 2015, Vol. 26
2015, Vol. 26



2 浙江理工大学 理学院, 浙江 杭州 310018
2 School of Science, Zhejiang Sci-Tech University, Hangzhou 310018, China
可靠性是衡量一个软件质量的重要指标,尤其是对于在线服务软件.例如应用于电信、金融、医疗、教育、制造、能源、物流等重要行业的软件.没有精确的可靠性预测,任何想不到的错误都可能中断服务.大多数这类系统都被期望满足严格的可靠性需求.当系统可靠性下降时,就需要提高系统可靠性,满足可靠性需求.在线服务型软件有着自己的特点:
· 首先,其运行环境是不确定和高度开放的,不同时刻有不同数量的用户在请求服务;
· 其次,服务组合软件系统由多个组件构成,由于并行使用,在同一时刻可能会有多个故障发生,而且会因异步服务而使故障的影响发生延迟.
因此,这类软件的可靠性随着运行时间的变化而动态发生变化.而传统的可靠性预测值在一个可控制的环境下得到,无法正确反映系统的实际可靠性,因此,我们需要对系统进行在线可靠性预测.当预测值低于期望可靠性时,我们就希望系统能够进行在线的自适应配置,从而提高可靠性.
目前已经有一些在线预测软件可靠性和提高软件可靠性的研究成果,比如:Pietrantuono等人[1]通过程序不变量来计算在线软件的可靠性;Malek等人[2]通过连续分析和自主配置来提高移动软件系统的可靠性;Cooray等人[3]采用隐式马尔可夫链来预测嵌入式系统和移动系统的可靠性,并通过对过程内的组件重新分配位置以及改变组件的个数来提高软件的可靠性.但这些工作有一些共同的弱点:
1) 不能预测软件在不同时段的可靠性;
2) 不能定位导致可靠性下降的组件.
在本文中,我们使用ARIMA模型对运行时软件的端口数据进行失效数据预测,进而进行在线系统不同时段的可靠性预测.若预测的可靠性低于预期值,则通过改进的基于频谱的错误定位技术定位出故障组件;然后,系统再自动添加与故障组件功能相同的组件,或用功能相同的组件替换故障组件来在线自动提高其可靠性.图 1显示了我们的方法的框架.本文的贡献主要在于成功地定位出导致系统可靠性降低的故障组件,在线自动提高了系统的可靠性.
 | Fig. 1 Framework of the proposed method 图 1 方法框架概况 |
本文第1节简要介绍我们以前的工作,即在线预测系统可靠性的方法.第2节介绍当系统可靠性降低时,如何定位故障组件的方法.第3节介绍如何对系统重新配置以提高系统可靠性,并给出系统自动提高系统可靠性的自适应算法.第4节通过实例演示说明我们的方法的可行性.第5节是相关工作的介绍.最后,对全文做出总结. 1 在线可靠性预测
在我们以前的工作中[4, 5],使用基于端口的可靠性模型,通过收集日志文件中记录的端口的变量值,运用统计模型ARIMA预测变量的失效数据,由失效数据预测端口的可靠性与系统的可靠性. 1.1 基于端口的组件模型
在我们以前的工作中,我们运用基于组件的服务组件架构SCA模型计算系统的在线可靠性.SCA提供独立于语言的方法来定义与组合服务组件,支持不同的编程语言实现组件功能.基于SCA,我们分析每个端口的可靠性并计算服务的可靠性.对于SCA模型简要介绍如下.
· 端口
端口p是一个多元组(M,t,c),M表示端口p的有限方法集,t表示提供或需求的端口类型,c表示同步或异步的通信类型.
· 组件
组件Com是一个多元组(Pp,Pr,G,W):Pp是提供端口的有限集;Pr是需求端口的有限集;G是有限子组件集;$W \subseteq TP \times \bigcup\nolimits_{C \in G} {(C.{P_p} \cup C.{P_r})} $表示非自反关系的端口关系,且$TP = {P_p} \cup {P_r} \cup \bigcup\nolimits_{C \in G} {C.{P_r}} ,$C.Pp 和C.Pr分别表示子 组件C提供和需求的端口集.
我们使用端口活动描述组件的动态行为,其基本活动被认为是两个端口之间的信息交换.组件动态行为表达式的语法定义如下:

这里:BBE代表跳过什么也不做的基本活动;分配活动p.x=e分配表达式e的值给p的变量x.b表示布尔表达式,定义省略;m代表消息;p·m代表端口p同步发送消息m,但是p和任何参考端口都不连接;p1·m p2表示端口p1同步发送消息m给端口p2;其他基本活动的含义基本相似.BE[p1/p2]是语法的重命名,表示在лBE中用p1替换p2.BE[p1→p2]用来指定连接操作,其语法转换定义如下:
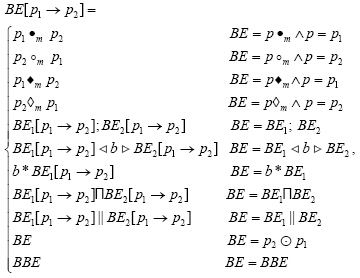
· 轨迹
一个给定的轨迹tr包含n个活动a1,a2,…,an,按照前面的语法规则,用 表示由BE转到BE¢,所经过的序列即为活动轨迹tr:
表示由BE转到BE¢,所经过的序列即为活动轨迹tr: 1.2 失效数据预测
1.2 失效数据预测
服务失败可能由服务组件的缺陷引起,也可能由所需的服务传播或执行环境等原因引起.这里,我们主要考虑与服务性能有关的错误,认为当一个服务请求的响应时间大于它的门限值时发生服务错误.我们使用ARIMA来预测失效数据.
