 2014, Vol. 25
2014, Vol. 25



2. 南京师范大学 计算机科学与技术学院, 江苏 南京 210023
2. School of Computer Science and Technology, Nanjing Normal University, Nanjing 210023, China
多标记学习是机器学习、模式识别等领域的研究热点之一.在多标记学习框架中,每个样本由一个特征向量表示,但可能同时隶属于多个类别标记,其目标是通过学习给定的多标记训练集有效地预测未知样本所属的类别标记集合.然而,在传统的监督学习(也称为单标记学习)框架中,每个样本由一个示例表示,但只隶属于一个类别标记(不管标记是两个还是多个).当每个样本只与一个类别标记相关时,多标记学习问题将退化为单标记学习问题.因此,单标记学习问题本质上是多标记学习问题的一种特殊情况[1].
多标记学习概念的提出,源于研究文本分类时所遇到的歧义性问题[2].在文本分类问题中,一篇文档可能同时与多个预先定义的主题相关[2,3],例如“篮球赛”和“体育”.近年来,多标记学习问题得到了广泛的关注[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26].在现实世界中,多标记学习问题也涉及其他研究领域,例如自动图像标注[4]、视频自动标记[5]以及生物信息学[3,6]等.在自动图像标注中,每张图像可能同时标注为多个语义概念类[4],例如“草地”、“树木”和“建筑”等.在视频自动标记中,每段视频片段可标记为多个类别[5],例如“表演”、“唱歌”和“跳舞”.在生物信息学中,每段基因序列可能具有多种功能[3,6],例如“转录”、“蛋白质合成”以及“新陈代谢”.在情感分类中,每个音乐片段可能包含多种情感,例如“欢快的”和“轻松的”.
近十几年来,许多学者致力于多标记学习问题的研究,提出了大量的多标记学习算法,并成功地应用于各个研究领域(如文本分类、图像和视频自动标记以及生物信息学等),例如基于Boosting的多标记文本分类算法(BoosTexter)[2]、多标记分类问题的核方法(RankSvm)[6]、多标记懒惰学习方法(MLkNN)[7]、校准标记排序算法(CLR)[8]以及集成的多标记分类器链算法(ECC)[9]等.一种最直接、最简单的方法是将多标记学习问题分成多个独立的二分类问题[4],其中每个对应一个标记,将属于该标记的样本看成正类,否则看成负类.对于未知样本,根据其在所有二分类器上的输出结果来预测所属的标记集合.该方法简单,但没有考虑标记之间的相关性.实际上,对于某个标记来说,如果充分利用其他相关的标记信息,可能更有利于其学习,尤其是当没有足够的训练样本时,标记之间的相关性可提供额外的有用信息[10].例如,一幅图像标记了“山”和“水”,则很可能也标记为“树”;一篇文档隶属于“奥斯卡”和“明星”,则很可能也隶属于“娱乐”;一段音乐标记为“欢乐的”,则不太可能标记为“悲伤的”.因此,如何有效地利用标记之间的相关性,是当前多标记学习问题的一个重要研究问题[1,10,11].
许多多标记学习算法试图利用标记之间的相关信息来提高多标记学习系统的泛化性能.例如,文献[3,6,8]考虑了标记对之间的相关性有效地提高系统的泛化性能.但是在真实世界中,一个标记可能与多个标记同时相关.文献[9]考虑了所有可能的标记之间的相关性,即对每个标记的学习都考虑了其他相关标记的影响.文献[12]考虑了随机标记子集之间的相关性.大多数多标记学习算法将标记之间的相关性作为先验知识或是计算标记的共现性,而标记之间的相关性可能事先很难准确获得.文献[11]提出多标记假设重用(MAHR)算法,可以自动地挖掘和利用标记之间的相关性,通过重用权重计算出标记之间的相关值,同时也发现标记之间的相关性是不对称的.据我们所知,很少有学者将多标记分类和标记相关性进行联合学习.< /p>
因此,本文提出了多标记分类和标记相关性的联合学习(joint learning of multi-label classification and label correlations,简称JMLLC).首先,为每个标记构建二分类器,每个标记不仅依赖于输入特征向量而且也依赖于其他标记变量;其次,构建了多标记分类和标记相关性的联合学习模型,同时,根据选择不同的损失函数(即logistic回归损失函数和最小二乘损失函数),分别推导出JMLLC-LR和JMLLC-LS算法,并首先在原始特征空间中学习,然后拓展到再生核希尔伯特空间中;最后,JMLLC-LR和JMLLC-LS模型都可转化为凸优化问题,并且可以采用交替迭代求解的方法进行模型求解.本文的主要贡献如下:
1) 构建了多标记分类和标记相关性的联合学习模型,自动挖掘和利用了高阶非对称的标记相关性,丰富了多标记学习和标记相关性等问题的研究;
2) 模型拓展性强,可以选择不同的凸损失函数,而且最终的优化问题可以转化为凸优化问题,并可以通过交替求解的方法进行模型求解;
3) 模型不仅可以在原始空间中学习,同时也可以拓展到再生核希尔伯特空间中学习.
1 相关工作 1.1 多标记学习已提出的多标记学习算法大致可以分成两大类[1,12,13]:问题转化方法(problem transformation methods,简称PTM)和算法改编方法(algorithm adaptation methods,简称AAM).
1.1.1 问题转化方法(PTM)PTM将多标记学习问题转化为其他已知的学习问题,例如两类问题、多类问题和标记排序问题等.
