 2018, Vol. 29
2018, Vol. 29



2. 中国科学院 软件研究所 协同创新中心, 北京 100190;
3. 北京工业大学 计算机学院, 北京 100124
2. Collaborative Innovation Center, Institute of Software, The Chinese Academy of Sciences, Beijing 100190, China;
3. School of Computer, Beijing University of Technology, Beijing 100124, China
搭载有定位模块(例如北斗、GPS、GSM、WIFI和蓝牙等)的智能终端不断普及, 使得随时随地获得个人位置信息成为可能, 从而产生了轨迹大数据, 并在基于位置的服务中得到了广泛应用, 例如现代交通管理、智能导航、位置推荐等.路网匹配(即将轨迹配准到道路交通网络)是此类应用不可缺少的关键模块, 而精确的路网匹配对提高服务质量起到了至关重要的作用.
然而, 受建筑物遮挡、定位模块错误、低能耗的模块设计、多模式和多样化精度的定位技术等因素的影响, 大部分轨迹的采样率较低.社交网络的签到和其他位置共享服务(例如Weibo、Facebook、Twitter等)也仅能提供低采样的轨迹.相似的低采样轨迹也可能来自具有位置标签的图片(例如Flickr、Panoramio)和稀疏的道路监控获取的车辆快照, 此类位置序列也形成了低采样轨迹.低采样轨迹的两个相邻采样点分别匹配到道路交通网络中不相邻的边, 补全轨迹实际经过的所有中间缺失边而构成完整的路径, 是本文研究的主要内容.
如图 1所示, p1和p2是轨迹中的两个相邻采样点, 分别匹配到路网中不相邻的边e1和e13, 然而难以确定轨迹实际采用的真实路径.可能的路径是P1~P4中的某一条, 查找出具体的路径称为路网匹配或路径推理.

