 2017, Vol. 28
2017, Vol. 28



2. 西北工业大学 电子信息学院, 陕西 西安 710072;
3. 中国人民解放军 32147 部队, 河南 商丘 476000
2. Institute of Electronic Information, Northwestern Polytechnical University, Xi'an 710072, China;
3. Troop 32147, Chinese People's Liberation Army, Shangqiu 476000, China
随着IP网络规模的不断扩大, 网络终端接入数量剧增, 路由器/交换机参与数目越来越多, 除了物理链路切断造成的网络阻塞外, 复杂的网络结构和不合理的路由原则均会造成网络多链路拥塞现象的发生.从而带来网络整体性能和服务质量的急剧下降.多链路拥塞造成的IP网络高网络时延和高网络丢包率等现象还可能是因为涉及违反了SLA(service-level agreement)等相关服务等级协定造成的[1].所以, 网络管理者需要及时、准确地定位网络中发生拥塞的链路并进行处理.
目前, 国内外对IP网络内部链路性能推理主要借助主动检测及被动检测两种方法.其中, 借助少量端到端(end-to-end, 简称E2E)路径探测(tomography)推理链路性能的主动检测[2-5]方法因具有不涉及用户隐私、实时性好、设备开销小, 且对网络性能影响不大等优点, 而被网络运营商及国内外研究学者所青睐.目前, 借助Boolean代数, 基于最小链路覆盖集(smallest consistent failure set, 简称SCFS)理论[3, 6]进行拥塞链路推理的主动检测方法Boolean tomography, 当待测IP网络拥塞链路比例增大时, 特别是当某条拥塞路径中除共享瓶颈链路外, 仍存在其他拥塞链路时, 因算法理论本身存在的缺陷, 将会造成算法推理性能的急剧下降.另外, 有部分文献对主动检测方法中的探针部署点[7, 8]及E2E发包路径优化[9, 10]等方面进行了研究, 在尽量减小开销的基础上, 尽可能多地覆盖待测IP网络中的链路范围.但并未研究算法链路覆盖范围变化对算法推理性能带来的影响.此外, Boolean tomography利用链路拥塞先验概率, 借助贝叶斯理论进行拥塞链路推理的CLINK算法, 能够有效地避免单时隙E2E路径探测对时间强关联性的依赖.但是, 对大规模IP网络多链路拥塞场景, 由于链路先验概率求解系统方程组系数矩阵的稀疏性, 易造成求解失败, 目前未见文献提出好的解决方法.
针对上述问题, 本文基于Boolean tomography的实用性, 针对大规模IP网络多链路拥塞场景, 提出一种基于贝叶斯最大后验概率(Bayesian maximum a-posterior, 简称BMAP)改进的拉格朗日松弛次梯度算法(Lagrange relaxation sub-gradient algorithm based on BMAP, 简称LRSBMAP).考虑到算法链路覆盖范围对推理性能的影响.首先, 根据待测IP网络各路由器度值, 提出一种通过设置度阈值参数(degree threshold value, 简称DTV)进行IP网络链路覆盖的方法(link cover method based on DTV, 简称LCDTV). LCDTV引入优选系数ρ进行待测IP网络各E2E发包路径及发包路由器探针部署节点的优选.考虑到网络用户及管理者对IP网络拥塞的容忍程度, 在链路先验概率学习的过程中, 引入了路径拥塞次数参数(path congestion time, 简称PCT), 对N次E2E性能探测过程中拥塞次数小于PCT的E2E路径视为正常路径, 通过去除正常路径及途经链路, 在链路拥塞先验概率学习过程中, 对待测IP网络进行拥塞选路矩阵及拥塞贝叶斯网模型的构建.针对大规模IP网络多链路拥塞场景下, 先验概率求解系统线性方程组系数矩阵的稀疏性, 提出一种收敛速度快且运行时间短的基于对称逐次超松弛(symmetry successive over-relaxation, 简称SSOR)分裂预处理的共轭梯度法(preconditioned conjugate gradient method based on SSOR, 简称PCG_SSOR), 迭代求解链路拥塞先验概率近似唯一解.在拥塞链路推理过程中, 首先, 对当前推理时刻正常路径及途经链路从链路拥塞先验概率学习过程中构建的拥塞贝叶斯网模型中去除, 并由此得到拥塞链路推理过程中的剩余拥塞选路矩阵.最后, 基于BMAP准则, 将IP网络拥塞链路推理问题转化为集合覆盖问题(set cover problem, 简称SCP), 利用本文提出的LRSBMAP算法在多项式时间内完成此SCP的迭代求解.
通过模拟不同拓扑类型及规模的IP网络模型, 利用检测率(detection rate, 简称DR)及误报率(false positive rate, 简称FPR)对本文提出算法与Boolean tomography经典算法CLINK进行性能比较评价, 验证本文提出算法的准确性及鲁棒性.另外, 本文提出利用LCDTV方法改变推理算法的链路覆盖范围, 实验验证了该方法的有效性.在LCDTV算法中, 通过引入优选系数ρ, 在兼顾开销的基础上, 有效地保证了拥塞链路推理算法的推理性能.在大规模IP网络多链路拥塞场景下, 利用本文提出的PCG_SSOR算法与传统的求解方法分别进行链路先验概率迭代求解, 验证了本文提出的PCG_SSOR方法的收敛性及稳定性.
本文的创新点主要体现在以下4个方面.
(1) 根据待测IP网络中各路由器度值, 引入度阈值参数DTV, 提出一种链路覆盖方法LCDTV算法; 算法根据优选系数ρ确定最优DTV, 兼顾了链路覆盖率、额外E2E路径探测发包数及探针部署开销;
(2) 根据路径拥塞容忍程度引入路径拥塞次数参数PCT, 根据拥塞路径及途经链路关系, 借助矩阵性质, 构建链路拥塞先验概率学习过程及拥塞链路推理过程中的化简拥塞选路矩阵及剩余拥塞贝叶斯网模型, 简化了推理复杂度;
(3) 针对大规模IP网络多链路拥塞场景, 先验概率求解系统线性方程组中系数矩阵的稀疏性问题, 提出PCG_SSOR方法迭代求解各链路先验概率近似唯一解;
(4) 根据拥塞链路推理时刻各E2E路径性能测量结果, 基于推理时刻剩余拥塞选路矩阵及BMAP准则, 提出一种多链路拥塞场景下的拥塞链路集合推理算法LRSBMAP.
本文第1节综述相关工作.第2节简述本文算法流程.第3节介绍LCDTV算法.第4节介绍拥塞贝叶斯网模型及拥塞选路矩阵的构建方法.第5节介绍PCG_SSOR算法.第6节介绍LRSBMAP算法.第7节对本文所提算法进行实验验证评价.第8节总结全文并对未来加以展望.
1 相关工作目前, 对IP网络内部拥塞链路状态推理主要借助主动检测及被动检测两种方法.其中, 被动检测是基于SNMP(simple network management protocol)协议, 通过采集IP网络中各网络设备(如:路由器, 交换机等)上的数据信息推理网络内部各链路连接性能.理论上, 被动检测方法对IP网络不产生附加流量, 不增加网络负担.但是, 此方法适合单个设备的监测, 对待测IP网络规模较大, 特别是需要进行大范围的拥塞链路推理、分析时, 需采集IP网络中各路由器的日志数据, 数据量巨大, 实时性较差, 且存在用户数据泄漏等安全性问题.而主动检测方法通过在网络各发包路由器上部署探针, 基于ICMP(Internet control messages protocol), 利用测量工具(如:Ping)向目的端路由器发送TCP(UDP)探针包, 根据E2E路径丢包率, 借助网络拓扑结构等, 推理IP网络内部链路性能, 不涉及用户隐私.
早期的主动检测方法利用多播探测发包方式进行多路E2E性能检测(snapshots)[11, 12].通过单时隙E2E路径性能探测, 推理IP网络内部各链路丢包率, 进而推理链路性能, 但因支持多播方式的路由器在大规模IP网络中并未普及而使多播方法受到限制[13].利用单播背靠背[5]与单播模拟多播的包群测量方式[14]以及用于测量共享路径长度的三明治报文[15], 虽然弥补了多播探测的缺陷, 但对时间关联性要求较高, 推理精度较难保证, 需要投入复杂的基础设施建设及较高的管理费用[4, 5, 10].并且, 在对各链路丢包率求解时, 涉及复杂的线性方程组矩阵求逆运算, 对大规模IP网络, 特别是多链路拥塞场景, 容易陷入维数灾难, 导致算法求解失败.因此, 为了避免单时隙性能探测对时间强相关性的要求, Nguyen和Thiran等人提出多时隙E2E路径性能探测方法, 将路径及链路状态通过Boolean代数模型进行表示[16], 并借助Bayes定理, 通过N次E2E路径性能测量结果, 学习IP网络链路拥塞先验概率, 基于BMAP准则推理当前推理时刻拥塞链路[4], 且较早期推理方法假设IP网络内部各链路具有一致先验概率的SCFS算法[3]或不借助先验概率的MCMC(Monte Carlo Markov chain)算法[2], 在推理性能上有了较大程度的提高.此外, Ghita等人将CLINK方法[4]推广到更一般的场景中, 发现并证明, 当网络中某些链路的状态不相互独立时, 链路先验拥塞概率可辨识的充要条件[17], 提出一种只需少量E2E路径测量即可求得链路先验拥塞概率的方案[18].
