 2015, Vol. 26
2015, Vol. 26



2. 软件工程国家重点实验室(武汉大学), 湖北 武汉 430072;
3. 西北农林科技大学 信息工程学院, 陕西 杨凌 712100
2. State Key Laboratory of Software Engineering (Wuhan University), Wuhan 430072, China;
3. College of Information Engineering, Northwest A & F University, Yangling 712100, China
在过去几十年间,生物度量在诸如监控、人机接口、司法和安全标识等许多领域扮演着非常重要的角色[1].生物度量识别是一种自动进行个体识别的方法,它通过比较生物体的生理或行为特性来进行识别,这些生理或行为特性往往被转换成一个特征向量.生理特性主要包括人脸、指纹、掌纹、手指形状、手掌形状、虹膜、视网膜以及声音等[2].人脸图像可以通过廉价的照相设备在一定的距离之外方便地获取,它不需要用户的主动参与,也没有任何健康风险[3].因此,人脸识别系统往往更容易被用户接受,并且得到了研究人员的持续关注.
常用的方法有主成分分析(principal component analysis,简称PCA)[4]、独立成分分析(independent component analysis,简称ICA)[5]、线性判别分析linear discriminant analysis,简称LDA)[6]、二维主成分分析(two- dimensional principal component analysis,简称2DPCA)[7]、等度规特征映射(isometric feature mapping,简称ISOMAP)[8]、局部线性嵌入(local linear embedding,简称LLE)[9]、局部保持投影(locality preserving projections,简称LPP)[10]、近邻保持嵌入(neighborhood preserving embedding,简称NPE)[11]、边界费舍尔分析(marginal fisher analysis,简称MFA)[12]、拉普拉斯核维数约简方法(Laplacian kernel dimensionality reduction method,简称LK- RDRM)[13]、梯度方向与欧拉映射(gradient orientations and Euler mapping,简称GOGM)[14]、拉普拉斯特征值映射(Laplacian eigenmaps,简称LE)[15]等.基于局部的表示方法主要从图像的局部块进行考虑,提取的是局部特征,常见的方法有Gabor特征[16]、局部二进制模式((local binary pattern,简称LBP)[17]、局部三进制模式(local ternary pattern,简称LTP)[18]、局部Gabor二进制模式(local Gabor binary pattern,简称LGBP[19]、中心对称局部二进制模式(center-symmetric local binary pattern ,简称CS-LBP)[20]、Gabor体局部二进制模式(Gabor volume local binary pattern,简称GV-LBP[21]、局部方向模式(local directional pattern,简称LDP)[22]和增强局部方向模式(enhanced local directional patterns,简称ELDP)[23]等.一般地,全局表示方法对光照、姿态、表情以及遮挡等复杂变化比较敏感.越来越多的研究表明:局部表示方法由于刻画了局部更细节的纹理信息,对光照、姿态、表情以及遮挡等复杂变化往往表现得更为鲁棒[19, 21, 22,23].为了提高全局特征对光照、姿态、表情及遮挡等复杂变化的鲁棒性,文献[24]提出了一类基于图像梯度方向的子空间学习方法(image gradient orientations,简称IGO).IGO方法首先把图像转换为梯度图像,然后在梯度空间[25]上进行全局维数约简.梯度图像更多地考虑了局部像素之间的关系,本质上是在获取图像的局部结构信息.与直接在图像强度值上处理相比,梯度图像的计算可以获得更好的鲁棒性,但是在遮挡处理方面,IGO方法仍然未能达到理想的效果.
LBP[17]作为一种简单而有效的局部人脸表示方法,已经引起众多研究人员的注意.LBP主要被用在人脸识别和纹理分析上,它依据中心像素和其邻域像素之差的正负来进行二进制编码,具有旋转不变性.它对单调光照变化比较鲁棒,但对非单调光照变化和随机噪声比较敏感.Jabid等人[22]提出一种基于局部方向模式(LDP)的更鲁棒的人脸特征表示方法.针对某个中心像素,LDP表示方法并不直接比较中心像素和相邻像素的强度值,而是通过8个Krisch掩模,在某个邻域内为中心像素计算8个方向的边缘响应值,然后把绝对值最大的k个边缘响应值所对应的二进制位设置为1,剩下的8-k个二进制位设置为0.Zhong等人[23]提出一种基于ELDP的人脸表示方法,ELDP只是考虑最强和次强的边缘响应值,它对边缘响应值的选取主要考虑边缘响应值的方向性,它把值最大和次大的边缘响应值(不考虑绝对值)所对应的位置,通过8进制方式进行编码.与稀疏采样的LBP相比,LDP和ELDP实质是对局部邻域的稠密采样.从统计观点看,稀疏采样会丢失更多的邻域信息,降低方法的正确性,而Kirsch掩模的采用会获得更鲁棒的效果.因此当有噪声存在时,LDP和ELDP会比LBP表现得更稳定.ELDP只对最大和次大的边缘响应值进行编码,编码结构更加简单.此外,与LDP相比,ELDP考虑了边缘响应值的方向性.尽管LDP和ELDP采用稠密采样,获取了更多的邻域信息,但它们对遮挡情况仍然比较敏感.
本文提出一种基于差值局部方向模式(difference local directional pattern,简称DLDP)的人脸表示方法.LDP和ELDP通过8个Kirsch掩模和图像的卷积结果进行编码,一个重要的问题是,LDP和ELDP并没有考虑近邻边缘响应值之间的强度变化.通常,强度变化越大,往往表示两个方向之间存在的边缘特征或对角线特征越突出.DLDP通过计算近邻边缘响应值之间的强度变化,本质上是在获取方向之间更丰富的细节特征.强度变化越大,往往表示两个方向之间的细节特征越突出,更突出的细节特征往往具有更强的判别力.另一个重要的问题是:LDP和ELDP受到原始Kirsch掩模的制约,只考虑3x3掩模,传统的高分辨率Kirsch掩模只是单纯考虑方向性(如在正东方向上,所有元素都设置为1),并没有考虑不同像素位置的权重.通常认为,距离参照点越近的权重越大,距离参照点越远的权重越小.通过分析3x3的Kirsch掩模所蕴含的约束机制,提出高分辨率Kirsch掩模的权值设计方法.此外,LDP和ELDP主要考虑在强度空间上进行编码,DLDP将在梯度空间进行编码.显然,梯度空间比强度空间包含更多的信息.比如,梯度空间可以保留像素之间的内在关系,而强度空间则不能.梯度空间保留这些内在关系,实质上揭示了图像的潜在结构信息,而这些结构信息往往具有更强的判别性.为了保证梯度计算更稳定,DLDP首先使用高斯方法平滑图像.高斯平滑可以减弱噪声的影响,而梯度空间的计算会使DLDP对光照变化更鲁棒.实验结果显示:DLDP在光照、表情、姿态和遮挡方面获取了较好的结果,尤其针对遮挡情况, DLDP表现更为突出.
本文第1节介绍相关研究.第2节提出相应的DLDP方法.第3节进行Kirsch掩模分析与加权设计.第4节描述相应的人脸表示与识别方法.实验结果与分析展示在第5节.最后,在第6节进行总结.
1 相关研究 1.1 LBPLBP[17]主要依据中心像素与其邻居像素之差的正负来进行二进制编码.针对图像中的每个像素,在以该像素为中心的一个局部邻域内,通过比较相邻像素和中心像素的大小来对中心像素进行二进制编码.当邻域像素与中心像素的差值为正值或为0时,相应的二进制位被编码为1;而当邻居像素与中心像素的差值为负值时,相应的二进制位被编码为0.
图 1展示了一个3x3的图像块中,像素的坐标位置及其对应的像素强度值.中心像素(xc,yc)一共有P(=8)个局部邻居像素,中心像素的强度值为gc,所有局部邻居像素的强度值分别为{g0,g1,…,g7}.LBP的具体编码方法如下:
| $LB{P_{P,R}}({x_c},{y_c}) = \sum\limits_{i = 0}^{P - 1} {s(g{}_i - {g_c})} {2^i},s(x) = \left\{ {\begin{array}{*{20}{l}} {1,}&{x \ge 0}\\ {0,}&{x < 0} \end{array}} \right.$ | (1) |

