 2016, Vol. 27
2016, Vol. 27



随着社会网络的快速发展和普及,社会网络中隐私信息的安全性成为当前数据隐私保护研究中的热点问题.为了保护社会网络中的隐私信息,提出了多种社会网络图匿名化技术.图匿名化目的在于通过图修改操作来防止隐私泄露,同时保证匿名图在社会网络分析和图查询方面的数据可用性.可达性查询是一种基本的图查询操作,同时,可达性查询精度是衡量图数据可用性的一项重要指标.然而,当前图匿名技术没有考虑图匿名操作对结点间可达性的影响,导致很大的可达性信息损失.
在社交网站服务(social networking service,简称SNS)中,通常支持两个用户之间的多种关系查询.一种常见的关系查询是可达性查询,即查看两个结点间是否存在一条可达路径.结点可达性是衡量图数据可用性的重要指标,在社会网络中,可达性查询操作更加频繁.例如,很多社会网络(Facebook、QQ朋友网等)均支持人脉联系查询:输入用户u和v,返回u,v之间的可达路径以及路径上包含的用户.显然,此类人脉联系查询的本质是结点间的可达性查询操作.很多社会网络应用基于结点间的可达性来进行好友推荐,提高社会网络的粘度和用户活跃度.因此,保持社会网络中结点间的可达性具有实际意义.然而在实际应用中,社会网络图中的结点可达性由于图匿名而受到严重影响,其主要原因在于当前图匿名技术忽视了图匿名过程中的边操作对结点间可达性的影响.例如,图 1显示了一个虚构的微博网络图G及图中结点的度,其中,din和dout分别表示结点的入度和出度,有向边(a,b)表示用户a收听了用户b.假设攻击者已知Alice没有粉丝并且Alice收听了其他两个用户,即din(Alice)=0和dout(Alice)=2,显然,攻击者可以1 00%的置信度识别出结点a是Alice,因为图中只有结点a具有和Alice相同的度(包括入度和出度).

|
Fig. 1 A social network graph and the degrees 图 1 虚构微博网络G及结点的度 |
文献[1]提出了k-度匿名隐私保护模型来防止结点度作为背景知识的身份识别攻击.所谓k-度匿名,是指对于图中任意结点v,至少有k-1个其他结点与v的度相同,使得攻击者识别结点v真实身份的概率≤1/k.例如,针对图 1(a)中的 G进行图匿名化,得到图 2中的两个2-度匿名图G1和G2.

|
Fig. 2 Two anonymized versions for G 图 2 G的两个匿名图 |
以G1为例,对于G1中的任意结点,至少有另一个结点与其具有相同的出、入度,因此,攻击者基于度来识别结点身份的概率不大于50%.如果结点u到v可达,则称〈u,v〉是一个可达对.虽然G1,G2均为G的2-度匿名图,但是在保持结点可达性方面具有不同效果.具体来说,在G中添加边(g,a)得到G1,导致增加31个新可达对,包括〈g,a〉和〈h,p〉等.而在G2中,仅增加了一个新可达对〈j,a〉.令R(G)表示G中所有可达对的集合,并定义结点到其自身可达.给定图G及其k-匿名图Gk,定义匿名损失Cost(G,Gk)来评估Gk在结点可达性上的数据可用性,具体计算如公式(1)所示.
| $Cost\left( G,{{G}_{k}} \right)=|R\left( G \right)-R\left( {{G}_{k}} \right)\left| + \right|R\left( {{G}_{k}} \right)-R\left( G \right)|$ | (1) |
公式(1)计算了Gk中新增和减少的可达对数目.较大的Cost(G,Gk)数值表示了Gk在结点可达性上的低数据可用性.根据公式(1),可以算得Cost(G,G1)=31和Cost(G,G2)=1,表明G2比G1更好地保持了结点间的可达性.
在本文研究工作中,针对社交网络图G,期望在生成其匿名图Gk的同时最小化匿名损失Cost(G,Gk).本文的主要工作及贡献如下:
(1) 提出了一种保持结点间可达性的社会网络图匿名算法RPA(reachability-preserving-anonymization),在进行图匿名化的同时保证了较小的可达性信息损失;
(2) 提出了可达区间以及相应的生成算法,基于可达区间实现高效评估边操作所导致的匿名损失,提高RPA算法的执行效率;
(3) 通过在结点匿名过程中采用候选邻居索引(CN-index),提高了RPA算法中候选邻居查找效率,加速了RPA算法对每个结点的匿名过程,保证了RPA算法在处理大规模社会网络图数据时的实用性.
本文第1节介绍在社会网络隐私保护方面的相关工作.第2节介绍相关预备知识,同时给出本文的研究问题定义.第3节给出可达性保持图匿名算法RPA,同时从执行效率方面提出RPA算法面临的两大挑战,即为边添加匿名损失评估、选择最小匿名代价出边邻居的问题.针对边添加匿名损失评估问题,第4节提出可达区间定义,基于可达区间实现匿名损失的高效评估.针对选择最小匿名代价出边邻居问题,第5节提出采用候选邻居索引,基于CN-index为结点匿名提出两种结点添加策略:单邻居添加策略和多邻居添加策略,从而优化了结点匿名效率.第6节基于真实社会网络数据,分别从算法执行时间、匿名损失、添加边和结点数目、图结构信息损失等方面进行实验测试.第7节总结全文并给出未来的工作.