除了对E2E测量方式的研究外, 还有一些关于如何减少E2E路径探测报文数目[9, 10]、减少部署测量监控节点数目[7, 8]等方面的讨论.但有关推理算法链路覆盖范围的改变对推理算法性能的影响未进行研究.另外, 为解决网络tomography方法本身E2E路径数过少造成的系统方程组系数矩阵欠定问题, Augustin[19]、潘胜利[1]等人提出单源多径路由等方法.此外, 当两条路径经历公共拥塞链路时, 路径性能将会具有很强的相关性.Kim等人[20]基于时延相关性, 提出小波降噪方法以识别共享拥塞链路.Zarifzadeh等人[6]借助Boolean tomography的实用性, 通过Analog tomography方法提高了链路性能分辨率.但当拥塞路径途经拥塞链路数过多时, 现有的基于SCFS理论的拥塞链路集合推理算法[3, 4, 6]的性能下降得较为明显.
2 LRSBMAP算法本文提出一种大规模IP网络多链路拥塞推理算法LRSBMAP, 主要包括3部分:(1) E2E路径及探针部署优选.在保证链路覆盖率的基础上, 根据待测IP网络拓扑, 进行E2E发包探测路径及发包路由器探针部署位置的优选; (2) 链路拥塞先验概率学习.根据N次E2E路径性能测量结果, 学习算法覆盖的各链路拥塞先验概率; (3) 当前时刻拥塞链路推理.根据当前推理时刻各E2E路径的拥塞情况, 基于BMAP准则, 推理当前IP网络最有可能发生拥塞的链路集合.算法原理框图如图 1所示.

|
Fig. 1 Principle frame of LRSBMAP algorithm 图 1 LRSBMAP算法原理框图 |
3 E2E路径及探针部署优选方法LCDTV 3.1 预选收发包路由器节点
借助tomography方法进行IP网络拥塞链路推理时, 对尽可能少的E2E路径利用Ping发包探测, 对尽可能多的途经链路进行性能推理.目前, IP网络拥塞链路推理算法通常选取叶子节点(端主机)作为收发包路由器端点[2-4], 如选取叶子节点向其他各叶子节点进行E2E路径发包探测, 虽然E2E路径数较少, 但因路由算法最短路径优先原则, 遍历的链路数不高, 无法进行整个待测IP网络中各链路的性能推理.另外, 如果E2E路径较长, 途经的链路数较多, 对推理模型构建的系统线性方程组因系数矩阵欠定[4], 各链路性能无法精确求解, 导致算法失败.虽然Nguyen等人提出利用两条路径相关补满秩的方法扩展矩阵行来解决此问题, 但是, 当两条路径相关无法对欠定矩阵补满秩时, 使用更多路径相关补满秩通常也会造成扩展路径行线性相关, 导致系数矩阵欠定.为便于算法说明, 模拟一个小型IP网络自制系统(autonomous system, 简称AS), 如图 2所示.其中, 路由器节点有8个, 分别用数字1~8进行表示; 链路有8条, 叶子节点(路由器度值=1) 分别为1, 4, 7, 8.如仅对节点1进行发包探针部署, 向其他叶子节点发送探针包, 因路由算法中最短路径优先策略, 路径数仅为3条.另外, 由于在实际IP网络中, 通过Traceroute获取到的路径途经链路信息为各路由器网卡的IP地址, 各网卡IP地址可通过sr-all工具对应到所属的同一个路由器, 为了便于程序编写, 将各路由器间连接链路利用路由器节点标号进行表示, 如:1|2代表路由器1与路由器2间的连接链路.传统的链路覆盖方法以叶子节点作为收发包路由器节点, 如:链路2|6较2|3优选, 3条E2E路径分别为P1:1|2, 2|6, 6|5, 5|4, P2:1|2, 2|6, 6|7, P3:1|2, 2|6, 6|8, 覆盖的链路数为6条, 链路2|3及3|5未能被E2E路径所覆盖.

|
Fig. 2 Some IP network topology simulation model 图 2 某IP网络拓扑仿真模型 |
在根据E2E路径探测性能结果进行途经链路性能推理时, 需借助E2E路径及途经链路构建链路先验概率求解线性方程组, 若路径数过少, 链路数远远超出路径数, 则将导致方程组无唯一解.特别是对大规模、不同拓扑类型的IP网络, 拥塞链路推理时, 如部分E2E路径性能探测正常, 正常路径及途经各链路将不被作为可能拥塞的链路集合参与推理, 而每条路径至少不小于1条链路.因此, 去除1条路径将去除多条链路, 路径数减小幅度通常超过链路数.因此, 本文根据待测IP网络中各路由器节点度值, 引入DTV参数, 由最优DTV参数决定IP网络预选收发包节点.具体方法如下:对IP网络中路由器度值小于等于DTV的路由器, 作为获取E2E路径中的预选收发包路由器节点.如图 2所示的IP网络, 如设置DTV=1, 即以度值小于等于1(叶子节点)的路由器作为预选收发包路由器节点.路由器节点1, 3, 4, 7, 8将作为预选收发包路由器节点.
3.2 预选E2E路径预选收发包路由器节点选定后, 基于最短路径优先策略, 利用贪心搜索算法[21]中最小生成树Prim理论, 以路径途经链路数最少作为权值对所有预选收发包路由器节点间所有可能到达的E2E路径进行轮询遍历, 获取待测IP网络中各E2E路径及途经链路.搜索出途经链路数最少的E2E路径.起始路由器节点相同(途经链路方向相反)的路径保留其中一条.由此, 得到预选E2E路径.图 3所示为图 2预选E2E路径获取示意图.

在图 2所示的IP网络中, 选择路由器节点1, 3, 4, 7, 8作为预选收发包路由器节点进行E2E路径轮询遍历, 可获得5条最短E2E路径.P1:1/2, 2/3, P2:1/2, 2/6, 6/8, P3:1/2, 2/6, 6/7, P4:1/2, 2/6, 6/5, 5/4, P5:3/5, 5/4.覆盖待测IP网络中全部8条链路.
3.3 选路矩阵构建各预选E2E路径P1~P5及途经各链路按照跳数(hop)级别关系依次排列, 见表 1.
| Table 1 Preliminary selection of E2E paths and traversing links in IP network of Fig.2 表 1 图 2所示IP网络各预选E2E路径及途经链路 |
为了便于描述, 对各IP|IP对应的链路按照跳数顺序依次利用L1~L8进行表示.根据IP网络拓扑结构中各E2E路径及途经链路的关系, 选路矩阵(依赖矩阵)D的构建方法如下定义.
定义1. IP网络的选路矩阵D的各行为E2E探测路径Pi(i=1, 2, …, np), 各列为IP网络中所有链路Lj(j=1, 2, …, nc)按照Hop级别从小到大依次排列; 当某条E2E探测路径Pi途经某条链路Lj时, 选路矩阵对应列的位置处元素值Dij=1, 否则, Dij=0.
对表 1所示的IP网络拓扑, 根据各E2E探测路径源端s到目的端d的Hop级别关系(Hop1, Hop2, ...), 可依此列写出D中各列所代表的链路, 见表 2.
根据定义1, 由表 2可构建出图 2所示IP网络的选路矩阵$D({n_p} \times {n_c}).$如式(1) 所示.
| $ \begin{array}{l} {L_{1}}\;{L_{2}}\;{L_{3}}\;{L_{4}}\;{L_{5}}\;{L_{6}}\;{L_{7}}\;{L_8}\\ D = \left( {\begin{array}{*{20}{c}} 1&0&1&0&0&0&0&0\\ 1&0&0&1&0&1&0&0\\ 1&0&0&1&0&0&1&0\\ 1&0&0&1&1&0&0&1\\ 0&1&0&0&1&0&0&0 \end{array}} \right) \end{array} $ | (1) |
其中, ${n_p}$代表待测IP网络预选E2E路径总数, ${n_c}$为各预选E2E路径途经的链路总数.
3.4 E2E探测发包路径及探针部署节点获取对选路矩阵D进行最大线性无关组化简可得矩阵D', D'中各行即为实际需要发包探测的E2E路径; 根据矩阵性质, 去除线性相关路径行并不影响矩阵列数, 即覆盖链路数不发生改变, 去相关化简后的矩阵D'中的各矩阵行, 即需进行Ping发包探测的E2E路径, 路径途经的各链路即为算法覆盖链路; E2E路径源端即为需要进行探针部署的路由器节点位置.由于式(1) 构建的图 2所示的IP网络选路矩阵D本身已为最大线性无关矩阵, 故D'=D.如式(2) 所示.
| $ \begin{array}{l} {L_{1}}\;{L_{2}}\;{L_{3}}\;{L_{4}}\;{L_5}_\;{L_{6}}\;{L_7}_\;{L_8}\\ D' = \left( {\begin{array}{*{20}{c}} 1&0&1&0&0&0&0&0\\ 1&0&0&1&0&1&0&0\\ 1&0&0&1&0&0&1&0\\ 1&0&0&1&1&0&0&1\\ 0&1&0&0&1&0&0&0 \end{array}} \right) \end{array} $ | (2) |
因此, 图 2所示的IP网络实际需要进行的E2E发包探测路径数为5条, 需进行探针部署的发包路由器节点分别为路由器节点1和路由器节点3.
