, 那么发起者需要计算:
| $XY = \sum\limits_{i = 1}^n {{x_i}{y_i}} $ | (1) |
其中, “●”表示内积.
2) 计算不可区分性:对于任意两个随机变量X, Y, 存在X={Xω}ω∈S, Y={Yω}ω∈S称为计算不可区分, 记为
| $|\Pr [{C_n}({X_w}) = 1] - \Pr [{C_n}({Y_w}) = 1]| < \frac{1}{{P(n)}}$ | (2) |
3) 如果应答者愿意参与计算与发起者的相似度, 却又不希望泄漏个人私有信息(可描述为私有向量), 则可以进行以下计算.
① 发起者Alice和应答者Bob协商n阶矩阵M和常数k, 其中, k < n;
② Alice计算
③ Bob计算
④ Alice计算${Y_A} = \sum\limits_{i = k + 1}^n {{x_{{A_i}}} \cdot {{x'}_{{B_i}}}}$;
⑤ Bob计算
安全性:Alice从
在移动社交网络中, 用户通过分享彼此个性化的特征属性文件(购物爱好、投资兴趣、地理位置、个人健康信息等, 见表 1)有利于找到与自己相同或者相近特征属性的潜在朋友, 从而为进一步交流和交友提供便利.但是在交友过程中, 陌生用户之间互相拥有对方的特征属性信息, 极有可能造成隐私泄漏, 从而增加安全风险.
| Table 1 User profile in mobile social networks 表 1 移动社交网络用户个人属性文档信息 |
3.1 系统模型
在以往的研究模型中, 用户特征属性的隐私安全主要包括以下两个方面.
1) 特征敏感属性的隐私安全:所有参与匹配过程的发起者、应答者, 都不能随意暴露自己和他人的隐私.任何一方无意或者恶意暴露用户隐私都是非法行为[15-18];
2) 通信信道安全:发起者和应答者之间信息交互时, 应当保证通信信道安全, 防止攻击者窃听或者截获交互信息, 造成用户隐私泄漏[19-21].
因此在本方案中, 为保护用户的隐私, 系统模型设计如下.
假设Alice为发起者, Bob和Cindy为应答者, 发起者和应答者的角色可以进行互换, 交友匹配过程如图 1所示.经过第1轮一跳范围内(通信距离)交友匹配过程结束后, 发起人知道与所有应答用户(通信范围内)匹配交集的大小, 而应答者不知道任何发起者的隐私信息.如果发起者有意愿寻找下一跳更匹配的用户, 发起者将第1轮匹配得到最大交集结果(阈值)和发起者经过混淆的个人特征属性配置文件交给代理用户(应答者)进行转发, 由应答者作为代理寻找更远距离的匹配用户, 一旦出现交集大于第1轮的匹配结果, 那么将由代理用户通知发起者, 由代理用户帮助发起者和第2轮的应答用户建立起联系, 如果没有更佳的匹配用户存在, 发起者仍然选择第1轮匹配交集排名最高的应答者进行交友匹配.

|
Fig. 1 Profile matching model in mobile social networks 图 1 移动社交网络匹配过程模型图 |
3.2 攻击模型
目前, 国内外研究交友匹配过程中的隐私保护, 均假设存在两种攻击者.
1) 内部攻击者, 也称为诚实而好奇的攻击者(honest-but-curious)[22]
在匹配过程中, 内部攻击者诚实地遵守双方协议, 通常不破坏协议流程, 但是试图从获取的信息中通过用户行为分析[23]来获得用户更多的隐私信息(例如:通过用户每天的消费习惯来推测用户的信用额度, 或者通过用户关注的医疗健康信息来了解用户的身体状况).
2) 外部攻击者, 也称为恶意攻击者(malicious model)攻击模型[24, 25]
外部攻击者通常不遵守协议流程, 采用暴力或非法窃取合法交友用户的信息来访问未获授权的信息; 监听合法交友用户通信信道并进行破解; 截获合法交友用户的通信信息, 进行伪装和篡改后再重传给接收者, 从而阻止资源的合法管理等.在本文中, 通过窃听、暴力攻击等手段的非法授权用户都属于外部攻击者.
为了进一步明确模型中的工作角色, 本方案假设发起者Alice是完全可信的, 应答者Bob, Cindy是诚实而好奇的, 即Bob, Cindy等应答者会按照既定协议工作, 但是不排除他们试图从获取的信息中采用用户行为分析等技术手段去窥视用户更多的隐私信息.而网络中存在的恶意攻击者是完全不可信的, 即恶意攻击者有可能通过膨胀攻击、暴力推测[26-28]等方法来非法访问未经授权的数据.因此用户在网络信道上传输隐私数据之前, 需要对数据进行利用大素数混淆处理.
3.3 安全模型一般来说, 要获得更高的隐私安全, 那么在通信效率和计算效率上就要付出更高的计算代价.因此, 针对移动社交网络的真实需求, 本文的安全目标拟达到定义1、定义2来保证用户之间的隐私.
定义1(抵御内部攻击者). 匹配完成时, 交友匹配双方仅仅知道彼此之间是否存在交集(共同属性), 以及如果存在交集, 发起者还应知道应答者与自身具体匹配的属性.除此之外, 匹配双方均不知道对方与共同属性无关的其他任何信息.