|
Fig. 1 Pixel coordinates and intensity values in a 3x3 image patch 图 1 3x3图像块中的像素坐标及强度值 |
这里,gc表示中心像素的强度值,gp表示以中心像素为圆心、半径为R的圆上的P个邻居像素的强度值.
利用公式(1)可以为每个像素获得一个8位的二进制编码(在3x3邻域内),因此,最多可以获得128(28)种计算结果,也就是常说的128种模式.但Ojala等人[26]观察到:在大量图像的编码中,只有有限的模式会频繁地出现,这些模式被称作uniform LBP.可以把二进制编码看作一个循环数据位序列,这些统一模式具有一个共同的特点,即,在循环序列中,相邻数据位从0到1或从1到0的变化次数最少.一般把变化次数小于等于2的模式称作uniform LBP,这样的模式一共有58种.为了充分利用所有出现的模式,LBP编码中往往把剩余的70(128-58)种模式当作一种单独的模式,因此在LBP算法中,用到的模式总共有59种.尽管LBP在纹理分析和人脸识别上已经取得了极大的成功,但LBP仍然对对非单调光照变化和随机噪声比较敏感.
1.2 LDP局部方向模式(LDP)[22]也为图像的每个像素分配一个8位二进制编码,它主要通过比较某个像素在不同方向上的边缘响应值(edge response value,简称erv)来获取模式.LDP通过Kirsch掩模为中心像素计算8个不同的方向响应值.图 2展示了8个不同方向的Kirsch掩模Mi,i=0,1,…,7.8个Kirsch掩模分别表示8个方向所对应的8条边,东向、西向、南向和北向分别对应直线边,东北向、西北向、西南向和东南向分别对应折线边.应用8个掩模对图像块进行卷积运算,我们可以获得中心像素的8个边缘响应值ERV={erv0,erv1,…,erv7},计算方法见公式(2):
| $er{v_i} = {I^ * }{M_i}$ | (2) |

|
Fig. 2 Kirsch edge response masks in eight directions (3x3) 图 2 在8个方向上的Kirsch边缘响应掩模(3x3) |
这里,*表示卷积运算,I表示输入图像,Mi表示第i个掩模,ervi表示第i个边缘响应值.
每个边缘响应值分别体现了在不同方向上边的重要性,在所有方向上的边缘响应值的重要性并不等同. LDP模式主要寻找前k个最大的反应值的绝对值,并把相应方向的二进制编码值设置为1,而其他的(8-k)个方向设置为0.具体编码方法见公式(3):
| $LDP({x_c},{y_c}) = \sum\limits_{i = 0}^7 {s(|er{v_i}| - \Psi ){2^i}} ,s(x) = \left\{ {\begin{array}{*{20}{l}} {1,}&{x \ge 0}\\ {0,}&{x < 0} \end{array}} \right.$ | (3) |
这里,Ψ表示第k个最大的边缘响应值的绝对值|ervk|,Ψ=Maxkth(ERV);ERV={|erv0|,|erv1|,…,|ervk|,…,|erv7|}.
利用Kirsch掩模对图像进行卷积运算,我们将为每个像素分配一个8位的二进制编码.LDP总共有C8k种不同的模式,如果k取3,则共有56种模式.
1.3 ELDPLDP使用边缘响应值的绝对值进行编码,Zhong等人[23]认为,原始的边缘响应值的正负意味着某个方向上两个相反的趋势(上升或下降),可能包含更多的信息,因此,他们提出一种增强局部方向模式(enhanced local directional pattern,简称ELDP).在ELDP中,首先通过LDP中的方法计算8个边缘响应值ERV={erv0,erv1,…, erv7};然后,通过边缘响应值ervi的下标值i来表示ervi的方向值,因此,8个方向正好可以分别用8个八进制编码来表示(0,1,2,3,4,5,6,7分别对应000,001,011,100,101,110,111).ELDP利用最大边缘响应值和次大边缘响应值的方向值进行编码,因此,ELDP编码可以用一个双八进制数(ab)8来表示,这个双八进制数可以通过公式(4)转换成十进制数:
| $ELDP\left( {{x_c},{y_c}} \right) = a \times {8^1} + b \times {8^0}$ | (4) |
在这里,a是最大边缘响应值ma的索引下标,b是次大边缘响应值mb的索引下标,其中,a,b$ \in $[0, 7].ELDP总共有$P_8^2 = 8 \times 7 = 56$种不同的模式,由于8个位置取不同的八进制数,因此是排列而不是组合.与LDP编码相比,ELDP编码只是对前两个最大边缘响应值对应的位置进行编码,显然,编码结果要相对简洁很多.此外,ELDP考虑边缘响应值的方向性,因此大部分情况选择的可能都是正响应值对应的方向.而通常,更小的负值也可能意味着更突出的图像边缘细节.
2 DLDP 2.1 DLDP编码LDP通过8个Kirsch掩模和图像的卷积结果进行编码,在LDP编码中,分别为每个参照像素分配一个8位二进制数来表示8个方向上的边缘响应强弱.ELDP通过考虑边缘响应值的方向性,提出相应的简化版编码方法.特别需要注意的是:LDP和ELDP都没有考虑近邻边缘响应值之间的强度变化,强度变化越大,往往表示两个方向之间存在更突出的边缘特征.另一个问题是,LDP和ELDP受到原始Kirsch掩模的制约,只是考虑3x3掩模.我们将在第3节把Kirsch掩模扩展到更高的分辨率,并且依据原始3x3掩模的权值设计约束,调整高分辨率中的掩模权值.
此外,LDP和ELDP主要考虑在强度空间上进行编码,DLDP将在梯度空间进行编码.显然,梯度空间比强度空间包含更多的信息.比如,梯度空间可以保留像素之间的内在关系,而强度空间则不能.梯度空间保留这些内在关系实质上揭示了图像的潜在结构信息,而这些结构信息往往具有更强的判别性.为了保证梯度计算更稳定,DLDP首先使用高斯方法平滑图像.高斯平滑可以减弱噪声的影响,梯度空间的计算会使DLDP对光照变化更鲁棒.
针对一幅变换后的梯度图像,我们通过计算近邻边缘响应值之间的差值derv来表示近邻边缘响应值之间的强度变化,然后计算相应的编码.具体编码方法见公式(5):
| $DLDP({x_c},{y_c}) = \sum\limits_{i = 0}^7 {s(|der{v_i}| - \Xi ){2^i}} ,{\rm{ }}s(x) = \left\{ {\begin{array}{*{20}{l}} {1,}&{x \ge 0}\\ {0,}&{x < 0} \end{array}} \right.$ | (5) |
这里,
•dervi表示近邻边缘响应值的差值,我们称作差值边缘响应值:
derv0=erv0-erv7,derv1=erv1-erv0,…,derv7=erv7-erv6;
•Ξ表示第k个最大的差值边缘响应值的绝对值|dervk|:
Ξ=Maxkth(DERV);DERV={|derv0|,|derv1|,…, |derv7|}.
由于采用了近邻边缘响应值之间的差值,因此,本算法被称为差值局部方向模式,图 3展示了具体的DLDP编码实例.DLDP和LDP类似,也有$C_8^k$种不同的模式,如果k取3,则共有56种模式.

