 2015, Vol. 26
2015, Vol. 26



2. 符号计算与知识工程教育部重点实验室(吉林大学), 吉林 长春 130012;
3. 国家地球物理探测仪器工程技术研究中心(吉林大学), 吉林 长春 130026;
4. 大连民族大学 信息与通信工程学院, 辽宁 大连 116600
2. Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education (Jilin University), Changchun 130012, China;
3. National Engineering Research Center of Geophysics Exploration Instruments(Jilin University), Changchun 130026, China;
4. College of Information and Communication Engineering, Dalian Nationalities University, Dalian 116600, China
广义上,本体指各种形式化的表示,它包括分类、具有层次化结构的术语词汇以及基于某种逻辑理论的领域描述[1].人工智能学科下的本体特指对达成共识的领域概念的形式化描述[2].本体的构建一般由领域专家手工完成或计算机程序辅助半自动完成,建成的本体被广泛应用于计算机科学和工程的各个方面[3-5].在本体构建、使用、升级和维护的整个生命周期中,都离不开对其内涵知识不一致性的冲突消解,因此,本体调试(ontology debugging)工作成为本体工程中不可或缺的重要环节.本体调试对本体建模人员来说是一项巨大的挑战,尤其是随着本体语言描述能力复杂度的提高和本体规模的增长,纯手工完成对复杂本体语言或大规模本体的调试工作是不可能的[6].现有的标准本体推理任务和推理机具备判定逻辑是否不一致的推理能力,但无法提供有效的参考信息和帮助来解决或排查本体中的逻辑冲突.本体调试的研究就是期望提供有效的方法和手段,辅助本体建模人员实现逻辑冲突的快速定位和冲突解决方案的自动生成.
本体调试在确定和解决本体中逻辑冲突的过程中,一般分为诊断和修复两个阶段[7],人工智能中的自动推理技术更适于处理第一阶段的问题.这是因为自动推理领域的一个共识是:如何选择最理想的方案解决逻辑冲突,是领域专家需要考虑的问题.自动化系统并不具备代替领域专家完成本体修复阶段任务的能力,而更善于对逻辑冲突进行搜索和定位.因而本体调试的大多数研究工作实际上是研究逻辑冲突的诊断问题(即逻辑冲突的定位),而不是逻辑冲突的解决和修复.
理论上,本体中的逻辑冲突表现为inconsistency或incoherency两种不一致,其中,inconsistency有时也泛指这两类冲突.根据Flouris[8]的定义,这里将二者加以区分:inconsistency指本体不存在任何模型,而incoherency特指本体中包含不可满足概念.Qi&Pan[9]提出了一种针对不一致本体的有效推理算法,并利用此算法实现inconsistency分层本体的调试;Meyer[10]将命题逻辑不一致管理技术加以改进并引入到描述逻辑本体,使用了conjunctive maxi-adjustment算法[11]实现对分层本体的调试过程的优化;Haase[12]提出使用本体进化方法避免本体的inconsistency、使用特殊的推理技术忽略本体中的inconsistency或者使用版本控制技术间接处理本体的inconsistency;Yue[13]利用超协调方法处理本体中的inconsistency,达到调试本体的目的.
以上的工作均是处理inconsistency的本体调试.事实上,本体调试的大多数工作都集中在如何解决incoherency[14].因为在本体的语境下,incoherency是很重要的性质,不可满足概念的存在通常表明本体中概念的形式化定义是有问题的.这一类研究中,通常都借助Tableau演算定位本体中的incoherency.Schlobach等人[15,16,17]给出了概念不可满足和本体不一致原因的形式化定义,即,最小不可满足保持子术语集MUPS和最小不连贯保持子术语集MIPS,并给出了扩展Tableau演算规则的不一致本体调试方法,但是只适用于非循环ALC不一致本体.Meyer[14]同样针对非循环ALC不一致本体计算不可满足概念的最大可满足术语集,并且做了大量的实验来分析方法的性能.Lam[6]扩展了Schlobach的工作,将incoherency从冲突公理集合进一步定位到冲突公理集合的某一局部,他将追踪incoherency的部分公理集的技术结合进来,提高了基于Tableau的本体调试算法的调试能力.Plesser[18]同样在Tableau演算的基础上构建概念依赖树得到MUPS,这种方法更适用于本体进化过程. Kalyanpur[19-21]对同一本体中多个不可满足概念之间的关联性做了分析和研究,定义了不可满足概念间的依赖关系,针对一些特殊概念,结合碰集方法计算其辩护(比MUPS更宽泛的概念,MUPS是辩护的特例),他们计算辩护的算法效率是比较高的.不修改Tableau演算,只调用外部推理机判断概念的可满足性实现本体错误的定位,因为不受本体语言和公理的类型限制,这种方法能够更好地应用于实际中.其中,Schlobach[15,16,17]可以计算单个MUPS,加入启发式和模式匹配也不能保证得到所有的MUPS[22],Kalyanpur[19,20,21]进一步地结合碰集树方法计算所有MUPS.Kostyantyn[23]将模型诊断[24, 25]中的基本定义和方法引入到本体调试中,给出了本体通用的诊断理论,提出一种不依赖于特定推理系统的正确完备求解最小不一致公理集的方法.文献[26, 27]则对诊断使用二分策略以减少对本体蕴含的查询,能够快速给出目标诊断.另外一些工作致力于不同描述逻辑语言表示的本体的调试方法及其优化,本体模块化方法能够很好地提高现有本体调试算法的效率,尤其处理大规模本体数据.文献[28]使用本体模块化限制计算OWL DL本体不可满足概念的所有辩护过程的搜索空间.文献[29]提出一种基于目标驱动的优化方法能够抽取出保证覆盖蕴含式所有辩护的模块,改进先前静态局部模块方法抽取模块规模大的弊端.文献[30]通过分析DL-Lite语言中不可满足概念或角色所具有的特点,针对DL-Lite本体给出计算概念MUPS的算法.
Haase和Qi[31]对本体调试研究进行系统性的分析和综述,对与调试直接或间接相关的方法进行了分类,并用各种标准对其进行较为严格的评价.通过分析和评测,他们认为:没有哪一种本体调试的方法是普遍适用于所有应用场景的,不同的方法是适合于不同调试目的和调试要求的.
就本体调试中的incoherency定位问题,本文针对描述逻辑中的非循环ALC本体术语集,借助Tableau演算推理方法研究不可满足概念与本体冲突的关联,提出基于概念R-MUPS的本体调试方法定位本体冲突.从问题定义来看,本文研究本体调试中的incoherency不一致冲突定位问题,而不是文献[9-12]的inconsistency不一致问题;从研究对象来看,本文研究针对非循环ALC本体的术语集(即TBox)逻辑冲突定位,而不同于文献[25-27]中的具体本体模型(即特定TBox下的ABox);从调试方法上来看,本文研究如何利用基于Tableau演算的推理机制(即白盒测试)直接解决incoherency的冲突定位,不同于文献[19-24]利用本体推理的标准问题结果或诊断方法(即黑盒测试)间接解决incoherency的冲突问题;在众多白盒测试方法的研究工作中,本文并不研究兼容于白盒测试的优化技术,如文献[27-30],而是研究导致本体冲突的本质原因;在探求冲突成因的研究中,不同于文献[15-17]中通过寻找不可满足概念的MUPS集合间接定位冲突,而是通过定义R-MUPS直接建立不可满足概念与冲突的联系.本文给出基于有序标签的本体调试的框架,其中以ALC语言为例,其他更复杂的描述逻辑本体可以在此基础上加以扩展,通过修改相应的Tableau规则予以实现.
本文第1节介绍ALC描述逻辑语言、本体中的基本概念以及标准的Tableau演算推演规则.第2节中形式化定义本体调试中的不一致(incoherency)定位问题,并给出概念覆盖、R-MUPS等一系列概念和定理,论述本文定义的R-MUPS与MUPS和MIPS之间的关系.第3节对基于R-MUPS的MIPS求解算法进行了表述和实例分析,并进一步给出算法正确性证明及其复杂度和效率分析.第4节用自动生成的本体测试集和现实本体及其扩建本体对算法进行实验评估,并与经典的基于Tableau推理的调试方法进行了分析比较.最后给出结论和工作意义,并指出下一步工作.
1 ALC及Tableau演算描述逻辑(description logics,简称DLs)是刻画本体的最常用形式化语言,它具有较强的表达能力,并能够提供可判定的推理服务.Baader&Nutt 2003[32]给出了关于描述逻辑的详细介绍.
用描述逻辑表示的本体知识库(knowledge base,简称KB)是由TBox和ABox两部分组成:
• TBox也叫术语集(terminology),是由C⊑D 或C$ \equiv $D形式的公理构成,其中,C$ \equiv $D等价于C⊑D和D⊑C,OWL中的disjoint(C,D)等价于C⊑$\neg $D和D⊑$\neg $C.如果公理左边是原子概念,称公理为该原子概念的一条定义公理;同时,该原子概念是命名符号,本体中没有定义公理的概念是基本符号.ALC描述逻辑语言中的概念描述为C,D$ \to $⊥| |A|?C|C
|A|?C|C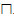 D|C
D|C D|$\exists $|R.C.
D|$\exists $|R.C.
