 2014, Vol. 25
2014, Vol. 25



多视图学习是机器学习和模式识别领域中处理同一对象多种表示(如同一图片同时由颜色和纹理构成)数据的一类重要学习方法,近年来已吸引了众多研究者的关注.典型相关分析(canonical correlation analysis,简称CCA)[1]是一种处理多视图数据的经典方法,其用于分析同一组目标两组不同观测(视图)数据间的相关性,获得一组相关性最大的投影向量,从而达到综合视图信息并提升学习性能的目的.CCA、主成分分析(principal component analysis,简称PCA)和线性判别分析(linear discriminant analysis,简称LDA)是在多元统计中起着重要作用的特征分析方法,它们及其后续变形已广泛应用于图像分析[2]、模式识别[3]、多媒体分析[4]和信号处理[5]等众多领域.
Sun等人[6]利用CCA提取出多视图特征后,通过并行和串行两种信息融合方式进行后续分类.由于该方法不仅对信息进行特征级融合,而且消除了信息冗余.因此,其后借助向量对的组合能够获得比使用单个向量更好的分类性能.然而该工作仅将CCA用于独立于分类的特征提取,尽管保证了所提取的两组特征间的相关性最大,但因未利用数据的类信息,导致获得的投影向量未必具有好的判别性能,因而也难以保证有好的分类效果.自然地,在相关分析中充分利用数据的类信息获取有利于分类效果的判别特征,成为研究的关注点之一[7]. Arandjelovic[8]先提取两组数据中最相似的变量,提出扩展的CCA(E-CCA);再通过归一化的类间 散度矩阵及平均类内散度矩阵对输入向量进行变换,将E-CCA推广到判别框架中,提出DE-CCA.Ji等人[9]通过将视觉检索中3个等级信息(非常相关/相关/不相关)作为类别信息嵌入CCA,用相关性约束矩阵替换原有的互协方差矩阵,提出Rank-CCA,并且该方法最大程度地利用了有标号及无标号数据进行特征提取.Sun等人[10]通过最小化类间相关距离和同时最大化类内相关距离提出了DCCA,由于加入了类信息,获得了比CCA更有判别性的相关特征.然而当数据标号有序时,DCCA虽然考虑了样本的类信息,但是与 CCA一样,没有考虑类间的有序信息,难以保证好的有序分类性能.
有序回归是机器学习领域另外一个研究热点,其目标是自动判别那些具有固定离散等级样本的等级.例如,在一个5星电影打分评级系统中,给定一部电影特定的评分(1~5),分值越高,表明电影综合质量越高.这些具体分值可对应到相应的有序标号,使标号不仅表明样本的等级,而且不同标号的样本通常互相关,如标号为3的样本等级要比标号为2的高而比标号为4的低.一部电影具有很多属性(演员演技、服装设计、音乐编排等),由这些属性最终决定了该电影的评级(标号),也就意味着标号提供了有序信息.不同于普通的回归问题,有序回归的输出属于有限离散,更重要的是,对多类分类问题,有序回归的目标不仅希望能得到尽可能高的分类精度,同时还希望预测标号与真实标号间的差别尽可能小.因此,考虑有序信息能使分类时得出的绝对平均误差会比单纯的分类方法小.目前,有序回归已在信息检索、协同过滤或用户推荐系统、医疗和心理学等领域得到了应用[11].
对于有序回归,优化分类精度并不意味着对绝对误差的优化,反之亦然,这就要在两个目标优化时寻找平衡点.求解有序回归时,最通常的想法是将有序回归转换为传统的回归问题.Kramer等人[12]通过将有序信息映射到对应数值上,得出距离敏感、预测有序标号的分类器.然而多数情况下,样本间真实的度量距离是未知的,导致并没有一种通用的方法可用来寻找合适的投影函数.更常见的做法是,将有序回归问题转换为多类分类问题或在传统分类问题中增添相应的约束.Herbrich等人[13]对有序回归作了理论研究并将结构风险最小原理应用于有序回归.Hsu等人[14]与Smola等人[15]都将有序回归转化为标准机器学习问题,分别提出了SVC1V1,SVC1VA以及支持向量回归(SVR).Crammer和Singer[16]通过寻找有序回归的方向及阈值,归纳出具有多阈值的感知机算法.在此基础上,Shashua和Levin[17]提出两个最大间隔原则用来处理方向及阈值,但该方法在某些情况下会导致获得的阈值排序错误.Chu和Keerthi[18]通过在约束中添加与阈值相关的约束对该方法进行改进,提出两个支持向量回归.基于从原始样本及代价矩阵中提取的样本,Li等人[19]提出一个从有序回归到二分类问题的约简(reduce)框架,该框架对于现有几个有序回归算法提供了一个独特的视角.在此基础上,Lin等人[20]通过增强二分类框架来解决有序回归问题,提出了REDSVM.Cardoso和C o sta[21]使用数据复制方法将有序回归问题转换为标准二分类问题,并将该方法应用于支持向量机及神经网络.Sun等人[11]在有序回归框架中引入线性判别分析,提出基于有序回归的判别方法.通过保持原有线性判别分析对于最小类间距离的要求,同时添加约束保证各类样本投影后均值有序,提出基于有序回归的判别方法.进而运用核方法将其推广到非线性情况.