定义2(抵御外部攻击者). 匹配完成时, 假设外部攻击者拦截到交互过程中的消息, 外部攻击者也无法将这些消息进行解密恢复消息明文.如果外部攻击者存在身份伪装欺骗等恶意行为, 那么用户能够快速识别.
基于定义1、定义2, 本文的安全目标应能够确定信息是否来源于合法交友用户, 应答者能够确定所获得的信息在传输过程中是否被篡改, 用户的隐私信息在整个匹配过程中能够保证其隐私性、完整原子性、可验证性和不可抵赖性.
4 方案设计方案包括以下4个阶段:系统初始化阶段, 矩阵混淆和权重变换阶段, 用户属性匹配阶段, 分布式计算代理寻找最优匹配阶段.本文的详细匹配过程如图 2、图 3所示.

|
Fig. 2 Multi-hops profile matching model in mobile social networks (Ⅰ) 图 2 移动社交网络多跳匹配过程模型图(Ⅰ) |

|
Fig. 3 Multi-hops profile matching model in mobile social networks (Ⅱ) 图 3 移动社交网络多跳匹配过程模型图(Ⅱ) |
4.1 系统初始化阶段
假设应用开发者在交友APP中定义了一系列个人属性可供用户选择, 例如q个属性可分别对应q个用户特征向量{I1, I2, …, Iq}, 用户可选择其中自身感兴趣的m个属性m∈q, 以及对某种属性的偏好程度(个人属性兴趣权重).属性权重可以由整数i进行表示, i∈[1, n], n可根据实际应用场景对某种属性的偏好程度进行细粒度的设置.
当一个发起者Alice有意寻找他/她邻近范围内的潜在交友用户时, Alice首先选择一定数目的属性
假设用户拥有3个属性, 对应矩阵的第1列~第3列, 分别为看电影、游泳和购物; 假设Alice对看电影的偏好程度为4级, 那么需要将矩阵a41的元素置为“1”, 而该列的其他元素则设为“0”; 同理, 如果Alice对游泳的兴趣爱好为1, 购物的兴趣爱好为5, 那么Alice的个人属性配置矩阵可表示为
| $M{A_{m \times n}} = \left[ {\begin{array}{*{20}{c}} {{a_{11}}}&{{a_{12}}}&{...}&{{a_{1n}}} \\ {{a_{21}}}&{{a_{22}}}&{...}&{{a_{2n}}} \\ {...}&{...}&{...}&{...} \\ {{a_{m1}}}&{{a_{m2}}}&{...}&{{a_{mn}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} 0&1&0 \\ 0&0&0 \\ 0&0&0 \\ 1&0&0 \\ 0&0&1 \end{array}} \right].$ |
直观地, 如果用户直接将MAm×n发送给周围参与匹配的交友用户.如果这些用户存在攻击者, 那么攻击者就可以掌握用户所有的特征属性, 从而造成用户隐私泄漏.
因此, 为保证用户隐私安全, 本文基于大数分解困难以及非方阵求逆复杂问题, 利用大素数对矩阵元素进行信息混淆, 同时利用单位矩阵对Alice的矩阵行向量(权重信息)进行转换.转换规则由用户自身掌握, 转换的目的可以有效保证用户配置文件即使被泄漏, 攻击者依然不能对矩阵权重元素进行信息对应, 从而可以抵制攻击者复制Alice配置文件副本对Alice进行膨胀攻击.为简化描述计算过程, 本文此后的MAm×n矩阵均用2行3列矩阵进行表示.
4.2 矩阵混淆和权重变换阶段在本节中, Alice通过随机产生的大素数α, β与两个随机产生的矩阵MCm×n, MRm×n对MAm×n中的元素进行混淆, 同时, 随机生成经过行变换的单位矩阵MIm×m, 用来对MAm×n矩阵的权重属性进行变换.密钥
本步骤结束后, 发起者将经过混淆的矩阵
| $Ms{g_{I2R}} = \{ MA_{m \times n}^ * , I{D_{{\rm{Alice}}}}, H(I{D_{{\rm{Alice}}}}), {\rm{\Delta }}t, {t_1}\} $ | (3) |
IDAlice代表发起者身份特征; H(·)是一个公开的哈希函数, H(IDAlice)代表Alice身份特征的哈希值; Δt代表时间戳, 用于抵抗重放攻击.为简单描述计算过程, 假设用户Alice的属性矩阵
算法1. 发起者属性矩阵初始混淆算法.
Input:发起者Alice构造属性矩阵MAm×n, MAm×n≠$\emptyset $, m≠n;
Output:生成混淆矩阵
1. Alice构造矩阵MAm×n;
2. Alice随机选择两个大素数α, β, 其中, β > (n+1)m2α2;
同时, 随机生成两个大素数矩阵MCm×n, MRm×n, 生成元素随机, 并且≠α, β;
3. MAm×n中的每一个元素分别乘以cij, rij, ∀cij∈MCm×n, ∀rij∈MRm×n(1≤i≤m, 1≤j≤n), 同时, cij远远小于大素数α;
4. for i=1; i≤m; i++ do
5.
6. for j=1; j≤n; j++ do
7. if maij==1 then
8. maij=α+cij+rij×β
9. else
10. maij=cij+rij×β
11. end if
12. ki=ki+(rijβ-cij);
13. end for
14.end for
15.生成一个单位矩阵MIm×m, 用来对MAm×n矩阵的权重属性进行变换.