3.5 探针部署优化通过分析发现, 为减少探针部署开销, 在对大型IP网络进行拥塞链路推理时, E2E探测路径及探针部署点选取可进一步进行优化.
(1) 如某预选收发包路由器端点与叶子节点(度值=1) 直接相连, 则此预选收发包路由器端点即便不作为预选收发包路由器端点, 根据E2E路径探测策略, 由于叶子节点必定仅连接了与之相连的预选收发包路由器端点, 因此, 路径探测时, 要到达此叶子节点必将途经连接彼此预选收发包路由器端点间的链路.故将与叶子节点相连的预选收发包路由器端点去除, 这并不影响IP网络E2E探测路径数及覆盖的链路数, 减少了探针部署开销;
(2) 考虑到若两个预选收发包路由器端点彼此相连, 根据路由算法中最短路径优先原则, E2E路径势必以两个预选收发包路由器直接相连的链路作为最短路径进行, 如均部署探针, 两个探针间仅包含一条链路, 则准确率能够保证, 但增加了探针部署开销.因此, 对相邻预选收发包路由器端点中度值小的路由器不进行探针部署;
(3) 如叶子节点数较多, 叶子节点既作为发包点也作为接收包点, 则算法对E2E路径获取复杂度较大.因此, 在通过探针部署对IP网络进行E2E路径获取及链路覆盖时, 可将叶子节点仅作为接收包点, 如图 4所示.○表示叶子节点, □表示度值 > 1的路由器节点.依据最短路径优先原则完成E2E路径获取及链路覆盖.

|
Fig. 4 Schematic diagram of optimizing E2E measurement paths 图 4 E2E探测路径获取优化方法示意图 |
通过实验, 对大规模IP网络借助LCDTV优化算法进行E2E路径及链路覆盖, 可大大缩短E2E路径及探针部署的计算时间, 且链路覆盖率变化不明显.
3.6 DTV选取策略在借助DTV参数进行E2E探测路径获取时, 路由器探针部署节点的数目对最终确定的主动E2E探测路径数及链路覆盖率有较大影响.因此, 为了兼顾探针部署开销及链路覆盖率, LCDTV算法中引入性能优选参数ρ对探针部署及E2E路径获取算法中的DTV参数进行优选.优选系数的计算方法如式(3) 所示.
| $ \rho = 探针部署数目 \times {\rm{E}}2{\rm{E}}探测路径数目 \times 未覆盖链路率 $ | (3) |
优选系数ρ选取时, 综合考虑如下3个因素:(1) 尽可能少地对待测ρ IP网络下的路由器进行探针部署; (2) 尽可能地减少对IP网络的额外流量注入, 对尽可能少的E2E路径发包探测; (3) 尽可能多地覆盖待测IP网络中的链路.本文提出一种DTV的选取策略:在保证链路覆盖率的情况下, 以参数ρ取得最小值时对应的DTV值作为获取E2E探测路径及探针部署节点的依据.即:
| $ DT{V_{{\rm{optimal}}}} = \min (DTV{{\rm{|}}_{\arg \min (\rho )}}) $ | (4) |
另外, 可以根据实际情况对式(3) 中的3个参数进行优选.例如:当以覆盖最大范围的链路为目标时, 应该以参数“未覆盖链路数/率”最小作为最重要的选取依据.
4 拥塞贝叶斯网模型及拥塞选路矩阵构建贝叶斯网模型是一个有向无环图(directed acyclic graph, 简称DAG), 可用式(5) 表示.
| $ G = (\nu, \varepsilon ) $ | (5) |
其中, ν代表节点, ε代表连接节点的有向边.在贝叶斯网中, 每个节点储存一个条件概率表, 当该节点为已知的证据节点时, 条件概率表为节点的先验概率分布.根据图中的因果关系以及一致的条件概率和先验概率, 可通过证据节点推理未知的隐藏节点状态.对IP网络进行贝叶斯网模型构建时, E2E路径的状态变量集合${\boldsymbol{\rm{Y}}} = ({y_1}, \ldots, {y_i}, ..., {y_{{n_p}}})$为贝叶斯网中的观测节点.各E2E路径途经链路的状态变量${\boldsymbol{\rm{X}}} = ({x_1}, \ldots, {x_j}, ..., {x_{{n_c}}})$为隐藏节点.为了进行拥塞链路推理, 需要对待测IP网络构建推理时刻的拥塞贝叶斯网模型.
定义2. E2E路径Pi拥塞, 其状态变量yi=1;正常, yi=0.同理, 链路拥塞, 其状态变量xj=1;正常, xj=0.

|
Fig. 5 Bayesian network model in IP network of Fig.2 图 5 图 2所示IP网络贝叶斯网推理模型 |
其中, 对待测IP网络进行拥塞链路推理时, 由于拥塞链路所在路径必为拥塞路径, 为简化推理过程, 可不考虑IP网络中的正常路径及途经链路.
定义3. 对待测IP网络构建的贝叶斯网模型中去除各E2E探测正常路径(观测节点)及途经链路(隐藏节点)以及连接有向边, 即得到待测IP网络的拥塞贝叶斯网模型.
本文关于拥塞链路的推理过程包括对两个拥塞贝叶斯网模型的构建过程.分别为IP网络链路拥塞先验概率学习过程中的拥塞贝叶斯网模型构建以及拥塞链路推理过程中的拥塞贝叶斯网模型的构建.
4.1 学习过程中拥塞选路矩阵构建在链路拥塞先验概率学习过程中, 借助拥塞选路矩阵作为系统线性方程组中的系数矩阵.因此, 需要对学习过程中贝叶斯网模型及拥塞选路矩阵D''进行构建.通过对待测IP网络各E2E路径进行N次snapshots, 当路径拥塞次数不超过设定阈值PCT(path congestion time)时, 则该路径正常, 途经链路也均正常.反之, 该路径拥塞.参数PCT的大小可根据网络用户或管理者对待测IP网络拥塞容忍程度进行设置, 如对网络性能要求很高, 则可设置PCT=0.即N次snapshot中只要有1次探测中路径发生拥塞, 则路径拥塞.将正常路径及途经链路从图 3所示IP网络贝叶斯网模型中去除, 即可得到链路拥塞先验概率学习过程中的拥塞贝叶斯网模型.
将N次E2E路径snapshots中正常路径及途经链路对应的矩阵行及列从线性无关化简选路矩阵D'中移除, 并再次进行线性无关化简, 即可得到待测IP网络在链路拥塞先验概率学习过程中的拥塞选路矩阵D''.如对图 2所示IP网络进行N=30次E2E路径探测, 路径P2始终保持正常, 则路径P2及途经链路L1, L4及L6对应的状态变量x1, x4, x6及连接有向边可从图 3所示的IP网络贝叶斯网模型中移除, 移除后可得到先验概率求解过程中的拥塞贝叶斯网模型, 如图 6所示.

同样, 对去相关化简矩阵D'中移除拥塞路径对应的矩阵行及列, 移除后的矩阵为D1'.
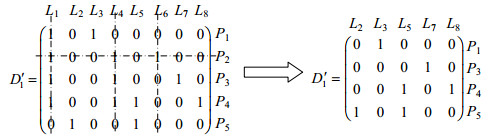
|
(6) |
对矩阵D1'去相关化简后可得D'', 本例中D''=D1',如式(7) 所示.
| $ \begin{array}{l} {L_2}_\;{L_3}_\;{L_5}_\;{L_7}_\;{L_8}\\ D'' = \left( {\begin{array}{*{20}{c}} 0&1&0&0&0\\ 0&0&0&1&0\\ 0&0&1&0&1\\ 1&0&1&0&0 \end{array}} \right) \end{array} $ | (7) |
从图 6可以看出, 在推理拥塞链路时, 如路径P1拥塞, 是由链路L3拥塞造成的.同样, 路径P3拥塞, 是由链路L7拥塞造成的.拥塞贝叶斯网模型的构建能够有效地减小拥塞链路推理的复杂度.
4.2 推理过程中拥塞选路矩阵构建在拥塞链路推理过程中, 需要构建剩余拥塞选路矩阵Dd, 对链路拥塞先验概率学习过程中的拥塞贝叶斯网模型中对应的拥塞路径进行1次E2E性能探测snapshots, 得到各E2E路径的性能结果, 并从学习过程中的拥塞贝叶斯网模型中移除探测结果为正常的路径及途经链路对应的节点及有向边, 即可获取当前拥塞链路推理时刻剩余拥塞贝叶斯网模型.同样, 将链路拥塞先验概率学习过程中构建的拥塞选路矩阵D''中移除推理时刻正常路径及途经链路对应的矩阵行及矩阵列, 则线性无关化简后即可得到待测IP网络在拥塞链路推理过程中的剩余拥塞选路矩阵Dd.如图 2所示的IP网络, 在推理过程中, 如测得路径P4为正常路径, 则剩余拥塞选路矩阵Dd如式(8) 所示.
