 2015, Vol. 26
2015, Vol. 26



2. 华北理工大学 信息工程学院, 河北 唐山 063009
2. College of Information Engineering, North China University of Science and Technology, Tangshan 063009, China
面对网络图像的爆炸性增长,网络图像标注成为近年来的一个研究热点.通常,图像被表示为各种不同类型的特征,因此,特征选择成为提高网络图像标注性能的一个重要手段.最近,稀疏特征选择以其较好的特征选择性能和较低的计算复杂度被广泛用于网络图像标注[1, 2, 3, 4]中.稀疏特征选择就是采用各种稀疏模型来实现特征选择和数据的稀疏表示.
最著名的稀疏模型是l1范数模型(lasso)[5],蔡等人[6]采用l1正则化回归模型进行特征选择.尽管l1范数计算方便,但是所选取的特征稀疏性不强,因此,l1范数模型被扩展到了lp(0<p<1)范数模型,lp范数模型比l1范数模型具有更好的稀疏性.最近,徐等人[7,8]指出:当p=1/2时,lp范数模型,也即l1/2范数模型具有最好的稀疏性.赵等人[9]将l1/2范数模型用于逻辑回归的处理上.然而,上述模型都是对特征进行逐一的选取,忽略了特征之间的关联信息.聂等人[10]提出l2,1范数模型进行特征选择,从所有的数据点中联合地选取特征;马等人[4]将l2,1范数应用到了图像标注.但是l2,1范数模型是基于l1范数模型的,因此所选取的特征还不够稀疏.
通常,一幅图像包含几个语义概念,因此图像标注实质上是一个多标签分类问题.Ando等人[11]提出不同的标签之间存在共享子空间,该共享子空间可以利用标签关联提升多标签分类的性能.杨等人[12]将共享子空间学习应用到多标签图像标注.同理,不同特征之间的关联信息也可以通过共享子空间学习来获得.马等人[13]将共享子空间学习应用到了稀疏特征选择,进而提升了网络图像标注的性能.
监督学习方法中,人工标注训练数据既费时又费力,因此不适合大规模网络图像标注.无标签训练数据易于获取,同时能够促进标注性能的提高.为了减少标注训练数据的人力投入成本,同时充分利用未标签训练数据,许多半监督学习方法被广泛应用到网络图像标注[12, 14, 15]中.在半监督学习方法中,最常用的是基于图拉普拉斯半监督学习.由于简单方便,KNN图拉普拉斯半监督学习被广泛采用.马等人[4]提出了一种半监督特征选择方法进行图像标注;杨等人[12]将共享结构学习与基于图的半监督学习相结合进行网络图像的标注;唐等人[14]提出基于KNN稀疏图的半监督学习方法进行有噪声标签网络图像标注.
由于l1/2范数模型比l1范数模型选取的特征更为稀疏有效[7, 8],我们将l2,1范数扩展到l2,1/2矩阵范数,利用该模型进行更加有效的稀疏特征选择.考虑到不同特征之间的关联信息,在特征选择过程中加入共享子空间学习来提升特征选择的效果.面对大量的网络图像以及无标签训练图像,半监督特征选择方法更加有效.因此,本文结合以上3点内容,提出一种增强稀疏性特征选择方法进行网络图像标注,即,基于l2,1/2矩阵范数和共享子空间的半监督稀疏特征选择算法(semi-supervisedsparse feature selection based on l2,1/2-matix norm withshared subspace learning,简称SFSLS).该算法在两个大规模网络图像数据库NUS-WIDE[16]和MSRA-MM 2.0[17]上进行了实验,结果表明:SFSLS算法优于现有的其他稀疏特征选择算法,适合大规模网络图像标注.
1 相关工作本节介绍与本文相关的3个主要工作,即:稀疏特征选择、共享子空间学习和图拉普拉斯半监督学习.
1.1 稀疏特征选择稀疏特征选择就是采用各种不同的稀疏模型来选取最具判别性的特征,从而得到数据的稀疏表示.稀疏特征选择不仅可以提升网络图像标注性能,同时还可以降低计算的复杂度.
最著名的稀疏模型是l1范数,该模型是凸问题,易于求解,但是所选取的特征不够稀疏.最近,徐等人指出,l1/2范数模型比l1范数具有更好的稀疏性[7, 8].然而,l1/2范数模型和l1范数模型在稀疏特征选择过程中忽略了特征之间的关联信息.聂等人[10]提出l2,1范数,该模型从所有数据点中进行特征选择;王等人[18]将l2,1范数扩展为l2,p范数(0<p≤1).
设G∈Rdxc为稀疏特征选择映射矩阵,其l2,p矩阵范数定义为
| $||G|{|_{2,p}} = {\left( {\sum\limits_{i = 1}^d {||{g^i}||_2^p} } \right)^{1/p}},p \in (0,1]$ | (1) |
很显然,当p=1时,l2,p矩阵范数即为l2,1矩阵范数.注意:l2,p矩阵范数是伪范数,不满足三角不等式.另外,l2,p矩阵范数是非凸的,不能直接采用文献[10]中的方法进行求解.
当p=1/2时,l2,p矩阵范数即为l2,1/2矩阵范数$||G||_{2,1/2}^{1/2}.$本文将l2,1/2矩阵范数应用到SFSLS算法中.
1.2 共享子空间学习在多标签学习问题中,Ando等人[11]提出:在原始的特征空间中存在一个共享子空间,该共享子空间与原始特征空间可以同时对图像语义概念进行预测.