16.
17. Return
| $M{A_{m \times n}} = \left[ {\begin{array}{*{20}{c}} {\alpha + {c_{11}} + {r_{11}}\beta }&{{c_{12}} + {r_{12}}\beta }&{\alpha + {c_{13}} + {r_{13}}\beta } \\ {{c_{21}} + {r_{21}}\beta }&{\alpha + {c_{22}} + {r_{22}}\beta }&{{c_{23}} + {r_{23}}\beta } \end{array}} \right]$ | (4) |
那么经过行初等变换的矩阵为
| $MA_{_{m \times n}}^* = \left[ {\begin{array}{*{20}{c}} {{c_{21}} + {r_{21}}\beta }&{\alpha + {c_{22}} + {r_{22}}\beta }&{{c_{23}} + {r_{23}}\beta } \\ {\alpha + {c_{11}} + {r_{11}}\beta }&{{c_{12}} + {r_{12}}\beta }&{\alpha + {c_{13}} + {r_{13}}\beta } \end{array}} \right].$ |
| $\vec K = \left( {\sum\limits_{j = 1}^3 {{r_{1j}}\beta - {c_{1j}}} , \sum\limits_{j = 1}^3 {{r_{2j}}\beta - {c_{2j}}} } \right)$ | (5) |
例如:k1=(r11β-c11)+(r12β-c12)+(r13β-c13).
4.3 用户属性匹配阶段 4.3.1 矩阵相乘假设应答者Bob(或者其他应答者)接收到发起者的查询信息MsgI2R, 并且有意与发起者Alice进行交友, 那么Bob将对Alice的身份信息进行数据完整性验证.
首先, Bob计算消息在接收时刻t2减去发送时刻t1是否小于Δt来对抗重放攻击; 同时, 利用公开的哈希函数H(·)对IDAlice进行哈希, 并与MsgI2R中H(IDAlice)进行比较, 如果值相等, 说明信息在传递过程中身份信息IDAlice没有被攻击者篡改.
其次, Bob根据自身属性配置文件
在计算过程中, 当两个矩阵拥有交集的时候, 算法将对应矩阵元素乘积设置为1, 否则设置为0.算法结束后, Bob将获得一个新矩阵MDm×m:
| $M{D_{m \times m}} = MA_{m \times n}^* \times MB_{m \times n}^T = {({d_{ij}})_{m \times m}}$ | (6) |
最后, Bob将MDm×m组成应答消息MsgI2R发送给Alice, 发送的消息为
| $M s g_{I 2 R}=\left\{M D_{m \times m}, I D_{\mathrm{Bob}}, H\left(I D_{\mathrm{Bob}}\right), \Delta t\right\} $ | (7) |
算法2.应答者矩阵相乘算法.
Input:
Output:生成新矩阵MDm×m=(dij)m×m.
1. Bob根据自身兴趣爱好生成MBm×n, 并计算$M D_{m \times m}=M A_{m \times n}^{*} \times M B_{m \times n}^{T}$;
2. for i=1; i≤m; i++ do
3. for j=1; j≤n; j++ do
4. temp=0;
5. for q=1; q≤n; q++ do
6. if mbjq==1 then
7.
8. else
9.
10. dij=temp;
11. end if
12. end if
13. end if
14. end if
15.Return MDm×m
为简单描述计算过程, 假设
| $M{D_{m \times m}} = MA_{m \times n}^* \times MB_{m \times n}^T = \left[ {\begin{array}{*{20}{c}} {a_{11}^*}&{a_{12}^*}&{a_{13}^*} \\ {a_{21}^*}&{a_{22}^*}&{a_{23}^*} \end{array}} \right]{\left[ {\begin{array}{*{20}{c}} {{b_{11}}}&{{b_{12}}}&{{b_{13}}} \\ {{b_{21}}}&{{b_{22}}}&{{b_{23}}} \end{array}} \right]^T} = \left[ {\begin{array}{*{20}{c}} {{d_{11}}}&{{d_{12}}} \\ {{d_{21}}}&{{d_{22}}} \end{array}} \right]$ | (8) |
推导过程如下:
| $\begin{array}{l} {d_{11}} = ({c_{21}} + {r_{21}}\beta ) + (\alpha + {c_{22}} + {r_{22}}\beta ) + \alpha ({c_{23}} + {r_{23}}\beta );\\ {d_{12}} = \alpha ({c_{21}} + {r_{21}}\beta ) + \alpha (\alpha + {c_{22}} + {r_{22}}\beta ) + ({c_{23}} + {r_{23}}\beta );\\ {d_{21}} = (\alpha + {c_{11}} + {r_{11}}\beta ) + ({c_{12}} + {r_{12}}\beta ) + \alpha (\alpha + {c_{13}} + {r_{13}}\beta );\\ {d_{22}} = \alpha (\alpha + {c_{11}} + {r_{11}}\beta ) + \alpha ({c_{12}} + {r_{12}}\beta ) + (\alpha + {c_{13}} + {r_{13}}\beta ). \end{array}$ |
Alice接收到Bob的信息MsgI2R后, 将利用单位矩阵MIm×m的逆矩阵