1 相关工作在社会网络中,常见的隐私攻击主要分为两种类型:结点识别攻击和链接识别攻击.在结点识别攻击(结点身份泄露)中,攻击者利用攻击目标在网络中所属的子图结构来识别其在社会网络图中的位置,从而导致攻击目标的身份隐私泄露.为了防止结点识别攻击,文献[2]提出通过匿名化每个结点的邻居子图来防止结点身份泄露.在文献[3]中,通过将结点聚类生成超点,从而使位于同一超点内的结点相互间不可区分,实现对超点内每个结点的身份隐私保护.文献[4]提出k-自同构图匿名模型,通过图匿名化操作,使得结点位于同构位置,从而实现结点隐私保护.在链接识别攻击(敏感关系泄露)中,攻击者的目的在于识别出社会网络中实体之间的敏感关系.为了防止敏感关系泄露,文献[5]提出了安全分组技术来保护二部图中的链接隐私,其主要思想是:对二部图中的结点进行分组,并且位于同一分组的结点在边连接方面相互间不可区分, 分组过程中,保证每条边的端点被推演概率小于安全阈值,从而起到边隐私保护的作用.文献[6]在文献[5]的基础上,提出采用结点聚类方法来保护链接隐私.文献[7]提出子图随机化方法来保护有向图中的链接隐私,通过在子图内进行随机图操作,在为边隐私信息提供保护的同时减少图操作对于图数据可用性的影响.文献[8]研究了云环境中的邻居隐私保护技术,并保证发布数据图在最短路径查询方面的数据可用性.文献[9]将攻击目标与公众名人之间的链接作为背景知识的攻击,称为Connection Fingerpring攻击,并设计了两种分别基于添加伪点和边修改的图匿名算法,从而保持社会网络图的高数据可用性.文献[10, 11]提出更加通用的隐私保护机制来同时保护结点和链接隐私信息.文献[10]提出k-同构图匿名模型来同时保护结点隐私和边隐私,其基本思想是:将图分割和重新构建为k个相互同构的子图,使得结点和链接隐私泄露概率均小于1/k.文献[11]给出了一种个性化隐私保护方法,在结点隐私和边隐私方面满足不同隐私保护层次和安全要求.上述研究工作主要防止匹配攻击所导致的隐私泄露,即防止攻击者基于攻击目标的背景知识在社交网络图中采用图匹配技术,从而唯一性确定攻击目标的位置或者边连接.目前,基于概率和推演模型的隐私攻击[12-15]已经引起研究人员关注.文献[13]研究了如何基于社会网络签到数据采用概率模型推演用户的位置隐私,并设计了一种隐私风险预警框架,实时监控可能导致用户位置隐私泄露的位置签到并进行报警.文献[14]针对敏感链接推演攻击,分别提出了防止单步链接推演攻击和级联链接推演攻击算法.文献[15]研究了针对社会网络图中的敏感标签的推演攻击,并提出了防推演算法.文献[16]研究在图匿名过程中如何保持社会网络图在社区划分方面的数据可用性.
可达性查询是图数据上的一种基本查询,同时也是一项热点研究问题,目前,针对可达性查询已经展开了广泛研究.按照查询类别的不同,图可达性查询分为基本可达查询[17-23]、d-可达查询[24-28]等.其中:基本可达查询用于查询两结点间是否存在一条可达路径;所谓d -可达查询,是指给定阈值d,查看两结点是否在d距离内可达;距离查询在返回两结点间是否可达的同时,给出了可达结点间的最短距离.针对可达性查询,提出了一系列图可达性查询技术.处理可达性查询的两种直接方法分别是对图进行深度或宽度优先遍历来查看结点间是否存在可达路径和提前计算图G的传递闭包,并基于传递闭包返回查询结果.然而,这两种方法存在执行效率低、传递闭包的空间代价大等问题.为了解决上述问题,相关工作[17-28]通过构建可达性索引并基于索引来实现高效的可达性查询处理.可达性索引的本质是:采用不同方法来压缩图的传递闭包,并在索引创建时间、索引空间代价和查询性能之间进行权衡.可达性索引方法主要分为集合覆盖法[21, 26-27]和区间标记法[17, 19-20, 22-23].
可以看出,当前研究工作忽视了在图匿名化过程中保持结点可达性,导致生成的匿名图在可达性查询方面的低数据可用性.本文针对此问题展开研究,提出一种保持结点可达性的高效社会网络图匿名算法,在匿名化社会网络图的同时保证匿名图在可达性查询方面的高数据可用性.
2 预备知识和问题定义在本文中,社会网络表示为有向图G=(V,E)且|V|=n和|E|=m,其中,V表示结点集合,E表示边集合;同时,V(G)和E(G)同样分别表示图G的结点集和边集.结点对(u,v)表示从结点u指向v的边;边(u,v)称为u的出边、v的入边;v是u的出边邻居,u是v的入边邻居.结点u的入边数目是u的入度,记作din(u);u的出边数目是u的出度,记作dout(u);结点u的度以(din(u),dout(u))的形式来表示.当向E中添加边(u,v)时,也称连接结点u和v.
2.1 社会网络隐私保护模型在本文中,假设攻击者将攻击目标的出度和入度作为背景知识进行结点身份识别攻击.基于文献[1]中的度匿名隐私保护模型,给出本文中的社会网络隐私保护模型.
定义 1(k-度匿名). 已知图G(V,E)和正整数k,对于∀v∈V,如果G中存在m(m≥k-1)个其他结点v1,v2,…,vm符合din(v)=din(vi)和dout(v)=dout(vi)(1≤i≤m),则称G为k-度匿名图.
例如,图 2中的G1和G2均为2-度匿名图.本文主要研究了对有向图匿名时,如何保持结点间可达性.本文的研究方法同样适用于无向图,因为无向图是有向图的特殊形式.此外,本文所提出的算法除了可以在k-度匿名隐私保护模型中保持结点间的可达性以外,还可以扩展至其他图匿名模型,包括邻接图匿名[2]、自同构图匿名[4]等.
2.2 问题定义首先给出可达性的定义,本文期望在匿名图中尽量保持结点间的可达性不变.
定义 2(可达性). 已知图G(V,E),如果结点u到v之间存在一条路径,则称结点u到v可达,记作u→v,结点对〈u,v〉称为可达对;将G的可达对集合记作R(G).
可达性查询是图研究领域的热点问题[17, 18].在社会网络中,查询两个结点之间是否存在路径可达是一项基本操作,如果两点可达,则意味着两个用户之间具有某种关系.
已知图G(V,E)和正整数k,期望通过对G进行一系列的图修改操作生成一个k-度匿名图Gk(Vk,Ek),并且Gk能够尽量保持G中结点间的可达性.在文献[4, 11]中,为了实现k-匿名,匿名图与原图的结点集和边集不完全相同,即Vk≈V和Ek≈E.本文进行图匿名化时仅考虑结点和边添加操作,即V⊆Vk和即E⊆Ek.问题1给出了可达性保持图匿名化问题.
问题 1(可达性保持图匿名化). 已知图G(V,E)和正整数k,构建一个k-度匿名图Gk(Vk,Ek),使得Cost(G,Gk)最小化.
由于在图匿名化过程中只考虑结点和边添加操作,因此R(G)⊆R(Gk).此时,公式(1)等于Cost(G,Gk)= |R(Gk)-R(G)|,即Gk中增加的可达对数目.
3 可达性保持图匿名算法本节介绍本文提出的可达性保持图匿名算法RPA,算法1给出了具体过程.RPA算法在对社会网络进行k-度匿名的同时保持结点间的可达性.
算法1的基本思想是:将具有相近度的结点分配到一个分组中,并通过图修改操作使得同一分组中的结点具有相同的度.给定入度和出度,RPA算法采用贪心策略匿名化每个结点,并最小化由于匿名操作而导致的可达性信息损失.由于社会网络中结点度符合幂律分布,因此,RPA算法首先从具有高入度和出度的结点开始匿名,剩余的具有较小入度和出度的结点比较容易匿名.