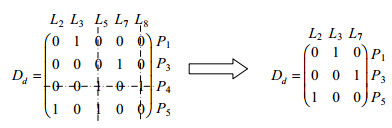
|
(8) |
本文基于Boolean tomography拥塞链路推理框架, 对当前推理时刻拥塞链路推理前, 先对待测IP网络多链路拥塞场景下的各链路进行拥塞先验概率学习.提出利用矩阵特性, 对IP网络构建的选路矩阵D进行去相关化简, 减少矩阵行数, 即:减少了E2E发包探测路径数.化简后, 矩阵D'列数不变, 链路覆盖范围保持不变.根据N次snapshots, 移除正常路径及途经链路对应的矩阵行及列后, 再次化简后得到矩阵D''.矩阵D''将作为链路拥塞先验概率求解线性方程组中的系数矩阵, 经两次化简操作, 大大降低了Boolean线性方程组求逆计算的复杂性.
IP网络拥塞路径的传输率等于该路径途经各链路传输率的乘积[22].如式(9) 所示.
| $ {\Psi _i} = \prod\limits_{j = 1}^{{n_\varepsilon }} {{\varphi _j}^{{{D''}_{ij}}}} $ | (9) |
其中, ${\Psi _i}$为第i条路径整体传输率, ${\varphi _j}$为该路径下途经的第j条链路的传输率, ${D''_{ij}}{|_{{D_{ij}} = \left\{ {0, 1} \right\}}}$为矩阵${D''_{ij}}$第i行第j列的元素值.借助二进制最大化操作“$\vee $”, 可将路径拥塞与链路拥塞关系表示为式(10).
| $ {y_i} = \mathop \vee \limits_{j = 1}^{{n_\varepsilon }} {x_j} \cdot {D''_{ij}} $ | (10) |
对式(10) 两边取数学期望E转换后可得路径拥塞与链路拥塞关系表达式如下.
| $ E[{y_i}] = P\left( {\mathop \vee \limits_{j = 1}^{{n_\varepsilon }} {x_j} \cdot {{D''}_{ij}} = 1} \right) = 1 -P\left( {\mathop \vee \limits_{j = 1}^{{n_\varepsilon }} {x_j} \cdot {{D''}_{ij}} = 0} \right) = 1 -\prod\limits_{j = 1}^{{n_\varepsilon }} {{{(1 -{p_j})}^{{{D''}_{ij}}}}} $ | (11) |
路径拥塞的期望值$E[{y_i}]$可通过N次路径探测得到的每次路径拥塞变量yi={0, 1}求和取平均后得出, 用${\bar y_i}$进行表示.为方便求解, 对式(11) 两边同时取对数, 可得出拥塞贝叶斯网模型下拥塞链路先验概率求解Boolean代数方程组, 如式(12) 所示.
| $ \lg (1- {\bar y_i}) = \lg (1- {P_i}) = \sum\limits_{j = 1}^{{n_\varepsilon }} {{{D''}_{ij}} \cdot [\lg (1-{p_j})]} $ | (12) |
将各E2E路径拥塞概率${P_i}$及拥塞选路矩阵${D''_{ij}}$带入式(12), 即可求得拥塞路径途经各链路的拥塞先验概率${p_j}.$当式(12) 的系数矩阵${D''_{ij}}$非奇异时, 方程组有唯一解.而由于E2E探测路径途经的链路数不止一条, 当探测路径条数过少时, 拥塞选路矩阵${D''_{ij}}$可能欠定.根据拥塞选路矩阵各行为拥塞路径, 各列为拥塞路径途经链路, 如在拥塞链路先验概率学习时, 将N次E2E探测得出的路径性能情况作为一个整体, 任意两条拥塞路径可关联为一条路径, 作为拥塞选路矩阵补满秩所需的扩展路径行.并通过Boolean二进制最大化操作构建拥塞选路矩阵关联路径行.扩展矩阵用${D''_{kj}}$进行表示.将去相关后的拥塞选路矩阵${D''_{ij}}$与其合并, 并再次去相关后可构建系数矩阵满秩的链路拥塞先验概率求解Boolean代数方程组.扩展后的拥塞选路矩阵$D'''$为秩为${n_\varepsilon }$的方阵, k值大小取决于${n_\varepsilon }-{n'_\theta }$的值, ${n_\varepsilon }$为拥塞路径途径的所有链路数, ${n'_\theta }$为拥塞选路矩阵去相关后的路径行数.
| $ D''' = {\left( {\begin{array}{*{20}{c}} {{{D''}_{ij}}}\\ {{{D''}_{kj}}} \end{array}} \right)_{{n_\varepsilon } \times {n_\varepsilon }}} $ | (13) |
如式(7) 即为对图 2所示IP网络构建的4x5矩阵D'', 需要扩展一条路径行完成满秩矩阵$D'''$的构建, 对式(7) 补满秩的结果如式(14) 所示.其中, $D'''$的扩展路径行为路径P4及P5通过Boolean最大化操作获取.
| $ \begin{array}{l} {L_{2}}\;{L_{3}}\;{L_{5}}\;{L_{7}}\;{L_8}\\ D''' = \left( {\begin{array}{*{20}{c}} 0&1&0&0&0\\ 0&0&0&1&0\\ 0&0&1&0&1\\ 1&0&1&0&0\\ 1&0&1&0&1 \end{array}} \right) \end{array} $ | (14) |
由式(14) 可知, 拥塞选路矩阵$D'''$各行分别代表路径P1, P3, P4, P5及扩展路径P45.各列分别为链路L2, L3, L5, L7, L8.求解各E2E拥塞路径途经链路的拥塞先验概率唯一解Boolean代数方程组可转化为式(15) 的形式.
| $ \lg (1- {P_i}) = \sum\limits_{j = 1}^{{n_\varepsilon }} {D'''} \cdot [\lg (1-{p_j})] $ | (15) |
其中, 扩展路径行${\bar y'_{il}}$可通过对两条拥塞路径Pi及Pl根据每次snapshot探测得出的拥塞变量yi及yl进行二进制最大化操作结果求和取平均后获得.为方便表示, 其向量表达如式(16) 所示.
| $ \left[{\begin{array}{*{20}{c}} {\boldsymbol{\rm{y}}}\\ {{\boldsymbol{\rm{y}'}}} \end{array}} \right] = D'''{[\lg (1-{\rm{\boldsymbol{p}}})]^T} $ | (16) |
式(16) 中,
| $ \left. \begin{array}{c} {\bf{y}} = {[\lg (1-{{\bar y}_1}), \lg (1-{{\bar y}_2}), ..., \lg (1-{{\bar y'}_{{n_\theta }}})]^T}, \\ {\bf{y'}} = {\left[{\lg (1-{{\bar y}_{12}}), ..., \lg (1-{{\bar y}_{1{{n'}_\theta }}}), \lg (1-{{\bar y}_{23}}), ..., \lg (1 - {{\bar y}_{2{{n'}_\theta }}}), ..., \lg \left( {1 - {{\bar y}_{\frac{{({{n'}_\theta } - 1){{n'}_\theta }}}{2}}}} \right)} \right]^T}\\ \lg (1 - {\bf{p}}) = {[\lg (1-{p_1}), \lg (1-{p_2}), ..., \lg (1-{p_{{n_\varepsilon }}})]^T} \end{array} \right\} $ | (17) |
但是, 通过随机选取任意两条路径行关联获取扩展路径行补满秩时, 有可能造成补满秩后的拥塞选路矩阵仍存在线性相关行, 而再次导致式(16) 系数矩阵欠定.因此, 在进行方程组求解时, 选择拥塞选路矩阵补满秩后为最大线性无关矩阵所对应的关联路径行进行补满秩操作, 以保证链路拥塞先验概率有解且唯一.
对线性方程组求解的直接解法主要包括:高斯消元法、克拉默法则、直接三角形法、平方根法、追赶法等.但是, 由于直接解法的存储量和计算量很大, 特别是在本文对求解链路拥塞先验概率的线性方程组中.当IP网络规模较大, 主元$D_{kk}^{(k)} = 0$(k=1, 2, …, ${n_{\varepsilon '}}$)时, 则无法计算.即使主元$D_{kk}^{(k)} \ne 0, $但当其绝对值$|D_{kk}^{(k)}|$很小时, 对拥塞选路矩阵求逆时作为除数, 因舍入误差的存在也会带来较大误差.由于IP网络构建的拥塞选路矩阵作为线性方程组系数矩阵, 为Boolean代数模型矩阵, 且非零值较少, 为典型的稀疏矩阵.因此, 本文将稀疏矩阵系数线性方程组求解方法中的迭代法引入到IP网络链路拥塞先验概率求解中.通常, 迭代法求解线性方程组主要包括:雅克比(Jacobi)迭代法、高斯-赛德尔(Gauss-Seidel)迭代法、逐次超松弛(SOR)迭代法、共轭梯度(conjugated garden, 简称CG)迭代法以及加预处理的共轭梯度法(preconditioned conjugated garden, 简称PCG)等.而对求解大型线性方程组以CG迭代法和PCG迭代法为主, 其具有存储量少、计算量小的优点.由于CG算法的收敛速度与系数矩阵的条件数密切相关, 条件数越小, 收敛性越好, 获取的近似解精度越高.但当系数矩阵的条件数很大时, 收敛速度就会变慢.由于对称逐次超松弛(symmetric successive over relaxation, 简称SSOR)分裂中具有对称因子, 可用于加速共轭梯度法.因此, 本文提出采用SSOR分裂预处理的共轭梯度(preconditioned conjugated garden based on SSOR, 简称PCG_SSOR)迭代算法, 通过引入预处理矩阵M, 使链路拥塞先验概率求解线性方程组中的特征值分布更集中, 从而降低矩阵条件数, 提高共轭梯度迭代法的收敛速度和求解精度.