BR(binary relevance)方法[4]是将多标记学习问题转化为若干个独立的二分类学习问题,该方法简单,而且每个二分类器可以单独学习,因此可以并行实现,但是忽略了标记之间的相关信息,系统的性能可能只达到次优而未达到最优.CC(classifier chains)[9]的基本思想是:将多标记学习问题转化为基于BR方法的分类器链,其中在分类器链中,后面分类器的构建是建立在前面的分类器基础上.该方法考虑了标记之间的相关性,实现了较高的预测性能,时间复杂度低,同时也保留了BR方法的优点.然而,链是随机排列的,随机地考虑了标记之间的相关性;而且当第1个分类器预测性能不好时,误差的影响可能随着链进行传播.为了克服这些不足,提出了多标记分类器链集成算法(ensembles of classifier chains,简称ECC)[9].
LP(label powerset)方法直接将多标记学习问题转化为多类学习问题:首先,将训练集中存在的所有不同的类别标记子集进行二进制编码,每个编码值看成不同的类别值,即多标记数据集转化为多类数据集;然后,训练多类分类器.当给定一个未知样本时,首先根据训练得到的多类分类器对其进行预测;然后将该预测值转化为二进制编码,从而得到其所属的类别标记集合.LP方法简单,但主要不足有:1) 当类别标记个数很多时,转化为多类数据集后,相应的新类别值个数会很多,从而导致有些新的类别值只有少量的训练样本以及训练时间开销大;2) 难以预测训练集以外的类别标记集合.为了保留LP方法的优点同时又克服其不足,提出了随机k标记集(random k-labelsets,简称RAkEL)[12]算法.RAkEL的基本思想是,将多标记学习问题转化为集成的多类学习问题:首先,从初始的类别标记集中随机地选择k个标记子集;然后采用LP方法,学习得到一个多类分类器;最后,建立一个集成的LP模型,通过阈值法或投票法预测未知样本的类别标记集合.
另一种被广泛应用的PTM方法是LR(label ranking)[14],其基本思想是:通过标记成对比较,将多标记学习问题转化为标记排序问题.在为每个标记对(yl,yk)构建两类分类器时,将属于类别标记yl但不属于类别标记yk的样本看成是正类样本,将属于类别标记yk但不属于类别标记yl的样本看成是负类样本,忽略其他的样本.给定一个未知样本,对每个二分类器的预测值进行投票,通过阈值法将排序后的投票结果划分为该样本的相关标记和不相关标记.该方法的主要难点在于:如何确定阈值来尽可能正确地估计样本所属的类别标记集合.为了解决这个问题,文献[8]提出了校准的标记排序算法(calibrated label ranking,简称CLR).与LR相比,给每个样本的类别标记集添加一个额外的虚拟标记yv,将其作为每个样本的相关标记和不相关标记的一个自然划分点;同时,也要将每个标记与虚拟标记进行成对比较,在对某个标记对(yl,yv)构建两类分类器时,将属于类别标记yl的样本看成正类样本,否则看成负类样本.对于给定的未知样本,将所有二分类器的预测结果进行投票,然后排序,将那些投票次数大于虚拟标记yv的类别标记看成该样本的相关标记,否则看成不相关标记.
1.1.2 算法改编方法(AAM)AAM是直接设计多标记学习算法处理多标记数据,即改编一些著名的算法来直接处理多标记数据.
文献[2]提出了多标记文本分类算法(BoosTexter),是著名的集成算法Adaboost的拓展.文献[2]采用了两种不同的方法来拓展Adaboost,包括Adaboost.MH和Adaboost.MR,其中:Adaboost.MH目的是为了最小化汉明损失;而Adaboost.MR的目标是最小化排序损失,尽量使相关的标记排在前面.
RankSvm算法[6]将经典的支持向量机(SVM)推广到多标记学习问题中.在RankSvm中,为每个类别标记构建一个SVM分类器,其中,经验损失项为排序损失.该方法利用排序损失考虑每个样本的相关标记和不相关标记,且目标优化问题可以转化为一个二次规划问题.由于需要计算大量的变量,故训练时间开销比较大.文献[15]基于SVM设计并实现了一个比RankSvm更高效的多标记分类算法(Rank-CVM).文献[16]通过引入近似的排序损失作为经验损失项,将传统的两类SVM拓展到多标记分类中,提出了拓展的 一对多多标记SVM算法(OVR-ESVM).文献[17]在RankSvm模型的基础上增加了未标记样本的损失项以及未标记样本的预测值的均值与已标记样本的真实标记均值相等的约束项,提出了一种归纳的多标记分类算法(iMLCU).
文献[7]提出了一种懒惰的多标记学习方法(MLkNN),是由传统的k近邻算法衍生出来的.对于每个测试样本,首先确定它的k个近邻样本;然后根据k个近邻样本的标记信息,用最大后验概率(MAP)准则预测它的类别标记集合.该方法简单,时间复杂度低;但独立地计算每个标记的先验概率和后验概率,没有考虑标记之间的相关信息.为此,文献[18]针对MLkNN中存在的不足,提出了一种新型多标记懒惰学习算法(IMLLA).该方法充分利用了训练数据的分布信息以及多个标记之间的相关信息.
文献[19]设计了基于朴素贝叶斯的多标记分类算法(MLNB),同时将特征选择机制加入到MLNB算法中.首先,用基于主成分分析(principal component analysis,简称PCA)的特征提取技术,将原始特征空间投影到低维的特征空间中;然后,用基于遗传算法(genetic algorithm,简称GA)的特征选择技术,选择最合适的特征子集来提高MLNB的预测精度.文献[20]将贝叶斯学习技术应用到多标记学习中,提出了用贝叶斯网络结构模型标记依赖性的多标记学习方法(LEAD).LEAD是一个两阶段学习算法,首先通过贝叶斯网络学习标记依赖性,然后再进行分类.此外,文献[3]提出了基于后向传播神经网络的多标记学习算法(BPMLL);文献[21]提出了用决策树技术处理多标记数据的算法ML-DT;文献[22]采用最大熵原理来处理多标记数据,提出了CML算法.