给定特征向量x∈Rd和预测函数f,则共享特征子空间学习可以定义为下式:
| f(x)=vTx+pTUTx | (2) |
上式中,v∈Rd和p∈Rr是权重向量,U∈Rdxr是所有特征的共享子空间.
为了获得预测函数f,目标函数可写为
| $\mathop {\min }\limits_f \sum\limits_{i = 1}^n {loss(f({x_i}),{y_i}) + \gamma R(f)} $ | (3) |
上式中,loss()是误差函数,γR(f)是正则项.
假设多标签学习中的图像包含c个概念,第t个概念包含ht个训练数据$\{ {x_i}\} _{i = 1}^{{h_t}}$,对应的标签为$\{ {y_i}\} _{i = 1}^{{h_t}}$.将公式(2)带入公式(3),则此时的目标函数为
| $\begin{gathered} \mathop {\min }\limits_{\{ {v_t},{p_t}\} ,U} \sum\limits_{t = 1}^c {\left( {\frac{1}{{{h_t}}}\sum\limits_{i = 1}^{{h_t}} {loss({{({v_t} + U{p_t})}^T}{x_i},{y_i}) + \gamma R(\{ {v_t},{p_t}\} )} } \right)} \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} $ | (4) |
公式(4)中,UTU=I为限定项,便于问题的求解.
由于共享子空间学习在多标签数据中的有效性,本文将共享子空间学习应用到特征选择框架SFSLS中.
1.3 图拉普拉斯半监督学习半监督学习可以同时利用有标签数据和无标签数据,因此非常适合仅有很少有标签数据的网络图像标注.一方面,半监督学习可以节省标注大量图像的人力,同时可以利用无标签数据来提升网络图像标注的性能.基于图拉普拉斯半监督学习得到了广泛研究,其中,KNN图及相关方法被广泛用于网络图像标注[4, 12, 14]中.
设X=[x1,x2,…,xm,xm+1,…,xn]T为训练图像的特征矩阵,共有n个训练数据,其中包含m个有标签数据,xi∈Rd(1≤i≤n)表示第i个图像的特征向量.设Y=[y1,y2,…,ym,ym+1,…,yn]T为训练图像的标签矩阵,c表示类别数,yi∈Rc(1≤i≤n)表示第i个标签向量.设Yij表示yi的第j个数据,如果xi是第j类,则Yij=1;否则,Yij=0.如果xi是无标签数据,即i>m,则yi为全0向量.
定义图模型S,其元素Sij表示xi与xj之间的相似性:
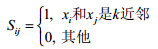
|
(5) |
设${D_{ii}} = \sum\limits_{j = 1}^n {{S_{ij}}} $为对角矩阵,则图拉普拉斯矩阵可以表示为L=D-S.
朱等人[19, 20]提出了同时利用有标签图像和无标签图像的半监督直推式分类算法.设所有训练数据的标签预测矩阵为F=[f1,f2,…,fn]T∈Rnxc,其中,fi∈Rc(1≤i≤n)为xi的预测标签.聂等人[21]指出:F应该与训练数据的真实标签保持一致,同时,在图模型上具有光滑性.因此,可以通过最小化下面的目标函数来获得预测标签矩阵F.
| $\mathop {\arg \min }\limits_F Tr({F^T}LF) + Tr({(F - Y)^T}Q(F - Y))$ | (6) |
上式中,对角矩阵Q∈Rnxn为决策规则矩阵.如果xi为有标签数据,则Q的对角元素Qii=¥;否则,其对角元素Qii=1.决策规则矩阵Q使预测标签矩阵F与训练数据的真实标签矩阵Y保持一致.
基于图的直推式算法被广泛应用于多媒体领域[22-24].与以前的半监督学习算法不同[25, 26],这里,我们根据标签预测矩阵来最小化预测误差,并将其应用到本文提出的SFSLS模型中.
2 基于l2,1/2矩阵范数和共享子空间的半监督稀疏特征选择算法本节中,我们提出一种增强稀疏性特征选择算法,即,基于l2,1/2矩阵范数和共享子空间的半监督稀疏特征选择算法,简称SFSLS.首先提出该算法,然后给出了算法的求解过程及算法的收敛性分析.
2.1 算法提出算法的基本思路:将l2,1/2矩阵范数、共享子空间学习和基于图拉普拉斯半监督学习相结合,得到稀疏特征选择模型SFSLS.
给定X=[x1,x2,…,xm,xm+1,…,xn]T为训练图像的特征矩阵,m表示有标签数据的数目,n为所有训练数据数目,xi∈Rd(1≤i≤n)表示第i个图像的特征向量.设Y=[y1,y2,…,ym,ym+1,…,yn]T为训练图像的标签矩阵,c表示类别数,yi∈Rc(1≤i≤n)表示第i个图像的标签向量.设Yij表示yi的第j个数据,如果xi是第j类,则Yij=1;否则,Yij=0.如果xi是无标签数据,即i>m,则yi为全0向量.
定义V=[v1,v2,…,vc]∈Rdxc,P=[p1,p2,…,pc]∈Rrxc和U∈Rdxr,这里,r表示共享子空间的维度.
