 2014, Vol. 25
2014, Vol. 25



2. 符号计算与知识工程教育部重点实验室(吉林大学), 吉林 长春 130012
2. Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education (Jilin University), Changchun 130012, China
状态评价是一类相当普遍的重要问题,它是一种典型的有序命题类问题[1].在日常生活中,评价类问题随处可见,如:环境监测领域,把室内环境舒适度分为很舒适、较舒适和不舒适3类;评估桥梁状况时,将其分为潜在危险、严重破坏、轻微破坏和状态极佳4类;农业生产领域,将耕作土地的肥沃程度分为高肥力、中上肥力、中肥力、中下肥力、低肥力5类.为了提高状态评价系统的可靠性和性能,现在普遍采用了多传感器信息融合技术.以室内环境舒适度评估为例,舒适度的评价非常复杂,不仅与温度、湿度、气流、太阳辐射等物理条件有关,而且随人体热平衡、个人活动量和着装多少而变化[2].由于 人类的感觉具有模糊性、不确定性和主观性而很难量化[3],所以,舒适度目前是一种不可直接测量的物理量,只能借助于信息融合技术对影响环境舒适度的多种属性进行推理,以评价环境的舒适程度.
近年来,世界范围的信息化变革,使得几乎每个行业都面临着大数据问题,这些数据具有海量、动态、不确定和多源异构等特点,上述特点使得数据的存储、传输与及时响应和处理面临巨大的挑战[3,4,5].信息融合作为有效整合和管理数据的重要工具之一,其研究正吸引着越来越多的研究者的关注[3,4].Dempster-Shafer证据理论既能处理随机性所导致的不确定性,又能处理模糊性所导致的不确定性,在信息融合领域中获得了广泛应用[3,4]. Basir等人采用传统证据理论对多传感器采集的证据进行融合来诊断汽车引擎的故障,并提出两种新方法提高mass函数建模和证据组合的有效性[6].Panigrahi等人使用当前证据和历史行为,提出结合证据理论和贝叶斯学习的方法来检测信用卡欺诈行为[7].Leung等人将群体决策与传统证据理论相结合,提出一种能够自动识别并处理不可靠证据的集成信息融合方法,可以有效地处理高冲突证据[8].Mora等人使用传统证据理论对空间和卫星采集的数据进行融合,以判定森林中的主要树种[9].传统证据理论模型不适于求解有序命题类问题,凸函数证据理论模型[10]是传统证据理论的一种重要改进,它给出了适合于有序命题类问题的组合函数,有效地解决了有序命题类问题的不确定性处理问题,拓展了证据理论模型的应用范围[11].但是在融合海量信息时,证据理论具有潜在指数级复杂度的缺点会更加突出.如何合理高效地利用海量信息、使用证据理论进行融合,是一个亟待解决的问题.
为此,本文提出一种结合聚类和凸函数证据理论的海量信息融合方法,旨在解决状态评价等普遍而重要的应用问题.该方法首先基于一种综合的层次聚类方法BIRCH[12]对采集的海量信息进行预处理,形成多个簇;然后,针对状态评价类问题所用数据大多为数值数据和序数数据这一特点计算每个簇的质心,将其作为该簇的代表信息;接着,基于广义三角模糊隶属函数[16]对每个质心信息进行基本概率指派(basic probability assignment,简称BPA);最后,基于凸函数证据理论完成各证据的组合,从而完成了海量信息的融合.本文在一个室内环境舒适度判定系统中验证了该方法的有效性,该方法也可以很方便地推广到其他状态评价系统中.
1 预备知识 1.1 凸函数证据理论凸函数证据理论模型[1,10]比传统的证据理论模型更适合对有序命题类问题进行不确定性推理[10,11].它构造了适合有序命题类问题和具有凸性质的证据组合函数,是非常适合求解有序命题类问题的不确定性推理
模型[10].
定义1. 简单命题P1,P2,...,Pn是一组有序命题,如果它们满足:
· 对i=1,2,...,n,命题Pi的主词项均为S,谓词项为si;
· 对i=1,2,...,n,si均描述S的同一性质或特征;
· 谓词项s1,s2,…,sn描述S同一性质的程度依次增强或减弱.