算法1首先将所有结点标记为“unanonymized”,并将这些结点存储于Setua中(第2行、第3行).在每次迭代过程中,算法均选择Setua中具有din+dout最大值的结点作为种子结点Seed(第5行).如果Setua中的结点数目大等于2k,算法在Setua中选择k个距离Seed最近的结点来生成集合vSet(第6行、第7行).如果Setua中的结点数目小于2k,则将Setua中的剩余结点来生成集合vSet(第9行).其中,对于任意结点u,基于u的度(din(u),dout(u))将其映射到二维空间中,采用曼哈顿距离来衡量两个结点之间的距离.
算法 1.可达性保持图匿名算法(RPA).
输入:社会网络图G=(V,E);匿名参数k.
输出:匿名图Gk.
1. Gk←G;
2. 将Gk中结点标记为“unanonymized”;
3. Setua={Gk中标记“unanonymized”的结点};
4. Repeat
5. Seed←Setua中具有最大din(s)+dout(s)的结点s;
6. If |Setua|≥2k Then
7. vSet←Setua中距离Seed最近的k个结点;
8. Else
9. vSet←Setua中剩余结点;
10. din←vSet中结点的最大入度;
11. dout←vSet中结点的最大出度;
12. For ∀u∈vSet Do
13. anonymizeOutDegree(Gk,u,dout,vSet);
14. anonymizeInDegree(Gk,u,din,vSet);
15. 将结点u标记为“anonymized”,并从Setua中删除;
16. Until Setua==∅;
17. Return Gk;
在图匿名过程中,如果只允许结点和边添加操作,则图中结点的入度和出度只会增加,不会减小.因此,算法1在匿名化vSet中的结点时,采用vSet中结点的最大入度和出度进行匿名(第10行~第15行).给定正整数dout和结点u,算法2采用贪心策略选择dout-dout(u)个结点并连接u和这些结点,使得u的出度为dout.其中,每个被选结点v应该符合如下条件:
(1) (u,v)∉E(Gk);
(2) 结点v是未匿名结点.
在这两个条件中,条件(1)是结点v成为u的新邻居的必要条件,条件(2)保证了匿名化结点u不会影响其他结点的匿名状态.将此两条件称为候选邻居条件(记作CNC),符合CNC的结点称为u的候选出边邻居.对于u的候选入边邻居v,条件(1)则更改为(v,u)∉E(Gk).为了保持入度小于等于din,算法不会选择vSet中结点作为u的候选出边邻居.在算法2的第2行~第5行循环中,算法采用贪心策略将导致最小Cost(u,v)的结点v作为u的新出边邻居,其中,Cost(u,v)是指在Gk中添加边(u,v)所导致的可达性信息损失,计算如公式(2):
| $Cost\left( u,v \right)=|R({{G}_{k}}\grave{E}\left\{ \left( u,v \right) \right\})|-\left| R\left( {{G}_{k}} \right) \right|$ | (2) |
在本文中,将此贪心策略称为单邻居添加策略,并在第5节中详细讨论.算法会将u的新出边邻居从candNeighbors中删除(第5行).当candNeighbors为空并且dout仍然大于dout(u)时,算法2添加dout-dout(u)个结点到Gk中,并连接u至这些新添加结点(第6行~第8行).显然,新添加结点的度为(1,0).根据度幂律分布可知,Gk中具有度(1,0)的结点数目远大于匿名参数k,因此可以安全地将这些结点标记为“anonymized”(第7行).对于结点的入度匿名过程与算法2相似,本文不再赘述.RPA算法在图匿名过程中虽然考虑了特定优化指标,即,保持结点间的可达性,但是由于生成的匿名图符合k-度匿名模型,基于结点度的隐私泄露概率小于等于1/k,此种优化指标不会为攻击者提供背景知识从而导致额外的隐私泄露.
算法 2. anonymizeOutDegree.
输入:图Gk;结点u∈V(Gk);整数dout;结点集vSet.
输出:匿名图Gk.
1. candNeighbors←{Gk中的候选出边邻居}-vSet;
2. While dout(u)<dout && candNeighbors≠∅ Do
3. u´←candNeighbors中具有最小Cost(u,v)的结点v;
4. 在E(Gk)中添加边(u,u´);
5. 将u´从candNeighbors中删除;
6. If t=dout-dout(u)>0 Then
7. 在V(Gk)中添加t个结点并标记为“anonymized”;
8. 连接u和新添加结点;
RPA算法在图匿名的同时保持了结点间的可达性,但是社会网络通常具有数以千万的结点和边,导致RPA算法的执行效率面临以下两个挑战:
(1) 已知图G具有n个结点和m条边,如何高效地评估任意图操作所导致的可达性信息损失?
在RPA算法中,评估添加边所导致的可达性信息损失是一项频繁操作,与RPA算法的执行效率密切相关.然而,此项操作非常耗时.例如,当评估在G中添加边(u,v)时的可达性信息损失时,一种简单方法就是计算图中每个结点的可达结点集合并比较其在边添加操作前后的变化.生成任意结点的可达结点集合需要一次宽度优先遍历,需要O(n+m)时间.因此,评估一个边添加操作的可达性信息损失需要O(2n(n+m))时间.对于结点u来说,由于在candNeighbors中至多包含(n-1)个结点,因此算法2需要O(2n2(n+m))时间来寻找使得Cost(u,v)最小的结点v(第3行).对于大型社会网络数据,如此高的时间复杂度使得此项操作不具有可行性.作为RPA算法的一项基本操作,对如何高效地评估边添加操作导致的可达性信息损失提出了一项挑战.
(2) 当需要将结点u的出度增加3时,RPA算法如何在图中高效地搜索u的3个新出边邻居,使得可达性信息损失最小?
显然,候选出边邻居的组合数目为
为了降低RPA算法的时间复杂度,使其具有可行性,本文第4节、第5节主要研究两个问题:
(1) 如何高效评估Cost(u,v)?
(2) 对于结点u,如何高效地寻找结点v,使得Cost(u,v)最小?
4 高效评估图匿名损失本节研究如何高效地评估Cost(u,v).首先提出可达区间的定义,然后给出基于可达区间的匿名损失高效评估方法.
4.1 采用可达区间评估匿名损失给定图G(V,E)和结点p∈V,R(p)表示p在图G中可达的结点集合,R-1(p)表示G中可达p的结点集合.为了方便讨论,假设每个结点到其自身可达,即p∈R(p)和p∈R-1(p).由于在图匿名过程中只采用结点和边添加操作,采用ΔR(p)来表示由于添加边(u,v)而导致R(p)所增加的结点集合.显然,当添加边(u,v)时,并不是所有结点的可达结点集都会受到影响.
定理 1. 在图G中添加边(u,v),可达结点集受影响的结点属于R-1(u).