定义映射矩阵为G=V+UP,其中,G∈Rdxc,则公式(4)可以写为
| $\begin{gathered} \mathop {\min }\limits_{V,P,U} loss({G^T}X,Y) + \gamma R(V,P) \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} $ | (7) |
将l2,1/2矩阵范数$||G||_{2,1/2}^{1/2}$、共享特征子空间学习(7)和基于图拉普拉斯半监督学习(6)相结合,同时采用最小均方误差函数作为损失函数,则得到稀疏特征选择模型SFSLS的目标函数为
| $\begin{gathered} \mathop {\arg \min }\limits_{F,G,U,P} tr{F^T}LF + tr{(F - Y)^T}Q(F - Y) + \alpha [||{X^T}G - F||_F^2 + \lambda ||G||_{2,1/2}^{1/2} + \mu ||G - UP||_F^2] \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} $ | (8) |
上式中,$\lambda ||G||_{2,1/2}^{1/2} + \mu ||G - UP||_F^2$为正则项,其中,$||G||_{2,1/2}^{1/2}$保证SFSLS模型选取的特征更加稀疏,更具判别性;$||G - UP||_F^2$共享子空间保证SFSLS模型在特征选择过程中充分考虑了不同特征之间的相关性.
值得注意的是,本文提出的算法与文献[12]的算法和文献[4]的算法不同.文献[12]中,算法不包含稀疏特征选择,我们提出的算法采用l2,1/2矩阵范数稀疏模型进行稀疏特征选择.文献[4]中介绍的算法虽然包含稀疏选择过程,但是采用的稀疏模型为l2,1矩阵范数,稀疏性较差,同时没有充分考虑不同特征之间的相关性.由于l2,1/2矩阵范数是非凸的,因此不能直接采用文献[12]和文献[4]中的方法来求解.下面我们提出了一种有效的迭代方法来求解SFSLS的目标函数.
2.2 优化求解由于目标函数(8)中包含l2,1/2矩阵范数,因此该目标函数是非凸的,我们采用如下方法来求解公式(8).
给定G=[g1,…,gd]T,设D为对角矩阵,其对角元素为${D_{ii}} = \frac{1}{4}||{g^i}||_2^{3/2},$则:
| $||G||_{2,p}^p = \frac{2}{p}Tr({G^T}DG),||G||_{2,1/2}^{1/2} = 4Tr({G^T}DG).$ |
对于任意矩阵A,有:$||A||_F^2 = Tr({A^T}A).$
将目标函数(8)中的矩阵范数转换为迹操作,则目标函数等价于:
| $\left. \begin{gathered} \mathop {\arg \min }\limits_{F,G,U,P} Tr({F^T}LF) + Tr({(F - Y)^T}Q(F - Y)) + \hfill \\ {\text{ }}\alpha [Tr({({X^T}G - F)^T}({X^T}G - F)) + 4\lambda Tr({G^T}DG) + \mu Tr({(G - UP)^T}(G - UP))] \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}$ | (9) |
对公式(9)中的参数P求导,并令等式为0,则有:
| (UTUP-UTG)=0?P=UTG | (10) |
将公式(10)中的P带入到公式(9),则目标函数为
| $\left. \begin{gathered} \mathop {\arg \min }\limits_{F,G,U} Tr({F^T}LF) + Tr({(F - Y)^T}Q(F - Y)) + \hfill \\ {\text{ }}\alpha [Tr({({X^T}G - F)^T}({X^T}G - F)) + 4\lambda Tr({G^T}DG) + \mu Tr({(G - U{U^T}G)^T}(G - U{U^T}G))] \Rightarrow \hfill \\ \mathop {\arg \min }\limits_{F,G,U} Tr({F^T}LF) + Tr({(F - Y)^T}Q(F - Y)) + \hfill \\ {\text{ }}\alpha [Tr({({X^T}G - F)^T}({X^T}G - F)) + 4\lambda Tr({G^T}DG) + \mu Tr({G^T}{(I - U{U^T})^T}(I - U{U^T})G)] \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}$ | (11) |
因为(I-UUT)(I-UUT)=(I-UUT),所以公式(11)可以写为
| $\left. \begin{gathered} \mathop {\arg \min }\limits_{F,G,U} Tr({F^T}LF) + Tr({(F - Y)^T}Q(F - Y)) + \alpha [Tr({({X^T}G - F)^T}({X^T}G - F)) + Tr({G^T}(4\lambda D + \mu I - \mu U{U^T})G)] \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}$ | (12) |
对公式(12)中的参数G求导,并令等式为0,则有:
| $2X{X^T}G - 2XF + 2(4\lambda D + \mu I - \mu U{U^T})G = 0 \Rightarrow (X{X^T} + 4\lambda D + \mu I - \mu U{U^T})G =\\ XF \Rightarrow G ={(A - \mu U{U^T})^{ - 1}}XF \Rightarrow G = {B^{ - 1}}XF$ | (13) |
上式中,$A = X{X^T} + 4\lambda D + \mu I,B = A - \mu U{U^T},B = {B^T}$.
