 2015, Vol. 26
2015, Vol. 26



2. 新疆大学 信息科学与工程学院, 新疆 乌鲁木齐 830046;
3. 太原理工大学 计算机学院, 山西 太原 030021
2. School of Information Science and Engineering, Xinjiang University, Urumqi 830046, China;
3. School of Computer Science, Taiyuan University of Technology, Taiyuan 030021, China
同步数据流语言[1,2](例如Lustre[3],Signal等)广泛应用于工业界的核心安全级控制系统,如航空、核电等高安全等级的关键领域,与语言相关的软件的安全性也越来越受到人们的关注,特别是一些基础软件,如操作系统、编译器等.确认这些软件的安全可靠非常重要,同时,随着软件系统的复杂度的提高,软件的安全性保证也变得越来越困难,依靠传统的测试、代码审核和过程管控等方法来保证软件的安全性是远远不够的.近年来,形式化验证方法已成功地应用于可信编译器的实现中,CompCert[4,5]是其中的杰出代表.形式化验证方法从数学角度对软件系统进行描述,从逻辑上对软件系统的正确运行进行验证,能够充分地保证软件系统可信,可以最大程度地提高软件系统的可信度.
我们项目组基于形式化验证方法开展了一项从Lustre*语言到C子集Clight的可信翻译器的研究工作,称为L2C项目[6].图 1是该项目的整体框架.
 | Fig. 1 Current architecture of the trustworthy compiler L2C图 1 当前L2C项目的可信编译器总体结构 |
Lustre*是一种类Lustre[7]语言,它是以Lustre V6[8]的核心语言为基础,并加上一些类似于Scade[9, 10]的扩展. Lustre*语言中除了通常的算术和逻辑表达式之外,还包含了struct,list,switch和array等表达式,这些表达式的执行规则类似于C语言中的相应表达式.此外,Lustre*从Scade中继承了一些高阶运算和对于数组和结构体的操作.Clight[11]来源于CompCert项目,是一种兼容于关键嵌入式软件推荐使用的较大的C语言子集.
L2C项目的开发采用辅助证明工具Coq实现,集程序、性质和证明于一体,最终代码被抽取为Ocaml代码,与前端的Ocaml代码集成,得到完整编译过程的代码.通过图 1的最后一步,Lustre*源程序最终被翻译到CompCert项目的Clight AST,Clight语言的语法语义采用CompCert的定义.
同步数据流语言Lustre*与Clight相比有着巨大的差异,Lustre*具有时钟同步、数据流、并发及流数据对象等特征,而Clight则具有顺序控制流特征,语言跨度较大.直接进行翻译及证明将会非常复杂,因此,我们将项目分为多个层次,保证每个层次语法和语义跨度不大,每个层次完成特定的工作,比如时钟归一化[12]、拓扑排序[13]、时态算子消除[14]等工作.& lt; span style='font-family:宋体;color:black'>本文的研究工作高阶消去翻译及正确性证明,包含于如图 1所示的LustreT到LustreR层的Reducing过程中. 1Lustre*的高阶运算
Lustre*语言是一种同步数据流语言,主要用于设计实时的反应式系统,其主要应用领域有自动化控制以及信号处理系统等.Lustre*具有时钟特性,在Lustre*中,任何变量和表达式都代表着一个流(stream)数据,我们将一个流数据看作由两部分组成:一个给定类型的值序列和一个时钟.由于在Well-Typed Lustre* AST层到LustreS AST层的翻译过程中已进行了时钟归一化处理,所有数据流都统一到全局时钟,因此,在后续的翻译过程 中不再需要考虑时钟.
Lustre*语言作为一种同步数据流语言,在实际程序中也有控制流的需求,Lustre*中控制流可以直接从两个方面体现:一是进行周期控制,针对数据流的时钟特性,每个周期处理当前周期的数据;二是通过if表达式进行条件控制.然而,在面对数组的处理时,这两个方面都无能为力.因此,在Lustre*中增加丰富的高阶运算以满足数组处理的需求.
Lustre*中的高阶运算包括map和fold两类算子.map运算形式为:v1,...,vk=(map op áásizeññ)(a1,...,an),a1到an是n个输入数组,size为数组大小;op为一个操作或一个节点node或函数function调用,其输入参数为n个数组;v1到vk为输出的数组结果,例如:arr1=(map add áá10ññ)(arr2,arr3),则arr1[i]=arr2[i]+arr3[i],0≤i<10.
fold运算形式为acc=(fold op áásizeññ)(init,a1,...,an),a1~an是n个输入数组,size为数组大小,op为一个操作或一个函数调用function,其输入参数为n+1个参数:n个数组和一个acc的初值init,输入参数列表必须非空, acc[0]=init,acc[i+1]=op(acc[i],a1[i],…,an[i]),0≤i<size.
除了map,fold算子以外,Lustre*中支持的其他高阶算子还有mapi,foldi,mapfold,mapw,foldw,mapwi和foldwi等,简单介绍如下:
· mapi运算类似于map,只是其第1个输入不是由外部输入,而是取固定的数组[v0,v1,…].
· foldi运算类似于fold,只是其第1个输入数组为固定的数组[v0,v1,…].
· mapfold运算相当于map运算和fold运算的一个组合,即同时进行map和fold运算.
· mapw运算是一个条件迭代高阶运算,它的执行过程与map类似,但是当条件为false时终止执行,并记录终止时的数组索引.
· foldw也是一个条件迭代高阶运算,其执行过程与fold类似,但是当条件为false时停止执行,停止执行时的索引值记为一个整型值.
· mapwi运算类似于mapw只是其第1个输入不是由外部输入,而是取固定的数组[v0,v1,…].
· foldwi类似于foldw,只是其第1个输入数组a1是取固定的[v0,v1,…].
通过对高阶运算的介绍我们可以看出,高阶运算的特点很鲜明:以一个操作或函数调用为输入,使用map或fold等算子构成一个新的算子,作用在数组或参数列表上进行循环运算.这样的一种运算在C中并没有直接与之对应的操作,因此我们在翻译到Clight的过程中必须消去高阶运算,我们将这项工作集中在LustreT到LustreR层的翻译阶段完成.
基于高阶运算的特点,我们最终将高阶运算翻译到C语言中for循环语句中,采用for循环来实现高阶消去.因此,我们在LustreR层中定义一个类for的语句,称为Rfor语句.下面给出一个fold运算的Lustre代码以及高阶消去后的代码(如图 2所示).
 | Fig. 2 An example of fold program for eliminating high-order operation 图 2 高阶运算消去的fold程序示例 |