• 其中,⊥为空集,为全集,A是原子概念,R是抽象角色;
• ABox是关于领域个体的断言集合,包括概念断言C(a)和角色断言R(a,b)两种:C(a)表示个体a满足概念C在TBox中的描述;R(a,b)表示个体a与b满足关系R,或者说个体b是角色R中个体a的承载者. DL的解释I=($\Delta $I,•I),$\Delta $I表示解释的域(个体集);•I是映射函数,对原子概念C映射为一个集合CI$ \subseteq $$\Delta $I, 对角色R映射为二元关系$\Delta $I×$\Delta $I.解释I是公理C⊑D的模型,如果I满足CI$ \subseteq $DI;解释I是本体 的模型,如果I满足中的所有公理.
的模型,如果I满足中的所有公理.
概念C在本体中是不可满足的当且仅当的所有模型I都有CI=$\emptyset $.判定概念可满足性是本体推理中的基本问题,其他的推理任务都可以相应地转化为概念可满足判定问题,Tableau演算可以判定TBox中概念的可满足性,ALC语言的Tableau扩展规则如图 1所示.

|
图 1 ALC 语言判断概念可满足性的Tableau扩展规则 Fig.1 Tableau transformation rules of concept satisfiability for ALC |
Tableau演算根据不同的规则来扩展分解概念C,其中每条扩展规则与描述逻辑中的构造算子相对应.其中,构造算子⊔会产生一个新的ABox,其他的构造算子扩展当前的ABox.初始时的ABox A={C(a)},当没有扩展规则可用或出现冲突时,Tableau演算终止.此时,扩展得到一个ABox集S={A1,…,An},其中:如果存在一个ABox Ai (Ai$ \in $S)是不封闭的,则概念C是可满足的;反之,若所有的Ai(Ai$ \in $S,1≤i≤n)都是封闭的,则概念C是不可满足的.ABox A是封闭的,如果A满足{⊥(x)}$ \subseteq $A或者{A(x),$\neg $A(x)}$ \subseteq $A,其中:x是Tableau演算过程中产生的某个个体;A
是原子概念,将A(x),$\neg $A(x)称为一个冲突对.
2 本体术语集调试中的R-MUPS 2.1 不一致的定位问题本体的逻辑冲突是本体工程中常见的问题,在诸如本体建模、本体融合、本体整合、本体迁移、本体进化等各种操作中极易产生.逻辑冲突一般表现为本体的逻辑不一致.文献[8]将本体不一致性解释为存在不可满足概念,定义如下.
定义1(TBox不一致(incoherency)[8]). TBox T是不一致的当且仅当T中存在一个不可满足概念.
本体术语集不一致,即是本文所要研究解决的逻辑冲突.我们所要完成的本体调试工作,就是通过确定和修复逻辑冲突,使本体达到逻辑一致的过程.Schlobach[15]认为:基于描述逻辑系统的调试结果是一个存在逻辑冲突的公理集,去掉或修改该结果,可以使一个或者多个概念可满足,命题逻辑中的诊断是建立在极小冲突集[24]基础之上.如果通过本体调试能够确定出所有这样的极小冲突公理集,即达到定位本体不一致的效果.下边通过一个例子解释本体调试相关概念和过程,并简单说明概念不可满足原因和本体术语集不一致原因.
以下面的术语集T1为例,试图构建一个包含7条公理的科研领域角色定义的知识术语集,其中,公理α4定义了概念“大学老师”A4是必须指导学生(即表示为$\forall $s.B)的教师(即表示为C).公理α5定义了概念“研究员”A5是至少指导一个不是学生的人,比如职工(即$\exists $s.$\neg $B).公理α3定义了身份既是大学老师又是研究员的,才是概念“科研人员”A3.从逻辑认知的角度得知,如此定义的“科研人员”是不存在的,即概念A3是不可满足的.原因在于根据定义A4和A5可知,“大学教师”和“研究员”是两个不相交的概念.即:一个实例要么所指导的人都是学生,要么所指导的人中至少存在一个不是学生,这两种情况不可能同时发生在同一个实例上.在人工智能的自动推理领域中,Tableau演算可以有效模拟人类思维去判别概念逻辑冲突的这一过程.类似A3,可以得到TBox T1中其他不可满足概念A1,A6和A7.但是经典的Tableau演算仅能够确定不可满足的概念,对概念为什么不可满足以及不可满足概念之间是否存在一些联系未加进一步推演.例如:概念A3不可满足是公理集{α3,α4,α5}导致的,A3是否可满足又决定概念A1的可满足性,或者说本体术语集中一个不可满足概念制约其他某些概念的可满足性.此外,A1定义中的$\neg $A和A2定义中的A构成一个冲突对,也导致概念A1不可满足,说明促使概念不可满足的原因并不唯一.
例:TBox T1:
α1: A1⊑$\neg $A⊓A2⊓A3 α2: A2⊑A⊓A4 α3: A3⊑A4⊓A5
α4: A4⊑$\forall $s.B⊓C α5: A5⊑$\exists $s.$\neg $B α6: A6⊑A1⊔$\exists $r.(A3⊓$\neg $C⊓A4)
α7: A7⊑A4⊓$\exists $s.$\neg $B
本体调试问题就是找出TBox不一致的所有原因,先给出概念不可满足原因的定义:
定义2(MUPS[15]). 设概念C是TBox T中的不可满足概念,一个子集$T'$$ \subseteq $T称为T中C的极小不可满足保持子集(minimal unsatisfiability preserving sub-Tbox,简称MUPS),如果C在$T'$下是不可满足的,则对于任意$T''$$ \subset $$T'$,C在$T''$下都是可满足的.用mups(T,C)表示T中关于C的所有MUPS的集合.
例子TBox T1中,mups(T1,A1)={{α1,α2},{α1,α3,α4,α5}}.由MUPS定义知,{α1,α2}和{α1,α3,α4,α5}任意子术语集都使得A1是可满足的.类似地有mups(T1,A3)={{α3,α4,α5}},mups(T1,A6)={{α1,α2,α4,α6},{α1,α3,α4,α5,α6}}, mups(T1,A7)={{α4,α7}}.MUPS是概念不可满足原因的形式化定义,下面针对本体术语集给出其不一致原因MIPS的形式化定义:
定义3(MIPS[15]). 设TBox T是不一致的,一个TBox $T'$$ \subseteq $T称为T的极小不一致保持子集(minimal incoherence-preserving sub-Tboxes,简称MIPS),如果$T'$是不一致的,对于任意TBox $T''$$ \subset $$T'$,$T''$是一致的.用mips(T)表示T中所有MIPS的集合.
本体调试的定义并不依赖某种特定的描述逻辑,本体术语集调试得到术语集的MIPS,对应诊断中的极小冲突集.例子TBox T1的MIPS为mips(T1)={{α1,α2},{α3,α4,α5},{α4,α7}},A1在公理集{α3,α4,α5}下是可满足的,A3却是不可满足的.TBox不一致说明本体中至少存在一个不可满足概念,本体术语集的每个MIPS必定会使得本体中的某些概念不可满足,而且MIPS的任意一个子集都没有这样的性质.进一步地,Kalyanpur在MUPS的基础上,将不可满足概念分为根和派生两类概念.
定义4(根与派生不可满足概念[19]). TBox T中,概念C是派生不可满足概念,如果C满足以下条件:存在i,j使得MUPSi(D)$ \subseteq $MUPSj(C).这种情况下,称C是派生不可满足概念,简称派生概念.如果C不满足这个条件,则C是一个根不可满足概念,简称根概念.其中,D是本体中另一个不可满足概念,0≤i≤|mups(T,D)|,0≤j≤|mups(T,C)|,即,任意的MUPSi(D)$ \in $mups(T,D),MUPSj(C)$ \in $mups(T,C).
根概念指概念的可满足性不依赖本体中其他不可满足概念,这种不可满足性源于概念自身定义公理的矛盾,例如T1中的A3.派生概念指概念不可满足直接或间接地依赖本体中另一个不可满足概念,例如T1中的A1依赖A3;同时,{α1,α2}也是A1的不可满足错误.
2.2 相对极小不可满足保持子术语集(R-MUPS)本体术语集由公理组成,每条公理是公理左端概念的一个形式化定义,每个命名概念都有相应的公理对其进行定义.给定本体术语集T,称T中的概念C直接使用D(D是原子概念或者角色),如果D出现在C的定义公理的右端,称直接使用的传递闭包为使用.本体包含一个循环,如果存在一个使用概念自身的原子概念,也称本体是循环的.表达能力最强的描述逻辑语言DL SROIQ包含枚举型概念({a1,...,an},其中,ai是个体,1≤i≤n),概念包含和等价公理,角色包含公理等[32].我们用U(T,C)为定义概念C所使用的符号集,其中包括概念、角色和个体符号.例子TBox T1中,U(T1,A1)={A,A2,A3,A4,A5,B,C,s}.
定义5(概念覆盖). 设T是一个不一致的本体术语集,C1和C2是T中两个不可满足概念.称C2覆盖C1,如果C2$ \in $U(T,C1).用cover(T,C)表示T中所有覆盖C的概念的集合.