ARIMA模型是时间序列分析中广泛使用的预测模型[6],我们选择该模型进行预测的原因在于:此模型考虑了时间序列数据的变化趋势、季节性、循环、误差和随机干扰性;其次,该模型对短期变化趋势的预测具有较高的准确率.而我们收集的失效数据是一个时间序列集,需要预测的是未来短期内的失效数据,因此,ARIMA模型是一个理想的预测模型.该模型一般形式表示为ARIMA(p,d,q),其中,p,q分别表示自回归项和移动平均项,d表示时间序列成为平稳时所做的差分次数.对于平稳、零均值的时间序列{Xt},其一般表达式为
Xt=Ø1Xt-1+…+ØpXt-p+εt+θ1εt-1+…+θqεt-q
, 其中,Ø1,…,Øp为自回归系数,θ1,…,θq为滑动平均系数,{εt}为白噪声序列(零均值和恒定方差σ2).利用ARIMA模型进行失效数据的预测包括如下过程:
· 第1步,失效数据的平稳化处理.
当失效数据序列{Y1,Y2,…,Yt}不平稳时,我们通过逐次差分,直到获得新的平稳序列{X1,X2,…,Xt-d},其中,所进行的差分次数即为d的值.然后,再将平稳序列{X1,X2,…,Xt-d}零均值化处理$\overline X $其中,$\overline X $为平稳序列的均值.
· 第2步,模型确定.
利用最小二乘估计法、极大似然估计法等方法对ARMA(p,q)的自回归系数、滑动平均系数进行估计;再利用AIC准则进行模型定阶,有着最小AIC值的模型即为最优模型.最后判断此模型的残差序列是否为白噪声:若是,则通过检验,得出软件可靠性预测模型;否则,重新计算.
· 第3步,失效数据预测.
根据所得模型预测$\{ {X'_t}\} $,然后还原为失效数据{Yt}的预测结果.预测过程的算法如下所示.
Algorithm 1. Pseudo-Code for the prediction of the algorithm.
Input: Original time series;
Output: Predict values.
Begin
Yt=read original time series
Internal ArrayList Adjust(ArrayList Yt)
{if (!judge(Yt))
{differential(Yt);}
else
return Yt is a stationary series;}
ModelIdentify(ACF,PACF)
/*ACF is autocorrelation function,
PACF is the partial autocorrelation function*/
While (ACF trail && PACF trail)
return ARMA(p,q);
ParameterEstimation(ARIMA(p,d,q))
{While (differential(Yt))
do (ADF check)
/*ADF represents Augmented Dickey-Fuller Unit Root Test*/
{if (Yt is a stationary)
d=differentialtimes;
return s;}
judge(p,q){
while (AIC=min && p && q)}
return ARIMA(p,d,q);}
Prediction(Yt)
{Ipm(predict early parameters values);
Epm(predict future parameters values);
Switch(choice)
Case 1: Ipm();
return result;
break;
Case 2: Emp();
return result;
break; } }
ErrorAnalysis()
{if ((|result-actualvalue|/actualvalue)<10%)
return result;
else ParameterEstimation(ARIMA(p,d,q))
End
算法中:
· 函数Adjust首先确定序列的稳定性;
· 函数ModelIdentify确定ARIMA模型;
· 模型ARIMA(p,d,q)的参数通过单元根检查和函数ParameterEstimation的AIC的值得到;
· 函数Prediction进行预测,由两个函数组成:Ipm预测早期参数值,Epm预测未来参数值;
· 函数ErrorAnalysis分析预测误差.
对于算法的复杂度,函数Adjust和ModelIdentify的复杂度为O(nlogn)和O(n),函数ParameterEstimation的复杂度为O(n2),函数Prediction的时间复杂度为O(1),函数ErrorAnalysis的时间复杂度为O(n2).所以,算法的时间复杂度为T(n)=O(n2). 1.3 预测端口可靠性
当一个端口的方法被调用时,我们认为这个端口被访问1次.ni表示端口p在一段时间间隔[0,T]内被访问的次数.预测过程中一个失效数据表示一次错误,fi表示预测过程中错误的次数.假设端口p有操作p1→p2,则在时间T端口p的可靠性定义为
$r(p[{p_1} \to {p_2}]) = 1 - \frac{{{f_i}}}{{{n_i}}}.$
因为端口p有一个固定操作p1→p2,为了方便起见,我们也记为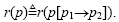 1.4 预测系统可靠性
1.4 预测系统可靠性
在我们以前的工作中,已经定义了基于端口的系统可靠性.系统在执行一段时间后的可靠性定义为
$r(system) = \frac{{\sum\nolimits_i {r(t{r_i})f(t{r_i})} }}{{\sum\nolimits_i {f(t{r_i})} }},$
其中,r(tri)是轨迹tri的可靠性,f(tri)是轨迹tri的发生频率.
行为表达式BE的轨迹可靠性为BE的端口可靠性的乘积.如果BE包含顺序、选择或循环结构,我们使用以下规则计算包含BE的所有轨迹的可靠性:
· [顺序规则]. p1,p2为两个端口,它们形成一个顺序的表达式:p1;p2,我们有:r(p1;p2)=r(p1)r(p2);
· [选择规则]. p1和p2为两个端口,它们形成的选择表达式为p1◁b▷p2.若b=True,则执行p1且X(b)=1;否则
执行p2,X(b)=0.于是有:r((p1◁b▷p2))=r(p1)x(b)xr(p2)1-x(b).
对于循环端口,我们有两种情况:(1) 循环的状况取决于用户输入或来自外部环境的数据;(2) 循环时间是一个固定的数字.
· [循环规则(1)]. p是一个端口,b是一个条件,它们形成一个循环表达式:b*p,假设退出第i次循环的概
率为p(i),且$\sum\nolimits_i {p(i)} = 1$.然后我们有:$r((b*p)) = r{(p)^{\sum\nolimits_i {ip(i)} }};$
· [循环规则(2)]. p是一个端口,n为一个正整数,它们形成一个循环表达式:n*p.那么我们有:r(n*p)=(r(p))n. 2 基于频谱的故障组件定位
上节我们讲述了在线服务系统在运行时的可靠性预测.当预测到的可靠性低于预期值时,可能由服务组件的缺陷引起,也可能由所需的服务传播或执行环境等原因引起.本文主要考虑因某个或多个组件发生故障导致预测到的系统可靠性达不到预期值,因此我们需要定位出发生故障的组件.本文在Abreu等人提出的错误定位方法的基础上[7, 8, 9],考虑到经过组件的次数,采用改进的基于频谱的错误定位方法进行错误组件的定位. 2.1 建立频谱矩阵
一个在线服务系统由一系列组件构成,可能会有多个错误组件.假设服务组合由M个组件组成,记为Cj (j&∈{1,…,M}),可能有E个错误组件.诊断报告D=<…,dk,…>为有序的可能的多个错误的组件候选集,dk按照错误的可能性排列.