首先, 将链路拥塞先验概率求解线性方程组中去相关, 补满秩后的拥塞选路矩阵系数$D'''$分裂为$D''' = {D_{sd}}-{C_L}-C_L^T.$其中, ${D_{sd}} = {\rm{diag}}({D'_{11}}, {D'_{22}}, ..., {D'_{kk}}, ..., {D'_{{n_\varepsilon }{n_\varepsilon }}}), $CL为严格的下三角矩阵, 则预处理矩阵C为
| $ C = \frac{1}{{\sqrt {\omega (2-\omega )} }}(D'''-\omega {C_L}){D'''^{-\frac{1}{2}}} $ | (18) |
其中, $\omega (0 \le \omega \le 1)$是参数, 所得SSOR预处理矩阵M如式(19) 所示.
| $ M \approx C{C^T} = \frac{1}{{\sqrt {\omega (2-\omega )} }}({D_{sd}}-\omega {C_L}){D_{sd}}^{-1}{({D_{sd}} - \omega {C_L})^T} $ | (19) |
在链路拥塞先验概率的求解过程中, 对图 2所示IP网络优选出的各E2E路径进行30次性能探测, 如本例中:各E2E路径拥塞次数分别为13, 1, 0, 16, 15, 由此可得各E2E路径拥塞概率P1=0.247, P2=0.0125, P4=0.331, P5= 0.301, 将各路径拥塞概率及式(13) 所得D'''代入式(16), 利用PCG_SSOR算法求出链路L2, L3, L5, L7及L8的拥塞先验概率:p2=0, p3=0.4338, p5=0.5, p7=0.0339, p8=0.0667.
6 拥塞链路推理算法LRSBMAP在对当前时刻IP网络拥塞链路推理时, 根据1次snapshots获取各E2E路径性能, 将正常路径及途经链路从拥塞贝叶斯网模型中去除, 可得到剩余拥塞贝叶斯网模型及剩余拥塞选路矩阵.将拥塞链路集推理过程归纳为SCP的求解过程, 由于SCP是NP Hard问题[23], 本文提出一种基于贝叶斯最大后验概率(BMAP)改进的拉格朗日次梯度算法LRSBMAP以求解拥塞链路集合最优解.
6.1 推理模型建立在对当前IP网络进行拥塞链路推理时, 根据主动E2E发包探测获取当前时刻拥塞路径及途经链路, 当前时刻IP网络拥塞链路推理问题可以表述为:根据当前时刻各E2E路径探测结果, 确定可能发生拥塞的链路集合${\rm{\boldsymbol{X}}} \subseteq {\rm{\boldsymbol{S}}}, $使其后验拥塞概率最大, 即求解argmaxP(X|Y).
| $ \arg \max P({\bf{X|Y}}) = \arg \max \frac{{P({\bf{X}}, {\bf{Y}})}}{{P({\bf{Y}})}} $ | (20) |
式(20) 中, 由于$P({\bf{Y}})$仅与网络状态及E2E探测结果有关, 与链路选取无关, 可简化为
| $ {\mathop{\rm argmax}\nolimits} P({\bf{X}}|{\bf{Y}}) = {\mathop{\rm argmax}\nolimits} P({\bf{X}}, {\bf{Y}}) = {\mathop{\rm argmax}\nolimits} \left\{ {\prod\limits_{i = 1}^{{n_{\theta '}}} {P[({y_i}|{p_a}({y_i})]} \prod\limits_{j = 1}^{{n_{\varepsilon '}}} {P({x_j})} } \right\} $ |
其中, ${n_{\theta '}}$为推理时刻剩余拥塞路径总数, ${n_{\varepsilon '}}$为推理时刻剩余拥塞路径途经链路总数, ${p_a}({y_i})$为拥塞贝叶斯网中${y_i}$的父节点.$P({x_j})$为链路${x_j}$先验概率.由于各E2E路径性能测量结果正常时, 途经所有链路状态均正常; 各E2E路径性能测量结果拥塞时, 路径途经链路至少有一条发生拥塞.从而有, E2E路径状态变量与途经各链路状态变量间存在如下概率关系:
| $ P({y_i} = 0|{p_a}({y_i}) = \{ 0, ..., 0\} ) = 1, P({y_i} = 1|\exists {x_i} = 1 \cap {x_i} \in {p_a}({y_i})) = 1 $ | (22) |
对当前E2E路径探测结果进行全网各链路拥塞联合概率求解表达式服从贝努利概型中二项概率公式:
| $ {P_n}(k) = C_n^k{p^k}{(1-p)^{(n-k)}} $ | (23) |
由于当前时刻仅对待测IP网络各E2E路径进行1次snapshots性能测量, n=1.且各链路状态概率均为独立分布, 由式(22)、式(23), 借助第4节求得待测IP网络各链路拥塞先验概率pj, 可得式(24).
| $ \mathop {\arg \max }\limits_{} P({\bf{X}}|{\bf{Y}}) = \mathop {\arg \max }\limits_{} P({\bf{X}}) = \mathop {\arg \max }\limits_{} \prod\limits_{j' = 1}^{{n_{\varepsilon '}}} {p_j^{x_j^{}} \cdot } {(1-p_j^{})^{(1-x_j^{})}} $ | (24) |
为研究方便, 对式(24) 两边取对数, 可得式(25).
| $ {\mathop{\rm argmax}\nolimits} \sum\limits_{j = 1}^{{n_{\varepsilon '}}} {[{x_j} \cdot \lg {p_j} + (1-{x_j}) \cdot \lg (1-{p_j})}] = {\mathop{\rm argmax}\nolimits} \sum\limits_{j = 1}^{{n_{\varepsilon '}}} {\left[{{x_j} \cdot \lg \frac{{{p_j}}}{{1-{p_j}}} + \lg (1-{p_j})} \right]} $ | (25) |
其中, 第2项$\lg (1-{p_j})$的取值与链路状态${x_j}$的取值无关, 故argmaxPp(X|Y)可由式(26) 求得.
| $ \arg \max {P_p}({\bf{X}}|{\bf{Y}}) = \arg \max \sum\limits_{j = 1}^{{n_{\varepsilon '}}} {\left( {{x_j} \cdot \lg \frac{{{p_j}}}{{1- {p_j}}}} \right)} = \arg \min \sum\limits_{j = 1}^{{n_{\varepsilon '}}} {\left[{{x_j} \cdot \left( {-\lg \frac{{{p_j}}}{{1-{p_j}}}} \right)} \right]} $ | (26) |
可将式(26) 归纳为SCP, 求解式(27).
| $ \left\{ \begin{array}{l} {z_{sc}} = \arg \min \sum\limits_{j = 1}^{{n_{\varepsilon '}}} {{c_j}{x_j}, \;\;\;\;{\rm{ }}{c_j} = - \lg \frac{{{p_j}}}{{1 - {p_j}}}} \\ {\rm{s}}{\rm{.t}}.\sum\limits_{j = 1}^{{n_{\varepsilon '}}} {{D_{d_{ij}^{}}}{x_j}} \ge 1, {\rm{ }}i = 1, 2, ..., {n_{\theta '}}\\ {x_j} \in \{ 0, 1\}, {\rm{ }}j = 1, 2, ..., {n_{\varepsilon '}} \end{array} \right. $ | (27) |
式(27) 的求解问题转化为NP Complete问题[21], 对于大规模IP网络, 当拥塞选路矩阵维数过大时, 现有的最优化算法均无法在多项式时间内得到最优解.一种折衷的方法是利用启发式算法在可接受的计算时间内得到问题的近优解.本文基于BMAP改进拉格朗日松弛次梯度算法LRSBMAP, 对IP网络拥塞链路覆盖集进行推理.
根据拉格朗日松弛理论[24, 25], 式(27) 可松弛为如下优化问题.
| $ \left\{ \begin{array}{l} {z_{LRSC}}({\bf{u}}) = \arg \min \sum\limits_{j = 1}^{{n_{\varepsilon '}}} {{d_j}{x_j} + \sum\limits_{i = 1}^{{n_{\theta '}}} {{u_i}} }, \\ {x_j} \in \{ 0, 1\}, {\rm{ }} \end{array} \right.j = 1, 2, ..., {n'_\varepsilon } $ | (28) |
式中, 拉格朗日乘子${d_j} = {c_j}-\sum\limits_{i = 1}^{{n_{\theta '}}} {{u_i}} {D_{d_{ij}^{}}}, {u_i} \ge 0, i = 1, 2, ..., {n_{\theta '}}.$对初始SCP优化算法中的一个有效的下界是当${d_j} \le 0$时, ${x_j} = 1, $反之, ${x_j} = 0.$即:
| $ {Z_{LB}} = \sum\limits_{j = 1}^{{n_{\varepsilon '}}} {\min (0, {d_j})} + \sum\limits_{i = 1}^{{n_{\theta '}}} {{u_i}} $ | (29) |
令${z_{LD}}, {z_{UB}}, {z_{LB}}$分别代表算法已搜索到的下确界值、式(27) 最优可行解对应的最优值、式(28) 某可行解对应的最优值.本文提出LRSBMAP算法伪代码如下.