| $M{T_{m \times m}} = MI_{m \times m}^{ - 1} \times M{D_{m \times m}} = \left[ {\begin{array}{*{20}{c}} {{T_{11}}}&{{T_{12}}} \\ {{T_{21}}}&{{T_{22}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} 0&1 \\ 1&0 \end{array}} \right]\left[ {\begin{array}{*{20}{c}} {{d_{11}}}&{{d_{12}}} \\ {{d_{21}}}&{{d_{22}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {{d_{21}}}&{{d_{22}}} \\ {{d_{11}}}&{{d_{12}}} \end{array}} \right]$ | (9) |
推导过程如下:
| $\begin{array}{l} {T_{11}} = ({d_{21}} + {k_1})\bmod \beta \\ {\rm{\;\;\;\;\;}} = \{ (\alpha + {c_{11}} + {r_{11}}\beta ) + ({c_{12}} + {r_{12}}\beta ) + \alpha (\alpha + {c_{13}} + {r_{13}}\beta ) + {k_1}\} \bmod \beta \\ {\rm{\;\;\;\;\;}} = \{ (\alpha + {c_{11}} + {r_{11}}\beta ) + ({c_{12}} + {r_{12}}\beta ) + \alpha (\alpha + {c_{13}} + {r_{13}}\beta ) \\ + ({r_{11}}\beta - {c_{11}}) + ({r_{12}}\beta - {c_{12}}) + ({r_{13}}\beta - {c_{13}})\} \bmod \beta \\ {\rm{\;\;\;\;\;}} = \{ [(\alpha + {c_{11}} + {r_{11}}\beta ) + ({r_{11}}\beta - {c_{11}})] + [({c_{12}} + {r_{12}}\beta ) + ({r_{12}}\beta - {c_{12}})] + [\alpha (\alpha + {c_{13}} + {r_{13}}\beta ) \\ + ({r_{13}}\beta - {c_{13}})]\} \bmod \beta \\ {\rm{\;\;\;\;\;}} = \{ [\alpha + 2{r_{11}}\beta ] + 2{r_{12}}\beta + {\alpha ^2} + (\alpha + 1){r_{13}}\beta + (\alpha - 1){c_{13}}\} \bmod \beta \\ {\rm{\;\;\;\;\;}} = \{ [{\alpha ^2} + \alpha + (\alpha - 1){c_{13}}] + [2{r_{11}} + 2{r_{13}} + (\alpha + 1){r_{13}}]\beta \} \bmod \beta \\ {\rm{\;\;\;\;\;}} = {\alpha ^2} + \alpha + (\alpha - 1){c_{13}}. \end{array}$ |
得到T11值之后, 将利用模运算对T11进行归一化, 得到
| $T_{11}^* = \frac{{{T_{11}} - ({T_{11}}\bmod {\alpha ^2})}}{{{\alpha ^2}}} = \frac{{{T_{11}}}}{{{\alpha ^2}}} - \frac{{{T_{11}}\bmod {\alpha ^2}}}{{{\alpha ^2}}} = \frac{{{\alpha ^2} + \alpha + (\alpha - 1){c_{13}}}}{{{\alpha ^2}}} - \frac{{[{\alpha ^2} + \alpha + (\alpha - 1){c_{13}}]\bmod {\alpha ^2}}}{{{\alpha ^2}}} = 1 - \frac{1}{{{\alpha ^2}}} \approx 1$ | (10) |
因为α, β为一个大素数, 同时在算法1中, 定义Cij远远小于大素数α, 因此可得到α+(α-1)c13 < α2, 所以
通过以上步骤, 可以获得两个矩阵的相似度矩阵为
在Alice接收到Bob或者其他应答者反馈的消息MDm×m=(dij)m×m的同时, Alice将根据MDm×m矩阵元素下标构造一个权重矩阵(Wij)m×m来恢复原矩阵的权重关系, 该权重矩阵用来描述发起者和应答者特征属性之间的关系, 也是为进行矩阵内积计算而得到两者之间的相似度.根据权重映射关系(对角线上的元素相似度最大), 同时为保证权重之间的差异化, 设计具体权重转换公式:
| ${({W_{ij}})_{m \times m}} = \left\{ {\begin{array}{*{20}{l}} {m + {i^2}, {\rm{ }}i = j} \\ {m + j - i, {\rm{ }}i - j > 0} \\ {m - j + i, {\rm{ }}i - j < 0} \end{array}} \right.$ | (11) |
根据公式(11), 可求得矩阵MDm×m权重关系为
根据权重关系Wij与相似度矩阵MT对应元素内积计算, 可以精确计算发起者和应答者相似度值Similary, 其中, “●”代表内积.
假设存在另外一个应答者Cindy, 其个人属性矩阵为
| $Similar{y_{Cindy}} = MTW = \left[ {\begin{array}{*{20}{c}} 2&0\\ 1&0 \end{array}} \right]\left[ {\begin{array}{*{20}{c}} 1&1\\ 1&4 \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {2 \times 1}&{0 \times 1}\\ {1 \times 1}&{0 \times 4} \end{array}} \right] = 2 + 0 + 1 + 0 = 3. $ |
通过比较发现, Bob与Alice的特征属性更相似.类似地, Alice就可以从所有的应答者中选择相似度值最大的用户作为其自身的匹配用户.