定义一组有序命题间的小于等于关系,记为≤.
定义2. 一组有序命题P1,P2,...,Pn的真值|P1|,|P2|,...,|Pn|应呈现出凸的性质,即对任意Pi≤Pj≤Pk,都有|Pj|≥min{|Pi|,|Pk|}成立.
文献[10]给出针对有序命题的新的综合函数f的定义.
定义3. 设概念S={s1,s2,…,sn},s1,s2,…,sn为一组有序命题. 表示2sÈ S上的基本支持函数空间,f:Âx®Â为其不确定性值的综合函数.对于"m1,m2ÎÂ,有:
表示2sÈ S上的基本支持函数空间,f:Âx®Â为其不确定性值的综合函数.对于"m1,m2ÎÂ,有:
① 当m1=m0,有f(m0,m2)=f(m2,m0)=m2;
② 当m1¹m0且m2¹m0时,有:
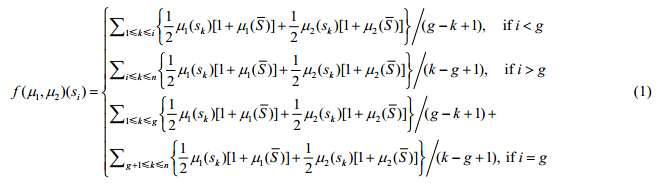
其中,
· 
· m0ÎÂ,满足m0(si)=0,对i=1,2,...,n.
定义3确定的证据理论模型被称作凸函数证据理论模型.可以证明:如上定义的函数w=f(m1,m2)是基本支持函数,并且是一个凸函数,对于"m1,m2ÎÂ [10].gÎ[1,n],g表示最有可能为真之命题的序号.
文献[1]对上述组合函数进行了深入细致地分析,并给出了改进方法,将定义3中的公式(1)改写为
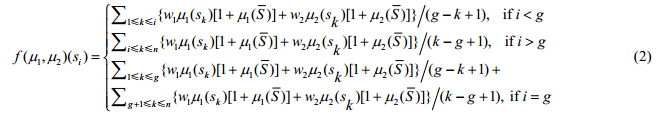
其中,

其中,w1+w2=1,Δ1,Δ2>0(两个待定常数),一般可选Δ1=0.2,Δ2=0.8.
当被组合的证据的个数m>2时,公式(2)变成公式(3):
令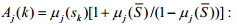
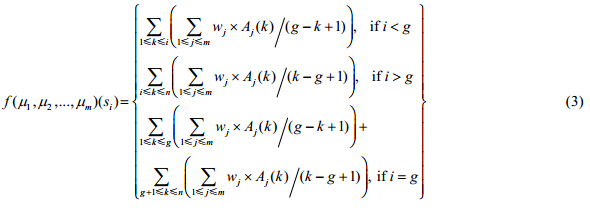
其中,

其中,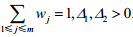 结果合成方法参见文献[1].
结果合成方法参见文献[1].
现有的传统聚类分析方法大多数仅局限于处理数据规模较小、包含连续属性或者分类属性的数据聚类问题,无法有效处理现实生活中包含混合属性的超大规模甚至海量数据的聚类问题[14].
BIRCH[8,9]是为大量数值数据聚类设计的,它将层次聚类与迭代划分等其他聚类方法集成在一起.BIRCH使用聚类特征(clustering feature,简称CF)概括一个簇,使用聚类特征树(CF-树)表示聚类的层次结构.这些结构帮助聚类方法在大型数据库、大规模数据集甚至在流数据库中取得高的速度和可伸缩性,还使得BIRCH方法对新对象增量或动态聚类也非常有效[13].基于BIRCH的上述优点,本文选取其对状态评估类应用中的海量数据进行预处理,将相似的数据聚集到同一簇内.
簇的聚类特征[13]是一个3维向量,汇总了对象簇的信息,定义如下:
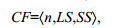
其中,LS是n个点的线性和,而SS是数据点的平方和.
聚类特征本质上是给定簇的统计汇总,使用其概括簇可以避免存储个体对象或点的详细信息,只需固定大小的空间来存放聚类特征.这是空间中BIRCH有效性的关键.