据我们了解,仅有Kawashima[22]的工作致力于采用CCA进行多视图的有序回归学习,其算法的实现不是将有序信息直接嵌入CCA,而是先用CCA进行信息融合,然后在融合空间中再借助现成的有序LDA设计有序回归算法.该方法与基于CCA的方法[9,10]类似,将信息融合与判别提取独立进行,如图 1所示.受我们先前工作的启发[23],本文旨在通过对融合后的信息进行判别信息提取,将类信息以及有序信息都加入到CCA的目标之中,发展出真正意义上的有序判别典型相关分析(ordinal discriminative canonical correlation analysis,简称OR-DisCCA).在保持(广义)相关性的前提下,使最后获得的投影不仅让不同类的数据投影后尽可能地分开,还能使投影后的数据按照一定的顺序排列.这样既提升分类精度,又降低平均绝对误差(mean absolute error,简称MAE).实验结果表明,OR-DisCCA的性能要比CCA,DCCA以及文献[22]的更优.另外,虽然OR-DisCCA只是对基本模型CCA的改造,但所用方法可方便地推广到其他改进形式的CCA.
 | Fig. 1 Feature extraction and information fusion图 1 特征提取以及信息融合过程 |
本文第1节介绍典型相关分析以及有序判别回归.第2节具体描述本文提出的OR-DisCCA.第3节是实验结果及与其他算法的对比.最后对本文的工作进行总结和展望.
1 相关背景 1.1 典型相关分析本节将对CCA进行简单的回顾.
设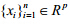 与
与 分别是同一目标两组中心化了的两视图观测数据,即
分别是同一目标两组中心化了的两视图观测数据,即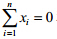 和
和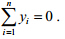
记 旨在寻找一对投影向量wxÎRp与wyÎRq,使得
旨在寻找一对投影向量wxÎRp与wyÎRq,使得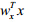 与
与 间的相
间的相
关性最大.等价于使下式最大:

由于优化问题式(1)中目标函数不随wx与wy的大小变化而变化,则公式(1)可改写为
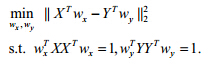
设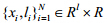 是一组训练样本,其中,
是一组训练样本,其中,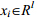 表示输入,liÎ{1,2,…,K}表示样本对应的标号,则类内与类间
表示输入,liÎ{1,2,…,K}表示样本对应的标号,则类内与类间
散度矩阵分别为:
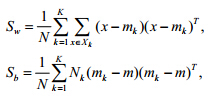
其中,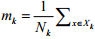 表示第k类的样本均值,
表示第k类的样本均值, 表示总样本均值.传统LDA通过最小化类内散度同
表示总样本均值.传统LDA通过最小化类内散度同
时最大化类间散度得出如下优化目标:
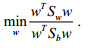
在LDA基础上,Sun等人[17]考虑在投影过程中同时保留有序信息,使得等级高的样本在投影后的均值要比等级低的大,由此建立如下优化目标:
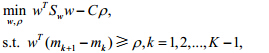
其中,C是惩罚系数.若r>0,则各类样本投影后的均值能够按照标号等级保持有序.
2 有序判别典型相关分析本文将类信息与有序信息同时加入到传统CCA框架中,提出有序判别线性相关分析.为此,需达成如下3个目标:
(1) 保持样本投影后相关性最大.类似CCA,相关性最大可通过如下方式获得:

注意到,公式(2)并未包含传统CCA中防止产生退化解的约束,而本文会通过其他约束保证这一点.获得投影向量后,传统CCA有如下两种常用的串行和并行特征融合方式用于后续分类[6]:
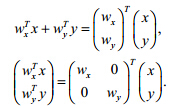
根据经验[23],使用以上两种不同融合方法,最后得出的结果不同.而实验发现:使用并行融合,最后能够获得更好的分类性能.所以本文使用了并行融合方法,这种特征融合方法也被称为特征融合策略2(FFS-II).