算法3.特征属性相似度(交集)计算算法.
Input:(Wij)m×m, MDm×m=(dij)m×m;
Output:通过安全内积计算出用户之间相似度λ.
1. Alice计算
2. Alice计算mtij=(ki+dij) mod β; $\forall m t_{i j} \in M T_{m \times n}$;
3. Alice进一步计算$m t_{i j}=\frac{m t_{i j}-\left(m t_{i j} \bmod \alpha^{2}\right)}{\alpha^{2}}$;
4. Alice计算
5. Return $\lambda = \sum\limits_{i = 1}^m {\sum\limits_{j = 1}^m {{h_{ij}}} }.$
4.4 分布式计算代理寻找最优匹配阶段完成步骤4.3, Alice将知道在她一跳范围内最匹配的交友用户.但是在实际的情况中, 有可能在应答者的下一跳会出现与Alice特征属性更匹配的用户, 因此本文假设第1轮的应答者Bob作为代理转发Alice的配置文件和第1轮所有应答用户最大相似度的值λmax.为减少代理和发起者的通信开销, 本方案设计只有相似度值大于λmax的用户才能够得到返回.同时, 为了避免过大的通信开销和计算时间消耗, Alice可以选择代理转发的跳数.通过这种方法, 发起者重新与新的最佳应答者(代理的下一跳的用户)建立起通信会话, 从而找到更适合自己的交友用户, 具体过程见图 3和算法4.
算法4.分布式计算代理寻找最优匹配算法.
Input:
Output:选择最匹配的用户.
1.代理用户(Bob)转发发起者配置文件, 由代理用户和其下一跳进行计算, 算法过程和算法1~算法3相同
2.代理得到他们下一跳应答者最大的匹配值λ'max
3. ${\lambda _{\max }} = Swap({\lambda _{\max }}, {\lambda '_{\max }})$
4. if $({\lambda _{\max }} < {\lambda '_{\max }})$
5. temp=λmax
6 ${\lambda _{\max }} = {\lambda '_{\max }}$
7. ${\lambda '_{\max }} = temp$
8. end if
9. Return λmax
5 安全与机会分析本节将分别考虑针对恶意攻击和诚实而好奇攻击情况下对本方案的安全性进行证明, 着重讨论发起者与应答者之间的隐私保护.为简化描述, 假设Bob是Alice最佳匹配者.
5.1 安全分析 5.1.1 抵御外部攻击者膨胀攻击和暴力攻击挑战1.攻击者可以攻击用户之间的通信信道, 如果攻击者可以成功截获用户之间的通信密文, 并能够将此密文恢复成明文, 那么攻击者将赢得这个挑战.
引理1. 本方案可以成功抵御外部恶意攻击者的膨胀攻击.
证明:假设外部攻击者可以窃听用户Alice和应答者Bob之间的通信过程, 并且拦截到Alice与Bob的消息
另外, 因为攻击者不是合法用户, 所以攻击者并不知道Bob的计算规则(算法2), 因此伪造的
引理2. 本方案可以成功做到抵御外部者恶意攻击者的暴力推测.
证明:假设攻击者利用背景知识或者其他攻击手段试图推导用户更多的隐私, 攻击者可根据用户的特征属性、兴趣爱好、地理位置等构造攻击字典, 并试图利用攻击字典来暴力破解用户的隐私.但是根据腾讯微博调查结果显示:移动社交网络中用户的特征属性具有多样化的特征, 普通社交用户至少拥有11个特征属性来细粒度地表示自己的兴趣爱好等.在本方案中, 如果每个属性有10个权重, 那么暴力攻击者试图分析出用户的真实属性, 将至少会有
挑战2. 假设Bob是内部攻击者, 彼此试图通过接收到的信息
引理3. 本协议可以成功保护发起者的隐私.
证明:发起者Alice根据自身特征属性, 编码混淆矩阵
为衡量真实移动社交网络中交友匹配的参与用户, 本文模拟在时间t内将参与人作为代理, 为满足交友计算需求能够提供的有效计算资源数.
引理4. 在[0, t]时间内, 所有用户可以提供预期总计算资源为$E\{ R(t)\} = \frac{{\lambda {t^2}p\eta }}{2}.$
证明:假设所有用户可以提供预期总资源E{R(t)}为1, 那么:
| $E\{ R(t)\} = \sum\nolimits_0^\infty {(P\{ {N_q}(t) = n\} E\{ R(t)|{N_q}(t) = n\} )} =\\ \sum\nolimits_0^\infty {P\{ {N_q}(t) = n\} } \cdot \frac{{nt\eta }}{2} = \frac{{t\eta }}{2} \cdot E({N_q}(t)) = \frac{{\lambda {t^2}p\eta }}{2} = 1.$ |
根据E(Nq(t))=λtp, 单个用户提供的计算资源为E(rq(t))=E{R(t)}/λtp, 并满足
根据真实应用场景需求, 将时间考虑在60s、120s、180s、240s、300s的参与人数和单个用户提供的计算资源, 计算模型仿真结果如表 2和图 4所示.
| Table 2 Provide resource expectation 表 2 提供资源预期 |
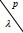

|
(a)设定阈值为P=0.4时, 所有代理用户预计提供的资源预期(b)设定阈值为P=0.8时, 所有代理用户提供的资源预期 Fig. 4 Opportunity calculation model 图 4 机会计算参与人数和提供资源模型图 |
从图 4(a)、图 4(b)可以看出:总资源一定的情况下, 在移动社交活动稀疏时刻, 计算资源闲置时, 可通过降低参与计算应答者的概率p, 做到增加社交交友的参与人数E(Nq(t)), 从而促进社交活动更有效地开展.