概念覆盖能够反映不可满足概念之间的依赖关系,概念C依赖cover(T,C).根概念在一定程度上决定派生概念的可满足性,如果没有概念覆盖C,那么C是根概念;否则,C是派生概念.例子T1中cover(T1,A1)={A3},cover(T1, A3)={},A1是A3的派生概念.相反,根概念和派生概念不能完全体现概念覆盖.例如,TBox T={β1:B1⊑$\neg $A⊓B2, β2:B2⊑A⊓B3,β3:B3⊑$\neg $A},mups(T,B1)={{β1,β2}},mups(T,B2)={{β2,β3}},由Kalyanpur的根概念定义知,B1和B2都是根概念,因为β1中的$\neg $A与β2中A冲突,掩盖了β2中A与β3中$\neg $A的冲突,使得{β1,β2,β3}不是B1的MUPS.根据概念覆盖有B2$ \in $U(T,B1),即B1覆盖B2.
定义6(R-MUPS). 设概念C是TBox T中的不可满足概念,M=${ \cup _{C'}}_{ \in cover\left( {T,C} \right) \cup \left\{ C \right\}}mups(T,C')$.一个TBox $T'$$ \in $M称为C的相对MUPS(relative minimal unsatisfiability preserving sub-Tbox,简称R-MUPS),如果不存在$T''$$ \in $M使得$T''$$ \subset $$T'$.用r-mups(T,C)表示T中关于C的所有R-MUPS的集合.
换句话说,R-MUPS是合并概念及其覆盖概念的所有MUPS的极小值.例子TBox T1中,r-mups(T1,A1)={{α1, α2},{α3,α4,α5}},{α3,α4,α5}对应的概念A3被A1覆盖.同样可以得到:
r-mups(T1,A3)={{α3,α4,α5}},r-mups(T1,A6)={{α1,α2},{α3,α4,α5}},r-mups(T1,A7)={{α4,α7}}.
根据R-MUPS的定义,显然知,不可满足概念的R-MUPS具有如下性质,其中,T是一个本体术语集,C是T中的不可满足概念:
(1) 对任意$C'$$ \in $cover(T,C),都有r-mups(T,$C'$)$ \subseteq $r-mups(T,C);
(2) 如果T中没有覆盖C的概念,那么r-mups(T,C)=mups(T,C);
(3) 对任意C都有r-mups(T,C)$ \ne $$\emptyset $.
引理1. C是本体术语集T中的不可满足概念,则对任意e$ \in $mups(T,C)都有Sig(e)$ \subseteq $U(T,C),其中,Sig(e)表示术语集e中使用的符号集(包括概念符号和角色符号).
定理1. C是本体术语集T中的不可满足概念,则r-mups(T,C)中的每个元素都是T的MIPS.
证明:根据R-MUPS的定义知r-mups(T,C)$ \subseteq $M,其中,M=${ \cup _{C'}}_{ \in cover\left( {T,C} \right) \cup \left\{ C \right\}}mups(T,C)$.假设存在ex$ \in $r-mups(T,C)不是T的MIPS,即,存在ey$ \subset $ex是T的MIPS.不妨设ex和ey分别为Cx和Cy的MUPS,由于ey$ \subset $ex,根据引理1得Cy$ \in $U(T,Cx),并且由概念覆盖的定义有Cy$ \in $cover(T,Cx).所以有Cy$ \in $cover(T,C),进而ey$ \in $M,这与ex$ \in $r-mups(T,C)矛盾.假设不成立,证毕. □
MIPS表示的本体术语集是不一致的,并且它的任意真子集表示的术语集是一致的.也就是说,MIPS使得某些概念不可满足,而这些概念基于MIPS的真子集所表示的术语集是可满足的.这样,MIPS必然是术语集中的某些不可满足概念的MUPS.同样地,由定理1可以知道:对于不一致本体的任意MIPS而言,必然存在某些不可满足概念的R-MUPS与之相等.所以,通过计算所有概念的R-MUPS,可以得到本体术语集的所有MIPS.但是由于不可满足概念的R-MUPS是建立在其覆盖概念的MUPS基础之上的,所以可以得到下边的定理:
定理2. 本体术语集T,任意rt$ \in $mips(T),T中至少存在一个不可满足概念C,使得rt$ \in $r-mups(T,C).
证明:Cpt(T)表示由T中所有不可满足概念构成的集合,令Tm=${ \cup _{C'}}_{ \in Cpt\left( T \right)}mups(T,C')$.对T中的任意不可满足概念C,令MC=${ \cup _{C'}}_{ \in {\mathop{\rm cov}} er\left( {T,C} \right)\left\{ C \right\}}mups(T,C')$,那么Tm=${ \cup _{C'}}_{ \in Cpt\left( T \right)}$${M_{C'}}$.用min(S)表示S在集合包含的偏序关系下的所有极小值构成的集合,根据R-MUPS定义,可知r-mups(T,C)=min(MC),由MIPS的定义有mips(T)=min(Tm).综合上边得到的等式,有mips(T)=min(Tm)=min(${ \cup _{C'}}_{ \in Cpt\left( T \right)}$${M_{C'}}$)=${ \cup _{C'}}_{ \in Cpt\left( T \right)}$min(${M_{C'}}$)=${ \cup _{C'}}_{ \in Cpt\left( T \right)}$r-mups(T,$C'$),证毕. □
定理2说明:求解本体术语集T的MIPS可以通过计算每个概念的R-MUPS可以得到;计算一个概念的R-MUPS等价于计算T的某个子术语集的MIPS.因为概念之间的覆盖关系,这个子术语集包含覆盖的概念.也就是说,如果已经知道某个概念的R-MUPS,那么不需要再对覆盖它的概念计算其R-MUPS.结合二者,本文算法可以快速实现本体调试:计算本体术语集T的mips(T)过程中,如果已经计算了不可满足概念C的r-mups(T,C),那么不用计算r-mups(T,$C'$),其中,$C'$$ \in $cover(T,C).
3 基于R-MUPS的MIPS求解Schlobach方法计算MIPS是基于MUPS,即:计算本体术语集中所有概念的MUPS并将其合并,再取其中的极小值得到术语集的MIPS.换句话说,合并TBox T中所有概念的MUPS得到集合Smups(T),Smups(T)上的集合包含关系是一个部分序关系,记为PS,则mips(T)是由Smups(T)在关系PS下的所有极小元构成.例子T1中,
Smups(T1)={{α1,α2},{α1,α3,α4,α5},{α3,α4,α5},{α1,α2,α4,α6},{α1,α3,α4,α5,α6},{α4,α7}};
mips(T1)={{α1,α2},{α3,α4,α5},{α4,α7}}.
3.1 R-MUPS算法为计算不可满足概念的R-MUPS,在Tableau演算扩展规则(如图 1所示)的基础上,定义标注有序标签的扩展规则(如图 2所示),它是在Tableau演算的基础上为断言加上一个标签形如(a:C)label,a是个体,C是概念,标签label是一个内部元素有序的公理集合.它以公理加入到标签中的先后为序,本文将带标签的断言简称为断言. R-MUPS算法执行的终止条件是:没有规则可用或者存在某个分支没有冲突(概念可满足).R-MUPS算法中,一个分支存在冲突,则该分支至少存在一个个体是⊥概念的实例或者同时是某个原子概念及其否定的实例.总是假定公式都是否定范式(negation normal form,简称NNF,否定只出现在原子概念前边).

|
Fig.2 Tableau transformation rules of R-MUPS for acyclic ALC (with labels) 图 2 非循环ALC TBox中概念的R-MUPS表扩展规则(带标签) |
首先对标签及其运算进行说明如下,其中,L1和L2是标签,βi(其中,1≤i≤m)表示公理:
(1) 标签用[β1,...,βm]表示,记法中,从左到右为公理加入到标签中的先后顺序,即标签的顺序;
(2) 用βi=NULL表示公理无效,最终不会出现在MUPS,MIPS和R-MUPS中,用作标签运算中的分界标识.公理相等当且仅当公理的标记一样,并且均不为NULL(公理的标记为βi);
(3) L1?L2,将L2中元素(包括NULL)逐个添加到L1的末尾,返回L1;
(4) L1$\infty $L2,将L2与L1不同的部分合并到L1中.合并方法:L1从头开始,在L1和L2第1次出现不等元素位置的前边插入无效公理,即NULL(分界标识);然后,将L2的剩余元素依次添加到L1的末尾,返回L1.
使用图 2给出的规则进行R-MUPS扩展时,对B运用⊔l-rule规则产生新分支,新分支则用产生分支断言的标签作为自己的标记,并且设置其父分支为当前分支.每个分支都有自己的标记(标签),记录从根分支到新分支扩展过程中所需的公理,标记中,末尾公理所描述的概念说明对其应用⊔l-rule规则产生标记所表示的分支.这样,n次运用⊔l-rule规则之后产生新分支Bn,产生分支路径为B-B1-…-Bk-1-Bk,称B为根分支,Bi是Bi+1的父分支, Bi+1是Bi的子分支,Bi为Bk的祖先分支,Bk为Bi的子孙分支,其中0≤i≤k-1,B0=B;对B运用⊓l-rule规则,满足条件则向B中加入新的断言,新断言继承标签;对B运用Axl-rule规则,向断言的标签末尾添加新公理;对B运用$\exists $l-rule规则,新增断言是由相应的存在((a:$\exists $Ri.C)L)和全称限定断言((a:$\forall $Ri.Cj)Lj,1≤j≤n)共同产生,执行L$\infty $Lj,在Lj与L共同公理部分之后加入分界标识NULL,表示标签中NULL之后的公理受到限定断言的约束,并将存在限定断言中约束全称限定断言的公理主次添加至其末尾.
