 2014, Vol. 25
2014, Vol. 25



2. 计算机网络和信息集成教育部重点实验室(东南大学), 江苏 南京 210096
2. Key Laboratory of Computer Network and Information Integration (Southeast University), Ministry of Education, Nanjing 210096, China
在多标记学习框架下,对于现实世界中的一个对象,学习系统在输入空间用一个示例(属性向量)刻画该对象的性质,在输出空间使用类别标记表征该对象的语义信息.多标记学习的目标是为现实世界中同时具有多个语义信息的对象建立分类模型,使得该模型可以有效地预测未见示例的所有相关类别标记[1].在实际应用中,存在很多同时具有多种语义信息的对象,例如:在文档分类应用中,一篇具有标记“科技”的文档,很有可能同时具有标记“经济”[2,3,4];多媒体内容标注应用中,一幅图像可能同时具有标记“大海”、“天空”以及“帆船”等[5,6,7].
形式化地,假设X=¡d代表d维的示例空间,y={l1,l2,…,lq}代表由q个类别标记组成的标记空间,多标记学
习系统的目标就是利用多标记训练集D={(xi,Yi)|1≤i≤m}学习得到一个分类器h:X®2y.其中,对于每一个多标记样本(xi,Yi),xiÎX为d维特征向量(xi1,xi2,…,xid)T,YiÍy为示例xi的相关标记集合.对于任何一个未见示例xÎX,多标记分类器h(×)可以预测其相关标记集合h(x)Íy.在很多情况下,多标记学习系统的输出对应于一组实值函
数{f1,f2,…,fq},其中,函数fk:X®¡(1≤k≤q)的返回值用于确定标记lk是否为当前待测示例的相关标记.此时,上述
的多标记分类器对应于h(x)={lk|fk(x)>0,1≤k≤q}.在过去的10年中,涌现出了大量的多标记学习算法[8],这些算法采用的共同策略是使用相同的属性集合预测所有的类别标记.换句话说,多标记学习系统返回的q个实值函数{f1,f2,…,fq}是由相同的属性集合训练得到的.
尽管上述策略在算法设计上取得了很大的成功,但是它可能并非最佳选择.举例来说,在图像语义标注系统中,直观上,我们可以认为颜色相关的属性(color-based feature)在判断“蓝天”这一标记上会有好的效果,而纹理相关的属性(texture-based feature)在判断“沙漠”这一标记上会有好的效果;在文本分类应用中,包含“政府”、“大选”等词汇的属性在判断“政治”这一标记上会有好的效果,而包含“GDP”、“纳税”等词汇的属性在判断“经济”这一标记上会有好的效果.上面的例子反映了一个事实,即,一个对象具有多种语义信息的原因在于该对象包含了描述这些语义信息的属性.换言之,每个标记可能具有其自身独特的属性特征,这些属性也是与该标记最相关、对该标记最具有判别能力的属性,称为类属属性(label-specific feature).基于此,文献[9]中提出了一种基于类属属性的多标记学习算法LIFT.该算法分为两个步骤:类属属性构造与分类模型训练.首先,LIFT在每个标记lkÎy的正类训练样本和负类训练样本上分别进行聚类分析,利用聚类结果构建标记lk的类属属性;然后,利用每
个标记的类属属性为该标记训练一个二类分类模型fk:X®¡(1≤k≤q),以此完成多标记学习任务.
本文在保留LIFT分类模型训练方法的同时,考察了另外3种多标记类属属性构造机制,从而实现LIFT的3种变体——LIFT-INSDIF,LIFT-MDDM以及LIFT-MLF.通过在12个数据集上进行的两组实验,验证了类属属性对多标记学习系统性能的影响以及LIFT采用的类属属性构造方法的有效性.
本文第1节介绍文献[9]中提出的LIFT算法.第2节给出多标记学习中已有的3种属性转换方法,并基于此设计LIFT的3种变体算法.第3节是本文的实验部分,包括算法参数设置、数据集、结果分析等.最后一节对本文工作进行总结.