|
Fig. 1 Low-Sampling trajectory and its possible paths 图 1 低采样轨迹及其可能路径 |
已有路网匹配方面的研究大多仅考虑单属性道路交通网络, 比如仅考虑旅行距离[1]、旅行时间[2, 3]或路径频繁度[4].然而在实际的路径规划中存在着多重属性, 不再是单一属性的最短路径、最快路径、最频繁路径或最省油路径, 而是多个属性的权衡(比如以权重将多属性线性组合为单一属性且组合后的属性代价最优, 或选择至少在某个属性上比其他所有路径优的路径).例如, 在旅行距离和旅行时间双属性道路交通网络中, 一个用户的旅行距离和旅行时间权重分别为0.3和0.7, 这表明该用户喜爱较短的旅行时间; 而另一个用户的旅行距离和旅行时间权重分别为0.8和0.2, 表明他更喜爱较短的旅行距离.这两个用户选择了不同路径, 但产生同样的低采样轨迹, 那么该轨迹将匹配到不同的路径.然而, 已有工作由于忽略了轨迹产生者之间的个性化差异, 最终把属于两个用户的相似轨迹匹配到相同路径, 而产生较大的误差.为了解决该问题, 本文将构建多属性路网中的用户偏好模型, 从而体现用户在路径规划时的个性化差异.
如图 1所示, 路径P1~P4都有可能是连接低采样轨迹相邻采样点p1和p2匹配到的边e1和e13, 从而构成轨迹的完整路径.然而, 作为旅行距离和旅行时间的均衡路径P2与最快路径P1、最短距离路径P3和最省油路径P4差异较大, 不同用户可能选择不同路径.已有研究表明, 来自不同用户的相似的低采样轨迹, 根据路网匹配考虑的属性代价区别, 最终可能匹配到的路径有所不同[1-4].
一般来讲, 在多属性路网中的每条路径都对应一个多属性的综合权重, 如图 1所示路径P2在双属性路网中(即旅行距离和旅行时间), 两者的权重分别为0.5和0.5.大部分用户在路径规划时不再选取单一属性最优[5], 而是在多属性之间权衡, 得到Skyline或Pareto路径.若用户知道了基本的路网代价, 就倾向于不去选择所有旅行代价都比其他路径要弱的路径(非优化路径).
本文提出在动态多属性道路交通网络中, 从用户所有历史高采样轨迹中学习出用户驾驶偏好, 并以多目标优化或数据分析中普遍使用的Skyline或Pareto技术指导路网匹配, 解决了现有路网匹配算法忽略用户个性化驾驶行为的不足.
本文研究了基于偏好的个性化路网匹配问题, 主要贡献如下所示.
● 驾驶偏好模型.根据以往路径规划数据构造了细粒度的驾驶偏好概率模型.
● 多目标优化.在低采样轨迹路网匹配中引入多目标优化方法, 即局部匹配为某条Skyline路径.
● 路网匹配精度有大幅度提升.我们在真实数据集上做了充分的实验, 实验结果表明, 所提出的方法比已有方法在相邻采样点采样时间间隔为20min时, 保证路网匹配精度不低于65%.
本文第1节介绍相关工作.第2节给出问题描述.第3节引入细粒度驾驶偏好模型.第4节提出两阶段路网匹配算法:局部匹配和全局匹配.第5节描述在真实数据集合上的实验.第6节总结全文.文中用到的主要符号见表 1.
| Table 1 A list of notations 表 1 符号列表 |
1 相关工作
路网匹配算法按照是否需要其他轨迹协助, 分为无依赖的单轨迹路网匹配和有依赖的多轨迹协同路网匹配.单轨迹路网匹配算法又可分为基于几何结构[6, 7]、网络拓扑结构[6-10]、统计[1, 10-13]的路网匹配算法.其中, 基于几何结构的路网匹配主要考虑轨迹采样点或采样序列与道路交通路网中边的几何形状之间的关系, 如Point- to-Point路网匹配算法[6]、Point-to-Curve路网匹配算法[6]和Curve-to-Curve路网匹配算法等[6, 14, 15]; 基于网络拓扑结构的路网匹配算法综合了道路交通路网中边的连接性、旅行时间和旅行距离等因素[7-9].把基于几何的方法和基于网络拓扑的方法结合起来设计新的路网匹配算法[6, 7].在基于统计的路网匹配算法中, 首先要计算每个采样点的候选匹配边或顶点集合, 并为每个匹配赋予一个和采样点与匹配元素间欧式距离或路网拓扑旅行代价相关的权重, 代表算法有ST-matching[11]和IVMM[10], 然而这两种算法对于过低采样的轨迹路网匹配效果较差, 在时间复杂度方面, 假设低采样轨迹GPS长度为n, 匹配用路网有m条边, 每个采样点相邻的候选边数量为k, 则ST-matching和IVMM的时间复杂度都为O(nk2mlogm+nk2).认为低采样轨迹是在真实路径中有噪音的稀疏观察点, 并采用隐马尔可夫模型设计路网匹配算法, 这些算法以高斯模型描述单一观察点、以观察点与路网中边的几何特征和路网的拓扑结构确定观察点之间的转移概率, 最后匹配的路径具有最大的后验概率[1, 12, 13].
与本文最相关的工作是数据驱动的低采样轨迹路网匹配算法, 这类方法也称为多轨迹协同路网匹配.这种路网匹配方法的优势在于用户的轨迹往往遵循较高的时间和空间旅行规律[16].HRIS以频繁路径体现时空旅行规律, 提出了数据驱动的两阶段路径推理系统:第1阶段为局部推理, 该阶段计算低采样轨迹任意相邻两点之间的多条可能路径; 第2阶段为全局推理, 该阶段使用动态规划算法从局部匹配结果中组合并计算出最可能的路径作为路网匹配结果.InferTra[2]是一个基于图的轨迹推理系统, 该推理系统使用吉布斯抽样算法和学习到的网络便携模型推理出轨迹的完整路径.STRS[3]是最新的路径恢复方法, 该方法同时考虑历史轨迹的时间和空间概率分布模型, 相比于其他低采样轨迹的路网匹配算法, STRS的准确率有较大提升.以轨迹聚类体现时空旅行规律, Li等人提出了连接多个边聚类而构成完整路径[17], 每个边聚类是路径的k条分段, 每条轨迹被划分为多个Multi-Track[18].
另一个与本文相关的工作是驾驶偏好的构建和带有偏好的路径查询.张凯评等人给出了兼顾查询者熟悉路径的个性化路径规划框架[19].Silva等人提出了多目标路径规划, 并以事先给出的路网静态属性重要程度来简化最终路径, 不同属性的重要程度即为驾驶偏好[20].Balteanu等人提出了支持两个静态属性的驾驶偏好, 比如旅行距离和经过的红绿灯数量[21].杨彬等人提出了在多属性动态道路交通网络中的概率型驾驶偏好模型, 可用于求解个性化Skyline路径[22].戴健等人研究了个性化路径推荐方法, 该方法采用概率型驾驶偏好模型[22], 从那些与查询者具有相似驾驶偏好的用户的历史轨迹中构建临时道路交通网络, 在该网络上查询最频繁路径, 该方法认为相似用户的轨迹具有更高的参考价值[23].
在多目标路径规划方面, 有关Skyline或Pareto路径的研究也得到了研究者的广泛关注[24-26].Kriegel等人提出了基于图嵌入的Skyline路径查询算法[27].Shekelyan等人为了降低Skyline路径数量, 提出了线性Skyline路径问题, 并给出了基于凸优化的精确算法和快速的近似算法[28].杨彬等人设计了动态网络下的快速Skyline路径查询算法Multi-Dijkstra[22, 29], 该算法在多属性情况下表现良好, 当属性数量较低时(比如小于3)性能较差.
然而, 现有针对低采样轨迹的路网匹配或路径推理算法都忽略了用户个性化驾驶偏好, 因此, 距离较远的相邻采样点, 该采样点来自驾驶偏好各不相同的多个用户(即实际所选路径很可能不同), 但是使用任一已有路网匹配算法, 最终得到的路网匹配结果是相同的[2-5].
当前已有用户驾驶偏好模型难以直接应用在个性化路网匹配中来:首先, 在路网匹配时, 难以为用户静态指定唯一的驾驶偏好, 静态的双属性难以满足多属性动态路网情形[8].在我们的问题设置中, 已有驾驶偏好模型由于考虑的用户驾驶偏好粒度较粗, 难以直接使用[22].
在Skyline或Pareto最优路径方面, 随着路网属性数量或两点间的距离增长, 最终路径的数量呈指数方式增长, 而难以直接应用到路网匹配中[27].而线性Skyline路径在一定程度上大幅度降低了Skyline路径的数量, 但极有可能也裁剪掉了用户实际选择的路径.
为了解决这些问题, 本文提出了基于驾驶骗好的Skyline或Pareto路径查询算法, 在多属性动态道路交通网络中对低采样轨迹进行局部路网匹配(第3节、第4节).
2 问题描述动态道路交通网络(简称路网)是一个多属性有向图G=(V, E, F), 其中顶点v∈V是路网中的交叉路口或道路端点, e=(s, d)∈E:V×V是一条有向边或道路中路段, e.s和e.d分别是边e的起点和终点, F:(T→
若m=3, 路网的属性可以是旅行距离(f1)、旅行时间(f2)和油耗(f3).若从顶点e.s的出发时间是t0, 则
定义1(轨迹). 给定轨迹集合Y, 轨迹
当轨迹的采样时间间隔Δt=pi+1.t-pi.t(1≤i < n)超过2min时, 称其为低采样轨迹; 否则, 称其为高采样轨迹.本文主要考虑低采样轨迹路网匹配问题, 而高采样轨迹用来估计动态路网属性和用户的驾驶偏好(见第3节).
定义2(路径). 给定路径集合
通过已有路网匹配算法可将高采样轨迹
问题描述:给定动态多属性道路交通网络G, 某用户的历史轨迹集合Y, 针对某个低采样轨迹
本节给出了从高采样轨迹
在不同交通状况下, 用户根据个人对路网中不同代价喜爱程度来选择路径, 我们引入路径偏好来描述用户这种路径选择行为.
定义3(路径偏好). 给定路径
例如, 路径P的起止顶点分别为s和d, 若从s到d的最小旅行距离和最小旅行时间分别为10km和15min, 而路径P的旅行距离和旅行时间分别为13km和18min, 那么P的路径偏好为(10/13, 15/18).
3.2 用户驾驶偏好把来自同用户的任意高采样轨迹
直接用DBSCAN对路径偏好聚类是不可行的.例如, 若路网属性为旅行时间(travel time, 简称TT)和旅行距离(travel distance, 简称TD), 给定路径偏好Γ1=(0.8, 0.7), Γ2=(0.8, 0.6)和Γ3=(0.7, 0.8), 则驾驶偏好Γ1和Γ3的距离比Γ2和Γ3的距离近, 说明Γ1和Γ3属于同一个聚类.然而, 由于Γ1和Γ2都偏爱短的旅行时间, 应该属于同一个聚类, 而Γ3偏爱短的旅行距离而属于另一聚类.在图 2(a)所示的驾驶偏好中, 用DBSCAN聚类算法[31]得到C1~C4共4个聚类, 其中, C1和C2聚类都表示与旅行时间相比用户更喜爱短的旅行距离, C3聚类表示用户更喜爱短的旅行时间.然而在包含11个元素的C4聚类中, 8个路径偏好说明用户喜爱短的旅行距离, 而另外3个路径偏好表明用户更喜爱短的旅行时间, 因此, 要用层次化聚类将聚类C4中不同的驾驶喜爱分离.否则, 使用11个混合驾驶偏好概率替代3个喜爱较短旅行时间的个人驾驶偏好概率, 会在后续的求解用户选择某条路径可能性时带来较大误差.而先层次化后, DBSCAN的混合聚类提高了用户选择某条路径的概率的准确度.