因此,公式(12)可重写为
| $\left. \begin{gathered} \mathop {\arg \min }\limits_{F,G,U} Tr({F^T}LF) + Tr({(F - Y)^T}Q(F - Y)) + \alpha [Tr({G^T}BG) - 2Tr({G^T}XF) + Tr({F^T}F)] \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}$ | (14) |
将公式(13)中的G带入到公式(14),则有:
| $\left. \begin{gathered} \mathop {\arg \min }\limits_{F,U} Tr({F^T}LF) + Tr({(F - Y)^T}Q(F - Y)) + \alpha [Tr({F^T}F) - Tr({F^T}{X^T}{B^{ - 1}}XF)] \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}$ | (15) |
对公式(15)中的F求导,并令等式为0,则得到:
| $LF + QF - QY + \alpha [F - {X^T}{B^{ - 1}}XF] = 0 \Rightarrow F = {(L + Q + \alpha I - \alpha {X^T}{B^{ - 1}}X)^{ - 1}}QY = {(R - \alpha {X^T}{B^{ - 1}}X)^{ - 1}}QY$ | (16) |
此时,目标函数可以转化为
| $\left. \begin{gathered} \mathop {\arg \max }\limits_U Tr({Y^T}Q{(R - \alpha {X^T}{B^{ - 1}}X)^{ - 1}}QY) \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}$ | (17) |
根据Sherman-Woodbury-Morrison定理[27],有:
| ${(R - \alpha {X^T}{B^ - }^1X)^ - }^1 = {R^ - }^1 + \alpha {R^ - }^1{X^T}{(B - \alpha X{R^ - }^1{X^T})^ - }^1X{R^ - }^1.$ |
因此,公式(17)转化为
| $\left. \begin{gathered} \mathop {\arg \max }\limits_U Tr({Y^T}Q{R^{ - 1}}{X^T}{(B - \alpha X{R^{ - 1}}{X^T})^{ - 1}}X{R^{ - 1}}QY) = \mathop {\arg \max }\limits_U Tr({Y^T}Q{R^{ - 1}}{X^T}{J^{ - 1}}X{R^{ - 1}}QY) \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}$ | (18) |
上式中,J=B-αXR-1XT.
| J -1=(B-αXR-1XT)-1=(A-μUUT-αXR-1XT)-1=(C-μUUT)-1 | (19) |
再次利用Sherman-Woodbury-Morrison定理,则有:
| (C-μUUT)-1=C-1+μC-1U(I-μUTC-1U)-1UTC-1=C-1+μC-1U(UT(I-μC-1)U)-1UTC-1 | (20) |
很显然,C与U相互独立.因此,我们可以将目标函数(18)重写为
| $\left. \begin{gathered} \mathop {\arg \max }\limits_U Tr({Y^T}Q{R^{ - 1}}{X^T}{C^{ - 1}}U{({U^T}(I - \mu {C^{ - 1}})U)^{ - 1}}{U^T}{C^{ - 1}}X{R^{ - 1}}QY) = \hfill \\ \mathop {\arg \max }\limits_U Tr({Y^T}Q{R^{ - 1}}{X^T}{C^{ - 1}}U{({U^T}KU)^{ - 1}}{U^T}{C^{ - 1}}X{R^{ - 1}}QY) \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}$ | (21) |
对于任意矩阵X,Y和Z,有Tr(XYZ)=Tr(YZX),公式(21)转化为
| $\left. \begin{gathered} \mathop {\arg \max }\limits_U Tr({({U^T}KU)^{ - 1}}{U^T}{C^{ - 1}}X{R^{ - 1}}QY{Y^T}Q{R^{ - 1}}{X^T}{C^{ - 1}}U) \Rightarrow \mathop {\arg \max }\limits_U Tr{({U^T}KU)^{ - 1}}{U^T}HU \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}$ | (22) |
上式中,K=I-μC-1,H=C-1XR-1QYYTQR-1XTC-1.
公式(22)可以转化为K-1H的特征分解问题,然而,U和G却不能直接从公式(22)求取.因此,在下面所示的算法1中提出了一种迭代算法来求取目标函数(22),流程如下.
算法1.
1.输入训练图像特征矩阵X∈Rdxn,对应的标签矩阵为Y∈Rnxc,正则化参数α,λ和μ,图拉普拉斯中的最近邻数k;
2.计算图拉普拉斯矩阵L∈Rnxn;
3.计算决策规则矩阵Q∈Rnxn;
4.计算R=L+Q+aI;
5.设t=0,初始化映射矩阵为随机矩阵G0∈Rdxc;
6.重复:
计算对角矩阵% MathType!MTEF!2!1!+- ${D_t}:{D_t} = \left[ {\begin{array}{*{20}{c}} {\frac{1}{{4||g_t^1||_2^{3/2}}}} {} {} \\ {} {...} {} \\ {} {} {\frac{1}{{4||g_t^d||_2^{3/2}}}} \end{array}} \right]$;
计算At=XXT+4λDt+μI;
计算Ct=At-αXR-1XT;
计算${K_t} = I - \mu C_t^{ - 1};$
计算${H_t} = C_t^{ - 1}X{R^{ - 1}}QY{Y^T}Q{R^{ - 1}}{X^T}C_t^{ - 1};$
对$K_t^{ - 1}{H_t}$进行特征分解;
计算${B_t} = {A_t} - \mu {U_t}U_t^T;$
计算${F_t} = {(R - \alpha {X^T}B_t^{ - 1}X)^{ - 1}}QY;$
更新${G_{t + 1}} = B_t^{ - 1}X{F_t};$
t=t+1;
7.直到收敛,返回最优映射矩阵G.
算法1中的迭代过程可以通过定理1证明其收敛于最优映射矩阵G,为了证明定理1,需要引入引理1.关于引理1和定理1的证明可见附录.
3 实验分析本节将所提算法SFSLS在两个大规模图像数据库上进行了实验,验证了其进行大规模网络图像标注的有效性.
3.1 数据库及评价标准实验中使用两个网络图像数据库:NUS-WIDE[16]和MSRA-MM2.0[17].
NUS-WIDE数据库是由新加坡国立大学媒体研究实验室于2009年创立的,该数据库包括269 648幅图像、81个概念.实验中,我们选用3种类型特征,即:144维颜色相关图、128维小波纹理和73维边缘方向直方图.我们将这3种特征串接为345维特征来表示每一幅图像.
MSRA-MM2.0数据库是由微软亚洲研究中心于2009年创立的,该数据库包括50 000幅图像、100个概念.实验中,我们也选用144维颜色相关图、128维小波纹理和75维边缘方向直方图这3种类型特征,并将其串接为347维特征来表示每一幅图像.