|
Fig. 3 An example of calculating DLDP code when k=3 图 3 当k取3时,DLDP的编码实例 |
图 4展示了AR数据中某个人的部分图像和对应的DLDP图像.图 4(a)对应非遮挡的原始图像,图 4(b)是其相应的DLDP编码图像.图 4(c)对应遮挡的原始图像,图 4(d)是其相应的DLDP编码图像.从图 4中可以看出, DLDP编码图像提取了更多边缘细节.通常意义上,边缘细节往往具有更强的判别性.

|
Fig. 4 Original images and DLDP code images 图 4 原始图像和DLDP编码图像 |
LBP和LDP的主要区别在于编码时对邻居集的采样方式,针对某个中心像素在某一方向上的编码,LBP往往只选择邻居集的1个像素或3个像素,属于稀疏采样;而LDP在计算某一方向的编码时,采用的是稠密采样,即,选择邻居内的所有像素.从统计观点来看,Kirsch掩模的采用会获得更鲁棒的效果;而稀疏采样会丢失更多的邻域信息,降低方法的正确性.因此,当有轻微噪声存在时,LDP,ELDP和DLDP会比LBP表现得更稳定.
LDP可以在局部邻域内获取更多的边缘特征:如果在某个方向上的边缘响应值为正值,则说明在该方向上存在由黑到白的边缘特征;如果在该方向上边缘响应值为负,则说明在该方向上存在有白到黑的边缘特征.正值或负值的绝对值越大,边缘特征的反差越大,也就是说,边缘特征越明显.ELDP主要考虑LDP计算的边缘响应值的符号,但问题是ELDP考虑的只是边缘响应值最大的两个,因此很有可能错过负值最小的边缘响应值,也就是说,会错过一些比较明显的由白到黑的边缘特征,这可能会导致ELDP在某些情况下要弱于LDP.
LDP和ELDP并没有考虑近邻边缘响应值之间的强度变化,DLDP通过计算近邻边缘响应值之间的强度变化来提取特征.通常认为:相邻的边缘响应值之差的绝对值越大,则说明在两个方向之间存在的特征越明显.这极有可能是两个方向的边缘响应值一个为正一个为负,显然一个从黑到白,一个从白到黑,此时,应该得到的是所谓的对角线特征.当然,也有可能是两个方向具有相同的符号,但二者相差很大,这说明在两个方向之间存在比较明显的边缘特征.因此,与LDP和ELDP相比,DLDP在局部邻域中获取了更丰富的细节特征,强度变化越大,往往表示两个方向之间的细节特征更突出,更突出的细节特征往往具有更强的判别力.
下面通过图 5中的例子来验证,图 5展示了3个局部3x3图像块,图 5(a)是原始图像块,图 5(b)是相应的高斯白噪声图像块,图 5(c)是相应的遮挡图像块.

|
Fig. 5 Stability of LBP, LDP, ELDP and ELDP 图 5 LBP,LDP,ELDP和DLDP的稳定性 |
从图 5(a)和图 5(b)可以看出,由于增加了白噪声,LBP的第5位从1变为0,因此,LBP模式从统一模式变成非统一模式.而由于LDP,ELDP和DLDP通过稠密采样,因此,即使在噪声情况下,两者也都产生了同样的编码模式.在图 5(c)中,我们把第1行设置为近似相等的像素以表示遮挡情况,此时,LBP,LDP和ELDP的模式都有别于图 5(a)和图 5(b)中对应的LBP,LDP和ELDP模式.但由于DLDP考虑了局部近邻方向上边缘响应值的差异性,因而即使在遮挡情况下,DLDP也产生了同样的编码模式.这充分说明了DLDP编码对遮挡的鲁棒性.
3 Kirsch掩模分析与加权设计 3.1 Kirsch掩模分析图 6展示了第i(=0,1,…,7)个Kirsch掩模,$M_i^8$为中心位置权值,$M_i^j(j = 0,1,...,7)$为$M_i^8$的8个邻居位置权值,结合图 2可以看出,Kirsch掩模主要满足如下3个约束:

|
Fig. 6 The ith Kirsch mask 图 6 第i个Kirsch掩模 |
(1) 对于任意一个Kirsch掩模Mi,中心位置$M_i^8$的权值为0;
(2) 对于任意一个Kirsch掩模Mi,中心位置的所有邻居位置的权值之和为0,即有$\sum\limits_{j = 0}^7 {M_i^j = 0} {\rm{;}}$
(3) 任意一个掩模中有3个较大权值wl,5个较小权值ws,较大权值所在的方向代表掩模的方向.
8个Kirsch掩模主要通过权值的设置来刻画8个不同的方向,如,为了获取东北方向掩模(如图 7所示),则为东北方向上3个连续邻居位置(实心圆形)设置较大的权值wl,而为其他5个连续邻居位置(空心圆形)设置较小的权值ws.由于要满足约束(2),因此对于东北方向掩模中,中心位置的所有邻居位置的权值应满足第3个约束,则有如下公式:
| $3 \times {w^l} + 5 \times {w^s} = 0 \Rightarrow \frac{{{w^l}}}{{{w^s}}} = \frac{5}{{ - 3}}$ | (6) |