R-Mups-ComputeFunction计算本体术语集T中概念C的所有R-MUPS和覆盖C的所有概念,返回值为$\langle $R-mups,Cover$\rangle $,其中,R-mups=r-mups(T,C),cover(T,C)$ \subseteq $Cover(如果C可满足,cover(T,C)=$\emptyset $).初始时,分支列表BranchList={B}只有一个分支B,其中,B={(a:C)$\emptyset $},B的标记为空,B的父亲分支为其自身.从BranchList中获取分支,对分支使用图 2中规则进行扩展,其中,运用⊔l-rule规则向BranchList头部插入新元素(新分支),使得BranchList={$B'$,$B''$,...},实现深度优先遍历分支.没有规则可用时,当前分支扩展终止,得到:
BranchList={$B'$,B1,…,Bn}.
如果当前分支$B'$存在冲突,首先调用conflictCompute($B'$,T)计算C在$B'$的R-MUPS,并分别处理返回值$\langle $Unsat,ownCon,fatherCon$\rangle $的各个部分:将Unsat表示的$B'$中不可满足概念加入到Cover,$B'$的自身冲突ownCon加入到R-mups,当前分支和fatherCon压入栈顶;然后调用函数CombineBranch(Stack,T),合并已经处理过的分支和当前分支,将合并后分支的自身冲突加入到R-mups;最后,当所有分支都处理完毕,将栈中的剩余分支回溯至根分支,并获取根分支的冲突.如果分支$B'$没有冲突,说明C是可满足的,那么R-mups=$\emptyset $,Cover={A|(a:A)z$ \in $$B'$},即,Cover保存$B'$中各断言所对应的原子概念,这些概念是可满足的,然后函数直接返回,见算法1.
算法1. 计算所有R-MUPS算法R-Mups-ComputeFunction(C,T).
输入:概念C,非循环ALC本体术语集T;
输出:公理集合簇(r-mups(T,C))R-mups,概念的集合Cover.
Step 1. 初始化变量R-mups,Cover,Stack为空,B={(a:C)$\emptyset $},BranchList={B};
Step 2. 遍历BranchList中的分支Br,做如下操作:
Step 2.1. 使用Fig. 1.1中的规则对Br进行扩展,直到没有规则可以使用时终止;
Step 2.2. 如果Br没有冲突,清空R-mups和Cover,遍历Br的断言(a:A)z,将A加入到Cover中,返回(R-mups,Cover);
Step 2.3. 如果Br存在冲突,做如下操作:
Step 2.3.1. 调用conflictCompute函数计算Br中的冲突,返回值为(Unsat,ownCon,fatherCon);
Step 2.3.2. 将$\langle $Br,fatherConñ入栈Stack;
Step 2.3.3. 调用CombineBranch函数计算分支合并后的所有冲突backCon;
Step 2.3.4. 取R-mups$ \cup $ownCon$ \cup $backCon中的极小值保存到R-mups中;
Step 2.3.5. 合并Unsat到Cover中;
Step 2.4. 从BranchList中删除Br;
Step 3. 将$\langle $null,null$\rangle $入栈Stack,作为结束标识符;
Step 4. 调用CombineBranch函数计算最后分支合并后的所有冲突backCon;
Step 5. 弹出Stack中的栈顶元素$\langle $rootBr,rootCon$\rangle $;
Step 6. 取R-mups$ \cup $rootCon中的极小值保存到R-mups中;
Step 7. 返回(R-mups,Cover);
冲突计算函数conflictCompute(C,B,T),实现计算概念C在分支B下的R-MUPS和覆盖C的所有概念.变量father记录当前分支到根分支的所有标记中的元素,Unsat记录B中的不可满足概念,ownCon记录分支自身的冲突,fatherCon记录除自身冲突之外的冲突,ownCon和fatherCon共同保存概念C在分支B下R-MUPS.关于冲突对(a:A)x和(a: $\neg $A)y,将标签x和y从头到尾第1次出现对应位置元素不相等的前一个公理记作αB,那么合并x和y中从αB到末尾间的公理集(由变量con表示),使得αB所描述的概念是不可满足的;进一步地,x或y中从头到αB之间的公理所表示的概念都是不可满足的(保存在变量Unsat中).如果αB不在father中,表示con可能是B上覆盖C的某个概念的MUPS,称为当前分支的自身冲突,保存到ownCon中;否则,保存到fatherCon中,称为当前分支的祖先冲突,见算法2.
算法2. 计算分支冲突算法conflictCompute(C,B,T).
输入:概念C,分支B,非循环ALC本体术语集T;
输出:概念的集合Unsat,公理集合簇ownCon,公理集合簇fatherCon.
Step 1. 初始化变量Unsat,ownCon,fatherCon,father为空,Btmp为B;
Step 2. 将分支Btmp的标记加入到father中;
Step 3. 做如下操作,直到Btmp的父亲分支不是其自身:
Step 3.1. 修改Btmp为其父亲分支;
Step 3.2. 将Btmp的标记加入到father中;
Step 4. 遍历B中冲突对(a:A)x和(a:$\neg $A)y,做如下操作:
Step 4.1. 将x和y中从开始,到第一次出现元素不相等位置之间的公理所描述的概念添加到Unsat中;
Step 4.2. 合并x和y中从第一次出现不等元素的前一位置的元素,到各自末尾之间的公理到con中,删除NULL;
Step 4.3. 如果con和father不相交,取ownCon$ \cup ${con}中的极小值保存到ownCon中;
否则,取fatherCon$ \cup ${con}中的极小值保存到fatherCon中;
Step 5. 返回(Unsat,ownCon,fatherCon);
分支合并函数CombineBranch(Stack,T),R-Mups-ComputeFunction(C,T)函数采用深度优先顺序处理各包含冲突的分支是分支合并的前提.如果栈顶元素$\langle $curBr,curCon$\rangle $=$\langle $null,null$\rangle $,表示C没有分支可扩展,则合并栈Stack中未处理的分支并回溯至根分支,Stack为空时终止.如果栈顶元素$\langle $curBr,curCon$\rangle $$ \ne $$\langle $null,null$\rangle $时,需要对当前分支和栈Stack中的分支进行祖孙关系判断,并作出相应的操作:如果栈Stack为空,表示当前分支是第1个分支,分支合并函数第1次被调用,将$\langle $curBr,curCon$\rangle $压栈并返回;如果栈Stack不为空,进行分支关系的判断,其中, CommonBranch为preBr与curBr到根分支的分支序列中第1个相同的分支:(1) 如果preBr与curBr相等,判断是否是同一分支,是则合并两个分支(将preBr并入到curBr中),再将$\langle $curBr,curCon$\rangle $压栈返回;(2) 如果preBr是curBr的祖先分支,不能合并分支,则依次将$\langle $preBr,preCon$\rangle $和$\langle $curBr,curCon$\rangle $压栈返回,等待当前分支处理完毕; (3) 如果preBr与curBr不是同一分支并且preBr不是curBr的祖先分支,则将preBr回溯至preBr与curBr第1个共同分支CommonBranch停止:首先,preBr回溯为其父分支,并分离新preBr的自身冲突(保存到backCon中)和祖先冲突(参与合并分支时的冲突计算),然后将CombineBr并入到preBr中(合并后分支的冲突是由参与合并分支的祖先冲突计算得到),称这样的过程为一次回溯.preBr与CommonBranch同一分支时回溯终止,再判断preBr与curBr是否进行同一分支的合并操作,见算法3.
算法3. 分支合并算法CombineBranch(Stack,B,T).
输入:栈Stack,分支B,非循环ALC本体术语集T;
输出:公理集合簇backCon.
Step 1. 初始化变量backCon为空;
Step 2. 弹出Stack的栈顶元素$\langle $curBr,curCon$\rangle $;
Step 3. 如果Stack非空,做如下操作:
Step 3.1. 弹出Stack的栈顶元素$\langle $preBr,preCon$\rangle $;
Step 3.2. 如果curBr为null,则变量CommonFather为null;
否则,CommonBranch为curBr和preBr到根分枝序列中第一个共同的祖先分支;
Step 3.3. 如果preBr与curBr表示的是不同分支,且preBr$ \ne $CommonBranch,做如下操作,直到Stack为空:
Step 3.3.1. 将preCon中与preBr的所有祖先分支都无交集的元素加入到backCon中,保留backCon中的极小值;
Step 3.3.2. 弹出Stack的栈顶元素$\langle $CombineBr,CombineCon$\rangle $;
Step 3.3.3. 令preBr=CombineBr;
Step 3.3.4. 取CombineCon和preCon笛卡尔乘积的极小值保存到preCon中;
Step 3.3.5. 如果CommonBranch和preBr表示同一分支,则跳出循环,即,跳至Step 3.4;
Step 3.4. 如果curBr不为null,并且curBr=preBr,则取curCon和preCon笛卡尔乘积的极小值保存到
curCon中;
否则,将$\langle $preBr,preCon$\rangle $入栈,即,加入到Stack中;
Step 4. 如果curBr不为null,将$\langle $curBr,curCon$\rangle $入栈,即,加入到Stack中;
Step 5. 返回backCon;