实验中,评估准则采用在多媒体领域里被广泛应用的平均准确率均值(MAP),其值越大,表示性能越好.
3.2 实验结果与分析实验中随机采样3 000个图像形成训练数据集,剩余数据作为测试集.训练集中有标签数据数量为m,分别为训练数据的5%,10%,25%,50%和100%,实验中分别记录相应的标注结果.随机进行5次实验,将5次结果的平均作为最终的标注结果.
将本文提出的SFSLS算法与现有的一些稀疏特征选择算法进行比较,这些算法包括贝叶斯l1正则化稀疏多项式逻辑回归方法(SBMLR)[28]、联合l2,1范数最小化特征选择方法(FSNM)[10]、稀疏性结构化特征选择方法(SFSS)[4].实验中,方法SFSLS与SFSS可以同时实现特征选择与分类,而FSNM和SBMLR方法仅用于特征选择,因此特征选择后,通过最小均方回归模型进行分类.
3.2.1 性能评估本文所提算法SFSLS与其他算法进行网络图像标注的性能比较结果见表 1,在两个数据库上分别进行了实验,最好结果用粗体标识.
| Table 1 Performance comparison (MAP±standard deviation)表 1 性能比较(MAP±标准偏差) |
从表 1我们可以得出以下结论:
·首先,随着有标签数据量的增加,所有算法的性能都逐渐提高.例如,对于数据库NUS-WIDE上的SFSLS算法,当有标签数据占训练数据总量的10%时,MAP是0.084;而当比例增加到25%时,MAP提高到0.093;
·其次,表 1表明,本文算法SFSLS的性能优于其他算法.这说明SFSLS算法能够有效选取更具判别性的稀疏特征来提升图像标注性能.另外,也说明了该算法能够用较少的有标签训练数据的半监督学习方式进行大规模网络图像标注.
对于SFSLS算法能够取得较好的图像标注性能,主要包括3个原因.
(1)采用l2,1/2矩阵范数进行稀疏特征选择,使所选取的特征更加稀疏,更具判别性;
(2)算法中采用了共享子空间学习,充分利用了不同特征之间的关联信息;
(3)采用基于图拉普拉斯半监督学习,同时利用了有标签数据和无标签数据,无标签数据进一步提升了网络图像标注的性能.
3.2.2 参数p的影响本文提出的SFSLS算法是基于l2,1/2矩阵范数模型的,这里的l2,1/2矩阵范数是l2,p矩阵范数在p=1/2时的一个特例.本节专门设计实验来分析参数p取不同值时对标注性能的影响.由于p∈(0,1],我们选取典型的p值{0.1, 0.25,0.5,0.75,1}在两个数据库上分别进行了实验.表 2列出了采用不同p值时的标注结果,最好的结果用粗体字标识.
| Table 2 Performance comparison withdifferent parameter p (MAP)表 2 采用不同参数p的性能比较(MAP) |
实验中设定有标签数据量为训练数据总量的10%.从表 2我们得到以下结果:(1) 当p=1/2时,即本文算法SFSLS,具有最好的标注性能;(2) 当p属于(0,0.5)时,p越接近于0,标注性能越差,这说明所选择的特征过于稀疏,丢失了有用信息;(3) 当p接近于1时,近似为SFSS算法.总之,该实验结果表明:本文所提算法SFSLS(对应p=1/2)具有最好的稀疏选择特性,能够获得很好的标注性能.
3.2.3 无标签数据的影响文本算法SFSLS中采用基于图拉普拉斯半监督学习,同时利用了有标签数据与无标签数据.本节设计了一个实验,验证无标签数据对标注性能的影响.为此,实验中设定两种情况:一种情况是仅采用有标签训练数据来获得SFSLS模型;另一种情况是采用所有的训练数据包括有标签和无标签数据来获得SFSLS模型.实验比较了两种情况的标注结果,从而得出无标签数据对标注性能的影响.有标签训练数据大小分为5种情况,分别为训练数据总量的5%,10%,25%,50%和100%.另外,实验中还将本文方法SFSLS与方法SFSS进行了比较,分别在两个数据库上进行了实验,实验结果如图 1所示.

|
Fig.1 Influence of unlabeled dataon annotation results 图 1 无标签数据对标注性能的影响 |
图 1给出了无标签数据对标注性能的影响结果,其中,图 1(a)所示为数据库NUS-WIDE上的标注结果,图 1(b)所示为数据库MSRA-MM上的标注结果.图中相邻的4个条形从左到右依次表示仅仅采用有标签数据的SFSS方法的标注结果,同时采用有标签数据和无标签数据的SFSS方法的标注结果,仅仅采用有标签数据的SFSLS方法的标注结果,同时采用有标签数据和无标签数据的SFSLS方法的标注结果.
图 1表明:无论是本文所提算法SFSLS,还是算法SFSS,无标签数据的加入能够提升网络图像标注的性能,采用包括有标签和无标签所有训练数据的标注结果要优于仅采用有标签数据的标注结果.同时也显示出:SFSLS的性能优于算法SFSS,无论是仅采用有标签数据的情况,还是采用全部训练数据的情况.