6 性能分析 6.1 复杂度分析 6.1.1 计算开销在本节中, 将与现有研究工作进行计算开销的对比分析, 对于计算开销, 本文主要考虑方案中乘法运算和加法运算的次数.
本文采用exp1标识1 024位的求幂操作, exp2标识2 048位的求幂操作, add表示模加运算, mul1, mul2分别表示1 024位和2 048位的乘法运算.详细比较结果见表 3.
| Table 3 Computation cost 表 3 计算数据开销 |
表 3中, 因为本文协议采用矩阵运算和大素数混淆运算, 发起用户在离线状态时, 仅需要将原始矩阵与混淆矩阵相乘, 再利用随机行变换矩阵进行混淆, 因此需要2m·n·mul1的计算开销.矩阵相乘后对矩阵运算进行相加计算, 需要3m·n·add的计算开销, 所以发起者离线状态下的总计算开销为2m·n·mul1+3m·n·add, 见算法1.与离线状态下WAS与Fine-grained方案均采用了较复杂exp1指数运算对比, 显然更有优势.
同时, 在发起用户在线阶段, 需要进行2次乘法运算和3次加法运算, 见算法3.因此, 总计算开销为2·m·m·mul1+3·m·m·add; 而应答用户则需要m·m·n·mul1+m·m·n·add的计算开销, 见算法2.相比WAS与Fine- grained方案, 本方案计算开销更小.
6.1.2 通信开销在本节中, 将与现有研究工作进行通信开销的对比分析.通信开销通常是由协议中的通信次数或者协议中发送的比特位数来决定.
假设每个用户的属性个数和属性权重分别是n和m, 接收和发送数量用比特位数进行计算.在用户信息交互过程中, 发起者仅仅需要将自身矩阵大小乘以可变密钥长度, 所以通信开销为m·n·k; 而应答者因为在多跳阶段需要承担交友配置文件的转发任务, 因此通信开销为2·m·n·k.
本方案因为采用可变密钥k, 因此可适用不同的安全需求场景.在安全性需求较高的情况下, 用户可以选择较长的可变密钥k; 在安全性需求较低的情况下, 用户可以选择较短的可变密钥k.与WAS和Fine-grained协议使用固定长度1 024bit和2 048bit的密钥相比, 显然更为灵活高效.
6.2 模拟实验和仿真结果在本文的测试环境中, 利用小米手机NOTE版进行群组测试.编程环境使用Eclipse, 利用Java作为编程语言进行代码开发.硬件条件为:CPU骁龙™ 8X74AC 801处理器, 主频2.5GHz, 使用LPDDR3 933MHz 3G高速内存, 支持蓝牙4.0和Wi-Fi双频.
开发库为(java.math.BigInteger/java.util.Arrays/java.util.Random), 用户特征属性(兴趣爱好)利用爬虫代码从社交网站进行抓取并进行处理.
考虑用户实际应用对数据安全的差异性需求, 本文分别采用64位、128位、256位的大素数作为密钥进行实验, 同时采用不同数目的权重和不同数目的属性对算法进行了对比分析.
图 5(a)~图 5(d)分别显示密钥长度为64位、128位、256位在线计算开销和离线计算开销在不同权重和属性影响下的评价结果.离线计算开销表示发起者构造

|
Fig. 5 Initiator offline and online computation cost 图 5 发起者离线计算和在线计算开销图 |
同时, 从图 5中可以看出:在线计算的时间以μs为单位, 而离线计算的计算时间以ns为单位, 这个时间对于进行移动社交网络交友的用户几乎可以忽略不计, 很好地保证了在交友过程中的用户体验.
图 6(a)、图 6(b)分别表示权值和属性变化时对计算总时间的影响.当权值和属性个数发生改变时, 相较于权值的改变, 属性个数改变对计算总时间产生更大的影响, 这也符合真实移动社交网络交友匹配的情景.因为通常在交友活动中, 用户希望提供更细粒度的属性选择, 以便更精确地匹配.特别地, 在图 7(a)中, 当属性值依次从10~100依次进行递增, 执行总时间相差并不大.在图 7(b)中, 属性保持10个可选属性, 密钥长度使用256位的大素数加密时, 依然能保持很好的用户体验.