(2) 与已提出的先提取特征再进行融合的方法不同,OR-DisCCA期望融合后的信息具有判别性.
(3) 利用类信息保证融合特征的类内散度尽可能小、类间散度尽可能大.利用有序信息对融合特征投影后各类均值进行约束,使相邻两类样本投影后的均值按照标号等级保持有序,可通过如下方式达到:
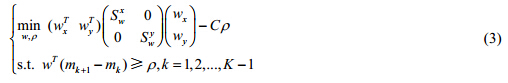
其中,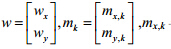 与my,k为X与Y第k类的样本均值.结合以上各式,最终形成如下优化目标:
与my,k为X与Y第k类的样本均值.结合以上各式,最终形成如下优化目标:

其中, 是参数.将平方项展开,公式(4)可改写为
是参数.将平方项展开,公式(4)可改写为
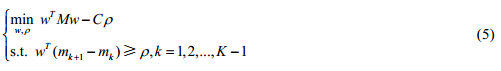
其中, .为了求解公式(5),定义拉格朗日函数:
.为了求解公式(5),定义拉格朗日函数:
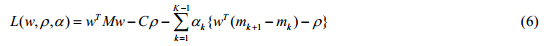
其中,拉格朗日乘子ak≥0.对L求偏导,得出:
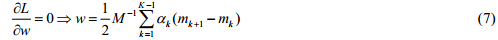

根据公式(7)以及公式(8),优化问题(5)可改写为:

优化问题(9)是一个标准凸二次规划问题(quadratic program,简称QP),许多现成软件包都可用来求解QP
问题.
用上述方法可求出第1组 ,由于OR-DisCCA额外包含有序约束,不像DCCA可通过求解广义
,由于OR-DisCCA额外包含有序约束,不像DCCA可通过求解广义
特征方程的方法一次获得多个投影向量,故需顺序地获取多个投影.大致步骤如下:若已求得前d-1个w,即w1,…,wd-1,则第d个wd要与之前求得的各w尽可能不相关,这可通过如下方法求解wd,其中,d≤min(p,q):
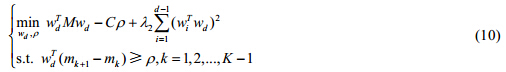
其中,l2是参数,为使投影方向间尽可能不相关,该参数可设为较大的值.现将平方项展开,公式(10)可改写为
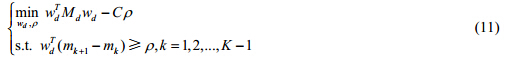
其中,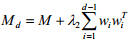 .公式(11)可运用之前所提方法求解.
.公式(11)可运用之前所提方法求解.
由于现有许多研究都表明多视图的统计意义比单视图要好[24,25],所以本文进行对比的算法都是多视图算法.本节通过在多特征手写体数据集以及8个标准数据集上与CCA,DCCA及文献[22]中的方法进行比较.使用五折(5-fold)交叉验证来选择参数l1,l2,C取为10.最后,使用平均分类正确率(mean classification accuracy,简称MCA)以及平均绝对误差(mean absolute error,简称MAE)来度量性能.
设N个测试样本真实的标号为{y1,y2,…,yN},预测的标号为 ,那么MCA与MAE的定义分别为
,那么MCA与MAE的定义分别为

其中,N1为预测标号与真实标号间误差不超过e的样本个数.
3.1 多特征手写体数据集多特征手写数据集(http://www.ics.uci.edu/~mlearn/MLSummary.html)是UCI数据集中的一个多视图数据集,包括0~9共10个手写数字的特征.数据集共有2 000个样本,每类200个,每个样本都由6个特征组成,分别是轮廓相关特征(mfeat_fac,216维)、傅立叶系数(mfeat_fou,76维)、K-L展开系数(mfeat_kar,64维)、像素平均(mfeat_pix,240维)、Zernike矩 特征(mfeat_zer,47维)、形态学特征(mfeat_mor,6维).