4 结 论本文提出一个增强稀疏性特征选择模型SFSLS进行网络图像标注,该模型基于l2,1/2矩阵范数进行稀疏特征选择,使选取的特征更为稀疏,更具判别性.算法中引入共享子空间学习,考虑了不同特征之间的相关性.另外,采用基于图拉普拉斯半监督学习方法,同时利用有标签数据和无标签数据,一方面能够节省标注大规模训练数据的时间和人力,同时,易于获取的无标签数据可以提升网络图像标注的性能.SFSLS算法的目标函数是非凸的,我们设计了一种有效的迭代算法来求取其最优解,并证明了该算法的收敛性.在两个大的网络图像数据库上进行了实验,结果表明:本文算法SFSLS优于其他稀疏特征选择算法,更适合大规模网络图像的标注.
致谢 在此,我们向对本文的工作给予支持和建议的同行,尤其是北京交通大学信息科学研究所袁保宗教授、郭松、王占等同学表示感谢.
引理1. 设Gt是第t次迭代得到的映射矩阵,Gt+1是第t+1次迭代得到的映射矩阵.同时,设$g_t^i$和$g_{t + 1}^i$分别是Gt和Gt+1的第i行(i=1,2,…,d),则下面的不等式成立:
| $\sum\limits_{i = 1}^d {\left( {||g_{t + 1}^i||_2^{1/2} - \frac{1}{4}\frac{{||g_{t + 1}^i||_2^2}}{{||g_t^i||_2^{3/2}}}} \right)} \leqslant \sum\limits_{i = 1}^d {\left( {||g_t^i||_2^{1/2} - \frac{1}{4}\frac{{||g_t^i||_2^2}}{{||g_t^i||_2^{3/2}}}} \right)} .$ |
证明:对于表达式φ(t)=4t-t4-3,对于任意的t>0,都有φ(t)≤0.
令φ(t)中的$t = \frac{{||g_{t + 1}^i||_2^{1/2}}}{{||g_t^i||_2^{1/2}}},$则$\varphi \left( {\frac{{||g_{t + 1}^i||_2^{1/2}}}{{||g_t^i||_2^{1/2}}}} \right) \leqslant 0,$也即$4\frac{{||g_{t + 1}^i||_2^{1/2}}}{{||g_t^i||_2^{1/2}}} - \frac{{||g_{t + 1}^i||_2^2}}{{||g_t^i||_2^2}} - 3 \leqslant 0.$
在上面不等式两侧同时乘以$\frac{1}{4}||g_t^i||_2^{1/2},$则有:
| $||g_{t + 1}^i||_2^{1/2} - \frac{1}{4}\frac{{||g_{t + 1}^i||_2^2}}{{||g_t^i||_2^{3/2}}} \leqslant \left\| {g_t^i} \right\|_2^{1/2} - \frac{1}{4}\frac{{||g_t^i||_2^2}}{{||g_t^i||_2^{3/2}}},i = 1,...,d.$ |
上面不等式是针对于每一行i,将所有的行相加(1≤i≤d),则得到引理1的结论:
| $\sum\limits_{i = 1}^d {\left( {||g_{t + 1}^i||_2^{1/2} - \frac{1}{4}\frac{{||g_{t + 1}^i||_2^2}}{{||g_t^i||_2^{3/2}}}} \right)} \leqslant \sum\limits_{i = 1}^d {\left( {||g_t^i||_2^{1/2} - \frac{1}{4}\frac{{||g_t^i||_2^2}}{{||g_t^i||_2^{3/2}}}} \right)} .$ | □ |
定理1. 采用算法1中的迭代过程,使公式(22)中目标函数在每次迭代过程中是单调递减的,最终收敛于最优的映射矩阵G.
证明:根据算法1,由公式(22)可以推得:
| $\left. \begin{gathered} {G_{t + 1}} = \mathop {\arg \min }\limits_{F,G,U,P} Tr({F^T}LF) + Tr({(F - Y)^T}Q(F - Y)) + \hfill \\ {\text{ }}\alpha [Tr({({X^T}G - F)^T}({X^T}G - F)) + 4\lambda Tr({G^T}DG) + \mu Tr({(G - UP)^T}(G - UP))] \hfill \\ {\text{s}}{\text{.t}}{\text{. }}{U^T}U = I \hfill \\ \end{gathered} \right\}.$ |
因此:
| $\begin{gathered} Tr(F_{t + 1}^TL{F_{t + 1}}) + Tr({({F_{t + 1}} - Y)^T}Q({F_{t + 1}} - Y)) + \hfill \\ \alpha [Tr({({X^T}{G_{t + 1}} - {F_{t + 1}})^T}({X^T}{G_{t + 1}} - {F_{t + 1}})) + 4\lambda Tr(G_{t + 1}^T{D_t}{G_{t + 1}}) + \mu Tr({({G_{t + 1}} - {U_{t + 1}}{P_{t + 1}})^T}({G_{t + 1}} - {U_{t + 1}}{P_{t + 1}}))] \leqslant \hfill \\ Tr(F_t^TL{F_t}) + Tr({({F_t} - Y)^T}Q({F_t} - Y)) + \hfill \\ \alpha [Tr({({X^T}{G_t} - {F_t})^T}({X^T}{G_t} - {F_t})) + 4\lambda Tr(G_t^T{D_t}{G_t}) + \mu Tr({({G_t} - {U_t}{P_t})^T}({G_t} - {U_t}{P_t}))]. \hfill \\ \end{gathered} $ |
| $\because Tr(G_t^T{D_t}{G_t}) = \sum\limits_{i = 1}^d {\frac{{||g_t^i||_2^2}}{{4||g_t^i||_2^{3/2}}}} ,Tr(G_{t + 1}^T{D_t}{G_{t + 1}}) = \sum\limits_{i = 1}^d {\frac{{||g_{t + 1}^i||_2^2}}{{4||g_t^i||_2^{3/2}}}} ,$ |
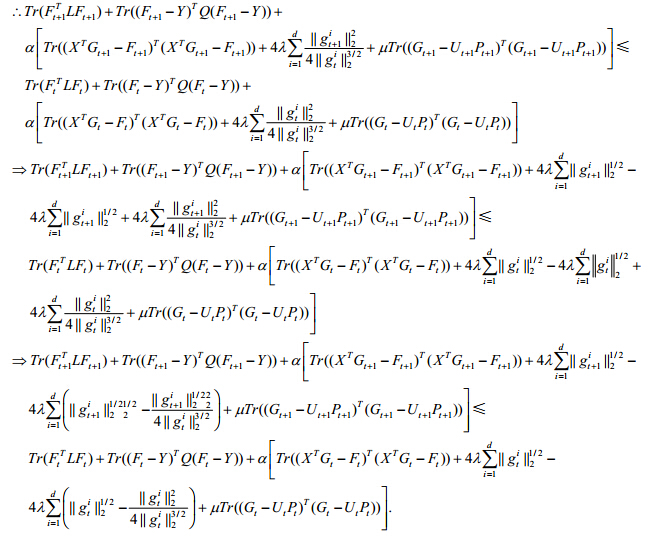
|
引理1中已经证明:
| $\sum\limits_{i = 1}^d {\left( {||g_{t + 1}^i||_2^{1/2} - \frac{1}{4}\frac{{||g_{t + 1}^i||_2^2}}{{||g_t^i||_2^{3/2}}}} \right)} \leqslant \sum\limits_{i = 1}^d {\left( {||g_t^i||_2^{1/2} - \frac{1}{4}\frac{{||g_t^i||_2^2}}{{||g_t^i||_2^{3/2}}}} \right)} .$ |