|
Fig. 6 Attributes and weights change execution cost 图 6 属性和权重分别变化执行总时间图 |

|
Fig. 7 Initiator and responder communication cost 图 7 发起者和应答者的通信开销 |
图 7(a)、图 7(b)分别表示发起者和应答者的通信开销.本文假设扩大1倍的通信范围去寻找与发起者更匹配的用户, 图 7(a)表示权重固定为10, 属性数目依次递增发起者的通信开销, 横坐标表示属性数目.图 7(b)表示应答者通信开销, 横坐标表示权重, 通过与表 4中其他协议比较发现:即使本文提出的方案扩大了通信范围, 因为采用代理承担通信负载, 因此通信效率得到了提高.由此可得出结论:本文在扩大交友匹配范围的同时, 通信消耗并没有明显的级数增长, 依然是线性的.
| Table 4 Communication cost 表 4 通信数据开销 |
同时, 在移动社交网络中, 运行安装在移动终端上的APP的能耗也是一个重要的考虑因素.本文通过参考文献[8], 利用能耗计算公式E=Nt·Et+Nr·Er进行了计算, 其中, Nt, Nr分别代表传输数据和接受数据.根据每比特的发送能量消耗Et≈4.8μJ和接收能量消耗Er≈6.7μJ, 为简单描述, 本文仅仅选取权重属性作为能量消耗的参考因素进行对比, 得出如下的计算结果, 如图 8所示.

|
Fig. 8 Initiator and responder energy consumption 图 8 发起者和应答者能量消耗图 |
通过全面的对比分析, 本方案与传统的利用对称加密、非对称加密技术进行社交交友方案相比较, 在计算开销、通信开销和能量消耗上均有较明显的优势.最后, 本文在方法的适应性上与其他协议进行了比较, 可以发现, 本方案更具有通用性(见表 5).
| Table 5 Adaptability comparison of typical privacy preserving methods in mobile social networks 表 5 移动社交网络典型隐私保护方法适应性比较 |
7 结束语
在移动社交网络中, 最大化增强彼此之间的联系和交流, 同时又保护用户的个人隐私问题, 是当前隐私保护方向的一个研究热点.本文基于数论基础, 提出不依赖TTP可信服务器轻量级的矩阵混淆和多跳代理方案, 实现了移动社交网络交友匹配的隐私保护.在计算量上没有使用复杂的双线性对和指数运算, 只使用了计算开销较小的哈希函数运算、取模运算和内积计算等.该方案提高了移动社交网络中用户的交友效率, 使用户能够迅速发现邻近范围内与发起者属性匹配的用户, 减少了移动终端计算和通信开销.通过机会分析、安全和性能分析, 本文提出的协议可以在终端资源受限的情况下, 让用户更有效、更安全地进行移动社交活动.
| [1] |
Fu YY, Zhang M, Feng DG, Chen KQ. Attribute privacy preservation in social networks based on node anatomy. Ruan Jian Xue Bao/Journal of Software, 2014, 25(4): 768-780(in Chinese with English abstract).
http://www.jos.org.cn/1000-9825/4565.htm [doi:10.13328/j.cnki.jos.004565] |
| [2] |
Zhang L, Li XY, Liu Y. Message in a sealed bottle:Privacy preserving friending in social networks. In:Proc. of the IEEE Int'l Conf. on Distributed Computing Systems (ICDCS)., 2013, 327-336.
[doi:10.1109/ICDCS.2013.38] |
| [3] |
Wang Y, Vasilakos AV, Jin Q. Survey on mobile social networking in proximity (MSNP):Approaches, challenges and architecture. Wireless Networks, 2013, 20(6): 1295-1311.
[doi:10.1007/s11276-013-0677-7] |
| [4] |
Guo L, Zhang C, Sun J. A privacy-preserving attribute-based authentication system for mobile health networks. IEEE Trans. on Mobile Computing, 2014, 13(9): 1927-1941.
[doi:10.1007/s11276-013-0677-7] |
| [5] |
Guo L, Zhu X, Zhang C. Privacy-preserving attribute-based friend search in geosocial networks with untrusted servers. In:Proc. of the IEEE Int'l Conf. on Global Communications (GLOBALCOM)., 2013, 629-634.
[doi:10.1109/GLOCOM.2013.6831142] |
| [6] |
Lu R, Lin X, Liang X, Shen X. A secure handshake scheme with symptoms-matching for mHealthcare social network. Mobile Networks and Applications, 2011, 16(6): 683-694.
[doi:10.1007/s11036-010-0274-2] |
| [7] |
Sarpong S, Xu C. A secure and efficient privacy-preserving attribute matchmaking protocol in proximity-based mobile social networks. In:Proc. of the Advanced Data Mining and Applications., 2014, 305-318.
[doi:10.1007/978-3-319-14717-8_24] |
| [8] |
Li M, Cao N, Yu S, Lou W. Findu:Privacy-preserving personal profile matching in mobile social networks. In:Proc. of the IEEE Int'l Conf. on Computer Communications (INFOCOM)., 2011, 2435-2443.
[doi:10.1109/INFCOM.2011.5935065] |
| [9] |
Yan Z, Ding W, Niemi V. Two schemes of privacy-preserving trust evaluation. Future Generation Computer Systems, 2015, 62(C): 175-189.
[doi:10.1016/j.future.2015.11.006] |
| [10] |
Kiraz MS, Genc ZA, Kardas S. Security and efficiency analysis of the hamming distance computation protocol based on oblivious transfer. Security & Communication Networks, 2015, 8(18): 4123-4135.
[doi:10.1002/sec.1329] |
| [11] |
Zhang R, Zhang J, Zhang Y, Sun J. Privacy-preserving profile matching for proximity-based mobile social networking. IEEE Journal on Selected Areas in Communications, 2013, 31(9): 656-668.
[doi:10.1109/JSAC.2013.SUP.0513057] |
| [12] |
Liao X, Uluagac S, Beyah RA. S-MATCH:Verifiable privacy-preserving profile matching for mobile social services. In:Proc. of the IEEE Int'l Conf. on Dependable Systems and Networks., 2014, 287-298.