|
Fig. 2 Hybrid hierachy-DBSCAN vs. DBSCAN clustering for driving preference 图 2 驾驶偏好的层次化与DBSCAN混合聚类和仅DBSCAN聚类的区别 |
鉴于此, 我们将偏好向量Γ转换为分量非递减排序的路径偏好
然而, 在层次化聚类结果中[22, 32], 同聚类的不同路径偏好之间可能存在着巨大差异.例如, 分别在旅行时间和旅行距离属性下, 驾驶偏好Γ1=(0.2, 0.9), Γ2=(0.8, 0.9)和Γ3=(0.7, 0.8), 虽然这3个驾驶偏好表明用户喜爱更短的旅行距离(如图 2(b)斜线L左上侧区域), 由于Γ1代表的路径在旅行时间上非常糟糕, 很少有用户选择这样的路径.而Γ2和Γ3表明, 用户喜爱较短的旅行距离, 且同时兼顾旅行时间的情况, 比如旅行时间不超过最快路径旅行时间的1.2倍.如图 2(b)所示, 经过层次化聚类算法得到由斜线L划分的两个层次化聚类(C1, C2和C4属于一个层次化聚类, 而C3和C5属于另一个层次化聚类), 在同一层次化聚类中, 有必要经过DBSCAN算法对同一层次化聚类进一步聚类, 从而得到C1~C5共5个驾驶偏好聚类, 其中, C4有8个元素, 而C5有3个元素.
为了弥补层次化聚类在对驾驶偏好进行聚类时存在的不足, 我们把层次化聚类的结果使用DBSCAN算法[18]再次聚类.先层次化后DBSCAN的混合聚类方式, 不仅体现了原有粗粒度驾驶偏好, 也突出了同偏好下的细粒度差异; 提高了驾驶偏好概率精确度, 也更好地刻画了用户的驾驶偏好.
到目前为止, 根据同用户所有历史路径, 得到他们的路径偏好, 并对其按照偏好的分量非递增排序; 经过混合聚类最终得到K个路径偏好聚类.由于混合高斯模型(Gaussian mixture model, 简称GMM)可以描述任意复杂的概率函数, 我们采用混合高斯模型来描述驾驶偏好向量中每个随机变量[33], 以此刻画用户的驾驶偏好.给定某用户的所有路径偏好, 经过混合聚类算法, 得到K个路径偏好聚类, 把驾驶偏好中第i个属性看做是随机变量(1≤i≤m), 用GMM算法构建高斯混合分布[29], 求得
定义4(驾驶偏好适配度). 给定某用户的驾驶偏好密度函数pdf和路径
本节介绍基于用户驾驶偏好的低采样轨迹路网匹配算法, 该算法包含两个阶段.
● 第1阶段为轨迹中所有相邻两采样点各自k1条最近邻边之间推荐在用户驾驶偏好下最可能的Top-k2 Skyline路径.
● 第2阶段为全局匹配阶段, 推荐与查询轨迹最匹配的Top-k3全局路径.
例如, 在图 3(a)中, 采样点p1, p2和p3的2条近邻边分别为(v1, v2)与(v1, v5)、(v7, v10)与(v9, v10)和(v15, v19)与(v18, v19), 则从(v1, v2)到达(v7, v10)的Top-2 Skyline路径分别为P3和P4, 从(v1, v5)到达(v9, v10)的Top-2 Skyline路径分别为P1和P2, 同样可求得从采样点p2到p3的两组Top-2 Skyline路径P5与P6和P7与P8.图 3(b)说明了全局匹配阶段根据第4.2节给出的动态规划算法求得全局路径分数最高的两组路径P2P5和P4P8, 其中移除了置信度较小的路径连接.

|
Fig. 3 Two-Stage map-matching: first local map-matching stage and second global map-matching stage 图 3 两阶段路网匹配:第1阶段局部匹配和第2阶段全局匹配 |
4.1 局部匹配
在多属性道路交通网络中, 用户在路径规划时往往同时考虑多个属性, 所选择的路径至少要在一个属性上比其他路径优秀, 很少选择那些在所有属性上都不优秀的路径, 即用户选择的路径没有被其他路径支配, 我们称这样的路径为Skyline路径.在局部路网匹配中, 我们以相邻两采样点之间的Skyline路径为准, 本节先给出局部路网匹配算法Local Match(如算法1所示), 然后给出求解Skyline路径的ComputeSkyline算法.
算法1. Local Match.