证明:反证法.当在图G中添加边(u,v)时,假设结点p的可达结点集受影响并且p∉R-1(u).令结点p的可达结点集R(p)中增加可达结点的集合为ΔR(p).对于∀q∈ΔR(p),则存在一条从p至q的路径,并且该路径经过边(u,v).显然,结点p至u是可达的,则p∈R-1(u),与假设p∉R-1(u)矛盾.
根据定理 1,可以通过检验每个结点p∈R-1(u)的ΔR(p)来计算匿名代价Cost(u,v).此时,公式(2)等价于采用公式(3)来计算:
| $Cost(u,v)=\sum\limits_{p\in {{R}^{-1}}(u)}{|\text{ }\!\!\Delta\!\!\text{ }R(p)|}$ | (3) |
为了高效地计算ΔR(p),提出可达区间数据结构.首先为图中的每个结点分配一个id,然后,基于结点的id来生成每个结点的可达区间.
定义3(可达区间). 对于任意结点u,u的可达区间由若干整数区间组成,记录了u在图中可达结点的id范围,记作Rl(u).
存在多种结点id分配方式,其中一种简单方法是随机分配方法,如图 3所示,图中结点被随机分配id,位于区间[0,n)内.此时,结点f和g的可达区间为
| $\begin{matrix} {{R}_{l}}\left( f \right)\to \left[ 4,6 \right)\grave{E}\left[ 8,10 \right)\grave{E}\left[ 13,14 \right)\grave{E}\left[ 15,16 \right); \\ {{R}_{l}}\left( g \right)\to \left[ 1,2 \right)\grave{E}\left[ 4,10 \right)\grave{E}\left[ 11,12 \right)\grave{E}\left[ 13,14 \right)\grave{E}\left[ 15,16 \right). \\ \end{matrix}$ |
令pid表示结点p的id,对于结点u和p,显然,pid∈Rl(u)当且仅当u→p.因此对于结点p,|ΔR(p)|=|ΔRl(p)|成立.此时,可以通过计算ΔRl(p)来代替公式(3)中的ΔR(p).

|
Fig. 3 Random id assignment 图 3 随机结点id分配 |
定理 2. 在图G中添加边(u,v),对于结点p∈R-1(u),可得ΔRl(p)=Rl(v)-Rl(p).
证明:反证法.在添加边(u,v)后,假设p的可达区间由Rl(p)变为
| $\text{ }\!\!\Delta\!\!\text{ }{{R}_{l}}(p)={{{R}'}_{l}}(p)-{{R}_{l}}(p)\supseteq {{R}_{l}}(v)-{{R}_{l}}(p).$ |
假设存在结点q满足qid∉Rl(v)-Rl(p)和qid∈ΔRl(p),可知添加边(u,v)使得p→q,因此,边(u,v)位于从p到q的路径上,从而可以推断v→q.由qid∈Rl(v)和qid∉Rl(v)-Rl(p)可知qid∈Rl(p),与假设qid∈ΔRl(p)矛盾,因此,结点q不存在并且ΔRl(p)=Rl(v)-Rl(p).
采用结点id随机分配方式时,对于任意结点p,Rl(p)存在至多
结点id的分配方式决定了可达区间的大小,而可达区间的大小决定了计算ΔRl(p)的时间复杂度.
4.2 生成结点的可达区间为了高效地计算ΔRl(p),本文扩展了文献[19]中的Dual Labeling方法来生成结点的可达区间,从而在O(t) (t<<n)时间内完成ΔRl(p)的计算.
Dual Labeling方法主要包含两步:(1) 基于输入图构建一个生成树;(2) 为每个结点分配一个区间标签,并记录非树边的连接情况,从而保证图可达性信息的完整性.
真实社会网络通常包含环,已知图G(V,E)且|V|=n和|E|=m,找出G的强连通分量,并将每个分量以一个超点来表示.采用文献[29]中的Tarjan算法,可以在O(n+m)时间内完成此超点生成过程.对于图 1(a)中的G,图 4(a)显示了对应的生成树T和所包含的超点.在图 4(a)中,生成树由实线箭头所组成,虚线箭头表示非树边.显然,位于同一超点内的结点具有相同的可达结点集.本文假设社会网络图是强连通图,如果不是,则通过设定一个虚拟根结点并将各连通分量连接起来即可.

|
Fig. 4 Extended Dual Labeling coding scheme 图 4 扩展Dual Labeling方法 |
由于生成树T上的某些结点为超点并包含多个图结点,为了准确计算匿名损失,本文对文献[19]中的Dual Labeling技术进行扩展来分配结点id.对生成树T进行一次遍历,每个结点u被赋值区间标签[ustart,uend).结点区间标签的具体赋值方法为:(1) ustart被赋值为
| $\begin{matrix} 8\to \left[ 1,7 \right), \\ 12\to \left[ 8,12 \right), \\ 13\to \left[ 15,17 \right), \\ 12\to \left[ 1,7 \right). \\ \end{matrix}$ |
基于结点u,v的区间标签和传递链接表L,可达性查询u→v可以在O(1)时间内完成,具体细节参见文献[19],本文不再赘述.
对于生成树T上的结点u,算法3为其生成一个可达区间Rl(u),包含了u通过树边和非树边可达的结点id区间.显然,在树结点u中,每个图结点的可达区间是Rl(u).假设T中包含t个非树边,则L至多包含
| $\begin{matrix} {{R}_{l}}\left( f \right)\to \left[ 1,7 \right), \\ {{R}_{l}}\left( g \right)\to \left[ 1,7 \right)\grave{E}\left[ 8,12 \right). \\ \end{matrix}$ |
算法 3.可达区间生成算法.
输入:生成树结点u;传递链接表L.
输出:可达区间Rl(u).
1. Rl(u)←[ustart,uend);
2. For each
3. If vstart∈[ustart,uend) Then
4. Rl(u)←Rl(u)∪
5. Return Rl(u);
文献[19]中提出,通过寻找最小等价图可以使得非树边的数目最小.当向图中添加边(u,v)时,对于结点p∈R-1(u),由于Rl(v)和Rl(p)至多包含t+1个区间,因此需要O(t)时间来计算ΔRl(p)=Rl(v)-Rl(p).令r=|R-1(u)|,则计算公式(3)需要O(rt)时间,r和t在真实社会网络中满足r<<n和t<<n.
5 优化结点匿名效率在匿名化结点u时,算法2(第3行)需要O(nrt)时间来寻找具有最小Cost(u,v)数值的结点v.为了加速此过程,本文采用文献[20]中的Chain Cover算法生成的索引结构,并基于此索引为结点匿名提出两种结点添加策略:单邻居添加策略和多邻居添加策略.