在Abreu等人提出的错误定位方法中,频谱矩阵表示系统动态行为中所包含的组件的标记.系统每执行一次,经过了的组件记为1,否则记为0.假设共执行了N次,频谱矩阵表示为一个NxM的矩阵A.执行的结果存储在向量e中,表示每次执行完毕后,若运行通过则记为0,运行失败记为1.本文改进了这一方法,考虑了所经组件的次数,即,矩阵元素aij表示组件Cj在第i次执行时是否经过此组件及经过的次数. 2.2 候选集生成
由上一步建立的频谱矩阵(A,e)可知:假设每次初始输入变量是正确的,最后组件的输出值由e给出,我们可以推断出所经过的组件的正确性.本文使用最小命中集算法来计算诊断候选集,因为当系统的组件数目庞大,需要搜索大量命中集时,这种解决方案可以很有效地获得所需最小命中集.按照相关性排序,排除可能没有价值的后验概率非常低的候选集,因此,该解决方案既能得到需处理的候选集最小数量,又提高了效率.基于频谱的错误定位技术(SFL)能够很好地按照组件故障可能性预测故障排行.SFL输入频谱矩阵(A,e)产生有序的组件错误可能性排行.组件以相似系数计算排名,提供了良好的准确性,即排名最高的组件往往是错误的.Abreu等人在文献[9]中给出了相似系数的定义,但他们只考虑到是否调用组件,而我们的频谱矩阵是经过组件的次数,故需修改n11,n10,n01的计算公式,具体相似系数的定义为
| $s(j) = \left\{ {\begin{array}{*{20}{l}} {\frac{{{n_{11}}(\{ j\} )}}{{den(j) = \sqrt {({n_{11}}(\{ j\} ) + {n_{10}}(\{ j\} ))*({n_{11}}(\{ j\} ) + {n_{01}}(\{ j\} ))} }},{\rm{ }}den(j) \ne 0}\\ {0,{\rm{otherwise}}} \end{array}} \right.$ | (1) |
其中,
${n_{11}}(j) = |\{ i \in \{ 1,2,...,N\} |{a_{ij}} > 0 \wedge {e_i} = 1\} |,$
${n_{10}}(j) = |\{ i \in \{ 1,2,...,N\} |{a_{ij}} > 0 \wedge {e_i} = 0\} |,$
最小命中集算法STACCATO如下:
Algorithm 2. Staccato.
Inputs: Matrix(A,e),number of components M,stop criteria l,L;
Output: Minimal Hitting set D.
1: TF¬{|ei=1} >Collection of conflict sets
2: R¬rank(H,A,e) >Rank according to heuristic H
3: D®
4: seen¬0
5: for all jÎ{1,...,M} do
6: if n11({j})=|TF| then
7: push(D,{j})
8: A¬Strip_Component(A,j)
9: R¬R\{j}
10: seen¬seen+1\M
11: end if
12: end for
13: while R¹ÆÙseen≤lÙ|D|≤L do
14: j¬POP(R)
15: seen¬seen+1\M
16: (A¢,e¢)¬Strip(A,e,j)
17: D¢¬Staccato(A¢,e¢,M-|{j|n11(j)=|TF|}|-1,l,L)
18: while D¢¹Æ do
19: j¢¬POP(D¢)
20: j¢¬{j}Èj¢
21: if is_not_subsumed (D,j¢) then
22: push(D,j)
23: end if
24: end while
25: end while
26: return D
算法STACCATO递归地使用频谱矩阵(A,e)的子结构生成最小命中集.算法分为3步.
(1) 初始化阶段使用相关系数对组件进行排行;
(2) 将所有失败的集合中包含的组件加入候选集D中;
(3) 当|D|<L时,对排行中首先超过λ的组件作以下处理:移除组件j,保留(A,e)中所有ei=1Λaij>0的${A_{{i^*}}}$,对新
的(A,e)运行STACCATO算法,将返回的组件加入D并验证它是否为最小命中集.
算法STACCATO的时间复杂度为O((|D|+Mx(N+logM))C),而实际中,由于搜索算法的时间复杂度只有O(Cx|D|+CxMx(N+logM)),对于空间复杂度,因为算法需要存储每个组件的4个计数器来得出排行(n11,n10,n01,n00),所以递归深度为C,算法STACCATO的空间复杂度为O(C×M). 2.3 候选集排序
对于上一阶段所得出的候选集dk与实际观测值一致,然而尽管候选集空间减小了,但剩余的候选集dk的概率也并非相同.因此,计算候选集概率Pr(dk)、建立候选集排行依旧至关重要.我们使用贝叶斯规则来计算候选集的概率.