|
如算法1所示, 由于较高的属性维度和较远的两点间距离会导致过多的Skyline路径, 这将增加路网匹配的时间复杂度.为了降低局部匹配路径的数量, 我们选择那些与用户驾驶偏好适配度最高的k2条Skyline路径作为局部匹配结果.给定某用户的驾驶偏好Γ和该用户生成的低采样轨迹
下面给出Skyline路径定义, 然后讨论在局部路网匹配下问题设定中的Skyline路径特征, 并给出高效的Skyline路径查询算法ComputeSkyline.
定义5(skyline路径). 在具有m个属性的路网G中, 令
1) 任意i∈[1, m], 使得Si(P)≤Si(Q)成立;
2) 存在i∈[1, m], 使得Si(P) < Si(Q)成立.
即路径P的代价在所有属性上不比Q差, 且至少在一个属性上比Q优.路径集合
引理1(skyline路径的前缀子路径也是skyline路径). 令路径
证明:给定Skyline路径P, 假设P的前缀子路经P′不是Skyline路径.记P=P′P″, 即P′和P″尾首连接构成路径P, 那么肯定存在另外一条与P′共享起止点的Skyline路径Q′(Q′≠P′), 且Q′支配P′, 得到:
1) 任意i∈[1, m], 使得Si(Q′)≤Si(P′)成立;
2) 存在i∈[1, m], 使得Si(Q′) < Si(P′)成立.
此时, 新路径Q=Q′P″, 根据Si(·)的可列可加性可知, Si(Q)=Si(Q′)+Si(P″)和Si(P)=Si(P′)+Si(P″)成立, 则
1) 任意i∈[1, m], 使得Si(Q)≤Si(P)成立;
2) 存在i∈[1, m]使得Si(Q) < Si(P)成立.
即Q支配P.根据Skyline路径的定义可知, 路径P不是Skyline路径.这与P是Skyline路径矛盾, 因此不存在路径Q′支配P′, 即P′不是Skyline路径不成立, 也即Skyline路径的前缀子路经是Skyline路径.引理得证.
我们称从源点s出发但没有到达终点d的路径为部分路径(s和d是采样轨迹相邻两采样点各自近邻边的两个端点), 称已经到达d的路径为完整路径.由于在Skyline路径查询中, 只有终点相同的路径之间才可用支配关系相互剪枝, 因此, 到达d的完全路径之间可以进行比较, 从而应用支配关系来剪枝掉某条完整路径.
由于在路网G中旅行时间是动态的, 不能保证车辆在道路中先进先出, 原有基于静态属性的多目标路径查询算法难以用来解决动态网络情形, 即同终点的部分路径之间, 由于到达的时间差异而导致后期路径的边权重的改变, 而导致难以比较其支配关系.若采用穷举法枚举所有从起点到终点的Skyline路径, 再求得与用户驾驶偏好适配度高的Top-k2 Skyline路径, 这种穷举法效率较低下, 仅适合路网规模较小的情况.
因此, 我们提出了多剪枝策略的Skyline算法ComputeSkyline(如算法2所示).
4个关键的剪枝策略如下所示.
1) 共享终点的部分路径之间剪枝策略, 称为树剪枝策略(tree pruning strategy).
2) 终点处Skyline完整路径与经预估到达终点的部分路径之间的剪枝策略, 称为预估剪枝策略(estimation pruning strategy).
3) 终点处完整路径之间剪枝, 称为完整路径剪枝策略(complete path pruning strategy).
4) 局部路径从当前顶点开始预估经由最快路径到达终点, 到达终点时间比已知时间是否晚了超过δmin, 称为时间松弛剪枝策略(time relaxed pruning strategy).
剪枝策略1(树剪枝策略). 起止点相同的局部路径P和Q, 若P支配Q, 则可安全地把路径Q剪枝掉, 即可把所有以Q为前缀并扩展到终点的路径扩展树剪掉.
证明:如图 4(a)所示, 给定共享起止点的局部路径P和Q, 满足条件P支配Q, 假设存在从起点到终点的路径R=QQ′是Skyline路径, 由于路径R=QQ′的前缀子路经Q被P支配, 这与引理1矛盾, 因此假设不成立.即不存在以Q为前缀而到达终点的路径是Skyline路径.因此, Q可被安全剪枝掉.树剪枝策略得证.

|
Fig. 4 Pruning between shared endpoints local paths and pruning between estimated to destination path and whole path 图 4 共享起止点部分路径间树剪枝和预估到终点路径与完整路径之间预估剪枝 |
剪枝策略2(预估剪枝策略). 给定任意从查询起点到终点的完全路径P和尚未到达终点的局部路径Q, 且P是Skyline路径.若存在理想的子路经Q′作为Q到达终点的后缀路径, 令包含理想子路经Q′的理想完整路径为R=QQ′, 称R是局部路径Q的预估路径, 其中, 理想后缀路径Q′在所有属性上都是从Q′的起点到终点的最短路径, 即任意i∈[1, m], 则
证明:如图 4(b)所示, 给定Skyline完整路径P和部分路径Q, 以及Q的预估后缀理想子路经Q′和预估理想完整路径R=QQ′, 且P支配R.假设存在另外一条子路经Q″与Q连接最终到达终点, 记该完整路径为R′=QQ″, 且R′是Skyline路径.由于Q′是理想后缀路径, 即
算法2. ComputeSkyline.

|
剪枝策略3(完整路径剪枝策略). 给定完全路径P和Q, 若P支配Q, 则可把完整路径Q剪枝掉.
完整路径剪枝策略可根据Skyline路径的定义证明.
剪枝策略4(时间松弛剪枝策略). 给定尚未到达终点的局部路径P, 若P从当前顶点在经过最快路径到达终点比预计时间晚了δmin, 则可安全地把P剪枝掉.
下面分析求解Skyline路径的具体过程.首先, ComputeSkyline(如算法2所示)通过逆Dijkstra算法(OneToAllSP函数)求解所有从其余顶点到达终点vd的第i个属性的最小旅行代价路径(第2行~第5行).在OneToAllSP函数中, 边e∈E的第i(1≤i≤m)个属性值是该属性在边e上所有可能取值中的最小值.并且在每个顶点v处, 记录从v到达vd的各个属性最小的代价向量(minimum cost vector, 简称MCV), 以此来预估部分路径到达终点处的理想代价, 进而可以使用预估剪枝策略(第16行~第20行).随后修正逆Dijkstra算法返回的从vs出发到达vd的路径各属性代价的精确值, 并通过Skyline更新算法验证该路径是否为Skyline路径(第4行、第5行).若这样的路径存在, 那么可以作为基准Skyline路径存储在集合
随后, 以广度优先遍历方式, 逐步探索从vs出发到达vd的所有路径(第8行~第23行).若这些路径是部分路径, 可应用树剪枝和预估剪枝策略.由于在广度优先没有到达终点时, 已有的Skyline路径最多为m条, 数量较少且剪枝效果好, 因此先进行预估剪枝, 再进行树剪枝策略(第19行、第20行).
若待验证路径是Skyline路径, 则将其添加到Skyline路径集合中, 作为Skyline的基准验证路径, 这是与基于标签的多目标路径查询算法最大区别.该基准路径有两种剪枝方式.
1) 完整路径剪枝(第21行), 算法UpdateSkyline实现了该剪枝策略(如算法3所示), 见剪枝策略3.
2) 预估剪枝(第16行~第20行).
若预估的属性代价被Skyline路径支配, 则从预估属性代价所属的部分路径出发到达终点的所有路径都不满足Skyline定义要求, 无需进一步探索该部分路径, 该部分路径应该被剪枝, 见剪枝策略2;若预估路径属性代价没有被基准Skyline路径支配, 那么从该部分路径出发有可能存在从vs到vd的Skyline路径, 则需要继续探索该路径(第20行).
算法3. UpdateSkyline.