如文献[20]中所描述,拟采用的索引结构是一个链表集合,包含了链表L1,L2,…,Ls,链表Li=si1→si2→…→
· 所有链表结点的并集等于G的结点集合,并且任意两个链表结点的交集为空;
· 任意链表Li符合:
(1) 对于结点∀u∈sij和∀v∈si(j+1),满足u→v并且v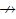
(2) 对于结点∀u,v∈sij,满足u→v并且v→u.
为描述方便,本文将该索引称为候选邻居索引(记作CN-index).文献[20]给出了CN-index的构建方法以及当发生图操作时如何动态维护CN-index,本文不再赘述.例如,对于图 1(a)中的G,图 5(a)显示了与其对应的一个CN-index.

|
Fig. 5 Selecting the out-OCN using the CN-index 图 5 基于CN-index选择out-OCN |
给定图结点u和CN-index中的索引结点ns,假设结点v属于ns,则将添加边(u,v)/(v,u)称作连接u至ns(或ns至u).下面介绍如何基于CN-index来加速结点匿名.
5.1 单邻居添加策略为了给结点u添加k个出边邻居,本节提出了单邻居添加策略.算法2进行结点匿名时采用了单邻居添加策略.单邻居添加策略的基本思想是:为结点u不断地选择和添加导致最小匿名损失的候选出边邻居,直至新添加的邻居数目为k.
定义 5(最优候选出边/入边邻居(out/in-OCN)). 已知图G和结点u∈V,如果结点v是u的候选出边/入边邻居并且具有最小Cost(u,v)/Cost(v,u),则称v是u的最优候选出边/入边邻居,记作out/in-OCN.
单邻居添加策略的关键是查找结点u的out/in-OCN.根据定理3,可以基于CN-index来加速out/in-OCN查找过程.
定理 3. 如果u→v并且v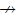
证明:由于u→v并且v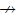
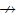
| $\sum\nolimits_{q\in {{R}^{-1}}(p)}{|{{R}_{l}}(v)-{{R}_{l}}(q)}|<\sum\nolimits_{q\in {{R}^{-1}}(p)}{|{{R}_{l}}(u)-{{R}_{l}}(q)}|=Cost(p,u)$ |
算法 4显示了基于CN-index来查找结点u的out-OCN.算法首先在R(u)中查找out-OCN(第2行),这是因为R(u)中的结点不会导致匿名损失.如果R(u)中没有候选出边邻居,则从CN-index中每个链表的尾部开始查找out-OCN(第3行~第14行).对链表Li进行查找时,如果遇到候选出边邻居结点,则在该链表的查找过程停止.算法将具有最小匿名代价的候选出边邻居存储于ocnset.当在ocnset中选择out-OCN时,选择具有最小入度的结点作为out-OCN(第15行),从而保持度幂律分布.
算法4.选择out-OCN.
输入:结点u.
输出:结点u的out-OCN.
1. ocn←null;
2. ocnset←R(u)中的候选出边邻居;
3. If ocnset==∅ Then
4. cost←+∞;
5. For CN-index中每个链表Li Do
6. For j=ni to 1 Do
7. candset←sij中的候选出边邻居;
8. If candset≠∅ Then
9. If cost>Cost(u,candset) Then
10. cost←Cost(u,candset);
11. ocnset←candset;
12. If cost==Cost(u,candset) Then
13. ocnset←ocnset∪candset;
14. Break;
15. ocn←ocnset中具有最小入度的结点v;
16. Return ocn;
令r=|R-1(u)|,由于CN-index中包含s个链表,则算法4的时间复杂度为O(srt),其中,t表示生成树中非树边的数目.
例如在图 1(a)中,当为结点b选择out-OCN时,图 5(b)显示了对应的CN-index.当G中的结点未匿名时,将在R(b)中选择候选出边邻居,如虚线框中所示的d,e,f和w.如果这4个结点已经匿名,则在CN-index的每个链表结尾开始查找out-OCN.如图 5(b)所示,经过检验的索引结点被标记上了连接b和该索引结点的匿名代价.在此示例中,结点q和v具有最小的匿名代价,可以随机选择任意结点作为out-OCN.
为结点u选择in-OCN的过程与算法4相似,本文进行简单介绍.
定理 4. 如果u→v并且v
根据定理 4,应该优先选择R-1(u)中的候选入边邻居作为u的in-OCN.如果不存在此种候选入边邻居,则从CN-index中每个链表的头结点开始查找in-OCN.当从具有最小匿名代价的候选入边邻居中选择in-OCN时,选择具有最小出度的结点作为in-OCN.
5.2 多邻居添加策略为结点u添加k(k>1)个出边邻居时,单邻居添加策略具有很高的执行效率,但是导致较大的匿名损失.为了解决此问题,本文提出了多邻居添加策略.
例如,当为结点u添加3个出边邻居时,图 6(a)显示了对应的CN-index.在CN-index中,每个链表结点s标记上了(no,nc),其中,no和nc分别表示s中候选出边邻居数目和连接u至s的匿名损失.为了方便讨论,假设不同链表上结点的匿名损失数值相互独立,即,连接u至Li上的结点不影响Lj(i≠j)上结点的匿名损失数值.当采用单邻居添加策略时,首先连接u至s13中的一个候选出边邻居,导致的匿名损失为3;然后,连接u至s32中的两个候选出边邻居,导致的匿名损失为4.因此,采用单邻居添加策略导致的匿名损失为3+4=7.与单邻居添加策略不同,另外一种邻居添加方法是连接u至s32中的3个候选出边邻居,导致的匿名损失为4.可见,此方法的匿名损失小于单邻居添加策略.

|
Fig. 6 An example of adding multiple out-neighbors 图 6 添加多个出边邻居示例 |
定义 6(最优候选出边/入边邻居集(out/in-OCNS)). 已知图G(V,E)和结点u∈V,假设在图匿名过程中需要为u添加k个出/入边邻居,令Vc⊆V是u的候选出/入边邻居集,如果Vo⊆Vc满足|Vo|=k并且对于∀V´⊆Vc(|V´|=k)都有Cost(u,Vo)<Cost(u,V´)/Cost(Vo,u)<Cost(V´,u),则Vo是u的最优候选出边/入边邻居集,记作out/in-OCNS.
在定义 6中,Cost(u,Vc)表示连接u至Vc中每个结点所导致的匿名损失.多邻居添加策略的主要思想是,枚举所有可能候选出边/入边邻居集并选择导致最小匿名损失的集合作为out/in-OCNS.本文设计一种剪枝-枚举算法来生成out/in-OCNS.
5.2.1 评估多边添加匿名损失首先介绍如何评估添加多边所导致的匿名损失.对于结点u和v,显然,边(u,v)的添加不会影响R-1(u).当连接u至多个候选出边邻居时,对于结点p∈R-1(u),根据定理5来计算ΔRl(p).