1.2 标记相关性在多标记学习中,每个样本可能同时隶属于多个类别标记,标记之间的相关信息可能会为多标记问题的学习提供额外的有用信息,从而有利于提升多标记学习系统的性能.因此,如何有效地利用标记之间的相关性,是当前研究多标记学习问题的核心内容.
根据多标记学习算法中考虑的标记之间的相关性的阶,将存在的方法大致可以划分为3类[1]:
1) 一阶策略:每个标记独立地处理,完全不考虑标记之间的相关性.例如,将多标记学习问题转化为多个独立的二分类问题[4].该方法简单,但由于忽略了标记之间的相关信息,学习算法的性能可能没有达到最优;
2) 二阶策略:考虑了标记之间的成对关系.例如,将多标记学习问题转化为标记排序问题[8,14].然而在一些实际应用中,标记之间的相关性可能会超过二阶;
3) 高阶策略:考虑了每个标记与其他标记之间的相关性或者随机的标记子集之间的相关性.该方法挖掘了很强的标记相关性,但是可能会导致计算更复杂.例如,ECC[9]和RAkEL[12]算法.
文献[23]假设多个标记共享一个子空间,标记之间的相关性通过多个标记所共享的低维子空间来获得,但并未显式地描述标记之间的相关性.很多利用标记之间相关性的方法都是假定标记之间的相关性是对称的或者事先确定的.然而,标记之间的相关性并非一定是对称的,且很难事先就确定.因此,文献[11]提出了标记之间的相关性是非对称的且可以正相关也可以负相关,并通过学习求解出了标记相关性矩阵,但求出的标记相关性矩阵并未用于最后的模型预测中.文献[24]采用标记协方差矩阵来显示地描述标记之间的相关性(可以正相关、不相关或负相关),而且标记相关性可以从数据中自动学习而不用事先确定,并可以同时学习标记相关性和模型参数,但是只能求出成对标记相关性.在文献[25,26]中,构建了基于类别标记变量的条件依赖网络,其中每个节点对应一个标记,且每个标记将其他的标记变量和输入特征变量看成为其父节点,用结构化的标记依赖特征来挖掘标记之间的相关性.然而对于每个测试样本,其在第l个概率预测函数上的预测值依赖于其他标记变量的值.而实际上,其他变量的值并非事先知道,不过可以采用Gibbs采样方法进行推理,但过程繁琐且非常耗时.
因此,本文构建基于类别标记变量的条件依赖网络,每个标记的学习依赖于输入变量和其他的类别标记;然后构建了多标记分类和标记相关性的联合学习模型,该模型最终可转化为凸优化问题,可采用交替求解的方法进行求解,且预测过程简单.与文献[23]相比,本文不需要假设多个标记共享一个子空间,可直接在原始空间中自动求解标记相关性,并显式地描述了标记之间的相关性.与文献[11]相比,本文的算法将求出的高阶非对称的标记相关性用于模型的预测中.与文献[24]一样,都是同时学习标记相关性和参数模型,但本文可求出高阶的标记相关性.与文献[25,26]相比,本文提出了将标记相关性和分类器进行联合学习,且预测过程非常简单.
2 多标记分类和标记相关性的联合学习(JMLLC) 假设给定训练数据集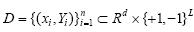 .其中,xiÎRd表示第i个训练样本,YiÎ{+1,-1}L表示其对应的类别标记向量,d为特征空间维数,L为类别标记个数.如果第i个样本属于第l个类别标记,则Yil=+1;否则,Yil=-1.为了方便表示,记数据矩阵X=[x1,…,xn]T,类别标记指示矩阵Y=[Y1,…,Yn]T.
.其中,xiÎRd表示第i个训练样本,YiÎ{+1,-1}L表示其对应的类别标记向量,d为特征空间维数,L为类别标记个数.如果第i个样本属于第l个类别标记,则Yil=+1;否则,Yil=-1.为了方便表示,记数据矩阵X=[x1,…,xn]T,类别标记指示矩阵Y=[Y1,…,Yn]T.
首先,将多标记学习问题转化为L个独立的二分类问题,其中,第l个标记的分类判别函数为

该方法简单,但主要的不足在于没有考虑标记之间的相关信息,而这些信息有利于提高系统的泛化性能.因此,如何将多标记学习问题转化为求解L个二分类问题的同时又考虑标记之间的相关性,是本文需要研究和解决的问题.受依赖网络(DN)模型[27]以及文献[25,26,28]的启发,构建基于类别标记变量的条件依赖网络,其中,每个节点代表一个类别标记,每个类别标记将输入特征变量和其他的类别标记作为其父节点.因此,每个分类器的构建依赖于输入特征变量和其他类别标记,则第l个类别标记最终所对应的预测函数表示如下:

其中,wlÎRd和blÎR分别表示第l个预测函数所对应的权重向量和偏差,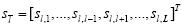 表示标记相关权重向量.
表示标记相关权重向量.