| $\begin{gathered} \Rightarrow Tr(F_{t + 1}^TL{F_{t + 1}}) + Tr({({F_{t + 1}} - Y)^T}Q({F_{t + 1}} - Y)) + \hfill \\ {\text{ }}\alpha \left[ {Tr({{({X^T}{G_{t + 1}} - {F_{t + 1}})}^T}({X^T}{G_{t + 1}} - {F_{t + 1}})) + 4\lambda \sum\limits_{i = 1}^d {||g_{t + 1}^i||_2^{1/2}} + \\\mu Tr({{({G_{t + 1}} - {U_{t + 1}}{P_{t + 1}})}^T}({G_{t + 1}} - {U_{t + 1}}{P_{t + 1}}))} \right] \leqslant \hfill \\ {\text{ }}Tr({F_t}^TL{F_t}) + Tr({({F_t} - Y)^T}Q({F_t} - Y)) + \hfill \\ {\text{ }}\alpha \left[ {Tr({{({X^T}{G_t} - {F_t})}^T}({X^T}{G_t} - {F_t})) + 4\lambda \sum\limits_{i = 1}^d {||g_t^i||_2^{1/2}} + \mu Tr({{({G_t} - {U_t}{P_t})}^T}({G_t} - {U_t}{P_t}))} \right], \hfill \\ \end{gathered} $ |
| $\begin{gathered} \Rightarrow Tr(F_{t + 1}^TL{F_{t + 1}}) + Tr({({F_{t + 1}} - Y)^T}Q({F_{t + 1}} - Y)) + \hfill \\ {\text{ }}\alpha [Tr({({X^T}{G_{t + 1}} - {F_{t + 1}})^T}({X^T}{G_{t + 1}} - {F_{t + 1}})) + 4\lambda ||{G_{t + 1}}||_{2,1/2}^{1/2} + \\\mu Tr({({G_{t + 1}} - {U_{t + 1}}{P_{t + 1}})^T}({G_{t + 1}} - {U_{t + 1}}{P_{t + 1}}))] \leqslant \hfill \\ {\text{ }}Tr({F_t}^TL{F_t}) + Tr({({F_t} - Y)^T}Q({F_t} - Y)) + \hfill \\ {\text{ }}\alpha [Tr({({X^T}{G_t} - {F_t})^T}({X^T}{G_t} - {F_t})) + 4\lambda ||{G_t}||_{2,1/2}^{1/2} + \mu Tr({({G_t} - {U_t}{P_t})^T}({G_t} - {U_t}{P_t}))]. \hfill \\ \end{gathered} $ |
上式表明:根据算法1,目标函数(22)是单调递减的,最终收敛于最优映射矩阵G. □
| [1] | Wu F, Yuan Y, Zhuang YT. Heterogeneous feature selection by grouplasso with logistic regression. In: Proc. of the Int’l Conf. on Multimedia. 2010. 983-986 . |
| [2] | YangY, Huang Z, Yang Y, Liu JJ, Shen HT, Luo J. Local image tagging via graphregularized joint group sparsity. Pattern Recognition, 2013,46(5):1358-1368 . |
| [3] | YuanY, Shao J, Wu F, Zhuang YT. Image annotation by themultiple kernel learning with group sparsity effect. Ruan Jian Xue Bao/Journalof Software, 2012,23(9):2500-2509 (in Chinese with English abstract).http://www.jos.org.cn/1000-9825/4154.htm |
| [4] | MaZG, Nie FP, Yang Y, Uijlings J, Sebe N, Hauptmann A. Discriminating jointfeature analysis for multimedia data understanding. IEEE Trans. on Multimedia,2012,14(6):1662-1672 . |
| [5] | TibshiraniR. Regression shrinkage and selection via the lasso. Journalof the Royal Statistical Society, 1996,58:267-288. |
| [6] | CaiD, Zhang C, He X. Unsupervisedfeature selection for multi-cluster data. In: Proc. of the ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining.2010.333-342 . |
| [7] | XuZB, Chang XY, Xu FM, Zhang H. L1/2 regularization: Athresholding representation theory and a fast solver. IEEE Trans. on Neural Networksand Learning Systems, 2012,23(7):1013-1027 . |
| [8] | XuZB, Zhang H, Wang Y, Chang XY, Liang Y. L1/2 regularizer. Science China, 2010,53(6):1159-1169 . |
| [9] | ZhaoQ, Meng DY, Xu ZB. L1/2 regularized logistic regression. Pattern Recognition and Artificial Intelligence, 2012,25(5): 721-728 (in Chinesewith English abstract). |
| [10] | Nie F, Huang H, Cai X, Ding C. Efficient and robust featureselection via joint L2,1-norms minimization. In: Proc. of the Neural Information ProcessingSystems. 2010. 1813-1821. http://papers.nips.cc/book/advances-in-neural-information-processing-systems-23-2010 |
| [11] | Ando RK, Zhang T. A framework for learning predictive structures frommultiple tasks and unlabeled data. The Journal of Machine Learning Research, 2005,6:1817-1853. |
| [12] | Yang Y, Wu F, Nie FP, Shen HT, Zhuang YT, Hauptmann AG. Web and personalimage annotation by mining label correlation with relaxed visual graph embedding.IEEE Trans. on Image Processing.2012,21(3):1339-1351 . |