任选两个特征作为两个视图,共有15种组合方式.实验中,每类随机选取100个样本作为训练集,剩余样本作为测试集,该过程独立地重复20次.最后,采用最近邻法进行分类,以20次平均得出的结果作为最终的性能衡量指标.其中,计算MCA时的参数e设置为1.由于原数据特征的维度较高,先采用PCA对除形态学以外的特征进行降维,保持数据95%的能量.另外,实验后发现:实验结果较为稳定,重复多次实验得出结果的方差较小,所以表中并未列出方差.实验结果见表 1.
| Table 1 Test results on on multiple feature database 表 1 多特征手写数据集上的实验结果 |
在8个标准数据集(www.liacc.up.pt/∼ltorgo/Regression/DataSets.html)上进行对比实验.对每个数据集,为方便实验,依照原始标号的不同赋予其从1~l的新标号.实验中,前4个较小的数据集与后4个较大的数据集分别随机地以50%和30%的比例将每一类划分成训练集和测试集两部分,该过程独立地重复20次.最后,采用最近邻法进行分类,以20次平均得出的结果作为最终的性能衡量指标.其中,为了实验更能反映出各个方法性能,计算MCA值时,所需参数e的大小也随着各个数据集的标号不同而变化.参数设置及实验结果见表 2.
| Table 2 Test results on eight data sets 表 2 标准数据集上的实验结果 |
由表 1可见,在15种特征组合中:
(1) 从MCA指标来看:OR-DisCCA有8种组合性能优于其他方法,3种与CCA持平;DCCA有4种优于其他方法;CCA仅有1种优于其他方法,3种与OR-DisCCA持平;
(2) 从MAE指标来看:OR-DisCCA有9种组合性能优于其他方法,1种与CCA持平;DCCA有4种优于其他方法;CCA仅有1种优于其他方法,1种与OR-DisCCA持平.
由表 2可见,在8个标准数据集上:
(1) 从MCA指标来看:OR-DisCCA有5种性能优于其他方法,DCCA仅有1种优于其他方法,CCA有2种优于其他方法;
(2) 从MAE指标来看:OR-DisCCA有5种性能优于其他方法,1种与DCCA持平,DCCA有2种优于其他方法.
上述实验结果表明:在MFD数据集上,大多数特征组合方式无论是在MCA还是MAE,OR-DisCCA的性能都优于其他方法,其中有8种显著更优.在8个标准数据集上,OR-DisCCA整体上也体现出了更好的性能.此外,文献[22]中所提方法即使与最基本的CCA相比,其性能也无优势,这归咎于其将信息融合与判别信息提取的两个过程单独处理.这也再次表明了OR-DisCCA通过添加有序约束和对融合后信息的判别性特征提取,使数据投影后尽可能地保持了有序结构的同时,也能获得更好的有序回归特性.然而,我们的方法在某些数据集上也没有获得好的效果,比如在Abalone上,这可能是由于这些数据集本身的稀疏性或样本分布的非均匀性,导致对类均值估计的有偏.同时,由于某些样本点可能与其他同类样本点间距离间隔过大,使估计所得的类均值无法真实反映相关类的中心趋势,导致在投影空间中难以保持有序.
4 结论与展望本文在CCA基础上,对融合后的信息进行判别特征提取及有序信息嵌入,提出了OR-DisCCA.尽管CCA在处理多视图问题上简单有效,但并未利用类信息.LDA利用了数据总体信息,但并未利用类间有序信息.本文对CCA进行了拓展,提出的OR-DisCCA不仅保持了CCA能达成视图数据间尽量相关的要求,同时有效地利用类信息和有序信息,使获得的组合特征更适合有序分类.在标准数据集上的实验结果,验证了本方法的有效性.下一步的工作一是运用核方法将其推广到非线性情况,二是推广至更现实的视图间样本的半配对场景,三是在最后分类过程中使用其他分类器替代最近邻分类器.