1 LIFT算法多标记学习的最大挑战在于其输出空间的类别标记集合数将随着标记个数的增加成指数规模增长.因此,为有效应对输出空间过大带来的挑战,如何利用标记之间的相关性提高系统的泛化性能,被认为是多标记学习取得成功的关键[8,10].基于此,已有多标记学习算法的一个共同点在于:重点关注输出空间(标记空间)[11,12],即考察标记之间的相关性,而较少关注输入空间(属性空间).与已有策略不同,文献[9]通过构建类属属性对输入空间的性质进行了考察,提出了多标记学习算法LIFT.
给定多标记训练集D={(xi,Yi)|1≤i≤m},其中,对于每一个多标记样本(xi,Yi),xiÎX为d维属性向量(xi1,xi2,…,xid)T,YiÍy是示例xi的相关标记集合.基于此,LIFT算法的的两个步骤可按如下方式完成.
1) 类属属性构建
在该步骤中,LIFT的目的在于构建每个标记的类属属性,以提高多标记学习系统的学习性能.为了达到这个目的,需要考察每个标记所对应样本的内在性质.具体来说,对于标记lkÎy,其正类示例集合与负类示例集合分别为

换句话说,Pk与Nk分别是由具有标记lk的示例与不具有标记lk的示例组成的集合.
为了考察集合Pk与Nk的内在性质,LIFT在两个集合上分别进行聚类分析(clustering analysis).文献[9]中采
用简单且高效的k-means算法进行聚类分析.在此,将集合Pk的 个聚类中心记为
个聚类中心记为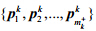 .相应地,将集合Nk的
.相应地,将集合Nk的 个聚类中心记为
个聚类中心记为 .为了应对可能存在的类别不平衡问题(即|Pk|<<|Nk|)[8],LIFT将Pk与Nk的聚类中心个数设置为相等,即
.为了应对可能存在的类别不平衡问题(即|Pk|<<|Nk|)[8],LIFT将Pk与Nk的聚类中心个数设置为相等,即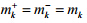 .如此,可以认为是对正类示例与负类示例的聚类信息赋
.如此,可以认为是对正类示例与负类示例的聚类信息赋
予相同的权重.具体来说,LIFT将示例集合Pk与Nk上的聚类个数设定为

其中,|·|返回集合的势,且rÎ[0,1]是控制聚类个数的参数.
由聚类的性质可知,Pk与Nk的聚类中心刻画了这两个集合中数据的内在结构.因此,聚类中心可以被用于构建标记的类属属性.本质上,类属属性的构建对应于一个从原d维属性空间X到新的d¢维属性空间Zk的映射jk:X®Zk(1≤k≤q).LIFT按如下公式定义映射jk:
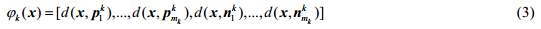
其中,d(×,×)返回两向量之间的距离,文献[9]中设置为欧氏距离.
2) 分类模型训练
在该步骤中,LIFT使用上一步中构造的类属属性分别训练q个分类模型{f1,f2,…,fq}.参照形式化定义,对于标记lkÎy,首先根据映射jk从原训练集D构造其相应的二类训练集BTk:

其中,若lkÎYi,则f(Yi,lk)返回+1;否则,返回-1.基于二类训练集BTk,可以使用任何一种二类分类算法B学习得到
标记lk对应的分类模型fk:Zk®¡.
对于未见示例uÎX,其相关标记按如下方式预测:

LIFT的伪码见文献[9].
2 多标记类属属性机制直观上看,解决多标记学习问题最简单的方法是:将多标记学习问题转换成为q个相互独立的二类分类问题,每一个二类分类问题对应于标记空间中的一个类别标记[5].基于此,Boutell等人在文献[5]中提出了多标记学习算法Binary Relevance(BR).针对第k个标记lk,BR首先构建该标记的二类训练集Dk={(xi,f(Yi,lk))|1≤i≤m}.