根据候选集dk的所有观测值,每个候选集dk的概率描述了实际系统的错误情况.由贝叶斯规则得出,在所观测到的观测值下候选集dk的后验概率的计算公式为
| ${P_r}({d_k}|obs) = \frac{{{P_r}(obs|{d_k})}}{{{P_r}(obs)}} \cdot {P_r}({d_k})$ | (2) |
令Pr(j)=p表示组件Cj错误的先验概率,假设组件错误是独立的,则候选集dk的先验概率为
| ${P_r}({d_k}) = {p^{|{d_k}|}} \cdot {(1 - p)^{M - |{d_k}|}}$ | (3) |
Pr(obs)是正规化因子,无需计算.因每次执行是独立的,故:
| ${P_r}(obs|{d_k}) = \prod\limits_{i = 1}^N {{P_r}(ob{s_i}|{d_k})} $ | (4) |
| ${P_r}(ob{s_i}|{d_k}) = \left\{ {\begin{array}{*{20}{l}} {1,{\rm{ }}{d_k} \to ob{s_i}}\\ {0,{\rm{ }}ob{s_i} \wedge {d_k}| = \bot }\\ {{\varepsilon _{ik}},{\rm{ }}{d_k} \to \{ ob{s_1},...,ob{s_N}\} } \end{array}} \right.$ | (5) |
关于εik的定义有很多种,本文的定义为
| ${\varepsilon _{ik}} = \left\{ {\begin{array}{*{20}{l}} {\prod\limits_{j:(j \in {d_k}) \wedge ({a_{ij}} > 0)} {h_j^{{a_{ij}}}} ,{\rm{ }}{e_i} = 0}\\ {1 - \prod\limits_{j:(j \in {d_k}) \wedge ({a_{ij}} > 0)} {h_j^{{a_{ij}}}} ,{\rm{ }}{e_i} = 1} \end{array}} \right.$ | (6) |
由公式(4)、公式(6),我们可以得出Pr(obs|dk)关于hj的表达式;通过最大似然估计法,我们可以得到hj的估计值,实际上就是求解如下极值问题:
| $\arg \mathop {\max }\limits_G {P_r}(obs|{d_k})$ | (7) |
上节提出了定位故障组件的方法.定位出故障组件后,为了提高系统可靠性,我们可以采用两种策略来实现这个目标:
· 第一,添加新的功能相同的组件,与故障组件共同实现组件功能,从而提高系统的可靠性需求;
· 第二,更换出故障组件,连接一个功能相同的新组件,解决故障组件的影响,提高系统可靠性.
这里,所谓的功能相同的组件是指它们具有相同的端口,包括相同的函数集合、相同的端口类型以及相同的通信类型,端口间的关系也一致. 3.1 添加组件
确定了故障组件后,通过在线新添加一个相同功能的组件,从而可以实现系统的正常运行.添加组件时,除了需要保证新加入的组件正常运行外,还需要减小新组件对其他部分的影响.在正在运行的系统中添加可以正常运行的组件,此时,系统并非处于初始状态,因此,添加的组件第1步是检查系统的当前状态,并对新组件执行必要的初始化操作,使之与系统同步.基于端口的组件架构中,端口封装了所有所需的复杂功能,保持着内部信息,并使用多个线程来控制.端口包含3个属性:伙伴链接、端口类型和两个服务之间的交互操作.因此,第2步,我们将最后一个服务点分配给伙伴链接以获得最后的服务组合的绑定信息,以此来满足端口到端口的动态绑定[10, 11],从而支持系统的重新配置.
添加新组件后,采用第1节所介绍的可靠性计算方法重新计算新配置好的系统可靠性.因新添加组件后,系统可选择运行的组件增多,因此,系统执行的轨迹也随之增加,而且轨迹执行的频率也发生了改变,但因新添加的组件而增加的轨迹与经过故障组件的轨迹之和应等于初始轨迹执行的次数.在系统添加新组件后计算其可靠性过程中,新组件的各端口的可靠性很高,从而提高了系统的可靠性. 3.2 替换组件
当系统可靠性低于预期值时,将故障组件替换为提供相同功能的正常组件,从而保证系统的可靠性需求.替换新组件时要保护组件各个端口的状态信息,而且要防止通信信息等数据的丢失.我们需要执行一系列的操作:
· 第一,通过停止所有由故障组件发出的通信来停止故障组件的执行;
· 第二,解除故障组件和其他组件间的绑定;
· 第三,通过发送请求,将系统其余部分和新组件链接;
· 第四,通过调整新组件与其他组件之间的服务通信来激活新组件[12, 13].
替换时先解除端口与连接器间的绑定,端口提供两种方法:一个用来发送状态信息,另一个用于替换组件时执行初始化操作.连接器可以通过将请求转发至替换组件处来解决组件失效问题.连接器将发送的先前建立的到原始组件的请求,再重新发送到新的组件.另外,因运行时改变架构,与需替换新组件的组件进行交互的组件暂时变得不可用,此时,连接器便调停其与其他组件间的交互,对服务请求排队,直到组件可用.因而,系统中其他组件不会受到改变架构时的影响,保证系统的正常运行.
替换故障组件后,再采用第1节所介绍的可靠性计算方法重新计算新配置好的系统可靠性.新组件的各端口可靠性很高,系统执行轨迹数目及其执行频率均未改变,进而提高了系统的可靠性. 3.3 自适应算法
我们开发出一种自适应算法来解决在线服务系统的可靠性提高问题.在系统运行过程中,通过组件端口的失效数据在线预测系统的可靠性,当预测到的系统可靠性降低时,我们认为系统某个或多个组件发生故障,导致系统可靠性低于预期.此时,通过改进的基于频谱的错误定位技术找出发生故障的组件,再自动地对系统添加新的与故障组件功能相同的组件,或用与故障组件功能相同的新组件替换出故障组件.最后重新计算系统的可靠性,从而达到提高系统可靠性的目的.算法描述如下:
Step 1:在线计算系统的可靠性R.
Step 2:if R<RE (RE为系统可靠性预期值),go to Step 3;
if R≥RE,end.
Step 3:计算候选集概率Pr(dk|obsi)并排序:
Step3-1:建立组件频谱矩阵(A,e);
Step3-2:确定可能错误组件候选集D;
Step3-3:确定各候选集的后验概率(即可疑度)并排序.
Step 4:选择当前候选集D中可疑度最高的候选集dk,D=D-{dk}.
Step 5:分别计算采用两种方案的系统可靠性:
1) 用与可疑度最高的候选集功能相同的组件集合进行替换,可靠性计算为R1;
2) 添加与可疑度最高的候选集功能相同的组件集合,可靠性计算为R2.
Step 6:重新配置系统:
 若R1≥R2,用功能相同的组件替换出故障的组件;
若R1≥R2,用功能相同的组件替换出故障的组件;
若R1<R2,继续添加新的功能相同的组件.
Step 7:如果max(R1,R2)<RE,goto Step 4;否则结束.