为了实现编译器的可信编译,人们提出了多种方法,主要有大量测试、人工代码审查以及开发过程的严格管控等,Scade通过严格的V&V过程管控实现了从Lustre到C的可靠翻译.然而,这些方法并不能够完全杜绝误编译的发生.形式化验证方法近年来成功地应用于可信编译器的构造中,编译器的形式化验证主要有两种方式:
· 一种是Pnueli等人[15]提出的翻译确认方法.它通过证明源代码和目标代码的语义等价性来验证编译器的正确性,不用对编译器自身进行验证,具有很好的可重用性,然而会有“虚报”的可能性.采用这种方法,Pnueli等人实现了对同步流语言Signal到C的翻译 过程的确认[16].
· 另一种是对编译器本身进行证明.经过严密的证明,可杜绝误编译的发生.CompCert编译器是其中的代表.CompCert将Clight到PowerPC汇编代码的编译过程划分为多个阶段,每个阶段独立地定义语法语义,完成特定的工作,并对每个阶段的翻译正确性进行证明,从而保证整个编译器的可信.对编译器本身进行验证是一种理想的方法,但其可重用性较差,因而开发成本较高,适用于为了安全性不惜代价的 领域.
我们借鉴CompCert的成功经验,采用对编译器本身进行证明的方法构造从Lustre*到C的可信编译器.据我们所知,目前仅有两个项目组规模性开展了类似的工作.除了本项目组以外,几年前,M. Pouzet和他的同事还启动了一项与我们目标相近的研究工作[17].目前,两个项目组都实现了相应的原型系统:M. Pouzet项目组在其最新的工作中完成了一个精简Lustre语言的经过验证的编译器[18];在L2C一期项目中,我们实现了一个单时钟的可信编译器原型[19].前者支持多时钟特征;后者根据项目甲方的需求,目前只支持统一的默认时钟(单一时钟).除了多时钟特征以外,后者还支持更大的Lustre子集.这两个可信编译器的设计框架完全不同,前者的许多核心翻译都集中在同一阶段,而后者分为多个阶段.相比之下,后者具有更好的可扩展性.根据我们的实践经验,这或许是扩展到实用语言编译器的必由之路.
目前,L2C项目已进入二期开发阶段.在二期工作中,我们将增加对数组和高阶运算以及其他在一期中未涉及的语言特征;同时,针对一期工作中的不足之处以及新的需求,对系统设计框架进行改进.
本文第3节介绍Lustre*高阶语法及语义.第4节介绍高阶消去的算法.第5节介绍高阶消去的证明.第6节介绍实现情况.第7节进行总结. 3Lustre*高阶语法及语义 3.1 高阶运算的语法
从Lustre*到Clight的整个翻译过程分为多个中间层次,每个中间层次都定义了各自的语法语义,相邻两层之间的语法语义较为接近,差异较大的部分很大程度上取决于当前翻译阶段的主体目标.例如,对于LustreT层到LustreR层的翻译阶段,我们定义了许多共有的语法元素,主要不同之处是:LustreT层有高阶运算;而在LustreR层,它将对应于循环语句.
一个LustreT/LustreR程序包括类型定义块、全局常量块以及节点/函数块(含一个主节点/函数).图 3描述了LustreT/LustreR程序的抽象语法.
 | Fig. 3 Abstract syntax of LustreT/LustreR program图 3 LustreT/LustreR程序的抽象语法 |
在LustreT/LustreR程序中,节点和函数的定义是一样的,二者的区别在于:node中有时态操作时需要的历史信息,而function中没有时态操作.节点/函数的抽象语法如图 4所示,其中,vars1为节点的输入参数列表,vars2为节点的输出参数列表,节点的body由语句列表组成.
 | Fig. 4 Abstract syntax of node/function图 4 节点/函数的抽象语法 |
stmt描述了等式(或语句)抽象语法,分别定义了赋值语句、节点调用语句及高阶运算语句,如图 5所示.表达式的抽象语法如图 6所示.hstmt的抽象语法如图 7所示.
 | Fig. 5 Abstract syntax of LustreT equation/statement图 5 LustreT等式/语句的抽象语法 |
 | Fig. 6 Abstract syntax of LustreT/LustreR expression图 6 LustreT/LustreR表达式的抽象语法 |
 | Fig. 7LustreT high-order operation syntax图 7 LustreT高阶运算语法 |
与LustreT层相比,LustreR层的语法中没有高阶语句Highorder和hstmt的定义,增加了Rfor语句,引入了显式的语句顺序复合算子seq以及skip语句,如图 8所示.
 | Fig. 8Abstract syntax of LustreR equation/statement 图 8 Lustre R层等式/语句的抽象语法 |
在介绍高阶运算的语义之前,首先对Lustre*语义环境和语义值进行介绍.Lustre*语义环境定义如下:
ge ::= (F,r) global environment
F ::= (id®fd) function map
r ::= (id,t)®v constant map
le ::= (id,t)®v local environment in current cycle
te ::= le* temporal environment
e ::= (te,id®e*) node environment
语义环境由全局环境(ge)和局部环境(e)组成,全局环境建立常量ID与相应的常量值和类型的映射,节点/函数ID与节点/函数定义之间的映射.
局部环境由3层构成:
· 当前周期的节点局部环境le:每个时钟周期每个节点实例都将生成一个局部环境le,建立当前周期下变量ID到变量值之间的映射关系.
· 时态环境te:Lustre*语言中,有pre,fby以及arrow等时态操作,在进行时态操作中,需要用到流数据的历史信息,因此,我们构造了时态环境te来记录每个节点实例的历史信息.一个节点实例的时态环境te是一个局部环境le列表,记录当前节点在所有时钟周期的执行情况,第n元素表示节点第n个时钟周期的le.
· 节点顶层环境e:一个节点实例的顶层环境e是一个复杂的树状结构,其数据域te维护了该节点实例中局部变量、输入和输出参量的历史取值,其每个子树本身又是新节点实例的顶层环境,第n个子树代表该节点中第n个调用的子节点实例的顶层环境.
Lustre*语义值包括整型值、浮点型值以及两个逻辑bool量,如图 9所示.
 | Fig. 9Semantic values图 9 语义值 |
基于以上的语义环境定义,我们有如下的基本执行规则:
· ge,lesexprÞv:在全局环境ge和当前周期的节点局部环境le中,执行表达式sexpr得到值v.
· ge,te(expr,t)Þv:在全局环境ge和时态环境te中,执行表达式expr得到值v.
· ge(e,fd,vargs)Þ(e¢,vrets):在全局环境ge中,输入参数列表为vargs的节点fd执行后返回值列表vrets,
局部环境由e变为e¢.
· ge(e,stmts)Þe¢:在全局环境ge中,执行等式/语句列表stmts,局部环境由e变为e¢.
· ge(e,vass,prog,n,maxn)Þvrss:在全局环境ge中,程序prog从第n周期到maxn周期周期性地执行,
vass和vrss分别为输入和输出流.
我们基于以上基本执行规则定义大步操作语义,限于篇幅,我们只列举一些典型的语义规则(均适用于LustreT和LustreR).
表达式sexpr的语义执行规则:

注:L2C项目中,采用整型值作为变量id,所有变量id进行统一管理,并区分为不同类别.vclassify(id)获取id的类别,Lid意为id用于节点内部,Gid意为id是一个全局常量的标识符.

注:sem_binary_operation是用于二元操作binop的语义函数.
赋值语句assign语义执行规则:
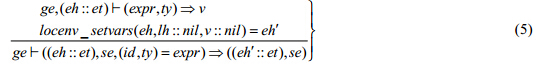
locenv_setvars(eh,vass,vrss)=eh¢意为在当前周期的节点局部环境eh中,用值列表vrss修改变量列表vars中所有变量的值,当前周期的局部环境变为eh¢,vars和vrss具有相同的列表长度. 3.3.2 LustreT层高阶运算语义
高阶运算是一个对数组或输入参数列表进行循环计算的过程,前面已经阐述过,针对高阶运算的这一特点,我们的高阶消去算法实现为将LustreT层的高阶运算翻译为LustreR层的Rfor语句.循环运算分3种状态进行归纳定义:初始状态、循环处理状态以及循环终止状态.我们在定义LustreT层的高阶运算的语义时,抽象地将其构造成3种形态:高阶初始状态、高阶运算主体以及高阶运算终止状态,分别对应于Rfor循环的初始状态、循环处理状态以及循环终止状态.这样的语义定义有利于证明过程中进行归纳证明.
LustreT层高阶运算的eval_Highorder_start语义规则:

eval_Highorder_start的语义规则为:在全局环境ge中,将循环变量loopid赋值0,局部环境由e变为e1. initstmtsof(hstmt)表示从高阶运算表达式hstmt中解析出高阶运算的初始化操作,局部环境由e1变为e2;接着执行完 高阶语句,局部环境由e2变为e3.
LustreT层高阶运算的eval_Highorder_stop语义规则:

loopid<j为条件表达式,j为数组上界.eval_Highorder_stop语义执行规则为:当在全局环境ge和局部环境eh下,如果loopid<j为Vfalse,则高阶运算终止,在高阶运算终止计算中不改变节点的局部环境.以图 2中fold程序为例,当loopid<5为Vfalse时,高阶运算终止.
LustreT层高阶运算的eval_Highorder_body语义规则:

eval_Highorder_body语义的执行规则为:当loopid<j为Vtrue时执行高阶运算,eval_htmt语义函数表示计算高阶表达式hstmt,局部环境变为e1;然后执行增量语句loop_add,局部环境变为e2;继续执行完高阶语句,局部环境 由e2变为e3.
eval_htmt(hstmt,loopid)的执行语义将归纳于hstmt的具体高阶算子进行定义,限于篇幅,我们不列举对应于所有这些高阶算子的语义规则,而是代表性地展示其中几条:
· 对应于mapbinary算子的语义规则:

mapbinary运算功能为对两个数组中所有元素执行二元操作,返回一个执行结果数组.mapbinary的语义执行规则为:首先,计算当前数组元素的索引i;然后,通过aryacc运算取出数组a1和a2中第i个元素,并进行二元运算得到值v;最后,通过locenv_setlvar在局部环境eh中将值v赋予一个新的数组中第i个元素,局部环境变为eh1.
· 对应于foldbinary算子的语义规则:

foldbinary运算功能为对一个数组和一个初值进行折叠处理,返回一个处理结果.foldbinary的语义执行规则为:对变量v和数组a1中第i个元素进行二元操作,并将操作结果赋于变量v,节点局部环境变为e1.
· 对应于mapcall算子的语义规则:

mapcall运算功能为调用节点对参数列表进行处理,返回一个结果列表.locenv_getarys(eh,args)=vargs意为从当前周期的局部环境eh中获取变量列表args的值列表vargs,call_env(fd,id2,se,se1,ef,ef¢)意为调用节点fd时,实例id2对应的子环境由se变为se1,局部环境由ef变为ef¢.mapcall的语义执行规则为:从全局环境中通过节点id1找到对应的节点定义fd,从局部环境eh中获取输入参数变量列表的取值vargs,调用节点对输入参数列表的取值进行处理,局部环境由ef变为ef¢,得到输出值列表vres.最后通过locenv_setarys在当前周期的局部环境eh中将vres赋于变量列表lhs,当前周期的局部环境变为eh1.
以上述3个高阶算子语义规则为参照,对LustreT层其他高阶算子语义规则简要概括介绍如下:
· mapbinaryi:语义与mapbinary语义类似,区别在于二元运算的第1个参数不是数组a1中的元素,而是当前loopid值;
· mapunary:语义与mapbinary语义类似,区别在于输入为一个数组a1,操作算子为一元操作.
· mapunaryi:语义与mapunary语义类似,区别在于输入为当前loopid值.
· foldbinaryi:语义与foldbinary语义类似,区别在于输入为当前loopid值.
· foldcall:语义规则为在foldbinary语义的基础上,以函数调用call的语义代替二元运算的语义,构成foldcall的语义规则.
· mapcallw:mapcallw在mapcall的运算中增加了一个bool变量mapwid,当mapwid为Vtrue时,其后续执行规则与mapcall相同;当为Vfalse时,其语义规则为

· foldcallw:foldcallw在foldcall的运算中增加了一个bool变量mapwid,当mapwid为Vtrue时,其后续执行规则与foldcall相同;当为Vfalse时,其语义规则为