基于此,使用某种已有的二类分类算法B训练一个二类分类器gk:X®¡.在预测阶段,对于未见示例x,BR将q个
二类分类器上的预测结果作为该未见示例的相关标记集合,即,Y={lk|gk(x)>0,1≤k≤q}.
由此可见,BR中各二类分类模型的训练均基于相同的属性向量,即针对每个标记的类属属性映射为jk:X®X(1≤k≤q).因此,BR可以看作LIFT算法的一个退化版本(degenerated version).
如第1节所述,多标记类属属性机制本质上对应于构建从原d维属性空间X到新的d¢维属性空间Zk的映射jk:X®Zk(1≤k≤q).下面,本文将给出3种基于多标记类属属性机制的LIFT变体算法——LIFT-INSDIF,LIFT-MDDM以及LIFT-MLF.其中,对应于每个标记的二类分类模型使用不同的属性向量进行训练,而其二类分类模型的训练过程与LIFT保持一致.
· LIFT-MDDM
多标记降维是一种常用的多标记属性转换方式.在此,我们使用已提出的一种基于过滤策略的多标记降维算法MDDM[13]构建LIFT的变体算法LIFT-MDDM.MDDM使用希尔伯特-施密特独立标准(Hilbert- schmidt independence criterion,简称HSIC)度量原始属性空间X和标记空间y的关联度(dependency),通过最大化该关联度求得dxd¢维线性转换矩阵P(d¢<<d).最终,LIFT-MDDM针对每个标记的类属属性映射可通过矩阵P构建,即

· LIFT-INSDIF
如本文引言所述,一个对象具有多种语义信息的原因在于,该对象同时包含了描述这些语义的属性.因此,相比于使用单示例描述方式,使用多个示例描述一个对象能够更好地刻画该对象的多重语义信息[14].基于此,我们使用多标记学习算法INSDIF[15]中提出的属性转换方法构建LIFT的变体算法LIFT-INSDIF.通过将示例x与每个标记的正类样本集Pk={xi|(xi,Yi)ÎD,lkÎYi}的中心求差&l t;/ span>,INSDIF将示例x转换成为由q个示例组成的示例包,
即,{x(k)|1≤k≤q},其中, .由此可得LIFT-INSDIF中针对每个标记的类属属性映射:
.由此可得LIFT-INSDIF中针对每个标记的类属属性映射:

· LIFT-MLF
另一种多标记属性转换机制是由原属性空间X构建元级属性(meta-level feature),以此刻画示例和标记之间的关系.在此,我们使用算法MLF[16]中的元级属性构建方法,实现LIFT的变体算法LIFT-MLF.MLF将每个示例x转换为q×(3r+2)维的元级属性向量[y(x,l1),…,y(x,lq)],其中y(x,lk)(1≤k≤q)是由示例x与Pk中的r个近邻样本构造的3r+2维元级属性.具体来说,y(x,lk)是示例x与其r个近邻样本的L2距离、L1距离、余弦距离以及与Pk中心的L2距离、余弦距离的结合.由此可得LIFT-MLF中针对每个标记的类属属性映射:

由此可见,以上介绍的BR,LIFT-MDDM,LIFT-INSDIF,LIFT-MLF以及LIFT都是一阶算法[8],未考虑标记之间的相关性.同时,上述算法的区别在于类属属性的映射方式不同,其二类分类模型的训练过程完全一致.
3 实 验 3.1 数据集对于数据集S={(xi,Yi)|1≤i≤p},我们使用|S|,dim(S),L(S)及F(S)分别表示样本个数、属性个数、标记个数以及属性类型.除此之外,在此还给出了几种描述多标记数据集性质的统计量[8,17]:
· 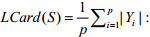 :标记基数(label cardinality),即每个样本具有的平均相关标记个数;
:标记基数(label cardinality),即每个样本具有的平均相关标记个数;
· 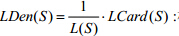 :标记密度(label density),即由标记个数归一化的标记基数;
:标记密度(label density),即由标记个数归一化的标记基数;
·  :标记多样性(label diversity),即数据集中不同标记集合的个数;
:标记多样性(label diversity),即数据集中不同标记集合的个数;
· 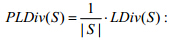 :归一化标记多样性,即由样本个数归一化的相异标记集.