|
为了在部分路径中使用树剪枝和预估剪枝策略, 我们在每个顶点v(v≠vd)处引入标签
另一方面, 由于Skyline路径是低采样轨迹相邻采样点之间的路径, 假设相邻采样点匹配到顶点vs和vd, 令用户到达vs和vd处的时间戳分别为ts和te, 那么候选Skyline路径的前缀路径从ts出发, 在到达vd顶点的时刻不能超过时间点te+δ.若部分路径预估到达顶点vd处的时间超出该时间点, 则该路径也应被剪枝(算法2第17行), 见剪枝策略4.根据访问起止点时间戳和时间松弛变量, 可以限定搜索的路网顶点数量, 提高了算法效率.
算法4. UpdateLabel.

|
局部匹配获得低采样轨迹
依次连接Pi∈
定义6(路径连接置信度). 令路径Pa和Pb的驾驶偏好分别为Γ(Pa)和Γ(Pb), 则路径Pa和Pb的连接置信度g(Pa, Pb)定义为
| $ g({P_a}, {P_b}) = \left\{ {\begin{array}{*{20}{l}} {1 - {{\sum\nolimits_{i = 1}^m {{{(\Gamma ({P_a}).{\gamma ^i} - \Gamma ({P_b}).{\gamma ^i})}^2}} } / {\sum\nolimits_{i = 1}^m {{{(\max ({\gamma ^i}) - \min ({\gamma ^i}))}^2}} }}, \\{\text{ }}{P_a}[|{P_a}|].e = {P_b}[1].s} \\ {\text{0}}, \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ {\text{otherwise}} \end{array}} \right.. $ |
其中, min(γi)和max(γi)分别返回所有用户驾驶偏好向量的第i个分量的最小值和最大值.
路径连接可信度表明, g(, )值越大, 则路径Pa和Pb的驾驶偏好越相似, 用户通过路径Pa接着通过Pb的概率就越高, 即轨迹所匹配的路径包含Pa◊Pb的可能性越高; 反之, g(, )取值越小, 两路径的驾驶偏好差异就越大, 而用户很难选择两条路径偏好不同的路径, 轨迹匹配的路径包含Pa◊Pb的可能性就越低.
当把多个局部Skyline路径首尾相接两两串联, 一直到轨迹最后一个采样点候选顶点处, 就构造出了该轨迹可能的匹配路径, 我们称其为全局路径.然而这样的路径数量庞大, 为了能够在不同路径之间进行比较, 我们定义了全局路径分数来概括各路径匹配到轨迹的可能性大小.
定义7(全局路径分数). 令P=P1◊…◊Pn是某用户的低采样轨迹Y的全局匹配路径, 且该用户的驾驶偏好分布密度函数为pdf, 则路径P的全局路径分数定义为
| $ s(P) = \mathcal{A}\mathcal{F}({P^1}, pdf) \cdot g({P^1}, {P^2}) \cdot \mathcal{A}\mathcal{F}({P^2}, pdf) \cdot ... \cdot g({P^{n - 1}}, {P^n}) \cdot \mathcal{A}\mathcal{F}({P^n}, pdf) = \\\prod\limits_{i = 1}^n {\mathcal{A}\mathcal{F}({P^i}, pdf)} \prod\limits_{i = 1}^{n - 1} {g({P^i}, {P^{i + 1}})} . $ |
因此, 适配度越高, 用户采用路径P的概率越高.
通过全局路径分数, 将低采样轨迹的全局匹配转换为查找分数最高的Top-k3全局路径问题.为了执行该查询, 最基本的方法为枚举所有全局路径, 最后再返回分数最高的Top-k3路径.然而, 枚举所有路径, 在轨迹采样点较多或每个采样点候选边个数较多情况下性能表现非常糟糕.假设我们考虑每个采样点的k1条近邻边, 属于相邻采样点的每个候选边对之间具有k2条Skyline路径, 若轨迹中采样点个数为|
在算法TkGP中(如算法5所示), 我们用矩阵M[, ]存储路径连接关系, M[j, i]记录了k3个全局或部分路径, 这些路径都以子路径
算法5. TkGP.
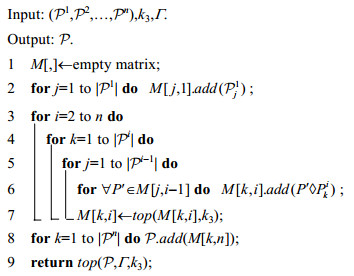
|
如算法5所示, 假设待匹配的低采样轨迹采样点个数为n, 那么在算法TkGP中, 首先将每个局部路径
● 空间复杂度
假设轨迹有n+1个采样点, 相邻两采样点间平均有r条路径, 则在全局匹配阶段, 主要引入了具有nr个元素的矩阵, 每个元素平均容纳k3条路径, 因此该阶段的空间复杂度为nrk3.在局部匹配方面, 假设在时间松弛剪枝下单次Skyline计算平均仅需访问N个顶点, 根据m维向量集合中Skyline解数量估计方法[34], 可确定在终点处大约有O((ln(N))m-1)条Skyline路径, 若内部顶点标签集合
● 时间复杂度
假设轨迹有n+1个采样点, 相邻采样点间平均有r条路径, 即
本节在真实数据集上研究DPMM的精确度和性能.所用数据集来自北京市5万多辆出租车在2012年12月将近13亿GPS轨迹点, 平均采样时间间隔为约38s, 前半月轨迹用于离线计算用户驾驶偏好, 精确度验证数据从后半月中随机选择来自不同用户的10 000条采样间隔不超过20s的轨迹, 实验结果采用数据的用平均值.用HMM路网匹配算法[1]对所有高采样轨迹进行路网匹配, 匹配结果作为基准参考.采用具有171 505个顶点和433 391条边的北京市路网.所有算法用C++语言实现, 编译器为gcc-4.8.4, 运行在配置为Intel i7-2600 CPU (3.4GHz), 32G内存, 7200RPM 1TB硬盘的工作站上, 操作系统为Linux 3.16.实验中默认参数见表 2.
| Table 2 Experimental parameter setting 表 2 实验参数设置 |
我们用高采样轨迹经过精确匹配的路径PG为基准正确性参照, 而低采样轨迹从该高采样轨迹中跳过若干个采样点扩大时间生成, 对比算法的路网匹配路径记为PM.我们以路网匹配准确率为度量标准, 其匹配准确度为Accuracy(PM, PG)=|PM∩PG|/|PG|, 当有多条全局路径时记为集合
| $ Accuracy'({\mathcal{P}_M}, {P_G}) = {\max _{P \in {\mathcal{P}_M}}}\{ |P \cap {P_G}|/|{P_G}|\} . $ |
● 对比算法
我们选择基于统计的低采样轨迹路网匹配算法ST-matching[11]和IVMM[10], 数据驱动的路网匹配方法:基于历史轨迹的路径推理系统(history based route inference system, 简称HRIS)[4]和基于时空的路径恢复系统(spatio- temporal-based route recovery system, 简称STRS)[3], 作为有效性方面的对比算法.
● 采样时间间隔效果
我们评估DPMM与4种对比算法之间路网匹配准确率, 此时采样时间间隔为2min~22min.如图 5所示, 所有路网匹配的精度随着采样时间间隔增大, 精确度都有所降低.当采样时间间隔小于10min时, ST-matching和IVMM精确度都能保持在50%以上; 当采样间隔大于10min时, ST-matching和IVMM在匹配精确方面越来越差, HRIS在采样隔超过14min时, 精确度方低于50%.STRS随着采样时间间隔逐渐增大, 下降相对缓慢.在采样时间间隔超过10min时, DPMM比STRS的准确率高出20%.