定理 5. 当连接u至CN-index的链表结点s1,…,sm时,对于结点p∈R-1(u),
定理 6中指出,计算ΔRl(p)时没有必要考虑u连接的所有链表结点.
定理 6. 当连接u至CN-index的链表结点sij和sil(j<l)时,对于结点p∈R-1(u),ΔRl(p)=Rl(sij)-Rl(p).
证明:给定结点p∈R-1(u),首先连接u至链表结点sij,此时ΔRl(p)为Rl(sij)-Rl(p),并且可知p→sil,因此,连接u至sil不会影响Rl(p).
根据定理 6,在计算ΔRl(p)时,只需考虑每个链表Li中被连接且具有最小j值的链表结点sij.例如在图 6(a)中,假设连接结点u至链表结点s12,s13,s21,s22,s32时,对于结点p∈R-1(u),则p的可达区间变化为
| $\Delta {{R}_{l}}\left( p \right)={{R}_{l}}\left( {{s}_{12}} \right)\grave{E}\cup {{R}_{l}}\left( {{s}_{21}} \right)\grave{E}\cup {{R}_{l}}\left( {{s}_{32}} \right)-{{R}_{l}}\left( p \right).$ |
对于链表Li,层次li表示链表结点
本文设计一种剪枝枚举方法来生成out-OCNS,剪枝枚举具体包括3个步骤:
(1) 给定结点u,枚举所有包含至少k个候选出边邻居的层次序列S并计算Cost(u,S),选择最小匿名损失的层次序列作为最优层次序列;
(2) 给定最优层次序列So,通过不断提高So中的链表层次来获得
(3) 在
剪枝枚举需要枚举出所有包含至少k个候选出边邻居的层次序列.在枚举过程中,可以采用如下性质来对层次序列进行剪枝:对于任意两个层次序列S和S´,如果S≺S´,根据定理6可知Cost(u,S)<Cost(u,S´),因此,当S包含至少k个候选出边邻居时,可以安全地将S´剪枝.在图 6(b)中,枚举树Te显示了剪枝枚举方法所检验的层次序列.在Te中,每个树结点表示一个层次序列,在树结点上标记了其所包含的候选邻居数目,剪枝枚举方法在Te的叶子结点中选择最优层次序列.例如在图 6的示例中,由于层次序列S=〈1,1,0〉已经包含了3个候选出边邻居,因此剪枝掉了层次序列S1=〈1,1,1〉和S2=〈1,2,0〉.如图 6(b)所示,如果枚举所有的层次序列,则需要评估3x2x2=12个层次序列,而剪枝枚举方法检验和评估了4个层次序列.
选择最优层次序列问题等价于“小盒放球”问题:将k个相同的球放入s个不同盒子中,有多少种方法?该问题的答案是
| $k!=\sqrt{2\pi k}{{\left( \frac{k}{e} \right)}^{k}}{{e}^{{{\lambda }_{k}}}}\left( \frac{1}{12k+1}<{{\lambda }_{k}}<\frac{1}{12k} \right)$ |
因此,对于∀k均有
给定最优层次序列So,剪枝枚举方法查找满足如下条件的层次序列
(1)
(2) 对于
为了寻找
定理 7. 当为结点u添加k个出边邻居时,
证明:令C为包含
基于So生成u的out-OCNS时,为了保持度幂律分布,将
在介绍如何生成in-OCNS之前,首先讨论为结点u添加多个入边邻居所导致的匿名损失.
对于结点u和v,添加边(u,v)不会影响R(u).假设S是候选入边邻居集合,当连接S中每个结点至u时,导致的匿名损失可计算为
| $Cost(S,u)=\sum\limits_{p\in {{R}^{-1}}(S)}{|{{R}_{l}}(u)-{{R}_{l}}(p)|}$ | (4) |
其中,
定理 8. 给定结点集合S并连接S中每个结点至u,对于CN-index的链表Li上包含S中结点的链表结点sij,令
在图 6中,当连接链表结点s12,s13,s21,s22,s31,s32至u时,可达性受影响的结点集合为
| ${{R}^{-}}^{1}\left( S \right)={{R}^{-}}^{1}\left( {{s}_{13}} \right)\grave{E}\cup {{R}^{-}}^{1}\left( {{s}_{22}} \right)\grave{E}\cup {{R}^{-}}^{1}\left( {{s}_{32}} \right).$ |
当为结点u生成in-OCNS时,层次li表示了链表Li上的结点si1至
为了方便讨论,之前在评估匿名损失时没有考虑新添加结点(即伪点)的影响.对于结点v和伪点v´,如果v→v´(或者v´→v),则ΔR (G)应该包含可达对〈v,v´〉(或者〈v´,v〉).
对于结点p,令fi(p)和fo(p)分别表示p的入边邻居伪点和出边邻居伪点.通过扩展公式(3),公式(5)给出了当考虑伪点时如何计算匿名代价Cost(u,v):
| $Cost(u,v)=\sum\limits_{p\in {{R}^{-1}}(u)}{({{f}_{i}}(p)+1)\left( |\text{ }\!\!\Delta\!\!\text{ }{{R}_{l}}(p)|+\sum\limits_{{{q}_{id}}\in \text{ }\!\!\Delta\!\!\text{ }{{R}_{l}}(p)}{{{f}_{o}}(q)} \right)}$ | (5) |
其中,ΔRl(p)=Rl(v)-Rl(p).如表 1中的“分类”列所示,将匿名图中增加的可达对分为4类.例如,如果可达对〈v,v´〉是〈fake,true〉种类,则表明v是一个伪点,v´是一个真结点.通过扩展公式(5),可以得到4个因式,表 1列出了每个因式所代表的可达对种类.
| Table 1 Incremental reachable pair categories represented by terms in Eq.(5) 表 1 公式(5)中因式所代表的新增可达对种类 |
6 实验分析
本文对提出的RPA算法进行性能分析和评价.在测试过程中,采用了两个真实社会网络图数据集Eu-Email,Epinions进行实验分析和测试.
6.1 实验设置Eu-Email网络是基于欧洲一个研究中心的电子邮件数据所生成,时间范围是2003年10月~2005年5月.每个结点对应一个电子邮件地址,一条有向边(i,j)表示至少有一封邮件由i发给j.Eu-Email图数据集包含 265 214个结点和420 045条边.Epinions网络是一个用户在线评论网络,有向边(u,v)表示了u信任v,该数据集包含了75 879个结点和508 837条边.表 2显示了图数据集相关统计数据.
| Table 2 Statistics of datasets 表 2 数据集相关统计数据 |
本文实现了两个版本的RPA算法:Single-RPA和Multi-RPA,分别在图匿名过程中采用了单邻居添加策略和多邻居添加策略.除了实现RPA算法以外,为了进行对比,本文对文献[2]中的图匿名算法进行了修改并实现,记作Neighbor-Greedy.实现Neighbor-Greedy时,主要修改了文献[2]中的匿名损失函数,将其中评价两个结点的邻居图相似度部分替换为评价两个结点的度相似度.