在上述算法中,我们假定新组件的可靠性为1.由以上算法分析其算法复杂度可知:第1节中我们已经分析了在线预测系统可靠性算法的时间复杂度为O(n2),当系统可靠性下降时,定位出故障组件的算法时间复杂度为O(Cx|D|+CxMx(N+logM))+O(NxM+Mx(N+logM)).自适应地对系统更换组件或添加新组件的时间复杂度为O(M).因此,该自适应算法的时间复杂度为O(n2+M2).
然而,这一方法还有一些不足之处.当组成系统的组件数目过于庞大时,基于频谱的错误定位算法复杂度会随组件数目的增加而增高,因而自适应算法的复杂度也相对增大.此时,该方法的有效性会大为降低,系统提高可靠性的效率相对较低. 4 实例分析
我们使用在线商店作为事例来阐明本文所提出的方法.在线商店包含组件:C11=INIT,C12=ORDER,C21= INVOICE,C22=PAYMENT,C3=DELIVERY,Ccs,Cds.系统由Java语言和Tomcat服务器与SQL数据库服务器支持实现.在线商店的架构图如图 2所示.
 | Fig. 2 SCA of online shop图 2 在线商店的服务组件体系结构 |
在此案例中,系统工作量由0~200个当前用户在20分钟内进行交易,每6s有一个用户进入系统.此外,我们定义响应时间大于8s为失效数据. 4.1 预测在线系统的可靠性
首先,我们以order端口为例,预测它在第23分钟时的可靠性.
通过日志文件,我们可以收集到系统所有端口的参数值.以order端口为例,分别预测第21分钟、第22分钟、第23分钟的相应时间.表 1列举了在20分钟内每隔1分钟所收集到的order端口所有响应时间的值.
| Table 1 Collected data for time 表 1 每分钟收集的数据 |
根据第1.2节所述,我们得到的预测模型为ARIMA(7,2,6),用此模型来预测接下来3分钟的响应时间,预测结果分别为7 072.03,7 816.51,8 518.68.显然,端口order只有在第23分钟时响应时间大于8s;其次,假设order端口共经过了468次.因此,我们可以得到端口order的可靠性为1-1/468=0.9978.
同理,我们可以预测其余各端口在第23分钟时的可靠性,见表 2.
| Table 2 Reliability of each port at the 23rd min 表 2 每个端口在第23分钟时的可靠性预测值 |
根据端口的可靠性预测值,我们可以计算整个系统的可靠性.根据日志文件可以得到系统共有13条运行轨迹,表 3给出其中的5条轨迹.表 4为对应轨迹的可靠性计算公式.
| Table 3 Part of online shop system traces 表 3 在线购物系统的部分轨迹路线 |
| Table 4 Traces reliability of online shop 表 4 在线商店的轨迹可靠性 |
· 概率:
${p_{{b_4}}}(1) = 0.965,{p_{{b_4}}}(2) = 0.024$(被盗的信用卡,信用不足等),(错别字等);
· 标记频率:
f(tr1)=56,f(tr2)=53,f(tr3)=78,f(tr4)=58,f(tr5)=85,f(tr6)=62,f(tr7)=49,
f(tr8)=65,f(tr9)=57,f(tr10)=94,f(tr11)=56,f(tr12)=76,f(tr13)=51.
因此,我们预测的整个系统的可靠性为$r(system) = \frac{{\sum\nolimits_i {r(t{r_i})f(t{r_i})} }}{{\sum\nolimits_i {f(t{r_i})} }} = 0.6989.$
可以看出,系统的可靠性低于预期值.为此,我们需要找出导致这一问题的故障组件. 4.2 定位故障组件我们从数据库的文件信息中得到系统运行时所经过的组件信息以及运行情况,以60s为窗口大小,更新频谱矩阵,见表 5.
| Table 5 Spectral matrix of online shop 表 5 在线商店的频谱矩阵 |
由第2节介绍的方法得出此矩阵推出可能发生错误的候选集.相关系数计算见表 6.
| Table 6 Correlation coefficient value of each component 表 6 各组件的相关系数 |
因此,由相关系数大小排序可得<C11,C12,C21,C22,Ccs,C3,Cds>.由最小命中集算法STACCATO返回的候选集为
{{C11},{C12,C21},{C12,C22}}.
计算每个候选集的概率值,从而确定出问题组件.对于候选集{C11}可知:
| C11 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| e | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| Pr(ei|dk) | h1 | 1-h1 | h1 | h1 | 1-h1 | h1 | h1 | h1 | h1 | 1-h1 |
故Pr(obs|{C11})=(1-h1)3,对h1求其最大似然估计值,得到h1=0.7,此时,Pr(e|{C11})=2.224x10-3.
同理,对于候选集{C12,C21}可知:
| C12 | C21 | e | Pr(ei|dk) |
| 0 | 1 | 0 | h2 |
| 1 | 1 | 1 | 1-h1h2 |
| 1 | 1 | 0 | h1h2 |
| 1 | 1 | 0 | h1h2 |
| 0 | 1 | 1 | 1-h2 |
| 0 | 1 | 0 | h2 |
| 0 | 1 | 0 | h2 |
| 1 | 1 | 0 | h1h2 |
| 0 | 1 | 0 | h2 |
| 1 | 0 | 1 | 1-h1 |
Pr(obs|{C12,C21})=(1-h1)(1-h2)(1-h1h2),对h1,h2求最大似然估计值为h1=0.6417,h2=0.8528,故:
Pr(obs|{C12,C21})=2.07x10-3.
对于候选集{C12,C22}:
| C12 | C22 | e | Pr(ei|dk) |
| 0 | 4 | 0 | $h_2^4$ |
| 1 | 4 | 1 | 1-${h_1}h_2^4$ |
| 1 | 4 | 0 | ${h_1}h_2^4$ |
| 1 | 4 | 0 | ${h_1}h_2^4$ |
| 0 | 4 | 1 | 1-$h_2^4$ |
| 0 | 4 | 0 | $h_2^4$ |
| 0 | 4 | 0 | $h_2^4$ |
| 1 | 4 | 0 | h1h4 |
| 0 | 4 | 0 | h4 |
| 1 | 0 | 1 | 1-h1 |
Pr(obs|{C12,C22})=对h1,h2求最大似然估计值为h1=0.6417,h2=0.9610,故:
Pr(obs|{C12,C22})=2.07x10-3.