3.2 R-MUPS算法举例以前面的TBox T1为例,计算R-Mups-ComputeFunction(A6,T1),初始BranchList={B},B={(a:A6)$\emptyset $}.
Step 1: 对B中(a:A6)$\emptyset $使用Axl-rule规则,得:$B'$={(a:A6)$\emptyset $,(a:A1⊔$\exists $r.(A3⊓$\neg $C⊓A4))α6},BranchList={$B'$};
Step 2: 对B应用⊔l-rule规则:BranchList={$B'$,$B''$},$B'$={(a:A6)$\emptyset $,(a:A1⊔$\exists $r.(A3⊓$\neg $C⊓A4))α6,(a:A1)α6}(标
记为[α6],父分支为$B'$),$B''$={(a:A6)$\emptyset $,(a:A1⊔$\exists $r.(A3⊓$\neg $C⊓A4))α6,(a:$\exists $r.(A3⊓$\neg $C⊓A4))α6}(标记为[α6],父分支为$B'$);
Step 3: 对$B'$使用Axl-rule,⊓l-rule和$\exists $l-rule规则逐步扩展,没有规则可用时终止,图 3给出$B'$的扩展过程和结果;
Step 4: 调用conflictCompute(A6,$B'$,T1)计算A6在$B'$下的R-MUPS,再将$B'$和返回值fatherCon压栈.每个
冲突对的计算结果如下,其中,变量father={α6}合并从$B'$到根分支序列上各个分支的标记,
common是冲突对标签中共同部分的公理所描述的概念,con是冲突对计算得到的冲突,father和
con与函数conflictCompute中的同名变量对应:
(1) ${(a:A)^{[{\alpha _6},{\alpha _1},{\alpha _2}]}}$和${(a:\neg A)^{[{\alpha _6},{\alpha _1}]}}$:con={α1,α2},common={A6,A1};
(2) ${(b:B)^{[{\alpha _6},{\alpha _1},NULL,{\alpha _2},{\alpha _4},{\alpha _3},{\alpha _5}]}}$和${(b:\neg B)^{[{\alpha _6},{\alpha _1},{\alpha _3},{\alpha _5}]}}$:con={α1,α2,α3,α4,α5},common={A6,A1};
(3) ${(b:B)^{[{\alpha _6},{\alpha _1},{\alpha _3},NULL,{\alpha _4},{\alpha _5}]}}$和${(b:\neg B)^{[{\alpha _6},{\alpha _1},{\alpha _3},{\alpha _5}]}}$:con={α3,α4,α5},common={A6,A1,A3};
最后返回值:Unsat={A6,A1,A3},ownCon={{α1,α2},{α3,α4,α5}},fatherCon=$\emptyset $;

|
Fig.3 Branch $B'$ which is R-MUPS transformating about concept A6 for TBox T1 图 3 TBox T1中A6进行R-MUPS扩展中的分支$B'$(标记为[α6],父分支为$B'$) |
第5步: 调用CombineBranch(Stack,T)函数进行分支合并.Stack中只有一个元素$\langle $$B'$,$\emptyset $$\rangle $,直接返回,合并分
支得到的R-MUPS为backCon=$\emptyset $;
第6步: $B'$处理完毕,计算R-mups和Cover值,R-mups是由R-mups,ownCon和backCon合并之后的极小
值构成,Cover是合并Cover和Unsat,R-mups={{
第7步: 对$B''$应用R-MUPS扩展规则逐步扩展结果如图 4所示.

|
Fig.4 Branch B'' which is R-MUPS transformating about concept A6 for TBox T1 图 4 TBox T1中A6进行R-MUPS扩展中的分支B''(标记为[α6],父分支为$B'$) |
第8步: 调用conflictCompute(A6,$B''$,T1)计算A6在$B''$下的R-MUPS,然后将$B''$和返回值fatherCon压栈:
(1) ${(b:C)^{[{\alpha _6},{\alpha _3},{\alpha _4}]}}$和${(b:\neg C)^{[{\alpha _6}]}}$:con={α6,α3,α4},common={A6};
(2) ${(b:C)^{[{\alpha _6},{\alpha _4}]}}$和${(b:\neg C)^{[{\alpha _6}]}}$:con={α6,α4},common={A6};
(3) ${(c:B)^{[{\alpha _6},{\alpha _3},NULL,{\alpha _4},{\alpha _5}]}}$和${(c:\neg B)^{[{\alpha _6},{\alpha _3},{\alpha _5}]}}$:con={α3,α4,α5},common={A6,A3};
(4) ${(c:B)^{[{\alpha _6},NULL,{\alpha _4},{\alpha _3},{\alpha _5}]}}$和${(c:\neg B)^{[{\alpha _6},{\alpha _3},{\alpha _5}]}}$:common={A6},con={α6,α3,α4,α5};
最后返回值:Unsat={A6,A3},ownCon={{α3,α4,α5}},fatherCon={{α4,α6}};
第9步: 调用CombineBranch(Stack,T)函数进行分支合并.Stack中有两个元素:栈顶元素$\langle $curBr,curCon$\rangle $= $\langle $$B''$,{{α4,α6}}$\rangle $,另一个元素$\langle $preBr,preCon$\rangle $=$\langle $$B'$,$\emptyset $$\rangle $.curBr与preBr的标记相同,表示同一个分支,进行合并操作(preBr并入到curBr中)得curCon=$\emptyset $(其中元素为curCon与preCon作笛卡尔乘积的极小值).然后返回,返回值backCon=$\emptyset $;
第10步: $B''$处理完毕,计算R-mups和Cover值,R-mups={{
第11步: 所有分支处理完毕,向Stack中压入$\langle $null,null$\rangle $,然后调用CombineBranch(Stack,T)函数做最后的分支合并处理.Stack中只有一个元素$\langle $preBr,preCon$\rangle $=$\langle $$B'$,$\emptyset $$\rangle $,已经是根分支,返回值backCon=$\emptyset $.
最后计算R-mups为合并R-mups和backCon得到的极小值:R-mups={{α1,α2}{α3,α4,α5}},Cover保持不变,即,Cover={A6,A1,A3}.函数返回值为({{α1,α2},{α3,α4,α5}},{A6,A1,A3}).这个例子简单验证了算法的正确性.
3.3 算法分析本节给出概念扩展树的构建规则与概念R-MUPS扩展过程等价定理,再用扩展树证明关于本体术语集T及其概念C的R-Mups-ComputeFunction(C,T)确实是R-MUPS问题的极小化函数.扩展树E-T中的结点记为(a,C,label),其中,a为个体,C为概念,label为扩展C的有序公理集.如果C=NULL,称结点(a,NULL,label)为空结点(NULL-node)或者关于个体a的空结点.
定义7. 概念扩展树是由唯一的起始结点根结点出发的结点集合,其中:任何非根结点有且仅有一个前驱结点,称之为该结点的父结点;任何结点都可能有多个后继结点,称为该结点的子结点;若某结点没有后继结点,称之为叶子结点.若存在路径n0-…-nm,其中,ni+1是ni的后继结点,则称nm是n0的子孙结点,n0是nm的祖先结点.一个结点到它的某个子孙结点有且仅有一条路径.
定义8. ETree为概念的一个扩展树,node为ETree的一个结点,除去从根结点root到node路径中与node对应个体不相等的空结点,得到结点序列root=(a0,C0,l0)-node1=(a1,C1,l1)-…-node=(an,Cn,ln),node到序列中任一结点nodei(0≤i≤n-1)的路径值为li·li+1·…·ln,其中,node到root的路径为l0·l1·…·ln.用path(n1,n2,ETree)表示树ETree中结点n1到结点n2的路径值,path(n,ETree)表示树ETree中结点n到根结点的路径值,路径值是一个有序公理集.
定义9(LCF). n1和n2是扩展树ETree中两个结点,结点NL是由根结点到n1和n2的路径上最后一个相同的非空结点(NL到根结点之间对应的结点都相同),并且NL对应的概念是原子的,称NL为n1和n2的LCF (LastCommonFather).用lcf(n1,n2,ETree)表示树ETree中结点n1和n2的LCF.
定义10. 概念R-MUPS分支B中的断言(a:C)x与概念扩展树中ETr中非空结点Nc=($a'$,$C'$,y)一一对应,如果$a'$=$B'$,C=$C'$,x=path(Ni,ETr)(标签与路径值中对应元素相等,其中,x中的NULL值与Ni路径结点序列中个体为$B'$的NULL结点对应).如果对任意的(a:C)x$ \in $B都存在($a'$,$C'$,y)$ \in $ETr与之一一对应,称B与ETr一一对应,其中,C为原子概念.
定义11(标识结点). 概念的R-MUPS分支B与概念扩展树ETr一一对应,称结点curNode=(acur,Ccur,lcur)为ETr的标识结点,如果path(curNode,ETr)等于B的标记,并且curNode的路径上不存在其他结点的路径值等于B的标记,称与B的父分支标记对应的标识结点为ETr的父标识结点.
概念R-MUPS扩展规则与图 4中相应的扩展树生成规则一一对应,对概念C进行R-MUPS扩展;相应地,对C执行图 4中相同的规则构建扩展树.初始时,R-MUPS扩展B={(a:C)$\emptyset $},对应扩展树ETr={(a,C,$\emptyset $)}. R-MUPS扩展终止时的每个分支都对应一棵扩展树,如果分支存在冲突,相应的扩展树也是冲突的,其中,与分支冲突对应的结点称为冲突结点.