· mapcalli:语义与mapcall语义类似,区别在于节点计算时第1个输入参数为当前列表索引,在语义规
则中表示如下:mapcall为ge(ef,fd,vargs)Þ(ef¢,vrets),mapcalli为ge(ef,fd,(i::vargs))Þ(ef¢,vrets).
· foldcalli:语义与foldcall语义类似,区别在于节点计算时第1个输入参数为当前列表索引,在语义规
则中表示如下:mapcall为ge(ef,fd,(v::vargs))Þ(ef¢,(vrets::nil)),foldcalli为ge(ef,fd,(i::v::vargs))Þ(ef¢,
(vrets::nil)).
· mapcallwi:语义与mapcallw语义类似,这二者的区别与mapcalli和mapcall的区别相同.
· foldcallwi:语义与foldcallw语义类似,这二者的区别与foldcalli和foldcall的区别相同.
· mapfoldcall:mapfoldcall的作用相当于mapcall和foldcall的一个综合体,其语义也是这二者的一个综合体.
高阶运算具有复杂的语义,其复杂之处主要在于环境变化的复杂性,每次计算都会引起局部环境的变化.当经过高阶消去翻译到LustreR层时,如何体现这种环境的变化以及如何证明这两层间环境的匹配是主要的难点. 3.3.3 LustreR层循环语义
LustreT层高阶运算经过高阶消去后翻译到LustreR层,对应的是Rfor语句,Rfor语句包括3种状态,分别是Rfor初始状态、Rfor循环状态以及Rfor终止状态.
在介绍Rfor语义规则之前,先介绍LustreR层另外两个语句skip和seq的语义规则:
· skip语句的语义规则:

· seq语句的语义规则:

skip语句的语义执行规则为:在局部环境e中执行语句skip,局部环境不变.seq语句的语义执行规则为:如果在全局环境ge中执行语句s1后,局部环境由e变为e1,执行语句s2后局部环境由e1变为e2,则在局部环境e中执行语句seq s1 s2后,局部环境变为e2.
LustreR层Rfor语句的eval_Rfor_start语义规则:

eval_Rfor_start的语义规则为:在全局环境ge中,从局部环境e中计算置初值语句a1,局部环境变为e1;接着执行完整个Rfor语句,局部环境变为e2.
LustreR层Rfor语句的eval_Rfor_stop语义规则:
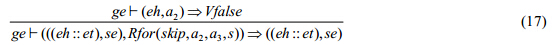
eval_Rfor_stop的语义规则为:在全局环境ge中,在局部环境eh中计算循环控制表达式a2为Vfalse,则结束处理.
LustreR层Rfor语句的eval_Rfor_loop语义规则:

eval_Rfor_loop的语义规则为:在全局环境ge中,在局部环境eh中计算循环控制表达式a2为Vtrue.在环境((eh::et),se)等式/语句s,局部环境变为e1.在局部环境e1中计算语句&l t;/ span>a3,局部环境变为e2.处理完毕后,在局部环境e2中继续执行完整个Rfor语句,局部环境变为e3. 4 高阶消去翻译
如上所述,鉴于高阶运算的特点,我们将LustreT层高阶运算翻译为LustreR层Rfor循环运算,从而实现高阶消去.Rfor语句的语法为Rfor(stmt1,expr,stmt2,stmt3),其中,stmt1为置初值语句,stmt2为增量语句,stmt3为主循环体,expr为循环条件表达式.根据Rfor的语法语义定义,我们需要从高阶语句hstmt中分别提取出这4个部分.我们以图 2中的fold程序为例阐述整个翻译算法(代码片段为辅助定理工具Coq[12]中编写的代码段).
· 置初值语句
在从高价语句中翻译置初值语句时,map运算与fold运算有所不同:
Ø map运算的初始状态为循环变量loopid的初值,定义为
Definition loop_init:=assign(loopid,Tint32)((Cint Int.zero),Tint32).
即,初始状态为循环变量loopid=0,
Ø 而fold运算除此之外,还必包含一个输入的初始值,需要从高阶运算表达式中提取:
Definition trans_finit(s:hstmt):stmt:=
match swith
|Foldbinary lh op init aÞassign lhinit
|…
注:|…表示当前定义还包括对s的其他构造子的相应处理,限于篇幅,在此不再详述,下同.
assign lhinit意为将初值init赋于变量lh.
因此,fold运算完整的初始状态为
init:=seq loop_init(trans_finit htmt).
· 循环条件表达式
对于高阶运算,其循环条件表达式为判断loopid是否小于数组长度,因此定义为
Definition loop_cond:=binop Olt(loopid,Tint32)((Cint j),Tint32) Tbool.
意为loop_cond(j):=loopid<j.
例如,图 2中fold程序的条件语句为loop_cond(5):=loopid<5.
· 增量语句:
高阶运算的增量语句是数组或参数列表的索引loopid每进行一次运算就加1,因此,增量语句定义为
Definition loop_add:=assign(loopid,Tint32)(binop Oadd(loopid,Tint32)((Cint Int.one),Tint32)Tint32).
意为loop_add:=loopid=loopid+1.
· 主循环体
foldbinary运算是对数组进行折叠运算最终生成一个单值,因此,foldbinary的翻译函数为
aryacc表达式为获取数组a中第loopid个元素,将该值与变量lh进行二元操作op,得到结果es,将结果es赋予变量lh.
综上所述,高阶消去翻译函数为
Definition trans_stmt(s:LustreT.stmt):res stmt:=
|Highorder fs jÞ
do fs1¬trans_hstmt fs;
let init:=seq loop_init(trans_finit fs) in
OK (Rfor init(loop_cond j) loop_add fs1). 5 高阶消去翻译证明 5.1 高阶消去翻译的证明框架
正如语法语义的定义采用的是一种层次结构,证明工作相应的也是一个层次化归纳的证明过程.整个证明框架如图 10所示.
 | Fig. 10 Hierarchy figure of proving图 10 证明层次图 |
因此,我们提出了如下定理:
程序翻译正确性定理. exec_prog_correct_general(从LustreT到LustreR程序的语义等价性):