利用公式(7)后,可知Pr(d1|obs)=1.86x10-9,Pr(d2|obs)=1.92x10-10,Pr(d3|obs)=1.92x10-10.所以,候选集排行为{{C11},{C12,C21},{C12,C22}},即,组件C11=INIT,出错的可能性最大.
定位出出错组件后,系统将进行重新配置. 4.3 计算添加新组件后的系统可靠性
采用系统重新配置的第1个方案,添加与组件C11=INIT功能相同的新组件${C'_{11}}$=INIT',重新计算系统可靠性.图 3所示为添加新组件${C'_{11}}$=INIT'后系统部分的架构图.
 | Fig. 3 Adding a new component of part online shop SCA 图 3 添加新组件的部分在线商店SCA |
添加新组件=INIT后,系统可选择组件C11=INIT与${C'_{11}}$=INIT两条路径开始执行,且两条开始路径互斥. 因此,系统的轨迹变为原来的2倍.各端口可靠性见表 7.
| Table 7 Values of reliability for each port 表 7 每个端口的可靠性的值 |
添加新组件后,整个系统的可靠性为
$r(system) = \frac{{\sum\nolimits_i {r(t{r_i})f(t{r_i})} }}{{\sum\nolimits_i {f(t{r_i})} }} = 0.8693.$
4.4 计算替换出故障组件后的系统可靠性采用系统重新配置的第2个方案,用功能相同的新组件=INIT²替换故障组件C11=INIT,重新计算系统可 靠性.各端口可靠性见表 8.
| Table 8 Values of reliability for each port 表 8 每个端口的可靠性的值 |
替换出故障组件后整个系统的可靠性为
$r(system) = \frac{{\sum\nolimits_i {r(t{r_i})f(t{r_i})} }}{{\sum\nolimits_i {f(t{r_i})} }} = 0.9546.$
比较添加新组件与替换出故障组件两种方案的实验结果可得:在该实验中,当系统可靠性达不到预期值时,更换组件提高的系统可靠性效果要更好.因此,本实例中采取更换故障组件C11=INIT的策略来自动地提高系统的可靠性. 5 相关工作
本文的工作与下面的研究领域有关.
· 系统可靠性预测
在过去的30多年间有很多模型和方法被提出[14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27],然而其中大多数方法都是从系统的软件架构考虑出 发[16, 17, 18, 19, 20, 21, 22, 27],这些方法中的基础假设使得它们不适用于动态服务系统领域.此外,目前许多方法是收集静态数据来预测系统可靠性,并未考虑系统的动态性问题.例如:Hu等人[28]在Nelson模型基础上考虑了从用户角度获得关于故障的严重性的信息,提出了基于多粒度故障严重性的软件可靠性模型;Gunawan[29]提出了利用蒙特卡洛方法来预测分布式系统的可靠性.目前也有一些关于在线可靠性预测的研究,例如Epifani,Ghezzi和Mirandola提出的通过运行时参数自适应模型演化的KAMI(keep alive models with implementations)方法[30],它利用运行时数据来更新可靠性模型的参数,提供连续的在线可靠性分析.Pietrantuono,Russo和Trivedi[1]结合静态可靠性模型与动态分析方法来预估运行时系统可靠性趋势.Wang等人[31]通过运行时数据以及结合动态分析方法与软件架构来预测系统可靠性.这些方法考虑了软件运行时系统可靠性的动态变化,运用变化来调整可靠性预测.然而这些方法只是预测系统实时的可靠性,并未使用在线数据进行从系统实时状态到相隔一个时间段后系统的可靠性预测.
· 系统可靠性在线提高
目前也有一些研究来实现此目标,比如Cooray[3]等人提出的通过在执行时加入包括系统的执行环境等各种信息资源来不断地提供精确的可靠性预测.通过对组件的再分配进程和改变组件副本的数量对系统进行重新配置,进而得到系统的最优配置,从而提高系统的在线可靠性.
他们将软件可靠性提高问题转化为一个优化问题,该优化问题是一个NP问题.该优化问题的解空间呈指数增长:O((max{wi}xh)t),wi为组件i最大可复制数,h表示过程数,t为组件数.Cooray等人首先通过最大变异优先策略(即,能产生最大可靠性的改变)获得可以达到可靠性要求的配置方案,然后再通过比较邻近配置方案,选择一个较好的配置方案.Caporuscio等人[32]研究了基于组件的软件系统的性能提高问题,通过系统配置(增加组件、移除组件、替代组件、修改参数等)来提高性能指标,并用贪婪策略选择最优配置方案.
· 软件自适应
研究者对软件自适应研究较多,如Chen等人在2008年举办的自适应系统软件工程讨论班上总结了自适应软件模型应具备的特征或维(dimensions),分别从目标(goal)、变化(change)、机制(mechanism)、效果(effects)这4个方面进行了讨论[33];Epifani等人通过在运行阶段调整模型的参数来更新模型,从而自动地提高软件的非功能性特性,如可靠性和性能[34];Mohammad等人[12]提出了在动态配置过程保证系统可靠性的方法——并行转换,即:通过部署一个空闲资源,同时允许对新组件和旧组件进行并发操作.Magee等人[35]根据3层模型,依据高层目标设计自适应软件架构,对任务进行合成.Garlan和Schmerl[36]通过描述架构类型和修复策略来实现动态变化.Cheng[16]设计了一个叫做Rainbow的框架,它具备在运行时监视、检测、决定、实施的自适应能力.孙熙等人[37]将软件Agent技术和构件技术结合起来,使得构件能够根据环境的状态调整自己的行为.面向服务的架构通过服务组合也支持实现自适应软件,如:Irmert等人[38]利用面向服务组件模型提出了(CoBRA)架构,用来支持动态适应;马晓星等人[39]提出了一种面向服务的动态协同架构,让应用系统能够灵活地动态演化,以适应底层Internet计算环境和用户需求的变化;Wang[40]提出了一个规则模型,该模型可以用来提取程序中离散的规则,从而提高软件的自适应能力;Ma等人[41]提出了一种用可自动地从构件的实施中提取的米利机来管理构件之间的动态依赖性,从而便于基于构件的系统进行实时重构.