CF-树是一棵高度平衡树,它存储了层次聚类的聚类特征.CF-树有两个参数:分支因子B和阈值T.分支因子定义了每个非叶节点子女的最大数目,而阈值参数给出了存储在树的叶节点中子簇的最大直径.这两个参数影响结果树的大小[13].
BIRCH方法包括两个阶段[13]:
· 阶段1:BIRCH扫描数据库,建立一个初始存放于内存的CF树,它可以被看作数据的多层压缩,试图保留数据内在的聚类结构;
· 阶段2:BIRCH采用某个聚类算法对CF树的叶节点进行聚类,如典型的划分方法.把稀疏的簇当做离群点删除,而把稠密的簇合并为更大的簇.
1.3 证据的基本概率指派方法正确获得证据理论中基本概率赋值,是应用证据理论的基础和关键,也是实际应用中最难的一步[15,16].BPA设置得是否合理,直接关系到融合结果是否正确.BPA生成可以分为两大类:一类是专家根据主观经验加以设定,一类是系统根据一些已知条件自动生成BPA.文献[16]提出的BPA属于BPA自动生成方法,指在系统具有一定样本数据的前提下,根据传感器报告自动生成BPA函数.该方法首先基于广义三角模糊数描述模型数据库中已知状态的特征属性(模糊模型标记),然后确定传感器测量值与模型库中模型标记的似然度,该似然度表示在采集的模糊信息下确定为某一目标的可能性,在数值上表示了传感器信息对某一命题支持的程度,利用似然度确定传感器输出的基本概率指派.该方法在目标识别中的应用实例说明:它可以较好地反映传感器报告对各个目标的隶属程度,具有较好的通用性,且计算复杂度低.为此,本文采用该BPA指派方法对传感器的测量信息进行基本概率赋值以产生证据.
2 基于凸函数证据理论的海量信息融合方法随着大数据时代的来临,物联网、面向复杂应用背景的多传感器系统的大量涌现将产生大量数据,这些数据具有海量、动态、不确定和多源异构等特点,使得数据的存储、传输与及时响应和处理面临巨大的挑战[3,4,5].
在实际应用中,所有融合方法都会面临处理不确定信息的挑战,而证据理论因其不确定性的表示、量度和组合方面的优势受到广泛地重视,是一种有前景的信息融合方法[3,4].但是,现有基于证据理论的信息融合方法还不具有处理海量信息(证据)的能力,这一缺点将严重阻碍证据理论在信息化变革的发展和应用.为此,本文将数据挖掘领域擅长处理大规模数据的综合聚类算法BIRCH[11]引入凸函数证据理论,提出一种新的基于凸函数证据理论的海量信息融合方法.算法的主要思想是:首先,基于聚类方法BIRCH对采集的海量信息进行预处理,形成多个簇;然后,计算每个簇的质心,将质心作为该 簇的代表;接着,使用本文第1.3节介绍的方法对每个质心信息中与融合目标相关的各个属性进行基本概率指派,组合后形成每个簇的代表性证据;最后,基于凸函数证据理论完成各簇代表性证据的组合,从而完成了海量信息的融合.由于本算法主要目标是处理状态估计应用中的数据,而这类数据主要是数值数据和序数数据,序数数据又可以转化为数值数据来处理[13],因此在聚类数值数据后,某一个簇的质心可以作为该簇的代表完成后续运算.算法的主要步骤如下:
1) 根据采集数据的特点,选择与融合目标相关的所有属性A1,A2,...,An;
2) 根据A1,A2,...,An,采集数据的规模和特点确定BIRCH算法的分支因子B、阈值T和叶节点中子簇数的最大值L.设定初始值B=10,T=0,L=15;
3) 根据步骤1)和步骤2),BIRCH算法对采集的N个海量数据进行聚类形成r个簇C1,C2,...,Cr;
4) 根据步骤3)的聚类结果,计算每个簇的质心数据Q1,Q2,...,Qr;
5) 根据应用问题,确定辨识框架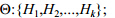