:归一化标记多样性,即由样本个数归一化的相异标记集.
表 1按照样本数的多少概括了本文实验所用的数据集,其中包括6个常规规模的数据集(|S|≤5000)以及6个大规模的数据集(|S|>5000).此外,根据惯例对文本数据集rcv1(subset1),rcv1(subset2),eurlex(subject matter)以及tmc2007按照文档频率[18]进行了降维处理.其中,文档频率最高的2%的属性被保留作为最终属性.
| Table 1 Characteristics of experimental data sets 表 1 实验数据集性质 |
从表 1可以看出:这12个数据集涵盖了很多实际应用领域,且其多标记性质各不相同.由此可见,本文实验所用的数据集是比较充分且全面的,具有较强的概括性.
3.2 实验设置由于每个样本可能具有多个标记,故传统的单标记评价指标如精度(accuracy)、查准率(precision)、查全率(recall)等在多标记学习中不再适用[8].假设多标记测试集为T={(xi,Yi)|1≤i≤t},多标记学习系统返回的q个实值函数为{f1,f2,…,fq}.在本文的实验中,我们使用5种基于样本的多标记评价指标[3,19,20]来评价学习系统的性能:
· Hamming Loss
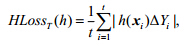
其中,h(xi)={lk|fk(xi)>0,1≤k≤q}对应于示例xi的相关标记集合,Δ返回两集合之间的对称差(symmetric difference).该评价指标考察样本在单个标记上的误分类情况,即:相关标记被预测为无关标记,或者无关标记被预测为相关标记.该评价指标取值越小,则系统性能越优,其最优值为0.
· Ranking Loss

该评价指标衡量错误排序的标记对的比例,即,无关标记排在相关标记之前的比例.该评价指标取值越小,则系统性能越优,其最优值为0.
· One-Error

其中,当谓词p成立时,§p¨返回1;否则返回0.该评价指标衡量在样本的类别标记排序中,排在第1位的标记不是
相关标记的样本所占的比例.该评价指标越小,则系统性能越优,其最优值为0.
· Coverage

其中,rankf(xi,l)对应于标记l根据{f1(xi),f2(xi),…,fq(xi)}的值降序排序后所处的位置.该评价指标衡量在测试集T上遍历到样本所有相关标记的平均查找深度.该评价指标取值越小,则系统性能越优,其最优值为1.
· Average Precision
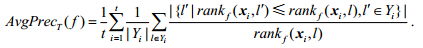
该评价指标考察在样本的标记排序序列中,排在该样本相关标记之前的标记仍为相关标记的比例.该评价指标取值越大,则系统性能优越,其最优值为1.
为便于对比,本文通过除以标记个数L(S)将评价指标Coverage规格化到区间[0,1].上述基于样本的评价指标首先衡量学习系统在每个测试样本上的分类性能,然后返回整个测试集的均值作为最终结果.
此外,本文还采用一种基于标记的评价指标Macro-averaging AUC[21].与基于样本的评价指标不同,基于标记的评价指标首先衡量学习系统在每个标记上分类性能,然后返回在所有标记上的均值作为最终结果.
· Macro-averaging AUC
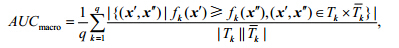
其中, 分别对应于含有标记lk的测试样本集合与不含有标记lk的测试样本集合.值得注意的是,上述公式可由AUC与Wilcoxon-Mann-Whitney统计量的相互关系导出[22].此外,该评价指标取值越大,系统的性能越优,其最优值为1.