文献[25,26]中,第l个概率预测函数虽然依赖于输入特征向量和其他标记变量,但 是已知的训练数据,在每次迭代学习的过程中是固定的,则学习wl时,只依赖于标记相关权重向量,而没有考虑其他的权重向量{w1,…,wl-1,wl+1,…,wL}.与文献[25,26]不同的是,本文令
是已知的训练数据,在每次迭代学习的过程中是固定的,则学习wl时,只依赖于标记相关权重向量,而没有考虑其他的权重向量{w1,…,wl-1,wl+1,…,wL}.与文献[25,26]不同的是,本文令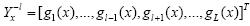 ,而不是一个固定的向量.这样,在学
习某个wl时,不仅考虑了其他的权重向量,而且也考虑了标记相关权重向量
,而不是一个固定的向量.这样,在学
习某个wl时,不仅考虑了其他的权重向量,而且也考虑了标记相关权重向量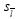 ,这样
,这样
不仅可以使得原本各自独立的标记分类器可以联合起来同时学习,从而增强了各个标记分类器的学习效果,而且多标记分类和标记相关性也联合起来同时学习,使得学习得到的标记相关性更为准确.另外,本文为每个标记构建相应的预测函数,而非概率预测函数,因此可以选择不同的损失函数,模型可扩展性强.在预测阶段,文献[25,26]需要通过Gibbs采样方法来进行预测,而本文的预测过程非常简单.最后,公式(2)可以写成:
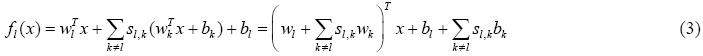
令S=[s1,…,sL]ÎRLxL,sl=[sl,1,…,sl,l-1,sl,l+1,…,sl,L]TÎRL,则公式(3)可表示为

其中,W=[w1,…,wL]ÎRdxL,b=[b1,…,bL]ÎR1xL.
因此,多标记分类和标记相关性的联合学习模型如下:
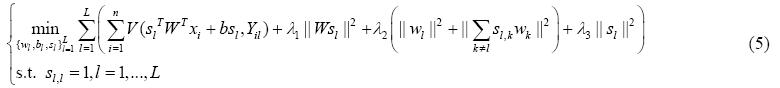
其中,V代表损失函数,正则化项||Wsl||2用于控制模型的复杂度,||wl||2用于控制单个类别标记所含的信息量,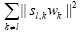 用来控制其他相关标记所含的信息量,||sl||2用来控制相关系数的大小.l1,l2和l3为正则化参数,用来权衡这4项.
用来控制其他相关标记所含的信息量,||sl||2用来控制相关系数的大小.l1,l2和l3为正则化参数,用来权衡这4项.
在以下两节中,我们分别选择两种不同的损失函数,即logistic回归损失函数和最小二乘损失函数.对于每个模型,首先定义在原始特征空间中,然后拓展到再生核希尔伯特空间(RKHS)中.
2.2 JMLLC-LR (JMLLC with logistic regression) 首先,选择logistic回归损失函数,即:
公式(5)可表示如下:

公式(6)的求解,采用交替迭代求解的方法.
1) 固定S,求W和b
当S固定时,公式(6)中的第4项为常数项,因此可以忽略.同时,约束条件也可以忽略.则公式(6)可重新写成:

公式(7)的目标函数是一个凸函数,并可重写成如下:
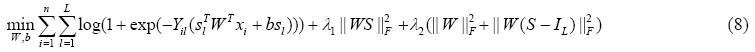
其中,IL为LxL的单位矩阵.
2) 固定W和b,求S
当W和b固定时,公式(6)中第3项的第1部分为常数项,因此可以忽略,则公式(6)可表示为
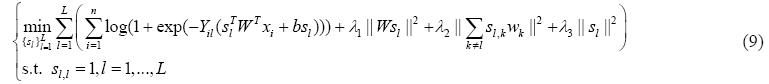
公式(9)的目标函数是一个凸函数,且可以进一步地分解成L个独立的优化问题.其中,第l个优化问题为

其中,el为L维的列向量,其第l个元素为1,其余为0.
2.2.2 在RKHS中学习现将JMLLC-LR拓展到再生核希尔伯特空间中.根据表示理论[29],可将wl表示如下:

其中,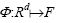 表示由核引导的特征映射.
表示由核引导的特征映射.
将公式(11)代入到公式(6)中可得:

其中,A=[a1,…,aL]ÎRnxL,al=[al1,…,aln]TÎRn表示第l个预测函数所对应的系数向量,K为nxn的Gram矩阵,ki表示核矩阵K的第i列.
公式(12)的求解,采用交替迭代求解的方法.
1) 固定S,求A和b
当S固定时,公式(12)中的第4项为常量,因此可以忽略;同时,约束条件也可以忽略.则公式(12)可以重新表示为
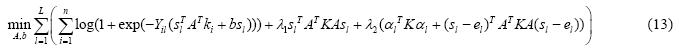
公式(13)的目标函数是一个凸函数,并且可进一步写成:
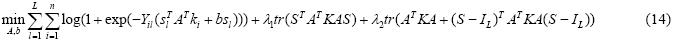
其中,tr(×)表示矩阵的迹.
2) 固定A和b,求S
当A和b固定时,公式(12)中第3项的第1部分为常数项,因此可以忽略,则公式(12)可重新写成如下:
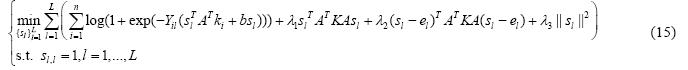
公式(15)的目标函数是一个凸函数,且可以进一步分解成L个独立的优化问题.其中,第l个优化问题如下:
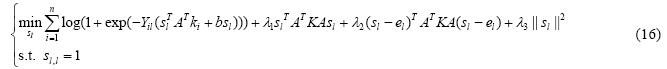
为了简单起见,假设X和Y已经中心化,此时,偏差都为0.我们选择最小二乘损失函数,即:
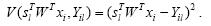
当公式(5)中的损失项为最小二乘损失函数时,可以得到最终的模型如下:
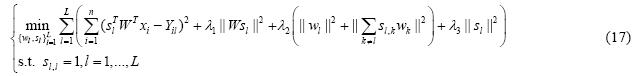
定理1. 采用交替迭代求解的方法求解公式(17).其中,
· 当S固定时,W可通过求解一个Sylvester方程求得:

其中,B=(XTX+l1Id)-1,C=(l2IL+l2(S-IL)(S-IL)T)-1,Id为dxd的单位矩阵;
· 当W固定时,S可通过求解下式来求得:
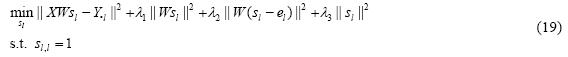
其中,Y·l=[Y1l,…,Ynl]T,即标记指示矩阵Y的第l列;el为L维的列向量,其第l个元素为1,其余为0.