6) 建立模型库的模糊模型标记.根据给定的H1,H2,...,Hk的一定量样本数据,针对样本的某个属性Ai,可以确定该属性的最小值、最大值和平均值,基于这3个属性值,可以建立一个三角形模糊数来描述命题Hj.据此,建立对应的隶属函数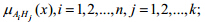
7) 确定传感器采集数据的观测函数.对属性Ai,首先计算出模型库中所有模型标记属性Ai的平均方差,根据计算所得平均方差和传感器当前的测量值,将该测量值扩展成可表示的三角模糊数,进而获得与其对应的传感器观测函数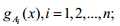
8) 确定传感器采集数据与模型库中模型标记的似然度.传感器观测函数 与目标模糊模型标记
与目标模糊模型标记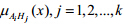 两条曲线相交部分纵坐标的最大值即为传感器报告与模型库中模型标记的似然度
两条曲线相交部分纵坐标的最大值即为传感器报告与模型库中模型标记的似然度
9) 生成基本概率指派:
a) 初始化BPA.令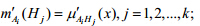
b) 令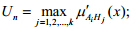
c) 设置全集Q的初始BPA:
d) 将 归一化处理后,获得此时传感器测量生成的属性Ai的数据对应的基本概率指派
归一化处理后,获得此时传感器测量生成的属性Ai的数据对应的基本概率指派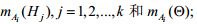
10) 对于步骤4)中得到的每个簇的质心信息,根据选定的属性A1,A2,...,An,重复步骤6)~步骤9),生成每个簇的质心对应的n条证据;
11) 使用经典证据理论的组合公式,融合步骤10)产生的n条证据,形成能反映簇Ci对融合目标支持程度的合成证据cmi(Hj),i=1,2,…,r,j=1,2,…,k;
12) 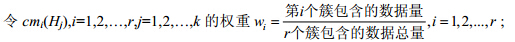
13) 利用凸函数证据理论的证据组合公式(3),利用步骤12)分配的权重对步骤11)生成的r条合成证据进行融合,确定最终融合结果.
本文提出算法的时间复杂度与BIRCH算法和凸函数证据理论融合证据时间紧密相关.BIRCH算法的时间复杂度为O(N),其中,N为被聚类的对象数[13].而针对辨识框架Q:{H1,H2,...,Hk},融合r个簇的质心对应的n条证据的时间为O(rxnxk).故,整个算法的计算时间为max{O(N),O(rxnxk)} .在处理实际应用问题时,n与k的值是确定的,因此,本算法具有线性的处理时间,明显优于传统的凸函数证据理论算法.
3 仿真实验海量数据的规模通常是TB级甚至PB级的,在现实生活中较难采集到.为了验证本文提出算法的有效性,我们选择室内环境舒适度这一典型的状态评价类问题中的大规模数据进行仿真实验.由于舒适度的评价非常复杂,本文选取温度、湿度这两个可直接测控并对人类舒适感影响最大的两个变量为代表进行判断,在两个房间Room 1和Room 2内,分别部署3个和4个温湿度传感器,我们每隔10s采集一次数据.这7个传感器24小时采集的数据量为24 000多条,10天可以采集2.5x105条,30天约采集7.5x105条数据.由于判定房间内24小时内某些时间段的环境舒适度会更有助于指导执行改进措施,因此选择在这两个房间里各传感器在3个连续时间段(15点~19点、7点~20点和0点~24点)采集的大规模数据进行舒适度评价的仿真实验,实验过程和结论也适用于实际评估中更多传感器更长时间采集的规模为TB级的海量数据.我们分别使用经典凸函数证据理论方法(简称CET算法)与本文算法对这6组数据进行融合,根据融合结果,评价某时间段内、某房间的环境舒适度.