其中,
· progT为LustreT层程序;
· progR为经过progT翻译到LustreR层的程序;
· mainT为程序progT的的主节点;
· mainR为节点mainT翻译到LustreR层的节点;
· trans_node函数将节点mainT翻译到LustreR层得到节点mainR;
· eval_nodeT和eval_nodeR分别为LustreT层和LustreR层的节点计算函数.
该定理语义等价性的含义是:如果程序progT在全局环境ge下对输入实参流vass的执行结果为流vrss,那么progR在全局环境ge下对输入实参流vass的执行结果同样是流vrss,且progT和progR中的局部环境e在n个周期中始终保持匹配关系.
LustreT层中的程序执行函数exec_progT和LustreR层的程序执行函数exec_progR二者的执行过程是相似的,可以理解为周期性主节点的串行执行过程,因此,程序执行的等价性可以转化为节点执行的环境匹配问题,也即节点翻译正确性问题,所以我们需要证明如下定理:
节点翻译正确性定理. trans_node_all_correct(从LustreT到LustreR节点的语义等价性):

该定理语义等价性的含义是:nodeT经过节点翻译函数trans_node翻译到LustreR层得到节点nodeR,如果节点nodeT在全局环境ge下对输入实参流vargs的执行结果为流vrets,局部环境由e变为e¢,那么nodeR在全局环境ge下对输入实参流vargs的执行结果同样为流vrets,局部环境由e变为e¢.
eval_nodeT和eval_nodeR分别为LustreT层和LustreR层的节点计算函数,二者的执行过程是相似的.节点执行的过程是节点中表达式串行化执行过程,因此,节点执行的等价性可以转换为相应语句stmt执行的环境匹配问题.
stmt采用归纳定义,我们根据stmt的语义定义进行归纳证明.
按照stmt的构造子的不同,证明目标细分为普通语句、高阶运算以及节点调用这3个子目标分别进行证明.
这些子目标的语义保持性都可以描述为:翻译前后的程序语句执行时,对语义环境的改变是一致的.不同语句的程序等价性的表述形式有所不同,本文重点讨论高阶运算语句的语义等价性. 5.2 高阶消去翻译的语义等价性证明
翻译正确性的证明也就是对翻译前后程序的语义等价性的证明,如果翻译前后的程序语义是等价的,则翻译过程是正确的.因此,基于前面描述的语法语义,我们对高阶消去前的LustreT程序与高阶消去后的LustreR程序的语义等价性进行证明.
结合前面语义的描述,语义等价性的证明归结起来本质上是在同一全局环境下,高阶消去前后的程序对环境的改变是匹配的,包括时态环境以及相应节点实例的局部环境.
由前面介绍的语义及翻译算法可知,LustreT层的高阶运算表达式翻译到LustreR层时将分成3个部分:初始状态、主循环体以及循环终止状态.因此,结合语义的定义,我们给出了如下的高阶消去正确性定理:
高阶消去正确性定理. 在任意全局环境ge中,如果满足以下条件,则高阶消去前后的程序是语义等价的:
· geeval_Highorder_start(e1,e2)~eval_Rfor_start(e1,e2);
· geeval_Highorder_body(e1,e2)~eval_Rfor_loop(e1,e2);
· geeval_Highorder_stop~eval_Rfor_stop.
符号“~”表示左右两个目标等价.例如,程序p1和p2语义等价,写作p1~p2.
相应地,该定理的证明从这3个部分进行归纳证明:
在介绍这3部分证明之前,先介绍3个引理:
赋值等价引理. 在任意全局环境ge中,LustreT层和LustreR层的赋值语句是等价的:
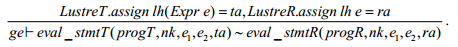
初值等价引理. 在任意全局环境ge中,LustreT层和LustreR层的循环初始值是等价的:
geeval_stmtT(progT,nk,e1,e2,LustreT.loop_init)~eval_stmtR(progR,nk,e1,e2,LustreR.loop_init).
循环增量等价引理. 在任意全局环境ge中,LustreT层和LustreR层的循环增量是等价的:
geeval_stmtT(progT,nk,e1,e2,LustreT.loop_add)~eval_stmtR(progR,nk,e1,e2,LustreR.loop_add).
eval_stmtT为LustreT中表达式计算的语义,eval_stmtR为LustreR层中表达式计算的语义.应用前面定义的语义执行规则和Coq证明策略,可以轻易地证明以上3条引理.以引理1的证明为例,其证明思路如下:
假设在LustreT层中,在全局环境ge和局部环境e1下,LustreT层程序progT翻译到LustreR层为程序progR.我们引入条件H:
eval_stmts(progT,nk,e1,e2,ta).
意为执行progT程序中的赋值语句ta后,局部环境变为e2.对条件H进行连续的逆向展开,条件H变为:将变量var的值v存入局部环境eh中,局部环境变为eh¢.然后,对证明目标应用assign语义规则,证明目标变为当设置变量var的值为v时,局部环境由eh变为eh¢.此时,应用条件H及环境的构造子即可完成证明. 5.2.1 初始状态的证明
将初始状态的等价性进行展开,我们需要证明如下引理:
引理trans_finit_correct. 在任意全局环境ge中,LustreT层程序progT翻译到LustreR层为程序progR,任意高阶运算表达式s在程序progT中计算初值时局部环境由e1变为e2,那么表达式s在progR中计算初值时局部环境也是由e1变为e2,即,翻译前后程序对局部环境的改变是匹配的:
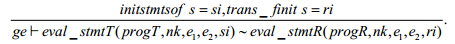
其中,si为从语句s中提取的LustreT层计算初值的语句,ri为将语句s翻译到LustreR层后计算初值的语句, eval_stmtT和eval_stmtR对LustreT层和LustreR的语句进行计算.initstmtsof,trans_finit分别为LustreT层和LustreR层求初值函数,二者的定义是:initstmtsof为assign lh(init)::nil,trans_finit为assign lh init.我们以图 2中的fold程序证明为例介绍整个证明思路.