|
Fig. 7 Northeast directional mask 图 7 东北方向掩模 |
因此我们可以得出wl和ws的比值关系,原始的Kirsch掩模实际上选取了最小整数权值5和-3,当然,也可以取5/3和-1,或者10和-6.
3.2 加权设计本节主要针对不同分辨率下的掩模进行加权设计.图 8显示了原始的5x5 Kirsch掩模.这里的Kirsch掩模只是单纯考虑方向性(如在正东方向上,所有元素都设置为1),并没有考虑不同像素位置的权重.通常认为:距离参照点(即中心点$M_i^8$)越近的权重越大,距离参照点越远的权重越小.

|
Fig. 8 Kirsch edge response masks in eight directions (5x5) 图 8 在8个方向上的Kirsch边缘响应掩模(5x5) |
对于任一分辨率为mxm(m为大于1的奇数)的掩模,总共有$\frac{{m - 1}}{2}$层,τr为第r层邻居个数,M(r),j表示掩模的第r层的第j个邻居,第r层的邻居从0排列到τr-1,为了满足约束(2),则有:
| $\sum\limits_{j = 0}^{{\tau _1} - 1} {{M^{(1),j}} + } \sum\limits_{j = 0}^{{\tau _2} - 1} {{M^{(2),j}} + ... + } \sum\limits_{j = 0}^{{\tau _r} - 1} {{M^{(r),j}} + } ... + \sum\limits_{j = 0}^{{\tau _{(m - 1/2)}} - 1} {{M^{((m - 1)/2),j}}} = 0$ | (7) |
对于公式(7),我们只需保证每层的权值之和为0即可.由公式(6),可以类似地计算出通用的掩模中心位置的每层邻居的权值比值.公式(8)是第r层的较大权值和较小权值的比值:
| $(2r + 1) \times w_r^l + ({\tau _r} - (2r + 1)) \times w_r^s = 0 \Rightarrow \frac{{w_{^r}^l}}{{w_r^s}} = \frac{{{\tau _r} - (2r + 1)}}{{ - (2r + 1)}}$ | (8) |
其中,τr为第r层邻居个数,$w_{^r}^l,w_r^s$分别对应第r层中设置的较大权值和较小权值.
下面以9x9(m=9)掩模为例,计算各层权值.9x9掩模总共有4层,从第1层~第4层的邻居个数分别为8,16,24和32.根据公式(8),分别设置如下权值:
•第1层:处于该层某方向上的邻居位置的较大权值为5,其他邻居位置的较小权值为-3;
•第2层:处于该层某方向上的邻居位置的较大权值为11,其他邻居位置的较小权值为-5;
•第3层:处于该层某方向上的邻居位置的较大权值为17,其他邻居位置的较小权值为-7;
•第4层:处于该层某方向上的邻居位置的较大权值为23,其他邻居位置的较小权值为-9.
图 9展示了不同层的邻居和相应的权值(对应东北方向),图 9(a)~图 9(d)分别对应1~4层.

|
Fig. 9 Neighbors and the corresponding weight values under different layers (northeast direction) 图 9 不同层的邻居和相应的权值(对应东北方向) |
根据图 9中的权值设置,可以得出完整的9x9 Kirsch掩模(对应东北方向),具体如图 10(d)所示,图 10(a)~图 10(c)分别是3x3,5x5和7x7掩模.但通常认为:距离参照点(即中心点)越近的权重越大(取绝对值),距离参照点越远的权重越小(取绝对值),图 10的权值设置显然不尽合理.当然,相同距离的位置,权值的设置遵照处于方向上的权值大于剩余的位置的权值(取绝对值).公式(9)用来计算对第r层中的权值进行放大的倍数,σ为倍数调整参数.σ越小,内层与外层权值变化就越小;相反,σ越大,内、外层权值变化就越大.
| ${\lambda _r} = \left| {\frac{{w_{^{r + 1}}^l}}{{w_{^r}^s}}} \right| + \sigma ,\sigma > 0$ | (9) |

|
Fig. 10 Krisch masks under different resolutions (northeast direction) 图 10 不同分辨率下的Kirsch掩模(对应东北方向) |
对于9x9掩模,相对于中心位置总共有4层,其中,前3层需要调整权值,各层权值调整参数计算如下:
•第1层:该层权值矩阵调整倍数为${\lambda _1} = \left| {\frac{{11}}{{ - 3}}} \right| + \sigma ,\sigma > 0{\rm{;}}$
•第2层:该层权值矩阵调整倍数为${\lambda _2} = \left| {\frac{{17}}{{ - 5}}} \right| + \sigma ,\sigma > 0{\rm{;}}$
•第3层:该层权值矩阵调整倍数为${\lambda _3} = \left| {\frac{{23}}{{ - 7}}} \right| + \sigma ,\sigma > 0.$
设M(r)表示第r层的所有邻居权值,为了保证内层权值大于外层权值,则需要乘上所有大于等于r层的的调整倍数.具体计算见公式(10):
| ${M^{(r)}} = {\lambda _{\max - 1}} \times {\lambda _{\max - 2}} \times ... \times {\lambda _r} \times {M^{(r)}},\max = \frac{{m - 1}}{2},r = 1,...,\max - 1$ | (10) |
max是mxm掩模中的最大层数,最外层不需要调整权值.
图 11展示了调整权值后的5x5 Kirsch掩模(对应东北方向),此时调整参数σ取1/3,调整倍数${\lambda _1} = \left| {\frac{{11}}{{ - 3}}} \right| + \frac{1}{3} = $4.经过调整后的5x5 Kirsch不但满足所有3个约束,而且满足距离参照点越远权值越小的思想.