3.1 证据的生成和组合 设室内环境温度为0°C~40°C,空气湿度为0~100%,舒适度论域Q={不舒适,较舒适,很舒适}.如前所述,采用广义三角模糊数来定义温度隶属函数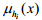 和湿度隶属函数,其中,i=1,2,…,n:
和湿度隶属函数,其中,i=1,2,…,n:
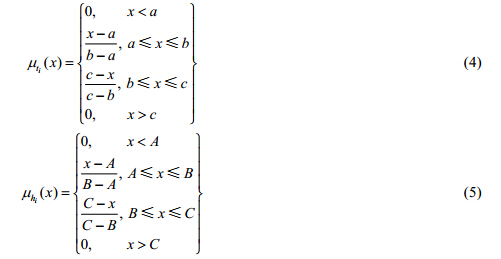
根据相关文献的研究结果[2,17],可以得到不同舒适度对应的温度和湿度区间.
| Table 1 Relationship between different comfort degree and temperature and humidity 表 1 不同舒适度与温、湿度的对应关系 |
由表 1中的数据,可以确定温度和湿度属性在某一区间上的最小值、最大值和平均值.基于这3个属性值,可以建立相应的三角模糊函数来描述舒适度的状态.特别地,对同一舒适度状态对应的温度和湿度的各个区间,要分别建立隶属度函数,在确定传感器采集数据与模型库中模型标记的似然度时,这些区间上的隶属度函数都要与传感器观测函数比较.以不舒适状态对应的温度为例,由于不舒适对应温度的两个区间,我们分别建立两个区间上的三角模糊函数
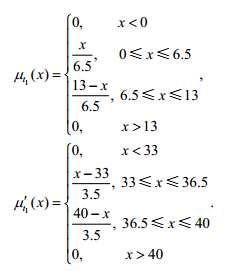
其他舒适度状态对应的温度、湿度隶属函数的构建方式类似,不再赘述.下面我们以Room 1的1号传感器采集的数据(1,52.75,19.25,2012/4/13 17:01:08)为例,说明根据其温度和湿度的测量值以及上述隶属函数进行证据BPA指派的过程.此数据的格式为(传感器编号,湿度,温度,采集时间).
首先,计算出模型库中所有模型标记温度的平均方差为4.根据计算所得平均方差,将测得的温度值扩展成
可表示的三角模糊数(15.25,19.25,23.25),其对应的传感器观测函数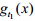 为
为
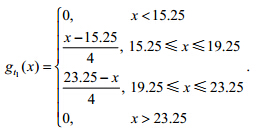
温度传感器观测函数分别与3种舒适度状态隶属函数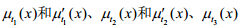 曲线相
曲线相
交部分纵坐标的最大值即为温度传感器报告与模型库中3种舒适度状态的似然度,则温度传感器报告各舒适度状态的似然度为

归一化处理后,对温度而言,这条传感器数据生成的基本概率指派为
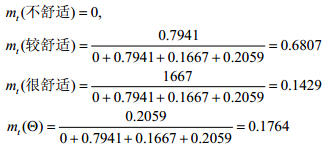
这样,就完成了使用温度属性生成基本概率指派的全部过程.同理,可使用湿度属性进行BPA指派,得到如下结果:

将新生成的证据mt和mh使用证据理论的组合规则进行融合,形成新证据为

利用所有新生成的证据,使用凸函数证据理论进行组合得到的融合结果,就可以判断该房间在某一时间段内的环境舒适度.
3.2 BIRCH算法中参数的选择BIRCH算法执行的关键步骤是构造CF-树,CF-树构建时需要确定3个参数:分支因子B、阈值T和叶节点中子簇数的最大值L.这3个参数的取值,直接影响结果树的大小.根据文献[12]的实验结果,我们选定B的初始值为10、T的初始值为0、L的初始值为15.我们根据所用的温度和湿度数据的特点进行了多次实验,在B和L值固定的前提下,以每次增加0.05的幅度调整T值,再观察最终融合结果的支持度值.具体的实验结果见表 2.