证明:用交替求解的方法来求解公式(17)中的优化问题.
1) 固定S,求W
当S固定时,公式(17)中的第4项为常数项,因此可以忽略;同时,约束条件也可以忽略,则公式(17)可重写成:

公式(20)可重写成如下:
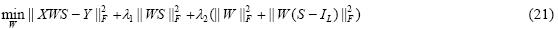
公式(21)的目标函数是一个凸函数,对公式(21)中的目标函数关于W求导并令其等于0,可得定理1中的公式(18).
2) 固定W,求S
当W固定时,公式(17)中第3项的第1部分为常数项,因此可以忽略.则公式(17)可表示为
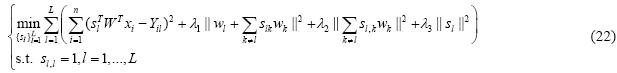
公式(22)的目标函数是凸函数,且可以进一步分解成L个独立的优化问题,可得定理1中的公式(19).
2.3.2 在RKHS中学习将公式(11)代入到公式(17)中可得:
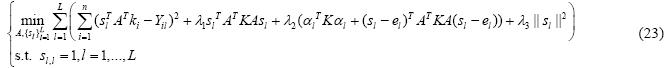
通过迭代求解的方法来求解A和S,可总结如下定理:
定理2. 采用交替迭代求解的方法求解公式(23).其中,
· 当S固定时,A可通过求解一个Sylvester方程求得:

其中,B=(K+l1In)-1,C=(l2IL+l2(S-IL)(S-IL)T)-1,In为nxn的单位矩阵;
· 当A固定时,S可通过求解下式来求得:
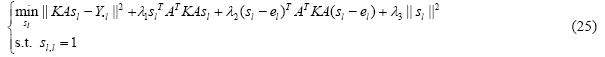
其中,Y·l=[Y1l,…,Ynl]T,即标记指示矩阵Y的第l个列;el为L维的列向量,其第l个元素为1,其余为0.
证明:采用交替求解的方法来解公式(23)中的凸优化问题.
1) 固定S,求A
当S固定时,公式(23)中第4项为常量,因此可以忽略;同时,约束条件也可以忽略,则公式(23)可重新表示为
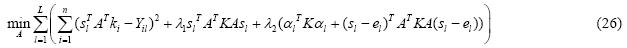
公式(26)可进一步写成:
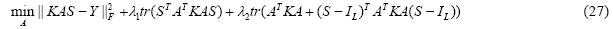
其中,tr(×)表示矩阵的迹.
公式(27)的目标函数是一个凸函数,对其关于A求导并令其等于0,可得定理2中的公式(24).
2) 固定A,求S
当A固定时,公式(23)中第3项的第1部分为常数项,因此可以忽略,则公式(23)可重新写成如下:

公式(28)的目标函数是凸函数,并且可以进一步分解成L个独立的优化问题,可得定理2中的公式(25). □
2.4 预测阶段在预测阶段,给定一个未知样本x,其预测的类别标记集合为
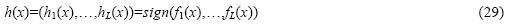
其中,sign(×)为符号函数.
3 实 验 3.1 数据集描述为了验证本文提出的方法的性能,我们选取了20个多标记基准数据集(其中,Yahoo包括11个数据集)进行实验测试.这些数据集涉及了文本分类、图像标记、音乐分类和生物信息学等应用领域,具体描述见表 1.
| Table 1 Detailed descriptions of multi-label data sets 表 1 多标记数据集的详细描述 |
其中,平均标记个数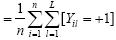 ,标记密度
,标记密度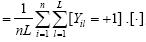 .[×]为1,如果条件为真;否则为0.
.[×]为1,如果条件为真;否则为0.
多标记学习框架中,每个样本可能同时隶属于多个类别标记.因此,与单标记学习系统相比,多标记学习系统的评价准则要更加复杂些.到目前为止,已提出了许多多标记学习系统的性能评价准则[1,3,7,13,15,16,19].假设测试集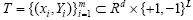 ,并根据预测函数fl(x),定义一个排序函数rankf(x,l)Î{1,…,L},如果fl(x)>fk(x),则rankf(x,l)<rankf(x,k).本文选取了5种常用的评价准则,即Hamming Loss,One-Error,Coverage,Ranking Loss和Average Precision来评价多标记学习系统的性能,具体定义如下:
,并根据预测函数fl(x),定义一个排序函数rankf(x,l)Î{1,…,L},如果fl(x)>fk(x),则rankf(x,l)<rankf(x,k).本文选取了5种常用的评价准则,即Hamming Loss,One-Error,Coverage,Ranking Loss和Average Precision来评价多标记学习系统的性能,具体定义如下:
1) Hamming Loss:用于度量样本在单个标记上的真实标记和预测标记的错误匹配情况:
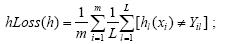
2) One-Error:用来考察预测值排在第1位的标记却不隶属于该样本的情况:

其中,
3) Coverage:用于度量平均上需要多少步才能遍历样本所有的相关标记:
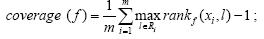
其中,Ri={l|Yil=+1}表示样本xi的相关标记集合,而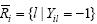 表示样本xi的不相关标记集合.