| [1] | Hotelling H. Relations between two sets of variates. Biometrika, 1936,28(3/4):321-377 . |
| [2] | Hardoon DR, Szedmak S, Shawe TJ. Canonical correlation analysis: An overview with application to learning methods. Neural Computation, 2004,16(12):2639-2664 . |
| [3] | Yan Y, Xiu P, Zhi X. A new fuzzy approach for handling class labels in canonical correlation analysis. Neurocomputing, 2008, 71(7-9):1735-1740 . |
| [4] | Feng WW, Kim BU, Yu YZ. Real-Time data driven deformation using kernel canonical correlation analysis. ACM Trans. on Graphics, 2008,27(3):91 . |
| [5] | Li YO, Adali T, Wang W, Calhoun VD. Joint blind source separationbymultiset canonical correlation analysis. IEEE Trans. on Signal Processing, 2009,57(10):3918-3929 . |
| [6] | Sun QS, Zeng SG, Liu Y, Heng PA, Xia DS. A new method of feature fusion and its application in image recognition. Pattern Recognition, 2005,38(12):2437-2448 . |
| [7] | Peng Y, Zhang DQ, Zhang JC. A new canonical correlation analysis algorithm with local discrimination. Neural Processing Letters, 2010,31(1):1-15 . |
| [8] | Arandjelović Q. Discriminative extended canonical correlation analysis for pattern set matching. Machine Learning, 2014,94(3): 353-370 . |
| [9] | Ji Z, Jing P, Su Y, Pang Y. Rank canonical correlation analysis and its application in visual search reranking. Signal Processing, 2013,93(8):2352-2360 . |
| [10] | Sun TK, Chen SC, Yang JY, Shi PF. A novel method of combined feature extraction for recognition. In: Giannotti F, ed. Proc. of the 8th IEEE Int' Conf. on Data Mining. Los Alamitos: IEEE Computer Society, 2008. 1043-1048 . |
| [11] | Sun BY, Li JY, Wu DD, Zhang XM, Li WB. Kernel discriminant learning for ordinal regression. Knowledge and Data Engineering, 2010,22(6):906-910 . |
| [12] | Kramer S, Widmer G, Pfahringer B, Groeve MD. Prediction of ordinal classes using regression trees. Fundamenta Informaticae, 2001,47(1):1-13. |
| [13] | Herbrich R, Graepel T, Obermayer T. Large margin rank boundaries for ordinal regression. In: Solla SA, ed. Advances in Neural Information Processing Systems. Cambridge: MIT Press, 1999. 115-132. |
| [14] | Hsu CW, Lin CJ. A comparison of methods for multiclass support vector machines. IEEE Trans. on Neural Networks, 2002,13(2): 415-425 . |
| [15] | Smola AJ, Schölkopf B. A tutorial on support vector regression. Statistics and Computing, 2004,14(3):199-222 . |
| [16] | Crammer K, Singer Y. Pranking with ranking. In: Dietterich TG, ed. Proc. of the Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2001. 641-647. |
| [17] | Shashua A, Levin A. Ranking with large margin principle: Two approaches. In: Becker S, ed. Proc. of the Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2002. 937-944. |
| [18] | Chu W, Keerthi SS. New approaches to support vector ordinal regression. In: Raedt LD, ed. Proc. of the 22nd Int' Conf. on Machine Learning. New York: Association for Computing Machinery Press, 2005. 145-152 . |
| [19] | Li L, Lin HT. Ordinal regression by extended binary classification. In: Becker S, ed. Advances in Neural Information Processing Systems. Cambridge: MIT Press, 2002. 865-872. |
| [20] | Lin HT, Li L. Reduction of cost-sensitive ordinal ranking to weighted binary classification. Neural Computation, 2012,24(5): 1329-1367 . |
| [21] | Cardoso JS, Da Costa JFP. Learning to classify ordinal data: The data replication method. Journal of Machine Learning Research, 2007,8(6):1393-1429. |
| [22] | Kawashima T, Ogawa T, Haseyama M. A rating prediction method for e-commerce application using ordinal regression based on LDA with multi-modal features. In: Haraikawa T, ed. Proc. of the 2nd IEEE Global Conf. on Consumer Electronics. New York: IEEE Consumer Electronics Society, 2013. 260-261 . |
| [23] | Zhou XD, Chen XH, Chen SC. Combined-Feature-Discriminability enhanced canonical correlation analysis. Pattern Recognition and Artificial Intelligence, 2012,25(2):285-291 (in Chinese with English abstract). |
| [24] | Lu JW, Tan YP. Fusing shape and texture information for facial age estimation. In: Zoubir A, ed. Proc. of the 2011 IEEE Int' Conf. on Acoustics, Speech and Signal Processing. New York: IEEE Signal Processing Society, 2011. 1477-1480 . |
| [25] | Cootes TF, Edwards GJ, Taylor CJ. Active appearance models. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2001, 23(6):681-685 . |
| [23] | 周旭东,陈晓红,陈松灿.增强组合特征判别性的典型相关分析.模式识别与人工智能,2012,25(2):285-291. |