|
Fig.5 Tableau transformation rules of concept transformation tree for acyclic ALC (with labels) 图 5 非循环ALC TBox概念扩展树的表扩展规则(带标签) |
引理2. R-MUPS扩展终止时得到的每个分支都存在一棵扩展树与其对应,且R-MUPS扩展分支中对应断言的标签等于相应扩展树中非空结点的路径值.
定理3. 关于本体术语集T及其不可满足概念C,极小化函数R-Mups-ComputeFunction(C,T)得到r-mups(T, C)和cover(T,C).
证明:R-Mups-ComputeFunction(C,T)的返回值为(R-mups,Cover),不可满足概念C的R-MUPS扩展得到所有分支BranchList={B1,…,Bn},相应的森林ETList={ETr1,…,ETrn}(森林是树的有限集合),其中,从B1到Bn是采用深度优先的处理顺序.每个分支Bi(1≤i≤n)对应一棵扩展树ETri,分支Bi中的每个冲突对(ci:Ai)li和(ci:$\neg $Ai)ki,分别对应扩展树ETri的冲突结点${N'_1} = ({c_i},{A_i},{l'_i})$和${N'_2} = ({c_i},\neg {A_i},{k_i})$.
(1) 当n=1时,C在R-MUPS扩展终止时只有一个分支B1:结点Cfather=lcf(${N'_1},{N'_2}$),以Cfather为根的子树是对其对应概念进行R-MUPS扩展得到的,Cfather子树中的冲突结点也是其祖先结点的冲突结点.Cfather对应概念不可满足的公理集con=path(${N'_1}$,Cfather,ETr)$ \cup $path(${N'_2}$,Cfather,ETr)-{NULL}(合并路径值并除去其中的NULL值),其祖先结点Anc对应的不可满足公理集为con$ \cup $path(Cfather,Anc,ETr)-{NULL}.Cfather对应的概念被其祖先结点的原子概念覆盖,有Cover=cover(T,C)={Cpt|Cpt是公理β所描述的概念,其中,β$ \in $path(Cfather, ETr)}.用ownCon保存这样的con,则有$R - mups = r - mups(T,C) = { \vee _{con}}_{ \in ownCon}({ \wedge _{ax}}_{ \in con}ax).$
(2) 当n=2时,C在R-MUPS扩展终止时有两个分支B1和B2:已知ETr1和ETr2的分支结点为Bnode=(ab,Cb, lb),(UC1,OC1,FC1)=conflictCompute(C,B1,T),(UC2,OC2,FC2)=conflictCompute(C,B2,T),Cover=UC1$ \cup $UC2,R-mups={con|con是OC1$ \cup $OC2$ \cup ${FC1与FC2笛卡尔乘积}的极小值},只要证明R-mups$ \subseteq $mips(T)成立.假设R-mups中存在conf$ \notin $mips(T),即:存在conm$ \in $r-mups(T,C)满足conm$ \subset $conf.由情形(1)得知,OC1$ \subseteq $mips(T),OC2$ \subseteq $mips(T),所以conm$ \notin $ OC1$ \cup $OC2,conf$ \notin $OC1$ \cup $OC2.设Cm是conm对应的不可满足概念,Cm对应ETr1或ETr2中根结点到Bnode间某个结点Nm=(am,Cm,lm),以Nm为根结点的子树对应Cm的R-MUPS扩展(同样有两个分支),即,conm=con1$ \cup $con2,其中,conj是ETrj(j=1,2)中得到conm的冲突.设βb是描述Cb的公理,分两种情况讨论如下:
$\langle $1$\rangle $ βb$ \notin $conm:βb$ \notin $con1,βb$ \notin $con2,也就是说,使得Cm不可满足的原因conm与分支无关,即con1=con2.如果con1$ \in $ FC1,必然有con2$ \in $FC2,那么con1$ \cup $con2$ \in $R-mups,与conf$ \in $R-mups矛盾.如果con1$ \notin $FC1,则存在cons1$ \in $FC1且cons1$ \subset $ con1,cons2$ \in $FC2且cons1=cons2,那么cons1$ \cup $cons2$ \in $R-mups且cons1$ \cup $cons2$ \subset $conm,与conm$ \in $r-mups(T,C)矛盾.假设不成立.
$\langle $2$\rangle $ βb$ \in $conm:当βb$ \in $con1,βb$ \notin $con2时,有con2$ \in $FC1,那么con2$ \cup $con2$ \in $R-mups且con2$ \cup $con2$ \subset $con1$ \cup $con2,与conm$ \in $ r-mups(T,C)矛盾.当axb$ \in $con1,axb$ \in $con2时,如果conj$ \in $FCj,有con1$ \cup $con2$ \in $R-mups,与conf$ \in $R-mups矛盾;如果conj$ \notin $ FCj,存在consj$ \in $FCj,则cons1$ \cup $cons2$ \subset $con1$ \cup $con2,与conm$ \in $r-mups(T,C)矛盾;如果con1$ \in $FC1,con2$ \notin $FC2,则存在cons2$ \in $FC2且cons2$ \subset $con2,那么con1$ \cup $cons2$ \subseteq $con1$ \cup $con2,与conm$ \in $r-mups(T,C)矛盾或者与conf$ \in $R-mups矛盾.
另外,如果Cb不可满足的,Cover=cover(T,C);否则,cover(T,C)$ \subset $Cover.综上情形$\langle $1$\rangle $、情形$\langle $2$\rangle $,FC1$ \cap $FC2中的元素是FC1与FC2笛卡尔乘积的极小值,R-mups=r-mups(T,C),cover(T,C)$ \subseteq $Cover.
(3) 假设当n=m时成立,证明当n=m+1时成立:从左向右扫描ETr1,…,ETrm+1,查找第1个连续的有相同分支结点的ETrp,ETrp+1,…,ETrq(其中,1≤p<q≤m+1),共q-p+1棵扩展树,设它们的分支结点Bnode=(ab,Cb,lb).合并ETrp,ETrp+1,…,ETrq为一棵扩展树ETrb,对应的Bb为合并Bp,Bp+1,…,Bq得到的分支,Bb的标记是Bj(p≤j≤q)父分支的标记.用ETrb替换ETList中的ETrp,ETrp+1,…,ETrq得到ETList={ETr1,…,ETrp-1,ETrb,ETrq+1,…,ETrm+1},相应的BranchList={B1,…,Bp-1,Bb,Bq+1,…,Bn}.这样,ETrb是Bb对应的一棵扩展树,即,ETrb中的分支结点不是Bnode,不妨设ETrb的分支结点为Fnode.(UCp,OCp,FCp)=conflictCompute(C,Bp,T),…,(UCq,OCq,FCq)=conflictCompute(C, Bq,T),UCb=UCp$ \cup $…$ \cup $UCq,OCb=OCp$ \cup $…$ \cup $OCq,FCb={FCp,…,FCq的笛卡尔乘积的极小值}.令FOb={con|con$ \in $FC AND con$ \cap $path(Fnode,ETrb)=$\emptyset $},FCb=FCb-FOb,OCb=OCb$ \cup $FOb,其他扩展树不影响Fnode的子孙结点的可满足性,则有(UCb,OCb,FCb)=conflictCompute(C,Bb,T).这样处理完之后,BranchList中分支数为m-(q-p),也就是说,C的R-MUPS扩展得到的分支数小于m,得到R-mups=r-mups(T,C),cover(T,C)$ \subseteq $Cover.
综合情形(1)~情形(3),得证. □
R-MUPS算法高效是因为当本体中不可满足概念描述的复杂度高:
(1) 析取构造符较多,即,概念的R-MUPS或者是MUPS扩展的分支较多.R-MUPS算法根据概念之间的覆盖关系对分支中的冲突进行分类,直接分离出本体的MIPS,将剩余的冲突参与到分支合并的计算,这样可以极大地减少分支合并过程中冲突极小化的计算量;
(2) 合取构造符较多,概念R-MUPS扩展的深度深.也就是说,不可满足概念之间的覆盖关系多.计算一个不可满足概念的R-MUPS过程中,大部分冲突都是分支自身的冲突,即,本体的MIPS,也减少了计算量;同时,计算一个概念的R-MUPS过程中,可以直接得到覆盖概念的R-MUPS.
不可满足概念的概念描述的复杂度和概念之间的覆盖关系,影响R-MUPS算法实现调试的效率.
概念的可满足性由Tableau算法判定,其计算复杂度为PSPACE-完全的[32],Schlobach计算概念MUPS的复杂度也是PSPACE-完全的[17],本文计算R-MUPS并不增加其计算复杂度.
空间方面,函数R-Mups-ComputeFunction计算概念的R-MUPS过程中采用深度优先遍历,即:在内存中每次仅保留一个分支,而且计算R-MUPS的同时也得到了概念的覆盖概念集.在计算R-MUPS时缓存概念所覆盖的概念,并且对可满足概念也保存其相关的可满足概念,实现快速计算MIPS.