|
Fig. 5 Overall evaluation for accuracy of road network matching 图 5 路网匹配精度比较 |
为了描述路网属性对匹配精度和运行时间的影响, 特有如下设定:当m为2~7时, 分别表示旅行时间、旅行距离、油耗、红绿灯数量以及二氧化碳(CO2)、一氧化碳(CO)、碳氢化合物(HC)和氮氧化合物(NOx)等气体排放量.其中, 油耗和气体排放量采用VT-Micro车辆微观气体排放模型[36], 该模型能够通过浮动车轨迹计算出油耗和二氧化碳等气体排放详细情况.在实验设置中, m=2表明算法仅考虑旅行时间和旅行距离; 当m=7时, 考虑除氮氧化合物之外所有路网属性.
● 路网属性维度效果
图 6描述了路网属性维度m为2~7时, 改变m对路网匹配精度和运行时间的影响.图 6(a)表明, 路网匹配精度在相同采样间隔下随着m的增大而增加, 且采样率越低路网匹配精确度增加越快; 但当k=4时达到最大值.这主要是由于用户对绿色路径规划关心较少, 几乎没有注意到驾驶带来的一氧化碳等气体排放对环境的影响; 而当采样频率较高时(SI=2), 由于两采样点之间距离较近而具有较少的Skyline路径, 反而受m影响最小.图 6(b)说明, 随着路网属性维度m的增加, 平均运行时间也在逐步增大, 尤其是两采样点距离越远, 路网属性维度就越高; 同距离顶点间的Skyline数量急剧增长, 距离越远两点之间的Skyline路径数量增长越迅速, 需要更多的计算代价.

|
Fig. 6 Effect of varying m 图 6 改变变量m的效果 |
● 时间松弛效果
图 7说明了改变时间松弛变量δ对路网匹配精度和运行时间的影响.δ主要用来限定从起点出发到达终点不能太迟(见剪枝策略4).图 7(a)表明, 采样间隔小的轨迹受δ影响小, 主要原因是两采样点距离较近存在较少的局部Skyline路径; 而对于采样时间间隔大的轨迹, 由于距离较远, 局部Skyline数量较大, 较小的δ可能剪枝掉实际路径而降低路网匹配精度, 即采样时间间隔越大, 路网匹配精度受到δ的影响越大.结合图 7(b)可知, 较小的δ值提高了时间松弛剪枝策略剪枝能力, 并降低了采样时间间隔较大轨迹的路网匹配时间; 较大的δ值(不超过10min)以削弱剪枝能力和延长运行时间为代价, 提高了较低采样轨迹的路网匹配精度, 但对采样时间间隔小的轨迹影响小; 当δ超过10min时, 则轨迹实际路径不会被δ剪枝掉, 因此不会再提高精确度; 但若继续增大δ, 则仅会降低剪枝能力而延长运行时间, 从而不能在提高精度方面获得收益.

|
Fig. 7 Effect of varying δ 图 7 改变变量δ的效果 |
● 采样点近邻边数量效果
给定两个相邻采样点pi和pi+1, 距离每个采样点最近的k1条候选边集合Ei和Ei+1, 要查询从任意ei∈Ei到ei+1的k2条Skyline路径(见算法1), 当k2和全局路径k3取默认值时, 本部分考察改变k1时对路网匹配精度和运行时间的影响.如图 8(a)所示, 当k1从1增加到3时, 能够提高距离较近的采样点之间路网匹配精度; 当超过3时, 影响较小; 而对于采样时间间隔较大轨迹的路网匹配精度而言, 当k1较小时, 路网匹配精度很低, 随着k1的增加, 路网匹配精度有较大提升.图 8(b)表明, 当k1增加时, 一方面提高了局部匹配查询的起止点对数量而增加了Skyline查询次数而提高了局部匹配的复杂度, 同时也增加了全局匹配时动态规划运行时间, 因此运行时间随着k1的增加而增大, 采样率越低, 则Skyline的查询距离越远, 使得计算Skyline路径的运行时间增加越快.