|
Fig. 11 Weighted 5x5 Kirsch mask (northeast direction) 图 11 调整权值后的5x5 Kirsch掩模(对应东北方向) |
给定一张图像I,通过DLDP操作后,我们可以获得一张编码图像IDL,在编码图像时,把边缘响应值最大的k=3个方向编码为1,把剩余的5个方向编码为0,最终可以获得56($C_8^3$)种不同的编码模式dpi,i=1,2,…,56.为了获取图像中丰富的局部纹理信息(例如边、点和角点等),通常采用直方图来统计局部图像块中的编码模式.接下来详述图像的直方图表示方法.
针对一张经过DLDP编码后的图像IDL,我们把它划分成L个非重叠的局部图像块IDL=[b1,…,bj,…,bL], 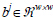 ,其中,w=4,8.对于编码图像中的每个局部块bj,可以通过如下公式计算其子直方图:
,其中,w=4,8.对于编码图像中的每个局部块bj,可以通过如下公式计算其子直方图:
| ${H^j}(d{p_i}) = \sum\limits_{(x,y)} {P({b^j}(x,y) = d{p_i})} {\rm{ where }}P(A) = \left\{ {\begin{array}{*{20}{l}} {1,{\rm{ }}A = {\rm{true}}}\\ {0,{\rm{ }}A = {\rm{false}}} \end{array}} \right.$ | (11) |
在子直方图的计算中,Hj(dpi)通过累加第j个子块中属于dpi模式的像素的个数来计算.子直方图Hj(dp)实际对应了一个长度为56的列向量hj,向量中的每个元素表示j个子块属于每个每个模式的像素个数.对于一幅编码图像IDL,串联所有的子直方图,以形成一个更具判别性的直方图HDL:
| ${H_{DL}} = \prod\limits_{j = 1}^L {{H^j}} $ | (12) |
这里,$\prod {} $表示串联操作,L表示一张图像划分的块的个数,串联后的直方图对应一个长度为56xL的列向量hDL.HDL在空间上组合了整张图像的统计模式,实际上扮演了全局特征脸的角色.因此,对于一张图像I,最终用列向量hDL来表示.图 12展示了用DLDP进行人脸表示的流程.

|
Fig. 12 Face representation using DLDP 图 12 用DLDP进行人脸表示 |
在人脸识别阶段,首先抽取所有候选脸和测试脸的直方图特征向量hDL,然后通过计算测试脸和候选脸的特征向量之间的相似性来判别测试脸属于哪一张候选脸.直方图向量之间的相似性测度通常采用Chi-square统计方法.给定两张脸的直方图特征向量$h_{_{DL}}^1 \in {\Re ^{56L}}$和$h_{_{DL}}^2 \in {\Re ^{56L}},h_{_{DL}}^1(i)$表示$h_{_{DL}}^1$的第i(=1,2,…,56L)维,则$h_{_{DL}}^1$和$h_{_{DL}}^2$之间的Chi-square统计测度定义为
| ${\chi ^2}(h_{_{DL}}^1,h_{_{DL}}^2) = \sum\limits_{i = 1}^{56L} {\frac{{{{(h_{_{DL}}^1(i) - h_{_{DL}}^2(i))}^2}}}{{h_{_{DL}}^1(i) + h_{_{DL}}^2(i)}}} $ | (13) |
利用公式(13)计算测试脸与所有候选脸之间的Chi-square测度值,选择具有最小Chi-square统计测度值的候选脸与测试脸匹配.
5 实 验本节主要评估我们提出的DLDP算法,并且与一些时新的算法进行比较.我们将在4个公开的人脸数据库(AR[27],Extended Yale B[28],CMU PIE[29, 30]以及FERET[31])上执行相关的实验,我们的实验涉及更广泛的人脸变化,主要有人脸表情变化(AR,CMU PIE和FERET)、光照变化(AR,Extended Yale B,CMU PIE和FERET)、原有遮挡(AR)、人为遮挡(AR,Extended Yale B,CMU PIE和FERET)、年龄(FERET)、轻度的姿态变化(CMU PIE和FERET).在实验中,AR图像的分辨率设置为100x90,Extended Yale B图像的分辨率设置为96x84,CMU PIE图像和FERET图像的分辨率都被设置为64x64.
实验中所有涉及LDA的方法(如LDA,IGO-LDA),为了避免类内散度矩阵Sw的奇异性,都采用带正则化参数的优化方法(Sw+εI)-1SbQ=QΛ.这里,ε是一个小的正则化常量(取10-3以下),I是一个单位矩阵.
对于LBP特征,采样点为8个,采样半径为2,在AR上的图像块设置为16x15,在其他数据库上的图像块设置为8x8,每块对应一个59维的直方图.对于LTP 特征,在AR上的图像块设置为16x15,在其他数据库上图像块设置为8x8,每个图像块对应一个128维的直方图.
对于LDP,编码为1的个数k=3;在AR,Extended Yale B和CMU PIE上的图像块设置为4x4,在FERET上的图像块设置为8x8,每个图像块都对应一个56维的直方图.
对于ELDP特征,把最大值和次大值对应的位置编码为8进制数,在AR,Extended Yale B和CMU PIE上的图像块设置为4x4,在FERET上的图像块设置为8x8,每个图像块都对应一个56维的直方图.
对于DLDP,在AR中编码为1的个数k=2(此时,每个图像块都对应一个28维的直方图);在Extended Yale B, CMU PIE和FERET中编码为1的个数k=3(此时,每个图像块都对应一个56维的直方图);所有数据库中掩模分辨率设置为5x5,加权倍数调整参数σ设置为1.在AR,Extended Yale B和CMU PIE上图像块设置为4x4,在FERET上图像块设置为8x8.
为了保证公平性,采用简单的1近邻分类器(1-NN)进行分类,距离度量方式采用余弦测度.而针对LBP,LTP, LDP,ELDP,DLDP,距离度量方式都采用Chi-square统计测度.
为了评价算法的鲁棒性,我们增加了一系列人为的遮挡实验.在这些遮挡实验中,主要用不同分辨率的恐龙头部图像,在测试图像的任意位置上进行遮挡.针对AR和Extended Yale B,分别使用分辨率为55x55的恐龙头部图像;针对CMU PIE和FERET,使用分辨率为45x45的恐龙头部图像.
5.1 AR数据库AR人脸库[27]包括4 000多张正面人脸图像,包括126个人(70个男性,56个女性).每个人有26张图像,被分为两部分:第1部分每个人共有13张图像,从1~13进行编号,其中包括不同的人脸表情(1~4)、光照变化(5~7)以及在不同光照条件下的不同遮挡(8~13);第2部分与第1部分类似,也有13张图像,分别对应表情、光照和遮挡.图 13展示了用在实验中的图像样例,第1行的7张图像来自于第1部分,第2行的7张图像来自于第2部分的非遮挡图像,第3行的7张图像是对第2行图像通过人为遮挡后的图像(恐龙头部遮挡),第4行的6张图像是来自于第2部分的系统遮挡图像(墨镜遮挡和围巾遮挡).