4 实验评测本文实验是在PC机Windows XP操作系统(Intel(R) Core(TM)2 Duo CPU E7500 2.93GHz,2.00GB的内存)下运行.在测试数据方面,首先利用公理数和公理长度自动生成不同规模本体,评价调试算法对不同数据强度的处理性能,然后利用现有开源本体及其扩建本体,评价调试算法对现实本体数据的处理性能.在进行比较的调试方法选取方面,我们选择Schlobach的MUPS方法进行比较.在所有本体调试策略中,该方法是与本文工作调试定位角度一致的,都是通过寻找不可满足概念间接实现极小不可满足术语集的判定.相对其他调试方法,如利用最大可满足术语集策略、利用术语集的扩展收缩策略、利用逻辑语言转换等方案,虽然都能从不同角度定位本体逻辑冲突,但无法为用户提供不可满足概念最小保持子集做调试参考.因此,在同一数据和测试平台下比较MUPS算法和R-MUPS算法具有现实意义.同时,我们还针对R-MUPS调试方法中是否引入概念覆盖进行了对比测试,即,比较计算所有不可满足概念的R-MUPS与计算部分不可满足概念的R-MUPS,其中,计算部分不可满足概念的R-MUPS是利用概念间的覆盖关系,不对被已经计算过R-MUPS的概念覆盖的概念再计算.通过实验对比,说明在R-MUPS调试方法中引入概念覆盖关系的意义.
4.1 自动生成的本体测试集自动生成不同规模的非循环ALC本体,需要设定以下几个参数:本体规模ConceptAmount(TBox的公理总数,每个公理描述TBox中唯一的原子概念)、最大公理长度maxAxiomLength(公理右边部分中⊓和⊔构造符数量的最大值)、基本原子概念和角色.按照分层思想生成不同规模的非循环ALC本体,包含所有ALC构造符及其构造的复合概念形式,同时,在一定程度上控制概念扩展的最大深度.首先,非循环ALC本体保证算法的可判定性;其次,随机选择概念描述构造符保证算法的完备性;最后,本体中概念间覆盖关系的复杂度的不确定性,保证测试本体并不有利于本文算法.
自动生成本体方法:构建TBox T,初始时T由基本原子概念和角色构成.逐个向T增加新概念及其公理,直到设定的本体规模值(ConceptAmount).完成新概念C及其公理的构造后,确定被C包含的概念数Sonc(子概念数),并将$\langle $Cx,Sonc$\rangle $插入到队列中,队列实现宽度优先生成新概念.采用队列的数据结构按照分层的方式完成新概念公理的构造,取队列头部元素$\langle $Cf,Ns$\rangle $,接着构造概念Cf的Ns个子概念Cs及其公理.构造公理之前,首先确定公理长度,然后选择公理的构造符为⊓或者⊔,按照已经确定的构造符得到复合概念complex,即,Cs⊑Cf⊓complex.根据构造符构造complex:(1) 构造符为⊓,则complex,C$ \to $D|$\neg $D|$\exists $R.D|$\exists $R.$\neg $D|$\forall $R.D|$\forall $R.$\neg $D|complex⊓C;(2) 构造符为⊔,则complex,C$ \to $D|$\neg $D|$\exists $R.D|$\exists $R.$\neg $D|$\forall $R.D|$\forall $R.$\neg $D|complex⊔C.其中,D为已经存在的且不超过Cf层概念或基本原子概念.
图 6和图 7给出最大公理长度为5、本体规模分别为3 000和5 000的参数设置下随机生成20个本体的调试时间,横坐标表示随机生成的本体,由本体的不可满足概念数和MIPS数标记,以不可满足概念数递增的顺序排列;纵坐标表示本体调试时间.总体上看:图 6规模相同的本体,本体调试时间随着本体中不可满足概念数的增加而增加,当本体中不可满足概念数相近时,调试时间随着本体MIPS数的增加而增加;图 7扩大本体规模,生成本体的不可满足概念数增加,相应的两种方法实现本体调试时间均会提高,不可满足概念数相近时,本体的MIPS越多,本体调试时间越长.用公式(Tm-Tr)/Tm计算R-MUPS方法较Schlobach方法的提高效率,累加各组数据的提高效率,取平均值作为图中给定参数下R-MUPS方法较Schlobach方法的提高效率的平均值,其中,Tm和Tr分别是R-MUPS方法和Schlobach方法的调试时间.

|
Fig.6 Texting automatically generated ontologies 1(different in scales) 图 6 自动生成本体测试1(不同规模) |

|
Fig.7 自动生成本体测试2(不同规模) 图 7 Texting automatically generated ontologies 2(different in scales) |
图 6中,计算所有不可满足概念R-MUPS方法提高效率的最大值为45%(第17组数据),平均值为20%(计算20组数据提高效率的平均值);计算部分不可满足概念的R-MUPS方法提高效率的最大值为49%(第17组数据),平均值为26%.图 7中,计算所有不可满足概念R-MUPS方法提高效率的最大值为20%(第16组数据),平均值为14%;计算部分不可满足概念的R-MUPS方法提高效率的最大值为26%(第5组数据),平均值为20%.
图 8和图 9给出本体规模为1 000、最大公理长度分别为5和10的参数设置下,随机生成20个本体的调试时间.图 8和图 9满足前边说明的本体中不可满足概念数和MIPS数影响本体调试时间.对图 9中R-MUPS算法调试时间高于MUPS调试时间的本体进行分析,都具有共同的特点是,本体中概念描述简单和概念间的覆盖关系较少.最大公理长度间接地限制本体中概念描述的复杂度,而概念描述的复杂程度隐含概念之间的覆盖关系;如果生成的本体的MIPS数小于不可满足概念数,说明存在概念之间的覆盖关系,本体不可满足概念数与MIPS数的差值越大,本体中概念的覆盖关系可能越复杂.图 9中:计算所有不可满足概念R-MUPS方法提高效率的最小值为-36%(图 9的第7组数据),平均值为19%;计算部分不可满足概念的R-MUPS方法提高效率的最小值为-26%(图 9的第7组数据),平均值为23%.

|
Fig.8 Texting automatically generated ontologies 3(same in the scale) 图 8 自动生成本体测试3(相同规模) |

|
Fig.9 Texting automatically generated ontologies 4(same in the scale) 图 9 自动生成本体测试4(相同规模) |
综合自动生成本体测试集的实验结果,相较于增加本体规模,增加概念描述的复杂度消耗更多的本体调试时间.当本体概念描述复杂或不可满足概念之间的覆盖关系较多时,R-MUPS算法相较于MUPS算法更为高效,效率平均提高20%.
4.2 现有本体及其扩建本体现有本体DICE-A[15],Mad-Cow,MGED(http://www.mindswap.org/ontlogies/debugging),OBI,hec-onto-drugs, openGalen(http://www.ontoware.org).openGalen是开源型医学术语集,目前可用的开源资源包括一个复杂的本体开发环境和一个大型的描述逻辑本体用于医疗领域;DICE-A是医学本体DICE中的解剖片段,包含有关解剖、病因和形态的概念(例如Brain⊑CentralNervousSystem,Brain⊑BodyPart,CentralNervousSystem⊑Nervous System,BodyPart⊑ØNervousSystem);生物医学本体OBI包括研究设计、协议、使用的仪器、所产生的数据和对数据进行分析的类型,从功能基因组学研究本体,将包含功能基因组学研究和那些特定领域方面的术语;MGED本体描述在微阵列实验所用的样品,主要目的是为微阵列实验的注解提供标准的条款,这些条款将使实验要素能够结构查询(例如);Mad-Cow和hec-onto-drugs是规模较小的本体(见表 1).
| Table 1 Testing real ontologies 表 1 现实本体测试 |
先将本体修改为非循环ALC本体,例如删除原本体中的个体,将数据类型属性改成对象类型属性,同时修改相应的概念描述.如果概念C的描述中包含带有定义域Range或者值域Domain的属性R,即C⊑$\exists $R.$C'$,则为C增加C⊑Range或者全称概念描述C⊑$\forall $R.Domain.修改之后,不改变原本体概念的可满足性,保证C在原本体中是可满足的,那么在对应的修改之后的本体中也是可满足的;反之亦然.然后修改一致本体,例如增加一些新概念,其概念描述与本体中原有的一些概念矛盾,进而使得本体不一致.
扩建现实本体,设定3个参数:新增概念数newCpt、不可满足概念数UnCpt、新增MIPS数newMips.新增加的概念分为3种类型:(1) 可满足概念CS$ \to $$C'$|C1⊔C2,其中,$C'$是已经存在的可满足概念,C1和C2至少有一个是可满足的;(2) 不可满足概念CU$ \to $$D'$|D1⊔D2,其中,$D'$,D1和D2是已经存在的不可满足概念,这样,CU覆盖$D'$或者D1和D2;(3) 不可满足概念CM$ \to $E1⊓$\neg $E2,其中,E1覆盖E2.扩建newMips个CM,UnCpt-newMips个CU,newCpt- UnCpt-newMips个CS.
图 10给出扩建不同规模DICE-A本体的平均调试时间,图 11是扩建新增规模为1 000、MIPS数为50,不同不可满足概念数的DICE-A本体的平均调试时间.各图中,每个数据点是由给定参数下随机生成的10个本体的平均值(其中,每个本体同样运行10次,获取调试时间的平均值),也就是说,图中每个数据点经过100次取样获得.