分别对应于含有标记lk的测试样本集合与不含有标记lk的测试样本集合.值得注意的是,上述公式可由AUC与Wilcoxon-Mann-Whitney统计量的相互关系导出[22].此外,该评价指标取值越大,系统的性能越优,其最优值为1.
本文将给出6种算法在上述12个数据集上的实验结果,包括BR,ML-kNN,LIFT,LIFT-MDDM,LIFT-INSDIF以及LIFT-MLF.根据文献[9],设定LIFT的参数r=0.1;根据文献[23],设定ML-kNN的近邻个数k=10;对于LIFT-MDDM,为与原文保持一致,控制转换后特征空间维度(即d¢)的参数thr设定为99.9%;对于LIFT-MLF,我们采取原文的策略,对近邻个数r在区间[10,100]进行调节,并最终设定为10.此外,为了对比的公平,所有算法的基二类分类器均使用线性核LIBSVM[24].
3.3 结果分析在每个数据集中,我们采用无放回抽样选取50%的样本构成训练集,余下的50%样本构成测试集,抽样过程重复10次并记录10次实验的均值和方差.
本文共有两组实验:第1组将没有使用类属属性机制的BR以及常用的ML-kNN算法与采用类属属性机制的算法LIFT,LIFT-MDDM,LIFT-INSDIF以及LIFT-MLF进行对比,目的在于验证类属属性机制对多标记学习的影响;第2组将LIFT与算法LIFT-MDDM,LIFT-INSDIF,LIFT-MLF进行对比,目的在于验证LIFT所采用的类属属性构建方法的有效性.
表 2与表 3给出了6个算法在12个数据集上的实验结果,实验结果采用均值±方差(mean±std)的形式表示.对于每个评价指标,表示其值越大,性能越优;相应地,¯表示其值越小,性能越优.此外,对比算法中性能的最好的结果使用黑体标出.
| Table 2 Predictive performance of each comparing algorithm (mean±std) on the six regular-scale data sets 表 2 对比算法在6个常规规模数据集上的实验结果(mean±std) |
| Table 3 Predictive performance of each comparing algorithm (mean±std) on the six large-scale data sets 表 3 对比算法在6个大规模数据集上的实验结果(mean±std) |
对于第1组实验,我们分别统计了BR,ML-kNN与LIFT及其变体算法在12个数据集、6个评价指标上的72个对比结果.与LIFT和LIFT-INSDIF相比,BR没有胜出的情况;与LIFT-MDDM相比,胜出的情况仅占5.56%;与LIFT-MLF相比,胜出的情况占44.44%.与LIFT,LIFT_INSDIF以及LIFT_MDDM相比,ML-kNN胜出的情况分别仅占6.9%,15.3%以及30.6%;与LIFT_MLF相比,胜出的情况占66.7%.从BR,ML-kNN与LIFT,LIFT-INSDIF,LIFT-MDDM的对比结果可以看出,有效的类属属性可以较大程度地提高多标记学习算法的学习性能.值得注意的是,LIFT-MLF的性能在一些数据集上比BR,ML-kNN的性能差.一个可能的原因是,该算法使用近邻样本构造元级属性的方式不能有效地构造标记的类属属性.可见,并非所有的属性转换机制都能十分有效地地构造类属属性.
如第2节所述,BR可认为是LIFT及其变体算法的退化(degenerated)版本.为了进一步验证类属属性对多标记学习算法的影响,对于每个评价指标,本文使用成对T检验(检验水平a=0.05)对BR与LIFT及其变体算法进行统计分析(见表 4(a)).表 4(a)中的结果进一步证实了上述结论,即:类属属性是提高多标记学习系统泛化性能的可行途径,但并非所有的多标记属性转换机制都能有效地构建类属属性.
| Table 4(a) Paired T-test results (win/tie/lose) of comparing BR against algorithms with label-specific features mechanism in terms of each criteria on the total twelve data sets at significance level a=0.05 表 4(a) 对于每个评价指标,BR与使用类属属性机制算法在12个数据集上的成对T检验(a=0.05)结果(win/tie/lose) |
与第1组实验相同,我们统计了LIFT及其3个变体算法在12个数据集、6个评价指标上的72个对比结果.其中,LIFT排在第1位的情况占87.5%,排在第2位和第3位的情况分别仅占11.11%和1.39%,且没有排在最后一位与倒数第2位的情况发生.由以上统计可以看出,LIFT的学习性能优秀,进而说明LIFT的类属属性构造方法是非常有效的.