|
Fig. 8 Effect of varying k1 图 8 改变变量k1的效果 |
● 局部Skyline路径数量效果
图 9说明了在局部匹配中起止顶点之间Skyline路径数量对路网匹配精度和运行时间的影响.图 9(a)说明:当采样率较高时, 由于两点之间距离较近, 满足条件的Skyline路径数量较少, 因此增加k2对精度影响小; 采样率越低的轨迹, 相邻两采样点之间距离越远, 潜在的Skyline数量越多, 随着k2的增加, 路网匹配精度有明显的提升.图 9(b)表明, 与k2相比, 求解Skyline路径与距离远近对运行时间影响更大, 采样率越低, 距离就越远, 求解Skyline路径需要的计算量也就越多, 而增加k2主要影响全局匹配的动态规划算法运行效率.

|
Fig. 9 Effect of varying k2 图 9 改变变量k2的效果 |
● 全局路径数量效果
如图 10(a)所示, 随着全局路径数量k3增加, 路网匹配精度都有所提升, 采样率越低, 路网匹配精度提高越明显.当k3从2增大到10时, 路网匹配精确度也在逐步提高; 但当k3超过10时, 路网匹配精确度就不再有所增加.这主要是由于足够大的k3值, 已经可以覆盖轨迹的实际路径.而图 10(b)表明, 随着k3的增大, 各采样率轨迹路网匹配运行时间都有所增长, 采样率越高, 轨迹的路网匹配运行时间受k3影响越大; 采样率越低, 影响越小.这主要是由于等距离的轨迹, 高采样轨迹点较多, 使得动态规划中出现较多阶段; 而低采样轨迹阶段较少, 且在同阶段中局部边数量固定, 则较多阶段比较少阶段受到k3的影响要大.