|
Fig.10 Debugging time of ontologies different in scales 图 10 不同扩建规模本体调试时间 |

|
Fig.11 Debugging time of ontologies different in numbers of unsatisfiable concepts 图 11 不同不可满足概念数本体调试时间 |
图 10显示:本体MIPS数和不可满足概念数不变,本体调试时间随本体规模扩大而增加,接近线性增长;同时,R-MUPS算法相较于MUPS方法,调试效率也按照1%的增长率提高.其中,计算所有不可满足概念的R-MUPS效率提高的最小值为20%(图 10中第6组数据),计算部分不可满足概念的R-MUPS效率提高的最小值为34%(图 10中第9组数据).图 11显示:本体规模和本体MIPS不变,增加不可满足概念,实际上是间接地增加概念描述的复杂度或者不可满足概念之间的覆盖关系,比增加本体规模消耗更长的调试时间;同时, R-MUPS算法相较于MUPS方法,计算所有不可满足概念的R-MUPS效率提高的最小值为21%(图 11中第1组数据),计算部分不可满足概念的R-MUPS效率提高的最小值为36%(图 11中第1组数据).相对地,增加本体规模或者概念描述复杂程度,本文算法都能较快地完成调试,尤其是处理复杂的大规模本体.
5 总 结本文通过定义不可满足概念的R-MUPS这一概念,直接建立不可满足概念与不一致本体MIPS之间的联系.从本体的不可满足概念出发,通过寻找所有不可满足概念的R-MUPS来定位本体不一致冲突.文中所提出的基于有序标签演算的R-MUPS算法较好地实现了这一想法,并进一步证明了该算法的正确性.同时,对算法的复杂度和影响求解效率成因进行了分析.在实验评测环节,采用自动生成本体测试集、现实本体及其扩建本体对R-MUPS算法进行实验测试,测试结果表明了利用不可满足概念的R-MUPS求解本体调试问题的有效性.关于R-MUPS的概念覆盖关系的本体调试可以极大地减少求解MIPS的计算量,加速求解效率.另外,基于R-MUPS的本体调试方法特别适于处理概念描述的复杂程度高的不一致本体.概念描述越复杂,R-MUPS算法的调试过程越快,算法执行时间越短,效率平均提高20%.
下一步,我们考虑如何将启发式技术、模块化技术等优化技术移植到本文的基于R-MUPS本体调试方法下,这些优化技术已经在文献[22, 28]中很好地兼容到Schlobach的基于Tableau调试方法中.我们相信,通过适当补充和调整,也能够优化本文所提出的调试方法.
| [1] | Noy NF, Klein M. Ontology evolution: Not the same as schema evolution. Knowledge and Information Systems, 2004,6(4): 428-440 . |
| [2] | Gruber TR. A translation approach to portable ontology specifications. Knowledge Acquisition, 1993,5(2):199-220 . |
| [3] | 王驹,蒋运承,申宇铭.描述逻辑系统vL循环术语集的可满足性及推理机制.中国科学(F辑),2009,39(2):205-211. |
| [4] | Ye YX, Ouyang DT. Semantic-Based focused crawling approach. Ruan Jian Xue Bao/ Journal of Software, 2011,22(9):2075-2088 (in Chinese with English abstract). |
| [5] | Ouyang DT, Cui XJ, Ye YX. Mapping integrity constraint ontology to relational databases. Journal of China Universities of Posts and Telecommunications, 2010,17(6):113-121 . |
| [6] | Lam SC, Pan JZ, Sleeman D, Vasconcelos W. A fine-grained approach to resolving unsatisfiable ontologies. In: Proc. of the 2006 IEEE/WIC/ACM Int’l Conf. on Web Intelligence (WI 2006). 2006.428-434 . |
| [7] | Flouris G, Manakanatas D, Kondylakis H, Plexousakis D, Antoniou G. Ontology change: Classification and survey. Knowledge Engineering Review, 2008,23(2):117-152 . |
| [8] | Flouris G, Huang ZS, Pan JZ, Plexousakis D, Wache H. Inconsistencies, negations and changes in ontologies. In: Proc. of the 21st National Conf. on Artificial Intelligence (AAAI 2006). 2006. 1295-1300. |
| [9] | Qi GL, Pan JZ. A stratification-based approach for inconsistency handling in description logics. In: Proc. of the Int’l Workshop on Ontology Dynamics (IWOD 2007). 2007. 83-96. |
| [10] | Meyer T, Lee K, Booth R. Knowledge integration for description logics. In: Proc. of the 7th Int’l Symp. on Logical Formalizations of Commonsense Reasoning and Proc. of the 20th National Conf. on Artificial Intelligence (AAAI 2005).2005.645-650 . |
| [11] | Benferhat S, Kaci S, Le Berre D, Williams MA. Weakening conflicting information for iterated revision and knowledge integration. Artificial Intelligence, 2004,153:339-371 . |
| [12] | Haase P, van Harmelen F, Huang ZS, Stuckenschmidt H, Sure Y. A framework for handling inconsistency in changing ontologies. In: Proc. of the 4th Int’l Semantic Web Conf. (ISWC 2005). 2005.353-367 . |
| [13] | Ma Y, Qi GL, Hitzler P. Computing inconsistency measure based on paraconsistent semantics. Journal of Logic and Computation, 2011,21(6):1257-1281 . |
| [14] | Meyer T, Lee K, Booth R, Pan JZ. Finding maximally satisfiable terminologies for the description logic ALC. In: Proc. of the 21st National Conf. on Artificial Intelligence (AAAI 2006). 2006. 269-274. |
| [15] | Schlobach S, Cornet R. Non-Standard reasoning services for the debugging of description logic terminologies.In: Proc. of the Int’l Joint Conf. on Artificial Intelligence (IJCAI 2003). 2003. 355-360. |
| [16] | Schlobach S. Diagnosing terminologies. In: Proc. of the 20th National Conf. on Artificial Intelligence (AAAI 2005). 2005. 670-675. |
| [17] | Schlobach S, Huang ZS, Cornet R, van Harmelen F. Debugging incoherent terminologies. Journal of Automated Reasoning, 2007, 39(3):317-349 . |
| [18] | Plessers P, De Troyer O. Resolving inconsistencies in evolving ontologies. In: Proc. of the 3rd European Semantic Web Conf. (ESWC 2006). 2006.200-214 . |
| [19] | Kalyanpur A, Parsia B, Sirin E, Hendler J. Debugging unsatisfiable concepts in OWL Ontologies. Journal of Web Semantics, 2005, 3(4):268-293 . |
| [20] | Kalyanpur A, Parsia B, Sirin E, Cuenca-Grau B. Repairing unsatisfiable concepts in OWL ontologies. Lecture Notes in Computer Science, 2006,4011:170-184 . |
| [21] | Kalyanpur A, Parsia B, Horridge M, Sirin E. Finding all justifications of OWL DL entailments. Lecture Notes in Computer Science, 2007,4825:267-280 . |
| [22] | Wang H, Horridge M, Rector A, Drummond N, Seidenberg J. Debugging OWL-DL ontologies: A heuristic approach. In: Proc. of the 4th Int’l Semantic Web Conf. (ISWC 2005). Springer-Verlag, 2005.745-757 . |
| [23] | Friedrich G, Shchekotykhin K. A general diagnosis method for ontologies. In: Proc. of the 4th Int’l Conf. on the Semantic Web. 2005.232-246 . |
| [24] | Reiter R. A theory of diagnosis from first principles. Artificial Intelligence, 1987,32(1):57-95 . |
| [25] | Greiner R, Smith BA, Wilkerson RW. A correction to the algorithm in reiters theory of diagnosis. Artificial Intelligence, 1989, 41(1):79-88. |
| [26] | Shchekotykhin K, Friedrich G, Philipp F, Rodler P. Interactive ontology debugging: Two query strategies for efficient fault localization. Journal of Web Semantics, 2012,12(13):88-103 . |
| [27] | Shchekotykhin K, Friedrich G. Query strategy for sequential ontology debugging. In: Proc. of the 9th Int’l Semantic Web Conf. (ISWC 2010). 2010.696-712 . |
| [28] | Suntisrivaraporn B, Qi GL, Ji Q, Haase P. A modularization-based approach to finding all justifications for OWL DL entailments. In: Proc. of the 3rd Asian Semantic Web Conf. (ASWC 2008). Springer-Verlag, 2008.1-15 . |
| [29] | Du JF, Qi GL, Ji Q. Goal-Directed module extraction for explaining OWL DL entailments. In: Proc. of the 8th Int’l Semantic Web Conf. (ISWC 2009). Springer-Verlag, 2009.163-179 . |
| [30] | Zhou LP, Huang HK, Qi GL, Qu YL. An algorithm for calculating minimal unsatisfiability-Preserving subsets of ontology in DL-Lite. of Computer Research and Development, 2011,48(12):2334-2342 (in Chinese with English abstract). |
| [31] | Haase P, Qi GL. An analysis of approaches to resolving inconsistencies in DL-based ontologies. In: Proc. of the Int’l Workshop on Ontology Dynamics (IWOD 2007). 2007. 97-109. |
| [32] | Baader F, Calvanese D, McGuinness D, Nardiand D, Patel-Schncider PF. The Description Logic Handbook: Theory, Implementation and Application. 2nd ed., Cambridge University Press, 2007. |
| [4] | 叶育鑫,欧阳丹彤.基于语义的主题爬行策略.软件学报,2011,22(9):2075-2088. |
| [30] | 周丽平,黄厚宽,漆桂林,瞿有利.一种在DL-Lite中计算本体最小不可满足保持子集的算法.计算机研究与发展,2011,48(12): 2334-2342. |