然而,上述研究有如下两个方面的不足.
(1) 可靠性预测方面
这些方法只是预测系统的可靠性,而无法根据实时运行数据和系统当前状态来预测系统在未来某个具体时间间隔的可靠性.
(2) 可靠性提高方面
当系统的可靠性降低时,上述相关研究者只是提出了一些通用的系统重新配置的方法,并未具体分析、定位引起可靠性降低的组件.
因此,本文首先根据以前工作中通过时间序列分析模型ARIMA来预测系统在未来某个具体时间间隔的可靠性.当系统可靠性降低时,我们首先通过基于频谱的错误定位技术定位出导致系统可靠性下降的故障组件,进而对故障组件进行在线重新配置,从而在线提高了系统可靠性. 6 结 论
在本文中,我们利用端口失效数据来预测在线服务组合系统的可靠性,通过改进的基于频谱的错误定位技术来定位出故障组件,系统自动重新配置:或者添加新组件,或者替换出故障组件,从而在线提高系统的可靠性,这样可以解决面向服务的软件的可靠性降低的问题.这种方法与现有技术的不同之处在于:它不仅可以在线预测系统运行不同时段的可靠性,而且还可以在系统可靠性降低而不满足可靠性需求时,定位出故障组件,重新配置系统以在线自动提高系统可靠性.
本文主要进行了如下两个方面的创新.
· 目前已有一些关于可靠性预测和可靠性提高的研究,但是这些研究没有考虑引起可靠性降低的原因.本文提出,通过故障组件定位来对系统进行自适应配置以提高系统的可靠性.因此,系统配置具有针 对性;
· 改进了Abreu等人提出的基于频谱的组件定位方法.我们考虑各个组件被执行的次数,而不仅仅是简单的是否被执行,因为不同组件被执行的次数将对定位的准确性具有较大的影响. 在将来的工作中,我们将针对如下4个方面进行更进一步的研究.
(1) 由于实时收集的数据是与时间有关的,我们要考虑研究参数值的变化对可靠性的影响问题;
(2) 采用更多的例子来验证预测模型的准确度;
(3) 考虑组件间的交互而引起的假性正确问题;
(4) 综合考虑系统自适应配置的成本(例如时间、内存、可靠性提高效果),从而选择合适的系统配置方法.
| [1] | Pietrantuono R, Russo S, Trivedi KS. Online monitoring of software system reliability. In: Proc. of the 2010 European Dependable Computing Conf. IEEE, 2010. 209-218 . |
| [2] | Malek S, Roshandel R, Kilgore D, Elhag I. Improving the reliability of mobile software systems through continuous analysis and proactive reconfiguration. In: Proc. of the 31st '1 Conf. on Software Engineering-Companion, Vol. 2009. 2009. 275-278 . |
| [3] | Cooray D, Kouroshfar E, Malek S, Roshandel R. Proactive self-adaptation for improving the reliability of mission-critical, embedded, and mobile software. IEEE Trans. on Software Engineering, 2013,39(12):1714-1735 . |
| [4] | Ding ZH, Xu T, Chen MH. Online reliability prediction of services composition. In: Proc. of the 2014 3rd Int'1 Workshop on Evidential Assessment of Software Technologies, Vol.264. 2014. 340-348 . |
| [5] | Ding ZH, Jiang MY. Port based reliability computing for service composition. IEEE Trans. on Service Computing, 2011,5(3): 422-436 . |
| [6] | Jia ZY, Kang R. Forecasting method of software reliability based on ARIMA model. Computer Engineering and Applications, 2008, 44(35):17-19 (in Chinese with English abstract). |
| [7] | Abreu R, Zoeteweij P, van Gemund AJC. A new bayesian approach to multiple intermittent fault diagnosis. In: Proc. of the Int'1 Joint Conf. on Artificial Intelligence. 2009. 653-658. |
| [8] | Abreu R, Zoeteweij P, van Gemund AJC. On the accuracy of spectrum-based fault localization. In: Proc. of the Testing: Academic and Industrial Conf. on Practice and Research Techniques--UTATION 2007. IEEE, 2007. 89-98 . |
| [9] | Abreu R, van Gemund AJC. Diagnosing multiple intermittent failures using maximum likelihood estimation. Artificial Intelligence, 2010,174(18):1481-1497 . |
| [10] | Yan GH, Han YH, Li XW. ReviveNet: A self-adaptive architecture for improving lifetime reliability via localized timing adaptation. IEEE Trans. on Computers, 2011,60(9):1219-1232 . |
| [11] | Peyman O, Nenad M, Richard NT. Architecture-Based runtime software evolution. In: Proc. of the 20th Int'1 Conf. on Software Engineering. IEEE, 1998. 177-186 . |
| [12] | Mohammad G, Abbas H. Partial scalability to ensure reliable dynamic reconfiguration. In: Proc. of the 2013 IEEE 7th Int'1 Conf. on Self-Adaptation and Self-Organizing Systems Workshops. IEEE, 2013. 83-88 . |
| [13] | Cao K, Jiang H, Chen GH, Cui P, Xiong T. Self-Adaptive induced mutation algorithm for reconfigurable antenna system. IEEE Antennas and Wireless Propagation Letters, 2014,13:237-240 . |
| [14] | Xie CL, Li BX, Su ZY. WSDG-Based reliability prediction approach for Web service composition. Journal of Southeast University (Natural Science Edition), 2012,42(6):1074-1079 (in Chinese with English abstract). |
| [15] | Cheung RC. A user-oriented software reliability model. IEEE Trans. on Software Engineering, 1980,6(2):118-125 . |
| [16] | Garlan D, Cheng S, Huang A, Schmerl B, Steenkiste P. Rainbow: Architecture-Based self-adaptation with reusable infrastructure. Computer, 2004,37(10):46-54 . |
| [17] | Gokhale SS. Architecture-Based software reliability analysis: Overview and limitations. IEEE Trans. on Dependable and Secure Computing, 2007,4(1):32-40 . |
| [18] | Goseva-Popstojanova K, Hassan A, Guedem A, Abdelmoez W, Nassar DEM, Ammar H, Mili A. Architectural level risk analysis using UML. IEEE Trans. on Software Engineering, 2003,29(10):946-960 . |
| [19] | Goseva-Popstojanova K, Trivedi KS. Architecture-Based approaches to software reliability prediction. Computer & Mathematics with Applications, 2003,46(7):1023-1036 . |
| [20] | Immonen A, Niemela E. Survey of reliability and availability prediction methods from the viewpoint of software architecture. Software and Systems Modeling, 2008,7(1):49-65 . |