本文测试了算法的执行时间、匿名损失、添加的边和结点数目、图结构信息损失.在测试中,匿名参数k的取值为10,20,30,40,50.实验测试的软硬件环境如下:
(1) 硬件环境:Intel Core 2 Duo 2.33GHz CPU,4GB DRAM内存.
(2) 操作系统平台:Microsoft Windows XP.
(3) 编程环境:Java,Eclipse.
6.2 执行时间本文测试了算法的执行时间随着k值的变化情况,实验结果如图 7所示.从实验结果中可以看出,执行时间随着k值的增大而增加.由于需要生成out/in-OCNS,Multi-RPA算法的执行时间最高.从理论上来说,Single-RPA算法中耗时的out/in-OCN查找操作会使得Single-RPA的执行效率低于Neighbor-Greedy,然而图 7中显示,这两个算法的执行时间基本相同,这是因为CN-index提高了out/in-OCN查找操作的效率.

|
Fig. 7 Runtime of graph anonymization 图 7 图匿名执行时间 |
6.3 匿名损失
给定图G和其k-度匿名图Gk,本文定义增量率incremental ratio=

|
Fig. 8 Incremental ratios 图 8 增量率 |
从实验结果中可以看出,Neighbor-Greedy的增量率最大,比Single-RPA和Multi-RPA平均高出0.25.这是因为在Neighbor-Greedy算法中,忽视了边修改操作对于结点可达性的影响.与Single-RPA算法相比,Multi-RPA算法具有更低的增量率,表明多邻居添加策略比单邻居添加策略导致更小的匿名损失.图 8显示了RPA算法的增量率平均低于0.02,证明了RPA算法可以很好地保持匿名图在可达性方面的数据可用性.
6.4 添加边和结点数目为了评估Gk中新添加边所占比例,定义了边添加率adding edge ratio=

|
Fig. 9 Adding edge ratios 图 9 边添加率 |
表 3中显示了匿名图中伪点的添加数目.在任意测试数据集中,每种算法的伪点添加数目均不超过70个,而匿名图中度为(0,1)或(1,0)的结点数目均大于10 000,因此,攻击者不会通过推断哪些结点是伪点并通过删除伪点及其连接边来进一步获得隐私信息.
| Table 3 Number of added fake vertices 表 3 添加伪点数目 |
6.5 图结构信息损失
为了测试生成匿名图Gk在图结构方面的信息损失,本文测试了匿名图的结构变化率,包括聚集系数(clustering coefficient)和平均路径长度(average path length),来评估图结构数据可用性.
对于一个结点v,v的聚集系数是指其所有邻居结点对中具有边连接的比率;两个结点的路径长度是指该两点间的最短路径长度.定义图结构变化率Change ratio=|Po˜Pa|/|Po|来衡量匿名图结构的变化,其中,Po和Pa分别表示原图和匿名图中的图结构数值.在测试平均路径长度时,随机选择了10 000个结点对作为测试对象.图 10和图 11分别显示了聚集系数和平均路径长度的变化率.可以看出,RPA算法生成匿名图的图结构变化率均小于Neighbor-Greedy算法.因为图结构与可达性相关,RPA可以保持匿名图的可达性,因此也实现了图结构的保持.随着k值的增大,RPA算法的图结构变化率基本不变,可见,保持结点间的可达性是保持图结构的基础.

|
Fig. 10 Change ratio of clustering coefficient 图 10 聚集系数变化率 |

|
Fig. 11 Change ratio of average path length 图 11 平均路径长度变化率 |
7 总结以及未来的工作
本文提出了在社会网络图匿名过程中保持结点间可达性问题.针对此问题,本文提出了可达性保持图匿名化算法(简称RPA算法).RPA算法通过将结点进行分组并采取贪心策略进行匿名,从而减少匿名过程中的可达性信息损失.同时,本文设计了一系列优化技术来保证RPA算法的执行效率,使其面对大规模社会网络图数据时具有可行性.本文首先提出采用可达区间来高效地评估边添加操作所导致的匿名损失;其次,通过采用候选邻居索引,进一步加速RPA算法对每个结点的匿名过程,保证了RPA算法的实用性.基于真实社会网络数据的实验结果表明了RPA算法的高执行效率,同时验证了生成匿名图在可达性查询方面的高精度.
距离查询是一种特殊的可达查询,其返回两个查询结点间的最短距离.距离查询是很多图应用的基础,保持匿名图在距离查询方面的可用性具有实际意义和应用价值.因此,如何在图匿名过程中保证距离查询的精度,成为我们下一阶段的研究方向.当前,我们正在研究图匿名操作对结点间最短距离的影响以及如何在图匿名过程中保持指定结点对间的最短距离.