LRSBMAP算法.
输入:推理时刻拥塞路径集合Pi及途经链路集合Lj, 拥塞选路矩阵Dd;
Lj中各链路lj先验拥塞概率pj.
Step 1:初始化${z_{LD}} =-\infty, {z_{UB}} = \infty, {u_i} = \min [{c_j}|{D_{d_{ij}^{}}} = 1, j = 1, 2, ..., {n'_\varepsilon }], i = 1, 2, ..., {n'_\theta }; $
Step 2:用当前的u求解式(28), 令其最优值为${z_{LB}}, $更新${z_{LD}} = \max ({z_{LD}}, {z_{LB}}); $
Step 3:构造原始SCP的一个可行解:
(1) 令$S = [j|{x_j} = 1, 2, ..., {n'_\varepsilon }]; $
(2) 对未覆盖的行i(即:$\sum\limits_{j = 1}^{{{n'}_\varepsilon }} {{D_{d_{ij}^{}}}{x_j}} = 0), $将对应于$\min [j|{D_{d_{ij}^{}}} = 1, {d_j} < \infty, j = 1, 2, ..., {n'_\varepsilon }]$的j添加到S;
(3) 将j∈ S按降序排列.如:$S-[j]$仍然是SCP的可行解, $S = S-[j]; $
(4) 更新${z_{UB}} = \min \left({{z_{UB}}, \sum\limits_{j \in S} {{c_j}} } \right).$
Step 4: ${z_{LD}} = \max {z_{LRSC}}({\bf{u}}), {z_{LD}} = {z_{UB}}, $ If ${z_{LD}} = {z_{UB}}, $转Step 9;
Step 5:计算次梯度${g_i} = 1-\sum\limits_{j = 1}^{{{n'}_\varepsilon }} {{D_{d_{ij}^{}}}{x_j}} {, ^{}}i = 1, 2, ..., {n'_\theta }.$ If $\sum\limits_{i = 1}^{{{n'}_\theta }} {{{({g_i})}^2}} = 0.$转Step 9;
Step 6:计算迭代步长$\delta = f(1.05{z_{UB}} - {z_{LB}})/\sum\limits_{i = 1}^{{{n'}_\theta }} {{{({g_i})}^2}} ,$其中, 初始值$f(0) = 2, $ If ${z_{LD}}$连续30次迭代中没有增加, 将f减半;
Step 7: If $f \le 0.005, $转Step 9;
Step 8:更新拉格朗日乘子${u_i} = \max [0, {u_i} + \delta {g_i}]{, ^{}}i = 1, 2, ..., {n'_\theta }, $转Step 2;
Step 9: 输出${L_j} = \{ {l_j}|x_j^{} = 1\}.$
7 实验验证对Internet拓扑结构的研究, 前人已经做了很多工作, 从最初的随机图模型代表Waxman[26]到Barabási, Albert等人[27, 28]提出的无标度网络模型BA, 再到Bu等人提出的基于节点度的幂率分布特征模型GLP[29], 人们都试图去发现和解析Internet拓扑演化的规律.因此, 为了验证推理算法的有效性及准确性, 本文借助Brite拓扑生成器[30], 分别生成Waxman、BA及GLP这3种不同类型、不同规模的IP网络拓扑.其中, Waxman模型是基于随机图模型的代表, 模型中的节点度数值随着节点数量的增加而增加, 但随机图模型无法生成节点众多但节点平均度值较小的网络.因IP网络规模的不断扩大, 当新的路由器节点加入Internet网络时, 通常倾向于与具有高度数值的“大节点”连接.基于这两个特征构造具有度分布呈幂率特征的无标度网络模型BA及GLP.3种拓扑网络模型均体现了Internet特性, 为了更好地验证本文提出算法在不同Internet环境中的拥塞链路推理性能, 分别在3种网络拓扑模型下进行了算法比较实验验证.
通过Eclipse平台将拓扑模型导入完成待测网络构建, 利用各推理算法进行拥塞链路推理实验验证.在进行拥塞链路推理实验时, 模拟实际IP网络路由算法最短路径优先原则, 模拟ICMP协议分别进行snapshots(包括Traceroute及Ping), 获取E2E路径及途经链路以及各E2E路径性能测量值, 本文利用随机数模型RNM(random number model)模拟待测IP网络每次snapshots中算法覆盖链路产生的拥塞事件.
7.1 算法参数设置及评价指标本文提出算法中各参数设置主要包括:DTV——路由器度值≤DTV时, 该路由器作为预选收发包路由器, 根据ρ值自动优选DTV; PCT——N次E2E路径探测中, 拥塞次数≤PCT的路径正常.算法默认设置N=30, PCT=0; LCR(link congestion ratio)——LRSBMAP算法模拟实验中设置参数.即:拥塞链路占算法覆盖链路的比例, 取值范围为[0, 1].通过选取各链路随机数赋值由大到小根据LCR得到每次snapshots的拥塞链路.利用检测率DR及误报率FPR, 对本文提出的LRSBMAP算法推理拥塞链路的结果进行评估.为了减小随机数模型对算法推理性能的影响, 每组实验中, DR及FPR均为各参数设置不变情况下10次实验结果取平均值后所得结果.
DR及FPR计算公式如式(30) 所示.
| $ DR = \frac{{F \cap X}}{F}, FPR = \frac{{X\backslash F}}{X} $ | (30) |
其中, F为实际拥塞链路, X为算法推理出的拥塞链路.
7.2 模拟实验流程模拟实验流程如下文图 7所示.

|
Fig. 7 Flow diagram of analog experiment 图 7 模拟实验流程 |
7.3 LCDTV实验结果分析
为了验证本文提出的LCDTV算法在E2E路径及探针部署获取中的有效性.利用Brite拓扑生成器模拟不同类型、不同规模的IP网络模型.传统算法中, E2E路径的收发包路由器为叶子节点, 通过E2E路径的发包探测, 对链路进行覆盖, 其方法相当于LCDTV算法中DTV=1时覆盖的E2E路径及链路.
(1) Waxman模型
利用Brite拓扑生成器以默认参数生成150个节点, 300条链路的Waxman模型, 通过选取不同DTV值, 基于最短路径优先原则进行E2E路径及发包探针获取, 从E2E路径中去除方向相反链路所在路径, 不同DTV下, 通过本文提出的优选策略获取的E2E路径数、覆盖链路数(覆盖率)、发包探针部署数及优选参数ρ的计算结果见表 3.
| Table 3 Performance comparision of LCDTV under the different DTV (Waxman model) 表 3 不同DTV下LCDTV算法性能比较(Waxman模型) |
如表 3所示, DTV=4时, ρ取得最小值, 此时, 覆盖链路285条, 覆盖率95%, E2E探测发包路径数为276条, 需要部署发包探针30个.因Waxman模型路径较长, 途经链路较多, E2E路径数较链路数少, 需要借助本文提出方法对链路拥塞先验概率求解Boolean线性方程组补满秩.由于默认参数生成的Waxman网络模型中没有度值为1的节点, 因此传统算法以度值最小的端主机作为E2E路径及链路覆盖的路由器, 链路覆盖率最低.根据Waxman模型结构特点, 利用LCDTV算法在优选系数ρ取得最小值时, 链路覆盖范围最广, 且兼顾了硬件探针部署开销及发包探测对IP网络的额外流量注入.
(2) GLP模型
由于IP网络规模的不断扩大, 当前IP网络拓扑结构表现出较强的幂率特性.因此, 利用Brite拓扑生成器以默认参数生成200个节点的GLP模型(链路354条, 叶子节点148个, 节点度数最大值47).利用传统算法及本文提出的LCDTV算法分别进行E2E路径及链路获取, 通过实验, 算法优化前后的E2E路径数、覆盖链路数(覆盖率)、发包探针部署数及优选参数ρ的计算结果见表 4.
| Table 4 Performance comparisons of LCDTV under the different DTV (GLP model) 表 4 不同DTV下算法LCDTV优化前后性能比较(GLP模型) |
由表 4可知, 对200个节点的GLP模型进行链路覆盖, 由于强幂率模型下的IP网络, 路径途径链路数较少, 因此, 传统算法仅通过叶子节点进行链路覆盖时, 因路由算法中最短路径优先原则, 不能有效覆盖待测IP网络中尽可能多的链路, 链路覆盖率仅为58%.LCDTV算法通过改变DTV参数, 覆盖链路有一定程度的提高.随着IP网络规模的激增, 实验发现, 利用LCDTV改进方法, 运行时间明显缩短, 但链路覆盖率变化不大.当DTV=3时, $\min (\rho {|_{DTV{\rm{ = }}3}}) = 0.671, $此时, 链路覆盖率为75.6%, 较传统算法提高了17.6%.虽然DTV=2时, ρ值更小, 但是链路覆盖率不超过70%, 为了覆盖IP网络中更多的链路, 可选择ρ次小值作为LCDTV算法中最优DTV值选取的依据.通过对不同模型下参数ρ值计算结果的分析, 当ρ取得最小或次小值时, 能够兼顾链路覆盖率、探针部署及E2E发包路径数, 验证了本文E2E路径及探针部署优化中参数ρ设置的有效性.