| Table 2 Results when B is 10,L is 15 and T is set to different value 表 2 B=10,L=15,T在不同取值时的实验结果 |
从表 2中不难看出:随着T的增加,生成的CF-树中叶节点的数量逐渐减少,算法的执行时间也随之减少.在各种取值情况下,融合的结果都是“较舒适”,只是证据对“较舒适”这一结论的支持程度不同.在T为0.25时,“较舒适”的mass函数值取得最大值0.814 0,因此我们选定T的取值为0.25.类似地,在T和L值固定的前提下,以每次增加5的幅度调整B值,然后观察最终融合结果的支持度值.具体的实验结果由于文章篇幅限制略去,我们最终选定B的取值为30,因为此时生成的叶节点数由原来的313降为259,时间几乎不变,而“较舒适”的mass函数值仍取得最大值0.814 0.进而,我们在保持T=0.25,B=30的前提下,以每次增加5的幅度来调整L值,仍 然 以“较舒适”的mass函数值为目标函数,确定此时使该函数取得最大值0.814 4的L为40,此时的运算时间为530ms,而生成的叶节点数降为100.因此,我们通过实验最终选定BIRCH算法的参数B=30,T=0.25,L=40.
3.3 大规模数据融合结果分析基于第3.1节和第3.2节的方法和结论,我们采集了Room 1和Room 2在3个连续时间段的6组数据,数据规模从4 000~24 000不等,分别使用CET算法和本文算法进行融合.实验结果如图 1和表 2所示.
图 1比较了两种算法在融合相同规模数据时的运行时间,通过图 1的实验结果我们可以看出:本文算法在运行时间上有明显的优势,随着数据量的增加,本文算法融合时间的增长速度比CET算法慢得多,当数据集的规模超过15 000条时,CET算法的时间接近于本文算法的两倍.由此仿真实验结果可以推断:当数据规模为海量时,本文算法的运行时间将比CET算法少得多,在时间方面有更大的优势.
 | Fig. 1 Time comparisonbetween CET and our algorithm图 1 CET算法与本文算法运行时间比较 |
表 3对CET算法和本文算法的最终融合结果进行了比较,不难看出:两种方法对同一数据的融合处理得到的结论是一致的.就“较舒适”的BPA值而言,两种算法的差别不大,在区间[0.01,0.1]内,BPA值间的差别与原始数据的分布有关,如果原始数据的值分布范围比较广,则两种算法的融合结果的BPA值差别较大;反之,差别较小.
| Table 3 Final fusion results comparison between CET and our algorithm 表 3 CET算法与本文算法最终融合结果的比较 |
综上,我们不难看出:与传统的凸函数证据理论方法相比,本文提出的算法在处理大规模或海量数据的融合问题时有明显的时间优势,且融合结果与传统方法一致.因此,从整体效果上看,本文算法既高效又合理地处理海量信息融合问题,为海量信息融合技术的发展提供了一条新的探索途径.
4 结 论凸函数证据理论模型能够有效处理有序命题类问题中的不确定性,拓展了证据理论模型的应用范围.但随着大数据时代的来临,在融合海量信息以解决状态评估等有序命题类问题时,传统的CET方法将具有指数级的时间复杂度,这是研究者无法接受的.针对这一问题,必须对传统的CET模型进行改进,才能完成海量信息的融合.本文正是以此为切入点,通过使用大数据聚类方法BIRCH对采集的海量数据进行预处理,形成多个簇.然后计算每个簇的质心,将其作为该簇的代表,使用基于广义三角模糊数的方法对每个质心信息进行基本概率指派.最后,基于凸函数证据理论完成各证据的组合,从而完成了海量信息的融合.仿真实验结果证明:本文提出的算法能在保证融合结果正确的前提下大幅度减少海量信息的融合时间,是一种合理高效的海量信息融合新方法.下一步工作计划获得其他应用领域规模更大的数据,如桥梁健康状况数据、土地肥沃程度数据等,利用本文算法进行测试,针对测试结果改进本文算法.
致谢 在此,我们由衷地感谢给本文工作提出宝贵建议的评审老师们.