表示样本xi的不相关标记集合.
4) Ranking Loss:用来考察样本的不相关标记的排序低于相关标记的排序的情况:
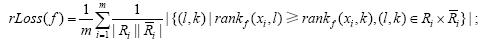
5) Average Precision:用来考察排在隶属于该样本标记之前的标记仍属于样本的相关标记集合的情况:
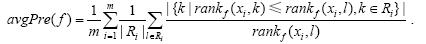
上述5个评价准则中,前4个值越小系统性能越优,最优值为0;最后1个值越大越好,最优值为1.
3.3 参数选择为了验证本文提出的方法JMLLC(包括JMLLC-LS和JMLLC-LR)的有效性,将JMLLC算法与8个多标记学习算法,即BR[4],MLkNN[7],BPMLL[3],RankSvm[6],CLR[8],RAkEL[12],ECC[9]和CDN-LR[26]进行实验比较.其中,JMLLC,MLkNN,BPMLL,RankSvm和CDN-LR是基于Matlab实现的,其他的是基于MULAN软件包[30]实现的.对于BR,CLR,RAkEL和ECC,都选择C4.5算法作为基分类器.对于MLkNN,近邻个数k和平滑参数s分别设置为10和1.在BPMLL中,神经网络的隐含神经元个数为特征个数的20%,学习率a=0.05以及训练时最大的迭代次数为100.对于RankSvm,代价参数c=1,同时选择RBF核函数,即K(x,y)=exp(-||x-y||2/2s2),其中,参数s等于所有训练样本对之间的欧式距离的均值.对于CDN-LR,也选择RBF核函数,l,n,tb和tc分别取0.1,100,100和500.对于本文的JMLLC-LS和JMLLC-LR,我们也选择RBF核函数,有3个正则化参数l1,l2和l3需要调整.对于JMLLC-LS和JMLLC-LR,都在一些数据集上用10折交叉验证来选择l1,l2和l3,它们的取值范围都为{0.0001,0.0005,0.001,0.005,…,1,5,10,50,100,500}.实验结果表明:当l1=0.005,l2=0.005以及l3=50时,JMLLC-LR产生稳定的性能.因此,本文中对于JMLLC-LR,在所有的数据集上,l1,l2和l3都分别取0.005,0.005和50.同样地,对于JMLLC-LS,在所有的数据集上都取l1=0.01,l2=0.5以及l3=5.
3.4 实验结果与分析我们将JMLLC-LR和JMLLC-LS与其他8个常用的多标记学习算法——BR,MLkNN,BPMLL,RankSvm,CLR,RAkEL,ECC和CDN-LR进行实验比较.根据5种不同的评价准则,表 2~表 6分别列出了我们的方法与其他8种对比算法在表 1中所列出的所有数据集上的详细实验结果,其中,将Yahoo的11个数据集上的平均结果作为Yahoo数据的结果.这些方法在每个数据集上的实验结果排序(其中,Yahoo数据的排序结果为Yahoo数据的11个数据集上的平均排序)都在实验数据后面用下标形式写出,且最好的结果加粗表示;同时,每种方法在所有数据集上的平均排序结果列在最后一行,其中,平均排序越小,系统性能越优.
| Table 2 Performance comparison based on Hamming Loss (the smaller,the better) 表 2 基于Hamming Loss(值越小越好)的性能比较 |
| Table 3 Performance comparison based on One-Error (the smaller,the better) 表 3 基于One-Error(值越小越好)的性能比较 |
| Table 4 Performance comparison based on Coverage (the smaller,the better) 表 4 基于Coverage(值越小越好)的性能比较 |
| Table 5 Performance comparison based on Ranking Loss (the smaller,the better) 表 5 基于Ranking Loss(值越小越好)的性能比较 |
| Table 6 Performance comparison based on Average Precision (the larger,the better) 表 6 基于Average Precision(值越大越好)的性能比较 |
在表 2中,对于前9个数据集,JMLLC-LS在7个数据集上的Hamming Loss值是最小的,即最好的,而JMLLC-LR在其余的2个数据集上的值是最小的.JMLLC-LR和JMLLC-LS在绝大多数数据集上的Hamming Loss都要小于其他对比算法,而且,JMLLC-LS算法的性能非常稳定.对于Yahoo数据集,JMLLC-LS的平均结果最优,其次是JMLLC-LR.根据20个数据集上的平均排序结果可以看出:JMLLC-LS排在第1,且在大多数数据集上都取得较优的结果;JMLLC-LR排在第2;而将其他标记变量值作为固定值的CDN-LR排在最后,性能最差.
从表 3中列出的结果可以看出:对于前9个数据集,JMLLC-LR和JMLLC-LS分别在3个和6个数据集上取得最好的结果,分别在4个和3个数据集上取得次优的结果,而且JMLLC-LS都是排在前两位;对于Yahoo数据集,JMLLC-LS的平均结果最优,其次是JMLLC-LR.根据各个算法的平均排序结果可以发现:JMLLC-LS位居第1,JMLLC-LR排在第2,考虑了高阶标记相关性的ECC算法位于第3位,而CDN-LR算法仍然位于最后.
表 4中的实验结果显示:对于前9个数据集,在大多数数据集上,JMLLC-LR都优于其他算法;在slashdot数据集上,BPMLL取得了最好的性能,但与分别排第2和第3的JMLLC-LR和JMLLC-LS算法相比较,Coverage值减少得非常少,分别不到0.1和0.2;在yeast数据集上,RankSvm取得了最好的性能,但与次优的JMLLC-LS和JMLLC-LR在Coverage指标上的性能相当;对于Yahoo数据集,JMLLC-LR的平均结果最优,其次是CLR.从平均排序结果来看,在Coverage指标上,JMLLC-LR的性能最稳定,排在第1.