7.4 PCG_SSOR实验结果分析为了验证PCG_SSOR迭代算法在一定规模IP网络下的链路拥塞先验概率求解性能, 模拟500个节点的Waxman(1 000条链路), BA(997条链路)及GLP(923条链路)IP网络模型.其中, CLR=0.1.首先, 对3种不同模型基于最优度值进行探针部署, 分别覆盖链路数958, 937及703条.利用误差曲线对PCG_SSOR, CG及SSOR算法进行比较.误差限均设置为10-3.在不同IP网络模型下, 模拟30次链路拥塞事件, 利用3种不同迭代算法求解链路拥塞先验概率, 各算法的误差曲线如图 8所示.

|
Fig. 8 Comparisons of iteration algorithm error curves under the different models 图 8 不同模型下各迭代算法误差曲线比较 |
表 5为500个节点规模、不同类型的网络模型下, 拥塞先验概率迭代求解运行时间结果.实验结果均是在i7-5600U CPU, 8G内存, 64位Win7操作系统LenovoX250下运行所得.
| Table 5 Comparisons between iterations and operation time under the different algorithms 表 5 不同算法迭代次数及运行时间比较 |
由表 5可知, 在相同误差限10-3下, 在3种不同类型的网络模型下, SSOR, CG及PCG_SSOR迭代算法均能在2 000次迭代内实现算法收敛.PCG_SSOR算法迭代次数最少, 收敛速度最快, 运行时间最短.通过实验发现, 在一定规模的IP网络多链路拥塞场景下, 传统Gauss消元法及Jacobi迭代算法不能有效地实现链路拥塞先验概率的求解.
7.5 LRSBMAP实验结果比较分析为了验证本文提出的LRSBMAP算法在拥塞链路推理中的有效性及准确性.利用Brite拓扑生成器以默认参数模拟不同类型, 规模的IP网络模型Waxman、BA及GLP, 并与CLINK算法进行推理性能比较.
(1) 不同CLR对算法推理性能的影响
对于150个节点规模的IP网络模型, CLR从0.05~0.6发生变化, 两种算法在最优DTV下DR及FPR如图 9所示.

|
Fig. 9 Inference performance comparisons under the different CLR (node number=150) 图 9 不同CLR下, 两种算法的推理性能比较(节点数=150) |
在不同类型的IP网络模型下, LRSBMAP算法的推理性能优于CLINK算法.随着CLR的增大, DR均呈下降趋势.两种算法的DR均在GLP模型下最高, 其次是BA及Waxman模型.这与IP网络模型拓扑结构有直接关系, 因Waxman为随机模型, 路径较长, 而BA及GLP为幂率模型, 网络中部分路由器度值较大, 共享链路数较Waxman模型中要多.因此, 在Waxman模型下, DR较GLP及BA模型有明显下降.当CLR < 0.2时, LRSBMAP及CLINK算法在GLP及BA模型下的推理性能相差不大.但是, 当CLR > 0.2时, LRSBMAP算法在Waxman, BA及GLP模型下, 其推理性能均优于CLINK算法, 并且随着CLR的增大, 推理性能的优势更加明显.体现出LRSBMAP算法在多链路拥塞下的性能优势.随着CLR的增大, LRSBMAP算法的性能下降较CLINK算法趋缓.当CLR=0.5时, CLINK算法在GLP及BA模型下的DR不足55%, 在Waxman模型下仅有40%;LRSBMAP算法在GLP模型下的DR仍保持在75%左右, 在BA及Waxman模型下分别为65%和55%以上.两种算法均在GLP模型下的FPR最低, 其次是BA及Waxman模型.随着CLR的增大, FPR均先呈缓慢上升趋势, 当CLR达到一定比例时, FPR呈下降趋势.
(2) 不同网络规模对算法的影响
为了验证算法在不同IP网络类型、不同规模下的推理性能.利用Brite生成节点数50~500的Waxman、BA及GLP网络拓扑模型.设置多链路拥塞场景, CLR=0.5.LRSBMAP算法及CLINK算法的DR及FPR如图 10所示.

|
Fig. 10 Inference performance comparisons under the different network scales (CLR=0.5) 图 10 不同网络规模下, 两种算法的推理性能比较(CLR=0.5) |
由图 10可见, 在不同类型、不同规模的IP网络模型下, 两种算法的推理性能均随网络规模的扩大呈缓慢下降趋势.其中, LRSBMAP算法对Waxman, BA及GLP模型推理性能均优于CLINK算法, 在GLP模型下, DR最高, 其次是BA及Waxman模型.在GLP模型下, FPR最低, 其次是BA及Waxman模型.两种算法在Waxman, BA及GLP模型下的推理FPR均随着IP网络规模的扩大, 基本保持稳定.在GLP模型下的FPR均较BA及Waxman模型下要低.在3种不同网络模型下, LRSBMAP与CLINK算法的拥塞链路推理FPR差距不大, 当CLR=0.5时, LRSBMAP算法的FPR平均值略高于CLINK算法.
(3) 不同DTV对算法推理性能的影响
假设IP网络CLR=0.5, 通过本文优选E2E探测路径及部署点方法, DTV从模型最小度值增大到待推理IP网络中路由器最大度值.得到不同的链路覆盖范围, 借助CLINK及LRSBMAP算法分别进行拥塞链路推理.在利用Brite拓扑生成器以默认参数生成的Waxman模型中, 路由器度值范围为2~14, BA模型中, 路由器度值范围为2~33, GLP模型中, 路由器度值范围为1~33.因此, 选取DTVWaxman∈ [2, 14], DTVBA∈ [2, 33], DTVGLP∈ [1, 33].按照本文对E2E路径获取优化策略进行E2E路径获取及链路覆盖.对Waxman模型, 当DTV=8~10及12~14时, E2E探测路径数及覆盖链路保持不变; 对BA模型, 当DTV=12~15及16~33时, E2E探测路径数及覆盖链路保持不变; 对GLP模型, 当DTV=5~7及9~33时, E2E探测路径数及覆盖链路不变.因此, 为了便于在同一坐标系下比较LRSBMAP算法在3种不同网络模型下的拥塞链路推理性能, 以DTV选取1~16作为横轴坐标刻度点.当CLR=0.5时, 在3种不同的网络模型下, LRSBMAP及CLINK算法的推理性能如图 11所示.

|
Fig. 11 Inference performance comparisons under the different DTV (CLR=0.5) 图 11 不同DTV下, 两种算法的推理性能比较(CLR=0.5) |
由图 11可见, 当DTV选取叶子节点或端主机进行探针部署, 通过snapshots对各E2E路径发包探测时, 对GLP及Waxman模型的链路覆盖范围不足, DR下降得明显, FRP较高.而对于150个节点的BA模型, 当进行DTV优选时, 因DTVoptimal=2, 是BA模型中路由器度值的最小值.此时, 链路覆盖率较高, 算法推理性能不受影响.通过对不同DTV的选取发现, 当推理算法对链路覆盖比例达到一定范围后, 推理算法对IP网络拥塞链路推理性能均趋于稳定, 算法推理性能与算法链路覆盖范围之间有一定的联系.
实验结果表明, 本文提出的LRSBMAP算法在推理性能上较CLINK算法有一定程度的提高.原因如下.
(1) CLINK算法认为, 链路包含在越多的E2E路径中, 越有可能是发生拥塞的链路;
(2) CLINK算法推理过程中, 如已确定某E2E路径途经的某条链路为拥塞链路, 则该路径及包含该链路的其他路径将从待推理的候选路径集合中去除.显然, 这两个拥塞链路推理策略是存在一定问题的.
虽然共享路径最多的链路是最容易拥塞的链路(瓶颈链路).但是, 如非瓶颈链路或共享路径较少的链路发生拥塞时, 如其拥塞先验概率较大, CLINK算法中通过引入共享数目|domain(ek)|的权重, 即便瓶颈链路的拥塞先验概率较小, 加权后仍被认为是最容易拥塞的链路, 推理结果可能存在误差.另外, 由于确定某路径中最有可能发生拥塞的链路后, 该路径将不再作为候选路径进行该路径下其他链路性能的推理, 除非被去除的链路仍存在于其他待推理的候选路径中, 否则, 将也不再被作为候选链路被推理.因此, LRSBMAP算法的推理精度较CLINK算法有一定程度的提高, 特别是当IP网络E2E路径中同时存在多条链路拥塞的场景下, CLINK算法的推理性能较本文提出的LRSBMAP算法有一定幅度的降低.
8 总结及展望本文提出一种大规模IP网络多链路拥塞场景下的拥塞链路推理算法LRSBMAP.通过度阈值优选, 兼顾链路覆盖率, E2E探测路径数及探针部署开销, 尽可能多地覆盖待测链路; 借助矩阵特性, 基于Boolean代数线性方程组系数矩阵稀疏性提出PCG_SSOR算法, 迭代求解各链路拥塞先验概率近似唯一解; 基于推理时刻剩余拥塞选路矩阵及BMAP准则, 提出利用改进的拉格朗日松弛次梯度算法推理最有可能发生拥塞的链路集合.实验验证了本文提出算法的准确性及鲁棒性.