|
Fig. 13 Face images of the same subject taken from the AR database 图 13 来自AR的同一个人的多张图像 |
针对AR数据库,我们共做了9个实验,表 1提供了每个实验详细的训练集和测试集信息.从表 1可以看出,所有实验的训练集被分为3类:第1部分的多个非遮挡图像(编号1~7),对应实验1~实验3;第1部分的较少非遮挡图像(编号1,2),对应实验4~实验6;第1部分的单个非遮挡图像(编号1),对应实验7~实验9.所有实验的测试集也被分为3类:第2部分的非遮挡图像(编号1~7);对第2部分的非遮挡图像(编号1~7)进行人为遮挡(恐龙头部遮挡);第2部分的系统遮挡图像(编号8~13,墨镜遮挡和围巾遮挡).表 2展示了实验1~实验9的相关实验结果.
| Table 1 All experiment configurations on the AR database 表 1 AR人脸库中所有实验的详细信息 |
| Table 2 Recognition rates (%) of different methods on the AR database (Exp.1~Exp.9) 表 2 在AR人脸库中,不同识别方法的识别率(%)(实验1~实验9) |
从表 2可以看出,DLDP算法在所有情况下都获得了最好的识别率.实验1主要针对非遮挡情况,PCA的识别率较差,LDA的识别率要高于PCA,但并不令人满意.IGO-PCA,IGO-LDA,LBP,LTP,LDP,ELDP和DLEP都取得了较好的识别效果,然而DLDP的识别效果是最好的.实验2和实验3是遮挡情况下的识别效果,显然,PCA,LDA的识别效果急速下降,说明全局特征方法对遮挡情况非常敏感.IGO-PCA,IGO-LDA和LBP,LTP的识别效果要好于PCA和LDA.值得注意的是,LDP,ELDP和DLDP都获得了较好的识别效果,这充分说明了稠密邻居采样的作用.但DLDP获得更好的识别效果,与排名第二的算法相比,分别高出2.42个百分点和2.33个百分点.
实验4不涉及遮挡问题,PCA,LDA表现不够理想.这表明当训练样本个数变少时,全局特征算法表现得较差.IGO-PCA,IGO-LDA获得了不错的识别效果,说明梯度空间的采用可以获取更多的结构信息,而结构信息显然更有助于识别率的提升.LBP,LTP,LDP和ELDP也获得了不错的识别效果,说明局部特征对光照和表情比较鲁棒.由于DLDP在梯度空间上提取局部的细节特征,因此取得了最好的识别结果,与识别率第二的LDP相比,提高了3.99个百分点.在实验5和实验6中,以正常图像作为训练,以遮挡图像作为测试,是更具挑战性的实验.在实验5中,我们通过恐龙头部图像在测试图像任意位置进行遮挡;在实验6中,我们选用数据库本身提供的遮挡图像(墨镜遮挡和面纱遮挡),遮挡位置比较固定.
从实验5和实验6的结果可以看出:PCA,LDA表现得更差,IGO-PCA,IGO-LDA,LBP和LTP的识别效果要好于PCA和LDA,但仍不能令人满意.LDP,ELDP和DLDP都取得了不错的识别效果,其中,我们提出的DLDP表现更好,与排名第二的算法相比(实验5中的ELDP和实验6中的LDP),分别高出4.14个百分点和5.17个百分点.DLDP获得较好的识别效果,主要原因有3点:第一,DLDP通过计算近邻边缘响应值之间的强度变化,本质上是在获取方向之间的更丰富的细节特征,强度变化越大,往往表示两个方向之间的细节特征越突出,更突出的细节特征往往具有更强的判别力;第二,DLDP通过分析Kirsch 3x3掩模所蕴含的约束机制,提出了高分辨率Kirsch掩模的权值设计方法;第三,由于DLDP在梯度空间上计算编码,因此对光照更鲁棒,此外,在梯度计算时采用高斯函数进行图像平滑,因此减弱了噪声的影响.
在实验7~实验9中,每个人的训练样本个数减少为1张图像,此时,传统的全局特征表示方法PCA和LDA的识别效果明显下降,这充分说明全局特征过于依赖于训练样本的个数.在遮挡情况下(实验8和实验9),PCA和LDA识别效果更差.在非遮挡情况下(实验7),IGO-PCA,IGO-LDA,LBP,LTP,LDP,ELDP和DLDP也获得了不错的效果,这与这些特征蕴含了局部信息有关.其中,我们提出的DLDP方法获得最好的识别效果,与排名第二的ELDP相比,提高了6.71个百分点.与非遮挡情况相比,在遮挡情况下(实验8和实验9),IGO-PCA,IGO-LDA,LBP, LTP,LDP,ELDP和DLDP的识别效果都有所下降,但其中IGO-PCA,IGO-LDA,LBP和LTP下降得更为明显,LDP, ELDP和DLDP下降得相对较少.与排名第二的算法相比(实验8中的ELDP和实验9中的LDP),DLDP分别高出2.57个和6.17个百分点.
5.2 Extended Yale B数据库Extended Yale B人脸库[28]包含2 414张正面人脸图像,包括38个人,每个人有大约64张图像,这些图像是在不同光照条件下采集的.尽管图像的姿态变化不大,但极度的光照条件对大多数人脸识别方法来说仍然是一个不小的挑战.所有标记为P00的前脸图像被应用在我们的实验中,图 14展示了用在实验中的一个人的多张人脸图像,其中,第1行是原始的非遮挡图像,第2行是相应的人为遮挡图像(用恐龙头部图像在第1行图像的任意位置进行遮挡).

|
Fig. 14 Partial face images of the same subject taken from the Extended Yale B database 图 14 来自Extended Yale B的同一个人的多张图像 |
我们一共执行两组实验:
•在实验1中,我们为每个人随机选择Ntrain个图像作为训练集,剩下的图像作为测试集.这里,Ntrain分别取4,8, 12,16,20和24.对于Ntrain的每种选择,分别随机生成10种不同的训练集进行实验;
•实验2和实验1类似,唯一的不同是在实验2中,所有的测试图像通过恐龙头部图像块进行人为遮挡.两组实验中所有方法的平均识别率被展示在表 3中.
| Table 3 Average recognition rates (%) of different methods on the Extended Yale B database (Exp.1~Exp.2) 表 3 在Extended Yale B人脸库中,不同识别方法的平均识别率(%) (实验1、实验2) |
从表 3可以看出:
•在非遮挡情况下(实验1),PCA的识别效果比较差,LBP和LTP获得了优于以上算法的识别结果,LDA获得了相对较好的识别效果,基于稠密邻域采样的LDP,ELDP,DLDP都获得了更好的识别效果.尽管当每人的训练样本个数较少时(选取4,8和12),DLDP的识别率要低于IGO-PCA,IGO-LDA,但随着训练样本的增加,DLDP逐渐取得了最好的识别率,并且识别率几乎都达到100%.
•在遮挡情况下(实验2),PCA,LDA等传统全局特征方法表现得更差,LBP,LTP,LDP,ELDP,DLDP,IGO- PCA和IGO-LDA都有不同程度的下降,但DLDP明显下降得更少,在所有情况都获得了最优的识别率,这充分说明DLDP算法对遮挡的鲁棒性.
5.3 CMU PIE数据库CMU PIE[29, 30]人脸数据库包含41 368张人脸图像,包括68个人,每个人的图像有13种不同的姿态、43种不同的光照条件和4种不同的表情.本实验选择PIE数据库的子集[30],该子集中每人包含50张人脸图像,这50张图像分属5种不同的姿态,每种姿态包含10张图像.图 15展示了用在我们实验中的一个样本的多张图像,其中,第1行是原始的非遮挡图像,第2行是相应的人为遮挡图像(用恐龙头部图像在第1行图像的任意位置进行遮挡).