从表 5可以看出:对于前9个数据集,JMLLC-LR,JMLLC-LS和BPMLL分别在5个、3个和1个数据集上性能最优;在slashdot数据集上,BPMLL取得了最好的性能,但比JMLLC-LR和JMLLC-LS的Ranking Loss指标值只低不到0.01,并且BPMLL在其他数据集上的性能都要比JMLLC-LR和JMLLC-LS差很多;对于Yahoo数据集,JMLLC-LR的平均结果最优,其次是CLR.从平均排序结果来看,JMLLC-LR都要优于其他的对比算法.
根据表 6中所列出的各种算法在以Average Precision作为性能评价指标的结果可以看出:对于前9个数据集,除了在slashdot数据集上JMLLC-LR排在第3位之外,在其他的数据集上,本文的算法JMLLC(包括JMLLC- LR和JMLLC-LS)性能都要优于其他的算法,JMLLC-LR和JMLLC-LS性能很稳定并且分别在4个和5个数据集上性能最好;对于Yahoo数据集,JMLLC-LS的平均结果最优,其次是JMLLC-LR,而没有考虑 标记相关性的BR算法平均结果最差.从平均排序结果可以看出:JMLLC-LS位居第1位,JMLLC-LR排在第2位.
根据以上的实验结果分析以及表 2~表 6中列出的在5个评价准则上的实验结果,充分表明了本文的算法优于其他的8种对比算法.对于Yahoo数据集且评价准则为Coverage和Ranking Loss时,JMLLC-LR要优于JMLLC-LS;其他情况下,JMLLC-LR和JMLLC-LS性能相当.这充分证明了本文算法JMLLC选择不同的凸损失函数作为经验损失项都能取得较好的性能,从而验证了本文算法的有效性和可扩展性.
为了在统计上比较本文算法与其他对比算法在20个数据集上的实验结果,我们采用显著性水平为5%的Friedman test[32].对于每个评价准则,由于都拒绝了零假设(所有算法性能相等),故需要结合特定的post-hoc test来进一步分析各个算法性能的差异[31,32].本文采用显著性水平为5%的Nemenyi test,若两个算法在所有数据集上的平均排序的差不低于临界差(critical difference,简称CD),则认为它们有显著性差异.图 1给出了在不同评价准则下所有算法之间的比较,其中,每个子图中最上行为临界值CD=3.03(10种算法、20个数据集 ),坐标轴画出了各种算法的平均排序且最左(右)边的平均排序最高(低).用一根加粗的线连接性能没有显著差异的算法组.
 | Fig. 1 Performance comparison of all classifiers in terms of five evaluation criteria图 1 所有分类器在5种评价准则上的性能比较 |
对于每种算法,都有45种实验比较结果(9种对比算法、5种评价准则).从图 1可以发现:
· 对于JMLLC-LR算法,31.1%的情况下(有14种比较结果与其他算法没有显著性差异),在统计上与其他算法性能相当,即:基于Hamming Loss时,与JMLLC-LS,ECC和MLkNN性能相当(如图 1(a)所示);基于One-Error时,与JMLLC-LS和ECC和性能相当(如图 1(b)所示);基于Coverage时,与CLR,RankSvm和ECC性能相当(如图 1(c)所示);与CLR,RankSvm和ECC在评价准则为Ranking Loss时性能相当(如图 1(d)所示);与JMLLC-LS,ECC和CLR的Average Precision值没有显著性差异(如图 1(e)所示).而68.9%的情况下,在统计上要优于其他算法;
· 对于JMLLC-LS,在40%的情况下,在统计上与其他算法性能相当;在4.4%的情况下,在统计上比其他算法的性能要差一些;在55.6%的情况,在统计上要优于其他算法;
· 对于ECC,在64.4%的情况下,在统计上与其他算法性能相当;在35.6%的情况下,在统计上要优于其他算法.
总的来说:JMLLC-LR性能最优,在68.9%的情况下,在统计上优于其他比较算法,而且不比其他算法性能要差;其次是JMLLC-LS算法,在55.6%的情况下,在统计上优于其他比较算法;排在第3的是ECC算法.
这些结果与分析进一步验证了本文算法的有效性.
4 结束语本文提出了多标记分类和标记相关性的联合学习JMLLC(包括JMLLC-LR和JMLLC-LS).通过构建基于类别标记变量的条件依赖网络,其中每个标记变量将其他标记变量和输入特征变量当作其父节点,来充分挖掘标记之间的相关性.最终的目标优化问题可转化为一个双凸优化问题,并可采用交替求解的方法进行求解.
在20个多标记数据集基于5种不同的评价准则的实验结果表明,JMLLC-LR和JMLLC-LS算法优于其他8种对比算法.
在现实世界中,获取有标记样本非常费时且代价很高,而大量的未标记样本却很容易获得.因此在未来的研究工作中,我们将致力于研究基于半监督的多标记学习算法.此外,获取大量标记不完整的弱标记样本也是相对比较容易的,故针对弱标记的多标记学习也是未来的研究方向之一.