| [1] | Tsoumakas G, Katakis I, Vlahavas I. Mining Multi-Label Data. Data Mining and Knowledge Discovery Handbook. 2nd ed., Berlin: Springer-Verlag, 2010.667-685 . |
| [2] | McMallum A. Multi-Label text classification with a mixture model trained by EM. In: Proc. of the Working Notes of the AAAI’99 Workshop on Text Learning. Orlando, 1999. |
| [3] | Schapire RE, Singer Y. Boostexter: A boosting-based system for text categorization. Machine Learning, 2000,39(2):135-168 . |
| [4] | Jiang JY, Tsai SC, Lee SJ. FSKNN: Multi-Label text categorization based on fuzzy similarity and k nearest neighbors. Expert Systems with Applications, 2012,39(3):2813-2821 . |
| [5] | Boutell MR, Luo J, Shen X, Brown CM. Learning multi-label scene classification. Pattern Recognition, 2004,37(9):1757-1771 . |
| [6] | Wang M, Zhou X, Chua TS. Automatic image annotation via local multi-label classification. In: Proc. of the 7th ACM Int’l Conf. on Image and Video Retrieval. Niagara Falls, 2008. 17-26 . |
| [7] | Bao BK, Ni B, Mu Y, Yan S. Efficient region-aware large graph construction towards scalable multi-label propagation. Pattern Recognition, 2011,44(3):598-606 . |
| [8] | Zhang ML, Zhou ZH. A review on multi-label learning algorithms. IEEE Trans. on Knowledge and Data Engineering, 2014,26(8): 1819-1837 . |
| [9] | Zhang ML. LIFT: Multi-label learning with label-specific features. In: Proc. of the 22nd Int’l Joint Conf. on Artificial Intelligence. Barcelona, 2011. 1609-1614 . |
| [10] | Zhang ML, Zhang K. Multi-Label learning by exploiting label dependency. In: Proc. of the 16th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. 2010. 999-1008 . |
| [11] | Huang SJ, Zhou ZH. Multi-Label learning by exploiting label correlations locally. In: Proc. of the 26th AAAI Conf. on Artificial Intelligence. 2012. 949-955. |
| [12] | Guo YH, Gu SC. Multi-Label classification using conditional dependency networks. In: Proc. of the 22nd Int’l Joint Conf. on Artificial Intelligence. 2011. 1300-1305 . |
| [13] | Zhang Y, Zhou ZH. Multi-Label dimensionality reduction via dependency maximization. ACM Trans. on Knowledge Discovery from Data, 2010,4(3):Article 14 . |
| [14] | Zhou ZH, Zhang ML, Huang SJ, Li YF. Multi-Instance multi-label learning. Artificial Intelligence, 2012,176(1):2291-2320 . |
| [15] | Zhang ML, Zhou ZH. Multi-Label learning by instance differentiation. In: Proc. of the 22nd AAAI Conf. on Artificial Intelligence. Vancouver, 2007. 669-674. |
| [16] | Yang Y, Gopal S. Multilabel classification with meta-level features in a learning-to-rank framework. Machine Learning, 2012, 88(1-2):47-68. |
| [17] | Read J, Pfahringer B, Helms G, Frank E. Classifier chains for multi-label classification. Machine Learning, 2011,85(3):333-359 . |
| [18] | Yang Y, Pedeson JO. A comparative study on feature selection in text categorization. In: Proc. of the 14th Int’l Conf. on Machine Learning. 1997. 412-420. |
| [19] | Ghamrawi N, McCallum A. Collective multi-label classification. In: Proc. of the 14th ACM Int’l Conf. on Information and Knowledge Management. 2005.195-200 . |
| [20] | Godbole S, Sarawagi S. Discriminative methods for multi-labeled classification. In: Proc. of the Advances in Knowledge Discovery and Data Mining. LNCS 3056, 2004. 22-30 . |
| [21] | Tsoumakas G, Vlahavas I. Random k-labelsets: An ensemble method for multilabel classification. In: Proc. of the Machine Learning: ECML 2007. LNCS 4701, 2007.406-417 . |
| [22] | Hanley JA, McNeil BJ. The meaning and use of the area under a receiver operating characteristic (ROC) curve. 1982, 143(1): 29-36. |
| [23] | Zhang ML, Zhou ZH. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognition, 2007,40(7):2038-2048 . |
| [24] | Chang CC, Lin CJ. LIBSVM: A library for support vector machines. ACM Trans. on Intelligent Systems and Technology, 2011, 2(3):Article 27. |
| [25] | Furnkranz J, Hullermeierm E, Mencia EL, Brinker K. Multilabel classification via calibrated label ranking. Machine Learning, 2008,73(2):133-153 . |