证明思路是:首先对高阶表达式s进行分解,同时,采用initstmtsof和trans_finit的定义进行化简,证明目标细分为9个子目标(注:虽然高阶表达式s有16个构造子,但map运算如mapbinary等其初值只是循环变量loopid=0,并不经过trans_finit处理,所以化简后直接排除了mapbinary等7个构造子).fold高阶运算为其中的foldbinary构造子化简所得的子目标.对该子目标进行证明:对条件H:eval_stmtT(progT,nk,e1,e2,si)进行连续的逆向展开,此时的证明目标与赋值等价引理相同,应用此引理即可完成证明.
其他高阶运算的证明思路类似.
高阶运算初始状态的证明为
geeval_Highorder_start(e1,e2)~eval_Rfor_start(e1,e2).
借助于引理trans_finit_correct,证明即可轻松完成,证明思路是:
假设在全局环境ge中,有条件eval_Highorder_start(e1,e2),我们应用eval_Highorder_start和eval_Rfor_start的语义规则进行展开,然后应用引理trans_finit_correct即可完成证明. 5.2.2 循环体的证明
循环体的证明包括两部分:
· 一是eval_Highorder_body和eval_Rfor_loop的语义等价性;
· 二是LustreT层和LustreR层的循环增量的等价性.
后者应用循环增量等价引理可证;第1项的证明稍显复杂,仍以图 2中fold程序为例阐述整个证明思路.
证明思路:先分别将eval_Highorder_body和eval_Rfor_loop按语义展开后,根据高阶运算的归纳定义,原证明目标依照各高阶运算表达式构造子被细分为多个证明子目标,这些子目标为各构造子翻译的正确性证明.此处我们证明foldbinary构造子对应的子目标:
ge(e1,e2,progT,eval_hstmt((lid,ty)=foldbinary op v a1,loopid))~(e1,e2,progR,eval_stmt(texp,loopid)).
progR为progT翻译到LustreR层的程序,rexp是高阶语句(lid,ty)=foldbinary op v a1经过高阶消去后翻译到LustreR层所得的表达式.
上式的含义是:在全局环境ge中,如果执行程序progT中高阶语句后,局部环境由e1变为e2,那么执行程序progR中相应的表达式rexp后,局部环境也将由e1变为e2.
依据前面介绍的高阶翻译函数trans_hstmt的定义,在全局环境ge中,存在条件H:
trans_hstmt((lid,ty)=foldbinary op v a1)=texp.
我们在证明目标中,将rexp通过条件H和翻译函数trans_hstmt的定义进行逆向展开,目标将变为R层的一个数组赋值表达式计算,此时,应用赋值等价引理即可完成证明. 5.2.3 终止状态的证明
终止状态的证明是直接可得的,直接运用eval_Highorder_stop和eval_Rfor_stop的语义规则进行展开,即可完成证明. 6 实现情况
高阶消去工作是整个L2C项目中的一个重要组成部分,程序的语法语义定义、算法实现以及证明工作都采用辅助定理工具Coq实现,整个工作大约4 500行代码,其中,
· 基本框架部分约1 600行代码,包括约700行定义、78个定理约900行代码.
· 高阶消去的语义部分约1 400行代码,包括语法定义300行、语义定义600行、31个定理约500行.
· 翻译算法部分约400行代码,包括算法实现300行、8个定理约100行.
· 证明部分约1 100行,包含45个定理或引理.
表 1展示了整个代码情况.
| Table 1 表 1 |
本文介绍了Lustre*到C子集Clight编译中高阶运算消去的翻译算法,并对算法正确性进行了形式化证明.虽然Lustre*与Clight之间有着巨大的语言差异,然而在L2C项目合理的框架下,高阶消去集中在LustreT层到LustreR层的翻译中,两层之间的语法语义差异较小,这给我们的整个翻译算法以及证明工作带来了极大的好处,良好的语义定义大幅度减轻了证明的难度.然而,高阶运算本身是比较复杂的,这项工作的难度也是显而易见的,需要细致、扎实的工作,语法、语义以及定理的定义也需要一定的技巧,目标是简洁、易理解以及有利于归纳和证明.本文的工作得益于L2C可信编译器框架已有较长时间处于稳定状态.本文的工作将随L2C编译器得到实际应用.
致谢 在此,我们向对L2C项目组所有成员表示感谢.| [1] | Halbwachs N. A synchronous language at work: The story of Lustre. In: Proc. of the 2nd ACM/IEEE Int'l Conf. on Formal Methods and Models for Co-Design (MEMOCODE 2005). IEEE Computer Society Washington, 2005.[doi: 10.1109/MEMCOD. 2005.1487884] |
| [2] | Benveniste A, Caspi P, Edwards SA, Halbwachs N, Le Guernic P, de Simone R. The synchronous languages twelve years later. Proc. of the IEEE, 2003,91(1):64-83.[doi: 10.1109/JPROC.2002.805826] |
| [3] | Caspi P, Pilaud D, Halbwachs N, Plaice J. Lustre: A declarative language for programming synchronous systems. In: Proc. of the 14th ACM Symp. on Principles of Programming Languages (POPL'87). 1987. |