致谢 我们衷心感谢各位老师(尤其是各位审稿专家)和同学给本文提出宝贵的建议以及对本文工作的支持.| [1] | Zhang ML, Zhou ZH. A review on multi-label learning algorithms. IEEE Trans. on Knowledge and Data Engineering, 2014,26(8): 1819-1837 . |
| [2] | Schapire RE, Singer Y. Boostexter: A boosting-based system for text categorization. Machine Learning, 2000,39(2):135-168 . |
| [3] | Zhang ML, Zhou ZH. Multilabel neural networks with applications to functional genomics and text categorization. IEEE Trans. on Knowledge and Data Engineering, 2006,18(10):1338-1351 . |
| [4] | Boutell MR, Luo J, Shen X, Brown CM. Learning multi-label scene classification. Pattern Recognition, 2004,37(9):1757-1771 . |
| [5] | Lo HY, Wang JC, Wang HM, Lin SD. Cost-Sensitive multi-label learning for audio tag annotation and retrieval. IEEE Trans. on Multimedia, 2011,13(3):518-529 . |
| [6] | Elisseeff A, Weston J. A kernel method for multi-labelled classification. In: Dietterich TG, Becker S, Ghahramani Z, eds. Proc. of the Advances in Neural Information Processing Systems 14. Cambridge: MIT Press, 2002. 681-687. |
| [7] | Zhang ML, Zhou ZH. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognition, 2007,40(7):2038-2048 . |
| [8] | Fürnkranz J, Hüllermeier E, Mencía EL, Brinker K. Multilabel classification via calibrated label ranking. Machine Learning, 2008, 73(2):133-153 . |
| [9] | Read J, Pfahringer B, Holmes G, Frank E. Classifier chains for multi-label classification. Machine Learning, 2011,85(3):333-359 . |
| [10] | Huang SJ, Zhou ZH. Multi-Label learning by exploiting label correlations locally. In: Proc. of the 26th AAAI Conf. on Artificial Intelligence. Toronto, 2012. 949-955. |
| [11] | Huang SJ, Yu Y, Zhou ZH. Multi-Label hypothesis reuse. In: Proc. of the 18th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2012. 525-533 . |
| [12] | Tsoumakas G, Katakis I, Vlahavas I. Random k-labelsets for multilabel classification. IEEE Trans. on Knowledge and Data Engineering, 2011,23(7):1079-1089 . |
| [13] | Tsoumakas G, Katakis I. Multi-Label classification: An overview. Int’l Journal of Data Warehousing and Mining, 2007,3(3):1-13 . |
| [14] | Hüllermeier E, Fürnkranz J, Cheng WW, Brinker K. Label ranking by learning pairwise preferences. Artificial Intelligence, 2008, 172(16):1897-1916 . |
| [15] | Xu JH. Fast multi-Label core vector machine. Pattern Recognition, 2013,46(3):885-898 . |
| [16] | Xu JH. An extended one-versus-rest support vector machine for multi-label classification. Neurocomputing, 2011,74(17): 3114-3124 . |
| [17] | Wu L, Zhang ML. Multi-Label classification with unlabeled data: An inductive approach. In: Proc. of the 5th Asian Conf. on Machine Learning. Canberra, 2013. 197-212. |
| [18] | Zhang ML. An improved multi-label lazy learning approach. Journal of Computer Research and Development, 2012,49(11): 2271-2282 (in Chinese with English abstract). |
| [19] | Zhang ML, Peña JM, Robles V. Feature selection for multi-label naive Bayes classification. Information Sciences, 2009,179(19): 3218-3229 . |
| [20] | Zhang ML, Zhang K. Multi-Label learning by exploiting label dependency. In: Proc. of the 16th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2010. 999-1008 . |
| [21] | Clare A, King RD. Knowledge discovery in multi-label phenotype data. In: Raedt LD, Siebes A, eds. LNCS 2168. Berlin: Springer-Verlag, 2001. 42-53 . |
| [22] | Ghamrawi N, McCallum A. Collective multi-label classification. In: Proc. of the 14th ACM Int’l Conf. on Information and Knowledge Management. New York: ACM Press, 2005. 195-200 . |
| [23] | Ji SW, Tang L, Yu SP, Ye JP. Extracting shared subspace for multi-label classification. In: Proc. of the 14th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2008. 381-389 . |
| [24] | Zhang T, Yeung DY. Multilabel relationship learning. ACM Trans. on Knowledge Discovery from Data, 2013,7(2):Article 7 . |
| [25] | Guo YH, Xue W. Probabilistic multi-label classification with sparse feature learning. In: Rossi F, ed. Proc. of the 23rd Int’l Joint Conf. on Artificial Intelligence. AAAI Press, 2013. 1373-1379. |
| [26] | Guo Y, Gu SC. Multi-Label classification using conditional dependency networks. In: Walsh T, ed. Proc. of the 22nd Int’l joint Conf. on Artificial Intelligence. AAAI Press, 2011. 1300-1305 . |
| [27] | Heckerman D, Chickering DM, Meek C, Rounthwaite R, Kadie C. Dependency networks for inference, collaborative filtering, and data visualization. The Journal of Machine Learning Research, 2001,1:49-75 . |
| [28] | Godbole S, Sarawagi S. Discriminative methods for multi-labeled classification. In: Dai H, Srikant R, Zhang C, eds. Lecture Notes in Artificial Intelligence 3056, Berlin: Springer-Verlag, 2004. 22-30 . |
| [29] | Schölkopf B, Herbrich R, Smola AJ. A generalized representer theorem. In: Helmbold D, Williamson B, eds. Lecture Notes in Artificial Intelligence 2111. Berlin: Springer-Verlag, 2001. 416-426 . |
| [30] | Tsoumakas G, Xioufis ES, Vilcek J, Vlahavas I. MULAN: A Java library for multi-label learning. Journal of Machine Learning Research, 2011,12(7):2411-2414. |
| [31] | Demšar J. Statistical comparisons of classifiers over multiple data sets. The Journal of Machine Learning Research, 2006,7(1): 1-30. |
| [32] | Zhang ML. LIFT: Multi-Label learning with label-specific features. In: Walsh T, ed. Proc. of the 22nd Int’l joint Conf. on Artificial Intelligence. AAAI Press, 2011. 1609-1614 . |
| [18] | 张敏灵.一种新型多标记懒惰学习算法.计算机研究与发展,2012,49(11):2271-2282. |