|
Fig. 10 Effect of varying k3 图 10 改变变量k3的效果 |
6 结论
本文提出了在多属性动态网络中低采样轨迹路网匹配的问题, 考虑到不同用户选择路径时的个性化差异, 我们构造了基于用户驾驶偏好的低采样轨迹个性化路网匹配算法, 通过从历史高采样轨迹中学习到的驾驶偏好来指导低采样轨迹的路网匹配.在驾驶偏好提取和路网匹配过程中, 采用多目标优化思想查找局部Skyline路径作为局部匹配的候选路径.该方法在采样时间间隔为20min时也能保证路网匹配精度在65%以上.我们基于真实数据集做了充分实验, 实验结果表明, 该方法是有效和高效的.在将来的工作中, 我们着重考虑道路交通网络边的动态属性服从一定概率分布的情形, 并在用户驾驶偏好模型中引入不确定性和动态性, 从而提高路网匹配的精度, 并设计更加高效的算法, 提高路网匹配运行效率.
致谢 感谢各位审稿专家, 他们给出的意见和建议对提高本文质量起到了关键作用.在此, 我们也向对本文工作给予支持和帮助的老师和同学表示感谢.| [1] |
Newson P, Krumm J. Hidden Markov map matching through noise and sparseness. In: Proc. of the GIS 2009. 2009. 336-343.http://dl.acm.org/citation.cfm?id=1653818&preflayout=flat |
| [2] |
Prithu B, Sayan R, Sriram R. Inferring uncertain trajectories from partial observations. In: Proc. of the ICDM 2014. 2014. 30-39.http://ieeexplore.ieee.org/document/7023320/ |
| [3] |
Wu H, Mao JY, Sun WW, Zheng BH, Zhang HY, Chen ZY, Wang W. Probabilistic robust route recovery with spatio-temporal dynamics. In: Proc. of the 22nd ACM SIGKDD Int'l Conf. on Knowledge Discovery and Data Mining. 2016. 1915-1924. |
| [4] |
Zheng K, Zheng Y, Xie X, Zhou XF. Reducing uncertainty of low-sampling-rate trajectories. In: Proc. of the 28th Int'l Conf. on Data Engineering. 2012. 1144-1155.http://dl.acm.org/citation.cfm?id=2310317 |
| [5] |
Ceikute V, Jensen CS. Routing service quality local driver behavior versus routing services. In: Proc. of the 14th Int'l Conf. on Mobile Data Management. 2013. 97-106.http://dl.acm.org/citation.cfm?id=2510020 |
| [6] |
White CE, Bernstein D, Alain LK. Some map-matching algorithms for personal navigation assistants. In: Proc. of the Transportation Research Part C8. 2000. 91-108.http://www.sciencedirect.com/science/article/pii/S0968090X00000267 |
| [7] |
Dai J, Ding ZM, Xu J. Context-Based moving object trajectory uncertainty reduction and ranking in road network. Journal of Computer Science and Technology, 2016, 31(1): 167–184.
[doi:10.1007/s11390-016-1619-5] |
| [8] |
Meng Y. Improved Positioning of land vehicle in ITS using digital map and other accessory information[Ph.D. Thesis]. Hong Kong: Department of Land Surveying & Geo-Informatics, Hong Kong Polytechnic University, 2006. |
| [9] |
Yin HB, Wolfson O. A weight-based map matching method in moving objects databases. In: Proc. of the Int'l Conf. on Scientific and Statistical Database Management (SSDBM 2004), Vol.16. 2004. 437-410.http://dl.acm.org/citation.cfm?id=1007156 |
| [10] |
Yuan J, Zheng Y, Zhang C, Xie X, Sun GZ. An interactive-voting based map matching algorithm. In Proc. of the 11th Int'l Conf. on Mobile Data Management (MDM 2010). 2010. 43-52.http://ieeexplore.ieee.org/document/5489808 |
| [11] |
Lou Y, Zhang C, Zheng Y, Xie X, Wang W, Huang Y. Map-Matching for low-sampling-rate GPS trajectories. In: Proc. of the 17th ACM SIGSPATIAL Int'l Conf. on Advances in Geographic Informathin System. 2009. 352-361.http://dx.doi.org/10.1145/1653771.1653820 |
| [12] |
Raymond R, Morimura T, Osogami T, Hirosue N. Map matching with hidden Markov model on sampled road network. In: Proc. of the 21st Int'l Conf. on Pattern Recognition (ICPR 2012). 2012. 2242-2245.http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6460610 |
| [13] |
Goh CY, Dauwels J, Mitrovic N, Asif MT, Oran A, Jaillet P. Online map-matching based on Hidden Markov model for real-time traffic sensing applications. In: Proc. of the 15th Int'l Conf. on Intelligent Transportation Systems. 2012. 776-781.http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6338627 |
| [14] |
Ochieng WY, Quddus MA, Noland RB. Map-Matching in complex urban road networks. Journal of Cartography, 2004, 55(2): 1–18.
http://d.old.wanfangdata.com.cn/OAPaper/oai_doaj-articles_13345825c027e552bb58dfca2585a4eb |
| [15] |
Brakatsoulas R, Pfoser D, Salas R, Wenk C. On map-matching vehicle tracking data. In: Proc. of the VLDB 2005. 2005. 852-864.http://dl.acm.org/citation.cfm?id=1083691 |
| [16] |
González MC, Hidalgo CA, et al. Understanding individual human mobility patterns. Nature, 2008, 453(7196): 779–782.
[doi:10.1038/nature06958] |
| [17] |
Li Y, Huang QX, Michael K, Zhang L, Leonidas G. Large-Scale joint map matching of GPS traces. In: Proc. of the 21st ACM SIGSPATIAL Int'l Conf. on Advances in Geographic Information Systems (GIS 2013). 2013. 214-223.http://dl.acm.org/citation.cfm?id=2525333 |
| [18] |
Javanmard A, Haridasan M, Zhang L. Multi-Track map matching. In: Proc. of the GIS 2012. 2012. 394-397.http://dl.acm.org/citation.cfm?id=2424373 |
| [19] |
Chang KP, Wei LY, Ling Y, Yeh MY, Peng WC. Discovering personalized routes from trajectories. In: Proc of the 3rd ACM SIGSPATIAL Int'l Workshop on Location-Based Social Networks. 2011. 33-40.http://dl.acm.org/citation.cfm?id=2063218 |
| [20] |
Silva ER, Souza C, Paiva AC. Personalized path finding in road networks. In: Proc. of the NCM. 2008. 586-591.http://ieeexplore.ieee.org/xpl/abstractAuthors.jsp?reload=true&arnumber=4624209 |
| [21] |
Balteanu A, Jossè G, Schubert M. Mining driving preferences in multi-cost networks. In: Proc. of the SSTD. 2013. 74-91.http://link.springer.com/10.1007/978-3-642-40235-7_5 |
| [22] |
Yang B, Guo CJ, Ma Y, Jensen CS. Toward personalized, context-aware routing. The VLDB Journal, 2015, 25(2): 279–318.
http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0234460024/ |
| [23] |
Dai J, Yang B, Guo CJ, Ding DZ. Personalized route recommendation using big trajectory data. In: Proc. of the Int'l Conf. on Data Engineering. 2015. 543-554.http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=7113313 |
| [24] |
Yang YJ, Gao H, Li JZ. Optimal path query based on cost function over multi-cost graphs. Chinese Journal of Computers, 2012, 35(10): 2147–2158(in Chinese with English abstract).
http://d.old.wanfangdata.com.cn/Periodical/jsjxb201210015 |
| [25] |
Wei XJ, Yang J, Li CP, Chen H. Skyline query processing. Ruan Jian Xue Bao/Journal of Software, 2008, 19(6): 1386–1400(in Chinese with English abstract).
http://www.jos.org.cn/jos/ch/reader/view_abstract.aspx?flag=1&file_no=20080612&journal_id=jos [doi:10.3724/SP.J.1001.2008.01386] |
| [26] |
Huang ZH, Xiang Y, Xue YS, Liu XL. An efficient method for processing skyline queries. Journal of Computer Research and Development, 2010, 47(11): 1947–1953(in Chinese with English abstract).
http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201011013 |
| [27] |
Kriegel HP, Renz M, Schubert M. Route skyline queries: A multi-preference path planning approach. In: Proc. of the Int'l Conf. Data Engineering. 2010. 261-272.http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5447845 |
| [28] |
Shekelyan M, Josse G, Schubert M. Linear path skylines in multicriteria networks. In: Proc. of the ICDE 2015. 2015. 459-470.http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=7113306 |
| [29] |
Yang B, Guo CJ, Jensen CS. Travel cost inference from sparse, spatio-temporally correlated time series using Markov models. Proc. of the VLDB Endowment, 2013, 6(9): 769–780.
[doi:10.14778/2536360] |
| [30] |
Orda A, Rom R. Shortest-Path and minimum-delay algorithms in networks with time-dependent edge-length. Journal of ACM, 1997, 37(3): 607–625.
http://d.old.wanfangdata.com.cn/NSTLQK/10.1145-79147.214078/ |
| [31] |
Ester M, Kriegel HP, Sander J, Xu XW. A density-based algorithm for discovering clusters in large spatial databases with noise. In: Proc. of the 2nd Int'l Conf. on Knowledge Discovery and Data Mining. 1996. 226-231. |
| [32] |
Rokach L, Oded M. Clustering Methods. Data Mining and Knowledge Discovery Handbook. Springer-Verlag, 2005: 321-352.
|
| [33] |
Bishop CM. Pattern Recognition and Machine Learning. New York: Springer-Verlag, 2006.
|
| [34] |
Bentley JL, Kung HT. On the average number of maxima in a set of vectors and applications. Journal of the Association for Computing Machinery, 1978, 25(4): 536–543.
[doi:10.1145/322092.322095] |
| [35] |
Serafini P. Some considerations about computational complexity for multiobjective combinatorial problems. Recent Advances and Historical Development of Vector Optimization, 1986, 294: 222–231.
https://link.springer.com/chapter/10.1007%2F978-3-642-46618-2_15 |
| [36] |
Rakha H, Ahn K, Trani A. Development of VT-micro model for estimating hot stabilized light duty vehicle and truck emission. Transportation Research Part D:Transportation Environment, 2004, 9(1): 49–74.
[doi:10.1016/S1361-9209(03)00054-3] |
| [24] |
杨雅君, 高宏, 李建中. 多维代价图模型上最优路径查询问题的研究. 计算机学报, 2012, 35(10): 2147–2158.
http://d.old.wanfangdata.com.cn/Periodical/jsjxb201210015
|
| [25] |
魏小娟, 杨婧, 李翠平, 陈红. Skyline查询处理. 软件学报, 2008, 19(6): 1386–1400.
http://www.jos.org.cn/jos/ch/reader/view_abstract.aspx?flag=1&file_no=20080612&journal_id=jos [doi:10.3724/SP.J.1001.2008.01386]
|
| [26] |
黄振华, 向阳, 薛永生, 刘啸岭. 一种处理Skyline查询的有效方法. 计算机研究与发展, 2010, 47(11): 1947–1953.
http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201011013
|