|
Fig. 15 Partial face images of the same subject taken from the CMU PIE database 图 15 来自CMP PIE的同一个人的多张图像 |
我们执行两组实验:
•在实验1中,我们为每个人随机选择Ntrain个图像作为训练集,剩下的图像作为测试集.这里,Ntrain分别取5,10,15,20和25.对于Ntrain的每种选择,分别随机生成10种不同的训练集进行实验;
•实验2和实验1类似,唯一的不同是在实验2中,所有的测试图像通过恐龙头部图像块进行人为遮挡.
两组实验中,所有方法的平均识别率被展示在表 4中.由于PIE数据库涉及到姿态、光照和表情,显然更具挑战性.
| Table 4 Average recognition rates (%) of different methods on the CMU-PIE database (Exp.1~Exp.2) 表 4 在CMU PIE人脸库中,不同识别方法的平均识别率(%) (实验1、实验2) |
从表 4可以看出:
•在非遮挡情况下(实验1),PCA的识别效果明显较差,LDA,LBP,LTP,LDP和ELDP的识别效果优于以上算法,IGO-PCA,IGO-LDA和DLDP获得了相对较好的识别效果.在非遮挡情况下,当训练样本较少时,DLDP并没有获得最优识别率,但随着训练样本的增加,DLDP的识别率不仅赶上了排名第一的IGO-LDA,而且在训练样本为20和25时超过了它.
•在遮挡情况下(实验2),无论训练样本多少,DLDP都获得了最优识别率.而在实验1中表现突出的IGO-LDA算法,在遮挡情况下识别率明显下降.这充分表明DLDP算法对遮挡情况的鲁棒性.
5.4 FERET数据库FERET数据库[31]由美国国防部通过DARPA(defense advanced research projects agency)计划发起,它已经成为一个测试和评估人脸识别算法的标准数据库.我们提出的算法在FERET的一个子集上进行测试,这个子集包括1 400张图像、200个人(每个人有7张图像).该子集涉及人脸表情、光照和姿态的变化.每个人的7张图像包括3张正脸图像和4张侧面图像,3张正脸图像包括光照、表情和时间(分别被标记为‘ba’,‘bj’,‘bk’),4张侧面图像具有具有±15°和±25°的姿态(分别被标记为‘bd’,‘be’,‘bf’,‘bg’)[30].图 16展示了用在我们实验中的一个样本的多张图像,其中,第1行是原始的非遮挡图像,第2行是相应的人为遮挡图像(用恐龙头部图像在第1行图像的任意位置进行遮挡).