| [13] | Ma ZG, Nie FP, Yang Y, Uijlings JRR, Sebe N. Web image annotationvia subspace-sparsity collaborated feature selection. IEEE Trans. on Multimedia, 2012,14(4):1021-1030 . |
| [14] | Tang JH, Hong RC, Yan SC, Chua TS, Qi GJ, Jain R. Image annotation by kNN-sparsegraph-based label propagation over noisily-tagged Web images. ACM Trans. on Intelligent Systems and Technology,2010,1(1):111-126 . |
| [15] | Lee WY, Hsieh LC, Wu GL, Hsu W. Graph-Based semi-supervised learningwith multi-modality propagation for large-scale image datasets. Journal of VisualCommunication and Image Representation, 2013,24(3):295-302 . |
| [16] | Chua TS, Tang J, Hong R, Li H, Luo Z, Zheng Y. Nus-Wide: Areal-world Web image database from national university of Singapore. In: Proc.of the Int’l Conf. on Image and Video Retrieval. Santorini: ACM Press, 2009.1-9 . |
| [17] | Li H, Wang M, Hua X. MSRA-MM 2.0: A large-scale Web multimediadataset. In: Proc. of the 2009 IEEE Int’l Conf. on Data Mining Workshops. Miami:IEEE, 2009.164-169 . |
| [18] | Wang LP, Chen SC. l2,p-Matrix norm and itsapplication in feature selection. 2013. http://arxiv.org/abs/1303.3987 |
| [19] | Zhu X. Semi-Supervised learning literature survey. Technical Report,1530, Madison: University of Wisconsin, 2007. |
| [20] | Zhu X, Ghahramani Z, Lafferty J. Semi-Supervised learning usinggaussian fields and harmonic functions. In: Proc. of the 20th Int’l Conf. on Machine Learning. Washington,2003. http://www.machinelearning.org/icml.html |
| [21] | Nie FP, Xu D, Hung T, Zhang CS. Flexible manifold embedding: Aframework for semi-supervised and unsupervised dimension reduction. IEEE Trans. on Image Processing, 2010,19(7):1921-1932 . |
| [22] | Yang Y, Zhuang YT, Wu F, Pan YH. Harmonizing hierarchical manifoldsfor multimedia document semantics understanding and cross-media retrieval. IEEETrans. on Multimedia, 2008,10(3):437-446 . |
| [23] | Zha ZJ, Mei T, Wang JD, Wang ZF, Hua XS. Graph-Based semi-supervisedlearning with multiple labels. Journal of Visual Communication and Image Representation,2009,20(2):97-103 . |
| [24] | Wang M, Hua XS, Tang JH, Hong R. Beyond distance measurement: Constructingneighborhood similarity for video annotation. IEEE Trans.on Multimedia, 2009,11(3):465-476 . |
| [25] | Chen J, Tang L, Liu J, Ye J. A convex formulation for learning sharedstructures from multiple tasks. In: Proc. of the 26th Annual Int’l Conf. on Machine Learning. New York: ACMPress, 2009.137-144 . |
| [26] | Ji S, Tang L, Yu S, Ye J. A shared-subspace learning framework formulti-label classification. ACM Trans. on Knowledge Discovery from Data, 2010,4(2):1-29 . |
| [27] | Golub GH, Loan CF. Matrix Computations. 3rd ed., Baltimore: TheJohns Hopkins University Press, 1996. |
| [28] | Cawley G, Talbot N, Girolami M. Sparse multinomial logistic regressionvia bayesian L1 regularisation. In: Schölkopf B, Platt J, Hoffman T, eds. Proc. ofthe Neural Information Processing Systems. 2007. 209-216. http://papers.nips.cc/book/advances-in-neural-information-processing-systems-20-2007 |
| [3] | 袁莹,邵健,吴飞,庄越挺.结合组稀疏效应和多核学习的图像标注.软件学报,2012,23(9):2500-2509.http://www.jos.org.cn/1000-9825/4154.htm |
| [9] | 赵谦,孟德宇,徐宗本.L1/2正则化Logistic回归.模式识别与人工智能,2012,25(5):721-728. |