| [1] | Liu K, Terzi E. Towards identity anonymization on graphs. In: Proc. of the 2008 ACM SIGMOD Int’l Conf. on Management of Data. 2008. 93-106. [doi:10.1145/1376616.1376629] |
| [2] | Zhou B, Pei J. Preserving privacy in social networks against neighborhood attacks. In: Proc. of the 24th IEEE Int’l Conf. on Data Engineering. 2008. 506-515. [doi:10.1109/ICDE.2008.4497459] |
| [3] | Hay M, Miklau G, Jensen D, Towsley D. Resisting structural identification in anonymized social networks. In: Proc. of the 34th Int’l Conf. on Very Large Databases. 2008. 102-114. [doi:10.14778/1453856.1453873] |
| [4] | Zou L, Chen L, Ozsu MT. K-Automorphism: A general framework for privacy preserving network publication. In: Proc. of the 35th Int’l Conf. on Very Large Databases. 2009. 946-957. [doi:10.14778/1687627.1687734] |
| [5] | Cormode G, Srivastava D, Yu T, Zhang Q. Anonymizing bipartite graph data using safe groupings. In: Proc. of the 34th Int’l Conf. on Very Large Databases. 2008. 833-844. [doi:10.14778/1453856.1453947] |
| [6] | Bhagat S, Cormode G, Krishnamurthy B, Srivastava D. Class-Based graph anonymization for social network data. In: Proc. of the 35th Int’l Conf. on Very Large Databases. 2009. 766-777. [doi:10.14778/1687627.1687714] |
| [7] | Fard AM, Wang K, Yu PS. Limiting link disclosure in social network analysis through subgraph-wise perturbation. In: Proc. of the 15th Int’l Conf. on Extending Database Technology. 2012. 109-119. [doi:10.1145/2247596.2247610] |
| [8] | Gao J, Xu JY, Jin R, Zhou J, Wang T, Yang D. Neighborhood-Privacy protected shortest distance computing in cloud. In: Proc. of the 2011 ACM SIGMOD Int’l Conf. on Management of Data. 2011. 409-420. [doi:10.1145/1989323.1989367] |
| [9] | Wang Y, Zheng B. Preserving privacy in social networks against connection fingerprint attacks. In: Proc. of the 2015 IEEE Int’l Conf. on Data Engineering. 2015. 54-65. [doi:10.1109/ICDE.2015.7113272] |
| [10] | Cheng J, Fu AWC, Liu J. K-Isomorphism: Privacy preserving network publication against structural attacks. In: Proc. of the 2010 ACM SIGMOD Int’l Conf. on Management of Data. 2010. 459-470. [doi:10.1145/1807167.1807218] |
| [11] | Yuan M, Chen L, Yu PS. Personalized privacy protection in social networks. In: Proc. of the 36th Int’l Conf. on Very Large Databases. 2010. 141-150. [doi:10.14778/1921071.1921080] |
| [12] | Wang L, Meng XF. Location privacy preservation in big data era: A survey. Ruan Jian Xue Bao/Journal of Software, 2014, 25 (4) :693–712(in Chinese with English abstract). [doi:10.13328/j.cnki.jos.004551] http://www.jos.org.cn/1000-9825/4551.htm |
| [13] | Huo Z, Meng X, Zhang R. Feel free to check-in: Privacy alert against hidden location inference attacks in GeoSNs. In: Proc. of the 18th Int’l Conf. on Database Systems for Advanced Applications. 2013. 377-391. [doi:10.1007/978-3-642-37487-6_29] |
| [14] | Liu X, Yang X. Protecting sensitive relationships against inference attacks in social networks. In: Proc. of the 17th Int’l Conf. on Database Systems for Advanced Applications. 2012. 335-350. [doi:10.1007/978-3-642-29038-1_25] |
| [15] | Yuan M, Chen L, Yu PS, Yu T. Protecting sensitive labels in social network data anonymization. IEEE Trans. on Knowledge and Data Engineering, 2013,25(3):633-647. [doi:10.1109/TKDE.2011.259] |
| [16] | Wang Y, Xie L, Zheng B, Lee KCK. High utility K-anonymization for social network publishing. Knowledge and Information Systems, 2014, 41 (3) :697–725. [doi:10.1007/s10115-013-0674-2] |
| [17] | Agrawal R, Borgida A, Jagadish HV. Efficient management of transitive relationships in large data and knowledge bases. In: Proc. of the 1989 ACM SIGMOD Int’l Conf. on Management of Data. 1989. 253-262. [doi:10.1145/67544.66950] |
| [18] | Anyanwu K, Sheth A. r-Queries: Enabling querying for semantic associations on the semantic Web. In: Proc. of the 12th Int’l Conf. on World Wide Web. 2003. 690-699. [doi:10.1145/775152.775249] |
| [19] | Wang H, He H, Yang J, Yu PS, Yu JX. Dual labeling: Answering graph reachability queries in constant time. In: Proc. of the 22nd Int’l Conf. on Data Engineering. 2006. 75-75. [doi:10.1109/ICDE.2006.53] |
| [20] | Chen Y, Chen Y. An efficient algorithm for answering graph reachability queries. In: Proc. of the 20th Int’l Conf. on Data Engineering. 2008. 893-902. [doi:10.1109/ICDE.2008.4497498] |
| [21] | Cheng J, Yu JX, Lin X, Wang H, Yu PS. Fast computing reachability labelings for large graphs with high compression rate. In: Proc. of the 11th Int’l Conf. on Extending Database Technology. 2008. 193-204. [doi:10.1145/1353343.1353370] |
| [22] | Seufert S, Anand A, Bedathur S, Weikum G. Ferrari: Flexible and efficient reachability range assignment for graph indexing. In: Proc. of the 2013 IEEE Int’l Conf. on Data Engineering. 2013. 1009-1020. [doi:10.1109/ICDE.2013.6544893] |
| [23] | Xie N, Shen D, Feng S, Kou Y, Nie T, Yu G. RIAIL: An index method for reachability query in large scale graphs. Ruan Jian Xue Bao/Journal of Software, 2014, 25 :213–224(in Chinese with English abstract). http://www.jos.org.cn/1000-9825/14039.htm |
| [24] | Cheng J, Shang Z, Cheng H, Wang H, Yu JX. K-Reach: Who is in your small world? In: Proc. of the 2012 VLDB Endowment. 2012. 1292-1303. [doi:10.14778/2350229.2350247] |
| [25] | Li M, Gao H, Zou Z. K-Reach query processing based on graph compression. Ruan Jian Xue Bao/Journal of Software, 2014, 25 (4) :797–812(in Chinese with English abstract). [doi:10.13328/j.cnki.jos.004567] http://www.jos.org.cn/1000-9825/4567.htm |
| [26] | Cohen E, Halperin E, Kaplan H, Zwick U. Reachability and distance queries via 2-hop labels. In: Proc. of the 13th Annual ACM-SIAM Symp. on Discrete Algorithms. 2002. 937-946. |
| [27] | Bramandia R, Choi B, Ng WK. On incremental maintenance of 2-hop labeling of graphs. In: Proc. of the 17th Int’l Conf. on World Wide Web. 2008. 845-854. [doi:10.1145/1367497.1367611] |
| [28] | Wei F. TEDI: Efficient shortest path query answering on graphs. In: Proc. of the 2010 Int’l Conf. on Management of Data. 2010. 99-110. [doi:10.1145/1807167.1807181] |
| [29] | Paige R, Tarjan RE. Three partition refinement algorithms. SIAM Journal on Computing, 1987, 16 (6) :973–989. [doi:10.1137/0216062] |
| [12] | 王璐, 孟小峰. 位置大数据隐私保护研究综述. 软件学报, 2014,25 (4) :693–712. [doi:10.13328/j.cnki.jos.004551] http://www.jos.org.cn/1000-9825/4551.htm |
| [23] | 解宁, 申德荣, 冯朔, 寇月, 聂铁铮, 于戈. RIAIL:大规模图上的可达性查询索引方法. 软件学报, 2014,25 :213–224. http://www.jos.org.cn/1000-9825/14039.htm |
| [25] | 李鸣鹏, 高宏, 邹兆年. 基于图压缩的k可达查询处理. 软件学报, 2014,25 (4) :797–812. [doi:10.13328/j.cnki.jos.004567] http://www.jos.org.cn/1000-9825/4567.htm |