| [4] | CompCert home page. http://compcert.inria.fr/ |
| [5] | Xavier Leroy. Formal verification of a realistic compiler. Communications of the ACM—CACM,2009,52(7):107-115.[doi: 10. 1145/1538788.1538814] |
| [6] | Blazy S, Leroy X. Mechanized semantics for the Clight subset of the C language. Journal of Automated Reasoning, 2009,43(3): 263-288.[doi: 10.1007/s10817-009-9148-3]. |
| [7] | Halbwachs N, Caspi P, Raymond P, Pilaud D. The synchronous dataflow programming language LUSTRE. Proc. of the IEEE, 1991, 79(9):1305-1320. |
| [8] | Lustre V6. The lustre v6 reference manual (draft). 2009. http://wwwverimag.imag.fr/DISTTOOLS/SYNCHRONE/Lustre-v6/doc/ lv6-refman.pdf |
| [9] | Paulin C, Pouzet M. Certified compilation of scade/lustre. 2006. http://www.lri.fr/paulin/lustreincoq.pdf |
| [10] | Le Sergent T. SCADE: A comprehensive framework for critical system and software engineering. In: Proc. of the Intergrating System and Software Modeling. LNCS 7083, Berlin, Herdelberg: Springer-Verlag, 2012. 2-3. |
| [11] | Ngo VC, Talpin JP, Gautier T, Le Guernic P, Besnard L. Formal verification of synchronous data-flow compilers. Project-Team ESPRESSO Research Report, No.7921. 2012. |
| [12] | The Coq Development Team. The Coq proof assistant reference manual version V8.3. 2010. http://coq.inria.fr/ |
| [13] | Shi G, Wang SY, Dong Y, Ji ZY, Gan YK, Zhang LB, Zhang YC, Wang L, Yang F. Construction for the trustworthy compiler of a synchronous data-flow language. Ruan Jian Xue Bao/Journal of Software, 2014,25(2):341-356 (in Chinese with English abstract). http://www.jos.org.cn/1000-9825/4542.htm[doi: 10.13328/j.cnki.jos.004542] |
| [14] | Gan YK, Zhang LB, Shi G, Wang SY, Dong Y, Zhang ZH, Wang YH. A verified sequentializer for synchronous data-flow programs. Computer Applications and Software, 2014,31(5):1-6. |
| [15] | Pnueli A, Siegel M, Singerman E. Translation validation. In: Proc. of the TACAS'98. LNCS 1384, 1998. |
| [16] | Pnueli A, Shtrichman O, Siegel M. Translation validation for synchronous languages. In: Proc. of the ICALP'98. LNCS 1443, 1998. 235C246. |
| [17] | Biernacki D, Cola_co JL, Hamon G, Pouzet M. Clock-Directed modular code generation for synchronous data-flow languages. In: Proc. of the LCTES. 2008. 121-30.[doi: 10.1145/1375657.1375674] |
| [18] | Auger C, Cola_co JL, Hamon G, Pouzet M. A formalization and proof of a modular lustre compiler. 2012. http://www.di.ens.fr/ pouzet/cours/mpri/cours4/scp12.pdf |
| [19] | Zhang LB, Gan YK, Shi G, Wang SY, Dong Y, Zhang ZH, Wang YH. A certified translation for eliminating temporal feature of a synchronize dataflow program. Computer Engineering and Design, 2014,35(1):137-143. |