参考第1组实验,本文使用成对T检验(检验水平a=0.05)对LIFT及其3种变体算法在每个数据集上的实验结果进行统计分析(见表 4(b)).从表 4(b)中可以看出:
| Table 4(b) Paired T-test results (win/tie/lose) of comparing LIFT against its variants in terms of each criteria on the total twelve data sets at significance level a=0.05 表 4(b) 对于每个评价指标,LIFT与其变体算法在12个数据集上的成对T检验(a=0.05)结果(win/tie/lose) |
(a) 在绝大多数情况下,LIFT的分类性能优于其他3种变体算法——LIFT-INSDIF,LIFT-MDDM以及LIFT-MLF.在很少数据集的个别评价指标上,LIFT的性能差于LIFT-INSDIF以及LIFT-MDDM;
(b) 除了评价指标One-Error及Coverage,LIFT-INSDIF与LIFT-MDDM在其余4个评价指标上的结果相当.LIFT与LIFT-INSDIF的性能优于或至少相当于LIFT-MDDM的性能,这说明相比于通过属性选择赋予每个标记相同的类属属性(即公式(6)),为每个标记构造不同的类属属性(即公式(3)与公式(7))是一种更有效的属性转换机制;
(c) 与表 4(a)中得到的结论一致,在每个评价指标上,LIFT-MLF的性能都要差于其余3种算法.可能的原因是,该算法使用近邻样本构造元级属性(即公式(8))的方式不能有效地构造标记的类属属性.
概括来说,表 4(b)中的成对T检验统计结果证明了LIFT中的属性转换机制能非常有效地构造类别标记的类属属性.因此,LIFT的类属属性机制可以作为很多多标记学习算法的预处理(pre-processing)部分,以提高学习系统的学习性能.
4 总 结与许多关注标记空间的算法不同,本文考察在属性空间进行操作对多标记学习算法学习性能的影响.本文在12个数据集上进行了大量的实验,将LIFT及其变体算法与BR进行对比分析,结果显示:有效的类属属性构造,的确能较大程度地提高多标记学习算法的学习性能.同时,LIFT与其变体算法的统计检验结果表明,LIFT的属性转换机制可有效地构造类别标记的类属属性.
值得注意的是,本文中所有算法均忽略标记之间的相关性.未来,我们可以尝试将类属属性和标记之间的相关性相结合,一种直观的方式是,为与标记配对相关的分类器[25]设计对应的二阶类属属性.