[doi:10.1109/DSN.2014.37] |
| [13] |
Yi X, Bertino E, Rao FY. Practical privacy-preserving user profile matching in social networks. In:Proc. of the IEEE Int'l Conf. on Data Engineering., 2016, 373-384.
[doi:10.1109/ICDE.2016.7498255] |
| [14] |
Pattuk E, Kantarcioglu M, Ulusoy H. Optimizing secure classification performance with privacy-aware feature selection. In:Proc. of the IEEE Int'l Conf. on Data Engineering., 2016, 217-228.
[doi:10.1109/ICDE.2016.7498242] |
| [15] |
Jung T, Mao X, Li XY, Tang SW. Privacy preserving data aggregation without secure channel:multivariate polynomial evaluation. In:Proc. of the IEEE Int'l Conf. on Computer Communications (INFOCOM)., 2013, 2634-2642.
[doi:10.1109/INFCOM.2013.6567071] |
| [16] |
Jung T, Li XY, Wan Z, Wan M. Control cloud data access privilege and anonymity with fully anonymous attribute based encryption. IEEE Trans. on Information Forensics and Security, 2015, 10(1): 190-199.
[doi:10.1109/TIFS.2014.2368352] |
| [17] |
Jung T, Li XY. Collusion-tolerable privacy-preserving sum and product calculation without secure channel. IEEE Trans. on Dependable and Secure Computation, 2015, 12(1): 45-57.
[doi:10.1109/TDSC.2014.2309134] |
| [18] |
Jung T, Li XY, Wan Z, Wan M. Privacy preserving cloud data access with multi-authorities. In:Proc. of the IEEE Int'l Conf. on Computer Communications (INFOCOM)., 2013, 2625-2633.
[doi:10.1109/INFCOM.2013.6567070] |
| [19] |
Abawajy J, Ninggal MI, Herawan T. Privacy preserving social network data publication. IEEE Communications Surveys & Tutorials, 2016, 18(3): 1974-1997.
[doi:10.1109/COMST.2016.2533668] |
| [20] |
Yan Z, Ding W, Niemi V. Two schemes of privacy-preserving trust evaluation. Future Generation Computer Systems, 2016, 62(C): 175-189.
[doi:10.1016/j.future.2015.11.006] |
| [21] |
Qian J, Qiu F, Wu F. Privacy-preserving selective aggregation of online user behavior data. 2016. 1.[doi:10.1109/TC.2016. 2595562]
|
| [22] |
Kim M, Mohaisen A, Cheon JH. Private over-threshold aggregation protocols over distributed databases. IEEE Trans. on Knowledge & Data Engineering, 2016, 1.
[doi:10.1109/TKDE.2016.2572686] |
| [23] |
Tsai CH, Liu HW, Ku T. Personal recommendation engine of user behavior pattern and analysis on social networks. In:Proc. of the IEEE Int'l Conf. on Computational Science and Computational Intelligence (CSCI)., 2015, 404-409.
[doi:10.1109/CSCI.2015.46] |
| [24] |
Mishra BK, Jha N. SEIQRS model for the transmission of malicious objects in computer network. Applied Mathematical Modelling, 2010, 34(3): 710-715.
[doi:10.1016/j.apm.2009.06.011] |
| [25] |
Sun J, Zhang R, Zhang Y. Privacy-preserving spatiotemporal matching. In:Proc. of the IEEE Int'l Conf. on Computer Communications (INFOCOM)., 2013, 800-808.
[doi:10.1109/INFCOM.2013.6566867] |
| [26] |
Schweitzer N, Stulman A, Shabtai A. Mitigating denial of service attacks in OLSR protocol using fictitious nodes. IEEE Trans. on Mobile Computing, 2016, 15(1): 163-172.
[doi:10.1109/TMC.2015.2409877] |
| [27] |
Geer DE. Attack surface inflation. IEEE Educational Activities Department, 2011, 9(4): 85-86.
[doi:10.1109/MSP.2011.78] |
| [28] |
Najafabadi MM, Khoshgoftaar TM, Calvert C. Detection of SSH brute force attacks using aggregated netflow data. In:Proc. of the IEEE Int'l Conf. on Machine Learning and Applications (ICMLA)., 2016, 283-288.
[doi:10.1109/ICMLA.2015.20] |
| [29] |
Niu B, Zhu X, Liu J. Weight-aware private matching scheme for proximity-based mobile social networks. In:Proc. of the IEEE Global Communications Conf. (GLOBECOM)., 2013, 3170-3175.
[doi:10.1109/GLOCOM.2013.6831559] |
| [30] |
Zhang R, Zhang R, Sun J. Fine-grained private matching for proximity-based mobile social networking. In:Proc. of the IEEE Int'l Conf. on Computer Communications (INFOCOM)., 2012, 1969-1977.
[doi:10.1109/INFCOM.2012.6195574] |
| [1] |
付艳艳, 张敏, 冯登国, 陈开渠. 基于节点分割的社交网络属性隐私保护. 软件学报, 2014, 25(4): 768-780.
http://www.jos.org.cn/1000-9825/4565.htm [doi:10.13328/j.cnki.jos.004565] |