| [21] | Kramer J, Magee J. Self-Managed systems: An architectural challenge. In: Proc. of the IEEE Future of Software Engineering. 2007. 259-268 . |
| [22] | Krishnamurthy S, Mathur A. On the estimation of reliability of a software system using reliabilities of its components. In: Proc. of the 8th Int'1 Symp. on Software Reliability Engineering. IEEE, 1997. 146-155 . |
| [23] | Reussner RH, Schmidt HW, Poernomo IH. Reliability prediction for component-based software architectures. Journal of Systems and Software, 2003,66(3):241-252 . |
| [24] | Rodrigues G, Rosenblum D, Uchitel S. Using scenarios to predict the reliability of concurrent component-based software systems. In: Cerioli M, ed. Proc. of the Fundamental Approaches to Software Engineering. Berlin, Heidelberg: Springer-Verlag, 2005. 111-126 . |
| [25] | Roshandel R, Medvidovic N, Golubchik L. A Bayesian model for predicting reliability of software systems at the architectural level. In: Overhage S, ed. Proc. of the Software Architectures, Components, and Applications. Berlin, Heidelberg: Springer-Verlag, 2007. 108-126 . |
| [26] | Singh H, Cortellessa V, Cukic B, Gunel E, Bharadwaj V. A Bayesian approach to reliability prediction and assessment of component based systems. In: Proc. of the 12th Int'1 Symp. on Software Reliability Engineering. IEEE, 2001. 12-21 . |
| [27] | Wang WL, Pan D, Chen MH. Architecture-Based software reliability modeling. Journal of Systems and Software, 2006,79(1): 132-146 . |
| [28] | Hu H, Jiang CH, Cai KY, Wong WE, Mathur AP. Enhancing software reliability estimates using modified adaptive testing. Information and Software Technology, 2013,55(2):288-300 . |
| [29] | Gunawan I. Reliability prediction of distributed systems using Monte Carlo method. Int'1 Journal of Reliability and Safety, 2013, 7(3):235-248 . |
| [30] | Epifani I, Ghezzi C, Mirandola R, Tamburrelli G. Model evolution by run-time parameter adaptation. In: Proc. of the 2009 31st Int'1 Conf. on Software Engineering. IEEE, 2009. 111-121 . |
| [31] | Wang WL, Hemminger TL, Tang MH. A moving average modeling approach for computing component-based software reliability growth trends. INFOCOMP Journal of Computer Science, 2006,5(3):9-18. |
| [32] | Caporuscio M, Marco AD, Inverardi P. Model-Based system reconfiguration for dynamic performance management. The Journal of Systems and Software, 2007,80:455-473 . |
| [33] | Cheng BHC, de Lemos R, Giese H, Inverardi P, Magee J. Software engineering for self-adaptive systems: A research roadmap. In: Proc. of the Software Engineering for Self- Adaptive Systems. Springer-Verlag, 2009. 1-26 . |
| [34] | Epifani I, Ghezzi C, Mirandola R. Model evolution by run-time parameter adaptation. In: Proc. of the 21st Int'1 Conf. on Software Engineering. IEEE, 2009. 111-121 . |
| [35] | Kramer J, Magee J. Self-Managed systems: An architectural challenge. In: Proc. of the 2007 Future of Software Engineering. IEEE, 2007. 259-268 . |
| [36] | Garlan D, Schmerl B. RAINBOW: Architecture-Based adaptation of complex systems. Technical Report, AFRL-IF-RS-TR-2005- 121, New York: Carnegie-Mellon Univ Pittsburgh Pa, 2005. 1-43. |
| [37] | Sun X, Zhuang L, Liu W, Jiao WP, Mei H. A customizable running support framework for autonomous components. Ruan Jian Xue Bao/Journal of Software, 2008,19(3):1340-1349 (in Chinese with English abstract). http://www.jos.org.cn/1000-9825/19/1340.htm |
| [38] | Irmert F, Fischer T, Meyer-Wegener K. Runtime adaptation in a service-oriented component model. In: Proc. of the 2008 Int'1 Workshop on Software Engineering for Adaptive and Self-Managing Systems. ACM Press, 2008. 97-104 . |
| [39] | Ma XX, Yu P, Tao XP, Lü J. A service-oriented dynamic coordination architecture and its supporting system. Chinese Journal of Computers, 2005,28(4):467-477 (in Chinese with English abstract). |
| [40] | Wang QX. Towards a rule model for self-adaptive software. ACM SIGSOFT Software Engineering Notes, 2005,30(1):1-8 . |
| [41] | Su P, Cao C, Ma XX. Automated management of dynamic component dependency for runtime system reconfiguration. In: Proc. of the 2013 20th Asia-Pacific Software Engineering Conf. IEEE, 2013. 450-458 . |
| [6] | 贾治宇,康锐.软件可靠性预测的ARIMA方法研究.计算机工程与应用,2008,44(35):17-19. |
| [14] | 谢春丽,李必信,苏志勇.基于WSDG的Web服务组合可靠性预测.东南大学学报:自然科学版,2012,42(6):1074-1079. |
| [37] | 孙熙,庄磊,刘文,焦文品,梅宏.一种可定制的自主构件运行支撑框架.软件学报,2008,19(6):1340-1349.http://www.jos.org.cn/1000-9825/19/1340.htm |
| [39] | 马晓星,余萍,陶先平,吕建.一种面向服务的动态协同架构及其支撑平台.计算机学报,2005,28(4):467-477. |