|
Fig. 16 Face images of the same subject taken from the FERET database 图 16 来自FERET的同一个人的多张图像 |
我们执行两组实验:
•在实验1中,我们从FERET数据库中为每个人选择2张图像作为训练集,剩余的作为测试.6种不同的训练集组合情况分别是‘ba’和‘bd’、‘ba’和‘be’、‘ba’和‘bf’、‘ba’和‘bg’、‘ba’和‘bj’、‘ba’和‘bk’.我们分别计算了每种算法在这6种情况下的识别率,也计算了这6种情况下的平均识别率.
•实验2和实验1类似,唯一的不同是在实验2中,所有的测试图像通过恐龙头部图像块进行人为遮挡.
两组实验的测试结果展示在表 5中.
| Table 5 Recognition rates (%) of different methods on the FERET database (Exp.1~Exp.2) 表 5 在FERET人脸库中,不同识别方法的识别率(%)(实验1、实验2) |
从表 5可以看出:
•在非遮挡情况下(实验1),DLDP在所有情况都获得了最佳识别率,DLDP的平均识别率比排名第二的LBP高出1.85个百分点,效果并不是很明显;
•在遮挡情况下(实验2),DLDP同样获取了最佳识别率.值得注意的是:在实验2中,DLDP的平均识别率比排名第二的ELDP高出7.7个百分点,比LBP高出14.02个百分点.这充分说明了DLDP对遮挡的鲁棒性.
5.5 参数分析本节主要讨论DLDP的相关参数设置.在DLDP中,主要涉及3个参数:选择编码为1的个数k、掩模分辨率mxm和加权倍数调整参数σ.接下来,在以上提到的4个数据库上,评估DLDP方法的参数设置对识别率的影响.我们首先分析参数k的取值和对应的模式情况,表 6展示了k在取不同的值时,所拥有的模式数量.参数k不可能取8,因为此时只有一种模式.当k取1或7时,只有8种模式存在,显然模式个数过少,识别效果不可能好.因此,在这里我们只讨论k取2,3,4,5,6时的情况.
| Table 6 Number of patterns under different k 表 6 不同的k所对应的模式数量 |
在AR数据库上,以每个人的第1部分的1张中性表情图像作为训练,以第2部分的7张图像作为测试.针对Extended Yale B数据库,我们为每个人随机选择8个图像作为训练集,剩下的图像作为测试集,一共进行10种不同的随机划分.针对CMU PIE数据库,我们为每个人随机选择10个图像作为训练集,剩下的图像作为测试集,同样进行10种不同的随机划分.然后,对得到的10个识别率取平均值,通过比较最终的平均识别率来获取最佳参数配置.针对FERET数据库,我们针对第6种情况进行测试.由于3x3掩模不涉及参数σ,因此,在任意的σ下都取同样的值.表 7展示了在4个人脸数据库AR,Extended Yale B,CMU PIE和FERET上的实验结果.
| Table 7 Recognition rates (%) of DLDP with different parameters on four face databases 表 7 在4个人脸库中,不同参数下DLDP的识别率(%) |
从表 7我们有如下观察:
(1) 无论哪一个数据库的实验结果,当掩模分辨率取3x3时,其识别效果要弱于分辨率取5x5和7x7,这充分说明了加权调整的作用.其中,掩模分辨率取5x5时获得更好的识别率.
(2) 与k取4,5,6和7相比,当k取2或3时,DLDP获得更高的识别率,其中,当k取2时,AR数据库获得了更好的识别率;但当k取3时,DLDP获得第二好的识别率.当k取3时,Extended Yale B,CMU PIE和FERET数据库获得了更好的识别率.
(3) 当掩模分辨率相同、k取值相同时,不同的σ下的识别率相差不大;但当σ取1时,在大部分情况下都能获得更好的识别率.
综上分析,针对不同人脸数据库,通常选取的最佳参数配置为:k取3,掩模分辨率取5x5,加权倍数调整参数σ取1.
6 结束语本文提出一种基于差值局部方向模式的人脸特征表示方法DLDP.与LDP和ELDP等考虑在强度空间上进行编码不同,DLDP主要在梯度空间进行编码.显然,梯度空间比强度空间包含更多的结构信息.然后,DLDP通过计算近邻边缘响应值之间的差值来获取近邻方向之间更丰富的细节特征,边缘响应值之间的差值绝对值越大,往往表示两个方向之间的细节特征越突出,更突出的细节特征往往具有更强的判别力.此外,基于Kirsch 3x3掩模约束机制的分析,DLDP为高分辨率的Kirsch掩模设计合理的权值.实验结果显示:DLDP在光照、表情、姿态和遮挡方面获取了较好的结果;尤其针对遮挡情况,DLDP表现得更为突出.
致谢 在此,我们向对本文的工作给予支持和建议的同行,尤其是武汉大学软件工程国家重点实验室丁立新教授、余旌胡教授领导的讨论班上的老师和同学表示感谢.
| [1] | Zhao W, Chellappa R, Phillips PJ, Rosenfeld A. Face recognition: A literature survey. ACM Computing Surveys, 2003,34(4): 399-485 . |
| [2] | Jain AK, Ross A, Prabhakar S. An introduction to biometric recognition. IEEE Trans.on Circuits and Systems for Video Technology, 2004,14(1):4-20 . |
| [3] | Jafri R, Arabnia HR. A survey of face recognition techniques. Journal of Information Processing System, 2009,5(2):41-68 . |
| [4] | Turk M, Pentland A. Eigenfaces for recognition. Journal of Cognitive Neuroscience, 1991,3(1):71-86 . |
| [5] | Comon P. Independent component analysis—A new concept. Signal Process, 1994,36(3):287-314 . |
| [6] | Belhumeur PN, Hespanha JP, Kriegman DJ. Eigenfaces versus Fisherfaces: Recognition using class specific linear projection. IEEE Trans.on Pattern Analysis and Machine Intelligence, 1997,19(7):711-720 . |
| [7] | Yang J, Zhang D, Frangi AF, Yang J. Two-Dimensional PCA: A new approach to appearance-based face representation and recognition. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2004,26(1):131-137 . |
| [8] | Tenenbaum JB, De Silva V, Langford JC. A global geometric framework for nonlinear dimensionality reduction. Science, 2000, 290(5500):2319-2323 . |
| [9] | Roweis ST, Saul LK. Nonlinear dimensionality reduction by locally linear embedding. Science, 2000,290(5500):2323-2326 . |
| [10] | He X, Yan S, Hu Y, Niyogi P, Zhang H. Face recognition using laplacianfaces. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2005,27(3):328-340 . |
| [11] | He X, Cai D, Yan S, Zhang H. Neighborhood preserving embedding. In: Proc. of the IEEE Int’l Conf. on Computer Vision. 2005.1208-1213 . |
| [12] | Yan SC, Xu D, Zhang BY. Graph embedding and extensions: A general framework for dimensionality reduction. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2007,29(1):40-51 . |
| [13] | Li ZK, Ding LX, Wang Y. A robust dimensionality reduction method from laplacian orientations. In: Proc. of the 15th IEEE Int’l Conf. on High Performance Computing and Communications. 2013.345-351 . |
| [14] | Li ZK, Ding LX, Wang Y, He JR. Face representation with gradient orientations and euler mapping: Application to face recognition. Int’l Journal of Pattern Recognition and Artificial Intelligence, 2014,28(8):1-21 . |
| [15] | Belkin M, Niyogi P. Laplacian eigenmaps and spectral techniques for embedding and clustering. In: Proc. of the NIPS, Vol.14. 2001. 585-591. |
| [16] | Liu C, Wechsler H. Gabor feature based classification using the enhanced fisher linear discriminant model for face recognition. IEEE Trans.on Image Process, 2002,11(4):467-476 . |
| [17] | Ahonen T, Hadid A, Pietikainen M. Face description with local binary patterns: Application to face recognition. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2006,28(12):2037-2041 . |
| [18] | Tan XY, Triggs B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans.on Image Processing, 2010,19(6):1635-1650 . |
| [19] | Zhang WC, Shan SG, Gao W, Zhang HM. Local gabor binary pattern histogram sequence (lgbphs): A novel non-statistical model for face representation and recognition. In: Proc. of the IEEE Int’l Conf. and Computer Vision. 2005.786-791 . |
| [20] | Heikkilä M, Pietikäinen M, Schmid C. Description of interest regions with local binary patterns. Pattern Recognition, 2009,42(3): 425-436 . |
| [21] | Lei Z, Liao SC, Pietikainen M, Li SZ. Face recognition by exploring information jointly in space, scale and orientation. IEEE Trans.on Image Processing, 2011,20(1):247-256 . |
| [22] | Jabid T, Kabir MH, Chae O. Robust facial expression recognition based on local directional pattern. ETRI Journal, 2010,32(5): 784-794 . |
| [23] | Zhong FJ, Zhang JS. Face recognition with enhanced local directional patterns. Neurocomputing, 2013,119:375-384 . |
| [24] | Tzimiropoulos G, Zafeiriou S, Pantic M. Subspace learning from image gradient orientations. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2012,34(12):2454-2466 . |
| [25] | Zhang TP, Tang YY, Fang B, Shang ZW, Liu XY. Face recognition under varying illumination using gradientfaces. IEEE Trans.on Image Processing, 2009,18(11):2599-2605 . |
| [26] | Ojala T, Pietikainen M. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2002,24(7):971-987 . |
| [27] | Martinez AM, Benavente R. The AR face database. CVC Technical Report, #24, 1998. |
| [28] | Lee KC, Ho J, Kriegman DJ. Acquiring linear subspaces for face recognition under variable lighting. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2005,27(5):684-698 . |
| [29] | Sim T, Baker S, Bsat M. The CMU pose, illumination, and expression database. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2003,25(12):1615-1618 . |
| [30] | Cai D, He XF, Han JW. Spectral regression for efficient regularized subspace learning. In: Proc. of the IEEE 11th Int’l Conf. on Computer Vision. 2007.1-8 . |
| [31] | Phillips PJ, Moon H, Rizvi SA, Rauss PJ. The FERET evaluation methodology for face recognition algorithms. IEEE Trans.on Pattern Analysis and Machine Intelligence, 2000,22(10):1090-1104 . |