考虑到当前IP网络中各AS区域多为动态路由算法, 在可用带宽下降的情况下, 将引起路由的动态变化.而当路由改变时, 拥塞链路推理时拥塞路径途经的链路可能并不包含在链路拥塞概率学习时的链路集合中.因此, 根据IP网络选路矩阵构建的贝叶斯网模型结构可能会发生变化, 导致推理性能下降.如何准确学习动态路由下各链路的拥塞先验概率, 并进行当前时刻拥塞链路定位推理和性能推断, 是未来课题的研究方向.
| [1] | Pan SL, Yang XR, Zhang ZY, Qian F, Hu GM. Congestion link identification under multipath routing for single-source networks.Journal of Electronics & Information Technology, 2015, 37(9): 2232–2237(in Chinese with English abstract). [doi:10.11999/JEIT150058] |
| [2] | Padmanabhan VN, Qiu LL, Wang HJ. Server-Based inference of Internet performance. Technical Report, MSR-TR-2002-39, Redmond:Microsoft Corporation, 2002. 1-12. |
| [3] | Duffield NG. Network tomography of binary network performance characteristics.IEEE Trans. on Information Theory, 2006, 52(12): 5373–5388. [doi:10.1109/TIT.2006.885460] |
| [4] | Nguyen HX, Thiran P. The Boolean solution to the congested IP link location problem:Theory and practice. In:Proc. of the IEEE Int'l Conf. on Computer Communications, INFOCOM 2007. Alaska:IEEE, 2007. 2117-2125.[doi:10.1109/INFCOM.2007.245] |
| [5] | Coates M, Hero A, Nowak R, Yu B. Internet tomography.IEEE Signal Processing Magazine, 2002, 19(3): 47–65. [doi:10.1109/79.998081] |
| [6] | Zarifzadeh S, Gowdagere M, Dovrolis C. Range tomography:Combining the practicality of Boolean tomography with the resolution of analog tomography. In:Proc. of the ACM Conf. on Internet Measurement, IMC 2012. Boston:ACM, 2012. 385-398.[doi:10.1145/2398776.2398817] |
| [7] | Ma L, He T, Leung KK, Swami A, Towsley D. Monitor placement for maximal identifiability in network tomography. In:Proc. of the IEEE Conf. on Computer Communications, INFOCOM 2014. Toronto:IEEE, 2014. 1447-1455.[doi:10.1109/INFOCOM.2014.6848079] |
| [8] | Rong ZZ, Jin YH, Cui YD, Yang T. An optimization algorithm for measurement nodes' automatic deployment in distributed network measurement.Chinese High Technology Letters, 2014, 24(11): 1147–1152(in Chinese with English abstract). [doi:10.3772/j.issn.1002-0470.2014.11.008] |
| [9] | Matsuda T, Nagahara M, Hayashi K. Link quality classifier with compressed sending based on l1-l2 optimization.IEEE Communications Letters, 2011, 15(10): 1117–1119. [doi:10.1109/LCOMM.2011.082911.111611] |
| [10] | Pepe T, Ericsson R, Italy P, Puleri M. Network tomography:A novel algorithm for probing path selection. In:Proc. of the IEEE Int'l Conf. on Communications, ICC. London:IEEE, 2015. 5337-5341.[doi:10.1109/ICC.2015.7249172] |
| [11] | Adams A, Bu T, Friedman T, Horowitz J. The use of end-to-end multicast measurements for characterizing internal network behavior.IEEE Communications Magazine, 2000, 38(5): 152–159. [doi:10.1109/35.841840] |
| [12] | Bu T, Duffield FL, Towsley PD. Network tomography on general topologies. In:Proc. of the SIGMETRICS 2002, ACM SIGMETRICS Int'l Conf. on Measurement and Modeling of Computer Systems. London:ACM, 2002, 30(1).[doi:10.1145/511334.511338] |
| [13] | Lawrence E, Michailidis G, Nair V, Xi B. Network tomography:A review and recent developments. Frontiers in Statistics, 2005, 345-366.[doi:10.1142/9781860948886_0016] |
| [14] | Duffield NG, Presti FL, Paxson F, Towsley D. Inferring link loss using striped unicast probes. In:Proc. of the IEEE Computer and Communications Societies, INFOCOM 2001. Anchorage:IEEE, 2001. 915-923.[doi:10.1109/INFCOM.2001.916283] |
| [15] | Malekzadeh A, MacGregor M. Network topology inference from end-to-end measurements. In:Proc. of the 27th IEEE Advanced Information Networking and Applications Workshops, WAINA. Barcelona:IEEE, 2013. 1101-1106.[doi:10.1109/WAINA.2013.215] |
| [16] | Duffield NG. Simple network performance tomography. In:Proc. of the ACM SIGCOMM Conf. on Internet Measurement, IMC 2003. Miami Beach:ACM, 2003. 210-215.[doi:10.1145/948205.948232] |
| [17] | Ghita D, Argyraki K, Thiran P. Network tomography on correlated links. In:Proc. of the ACM SIGCOMM Conf. on Internet Measurement, IMC 2010. Melbourne:ACM, 2010. 225-238.[doi:10.1145/1879141.1879170] |
| [18] | Ghita D, KaraKus C, Argyraki K, Thiran P. Shifting network tomography toward a practical goal. In:Proc. of the 7th Conf. on Emerging Networking Experiments and Technologies, CoNEXT. Tokyo:ACM, 2011. 1-12.[doi:10.1145/2079296.2079320] |
| [19] | Augustin B, Friedman T, Teixeira R. Measuring multipath routing in the Internet. IEEE/ACM Trans. on Networking, 2011, 19(3):830-840.[doi:10.1109/TNET.2010.2096232] |
| [20] | Kim MS, Kin T, Shin Y, Lam SS, Powers EJ. A wavelet-based approach to detect shared congestion.IEEE/ACM Trans. on Networking, 2008, 16(4): 763–776. [doi:10.1109/TNET.2007.905599] |
| [21] | Liu XH, Yin JP, Lu XC, Zhao JM. A monitoring model for link bandwidth usage of network based on weakvertex cover.Ruan Jian Xue Bao/Journal of Software, 2004, 15(4): 545–549(in Chinese with English abstract). http://www.jos.org.cn/1000-9825/545.htm |
| [22] | Shavitt Y, Sun X, Wool A, Yener B. Computing the unmeasured:An algebraic approach to internet mapping.IEEE Journal on Selected Areas in Communications, 2004, 22(1): 67–78. [doi:10.1109/JSAC.2003.818796] |
| [23] | Garey MR, Johnson DS. Computers and Intractability:A Guide to the Theory of NP-Completeness. New York: Freeman Press, 1979. 109-118. |
| [24] | Xing WX, XIE JX. Modern optimization algorithm. 2th ed., Beijing:Tsinghua University Press, 2005. 210-236(in Chinese). |
| [25] | Shakeri M, Pattipati R, Raghavan V, Patterson-Hine A. Optimal and near-optimal algorithms for multiple fault diagnosis with unreliable tests.IEEE Trans. on Systems Man & Cybernetics (Part C:Applications & Reviews), 1998, 28(3): 431–440. [doi:10.1109/5326.704583] |
| [26] | Waxman BM. Routing of multipoint connections.IEEE Journal on Selected Areas in Communications, 1989, 6(9): 1617–1622. [doi:10.1109/49.12889] |
| [27] | Barabási AL, Albert R. Emergence of scaling in random networks.Science, 1999, 286(5439): 509–512. [doi:10.1126/science.286.5439.509] |
| [28] | Albert R, Barabási AL. Topology of evolving networks:Local events and universality.Physical Review Letter, 2000, 85(24): 5234–5237. [doi:10.1103/PhysRevLett.85.5234] |
| [29] | Bu T, Towsley D. On distinguishing between Internet power law topology generators. In:Proc. of the IEEE Computer and Communications Societies, INFOCOM 2002. New York:IEEE, 2010. 638-647.[doi:10.1109/INFCOM.2002.1019309] |
| [30] | Medina A, Lakhina A, Matta I, Byers J. BRITE:An approach to universal topology generation.Modeling, Analysis and Simulation of Computer and Telecommunication Systems, 2001, 28(2): 346–353. [doi:10.1109/MASCOT.2001.948886] |
| [1] | 潘胜利, 杨析儒, 张志勇, 钱峰, 胡光岷. 单源多径路由网络拥塞链路识别. 电子与信息学报, 2015, 37(9): 2232–2237. [doi:10.11999/JEIT150058] |
| [8] | 荣自瞻, 金跃辉, 崔毅东, 杨谈. 分布式网络测量的测量节点自动部署优化算法. 高技术通讯, 2014, 24(11): 1147–1152. [doi:10.3772/j.issn.1002-0470.2014.11.008] |
| [21] | 刘湘辉, 殷建平, 卢锡城, 赵建民. 基于弱顶点覆盖的网络链路使用带宽监测模型. 软件学报, 2004, 15(4): 545–549. http://www.jos.org.cn/1000-9825/545.htm |
| [24] | 邢文训, 谢金星. 现代优化计算方法. 第2版, 北京: 清华大学出版社, 2005. 210-236. |