| [1] | Liu DY, Yang K, Tang HY, Chen JZ, Yu QY, Chen GF. A convex evidence theory model. Journal of Computer Research & Development, 2000,37(2):175-181 (in Chinese with English abstract). |
| [2] | Han JF. Research on the synthesis of comfort degree for fuzzy sensors based on temperature and humidity. Journal of Transducer Technology, 2002,21(6):19-24 (in Chinese with English abstract). |
| [3] | Nakamura EF, Loureiro AAF, Frery AC. Information fusion for wireless sensor networks: Methods, models, and classifications. ACM Computer Survey, 2007,39(3):9 . |
| [4] | Bahador K, Alaa K, Fakhreddine OK, Saiedeh NR. Multi-Sensor data fusion: A review of the state-of-the-art. Information Fusion, 2013,14:28-44 . |
| [5] | Debasis B, Jaydip S. Internet of things: Applications and challenges in technology and standardization. Wireless Personal Communications, 2011,58:49-69 . |
| [6] | Otman B, Yuan XH. Engine fault diagnosis based on multi-sensor information fusion using Dempster-Shafer evidence theory. Information Fusion, 2007,8(4):379-386 . |
| [7] | Suvasini P, Amlan K, Shamik S, Majumdar AK. Credit card fraud detection: A fusion approach using Dempster-Shafer theory and Bayesian learning. Information Fusion, 2009,10(4):354-363 . |
| [8] | Yee L, Ji NN, Ma JH. An integrated information fusion approach based on the theory of evidence and group decision-making. Information Fusion, 2013,14(4):410-422 . |
| [9] | Brice M, Michael AW, Joanne CW. An approach using Dempster-Shafer theory to fuse spatial data and satellite image derived crown metrics for estimation of forest stand leading species. Information Fusion, 2013,14(4):384-395 . |
| [10] | Yang Y, Liu DY, Wu LZ, Wang WY. An important extension of an evidence-theory based inexact reasoning model. Chinese Journal of Computers, 1990,13(10):772-778 (in Chinese with English abstract). |
| [11] | Liu DY, Ouyang JH, Tang HY, Chen JZ, Yu QY. Research on a simplified evidence theory model. Journal of Computer Research & Development, 1999,36(2):134-138 (in Chinese with English abstract). |
| [12] | Zhang T, Ramakrishnan R, Livny M. BIRCH: An efficient data clustering method for very large database. In: Proc. of the ACM SIGMOD Int’l Conf. on Management of Data. 1996. 103-114 . |
| [13] | Han JW, Kamber M, Pei J. Data Mining: Concepts and Techniques. 3rd ed., Beijing: China Machine Press, 2012 (in Chinese). |
| [14] | Chiu T, Fang DP, Chen J. A robust and scalable clustering algorithm for mixed type attributes in large database environment. In: Proc. of the 7th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. 2001. 263-268 . |
| [15] | Xiao JY, Tong MM, Zhu CJ, Wang XL. Basic probability assignment construction method based on generalized triangular fuzzy number. Chinese Journal of Scientific Instrument, 2012,33(2):429-434 (in Chinese with English abstract). |
| [16] | Deng Y, Zhu ZF, Zhong S. Fuzzy information fusion based on evidence theory and its application in target recognition. Acta Aeronautica et Astronautica Sinica, 2005,26(6):754-758 (in Chinese with English abstract). |
| [17] | Xie DP, Qin HF, Yu CB. Research of monitoring system for indoor comfort degree based on fuzzy theory. China Measurement & Testing Technology, 2008,34(4):126-128 (in Chinese with English abstract). |
| [1] | 刘大有,杨鲲,唐海鹰,陈建中,虞强源,陈桂芬.凸函数证据理论模型.计算机研究与发展,2000,37(2):175-181. |
| [2] | 韩峻峰.基于温湿度的模糊传感器舒适度合成法研究.传感器技术,2002,21(6):19-24. |
| [10] | 杨莹,刘大有,吴立真,王伟元.对一种基于证据理论的不确定性处理模型的重要扩充.计算机学报,1990,13(10):772-778. |
| [11] | 刘大有,欧阳继红,唐海鹰,陈建中,虞强源.一种简化证据理论模型的研究.计算机研究与发展,1999,36(2):134-138. |
| [13] | 韩家炜,Kamber M,裴健.数据挖掘:概念与技术.第3版,北京:机械工业出版社,2012. |
| [15] | 肖建于,童敏明,朱昌杰,王小蕾.基于广义三角模糊数的基本概率赋值构造方法.仪器仪表学报,2012,33(2):429-434. |
| [16] | 邓勇,朱振福,钟山.基于证据理论的模糊信息融合及其在目标识别中的应用.航空学报,2005,26(6):754-758. |
| [17] | 谢东坡,秦华锋,余成波.基于模糊理论的室内环境舒适度监测系统研究.中国测试技术,2008,34(4):126-128. |