 2014, Vol.
2014, Vol. 



2 武汉大学 计算机学院, 湖北 武汉 430072;
3 软件工程国家重点实验室(武汉大学 计算机学院), 湖北 武汉 430072
2 Computer School, Wuhan University, Wuhan 430072, China;
3 State Key Laboratory of Software Engineering (Computer School, Wuhan University), Wuhan 430072, China
位置服务(location based service,简称LBS)是近年来新兴的移动计算服务.发展位置服务主要需重视其两个方面的能力:提供位置的能力和理解位置的能力.在提供位置方面,随着室内外无缝定位技术和增强系统技术的发展,定位精度不断提高[1],在大众应用层面已经基本满足人们生产、生活的需要;然而在理解位置的能力方面,目前尚有很多挑战,是学术界和产业界关注的热点.理解位置其实就是理解位置背后所反映出来的人的活动、人的情感和人的环境,因此也被称为泛在测绘(ubiquitous mapping)或位置社会感知(location-based social awareness)[2].
位置大数据(location big data)是构成泛在测绘和位置社会感知的重要资源,具有相当大的体量.近几年,位置服务、数据挖掘和机器学习领域,已经涌现出一批针对位置大数据的优秀研究.其所使用的数据集在体量和复杂性上均已达到了“大”数据的层次,代表性实例见表 1.
| Table 1 Instances of location big data 表 1 位置大数据实例 |
位置大数据主要来源于车联网(Internet of vehicles,简称IOV)、移动社交网络、微博等新兴互联网应用,更新速度快且具有很大的混杂性(inaccurate).同时,往往受到数据采集技术等方面的客观制约,使得这些数据不能全面和正确地反映观察对象的整体全貌,因而具有“复杂但稀疏(complex yet sparse)”的特点.如何从位置大数据中获得价值,进而发现人类社群活动规律,是非常值得探讨的问题.本文将着重归纳和阐述这其中有关局部特征提取、数据降维、整体特征建模以及整体数据协同挖掘的方法.
本文的另一个贡献是从关联应用角度阐述了位置大数据的意义和价值.传统的诸如轨迹数据等往往仅被用以分析城市交通等直接且特定的问题.大量经典的大数据科学研究表明,通过价值提取和协同挖掘后的数据结果能够将一些看似无关的事件很好地联系在一起,从而从数据层面“直接”反映一些原本需要复杂因果建模才能得到的结果,且更加直观和准确[10,11,12,13].这些案例对位置大数据研究同样具有启发性.因此,我们在探讨位置大数据分析方法时,本身就应将其置于关联应用的大背景下,着重探讨如何将模型参与到社会经济活动、政治活动、自然环境、人类情感以及人口卫生等一系列社会学、人类学、经济学的研究中.这样的位置大数据才更有助于地理国情的分析和智慧城市的建设.
1 基本定义和预处理方法首先,我们给出本文所面对的位置大数据的基本结构.前文已述,当前的位置大数据主要来源于IOV、移动社交网络新兴互联网应用,有如下描述:
定义1. 位置数据集记为LBD={O,T,P},其中,O={o1,o2,…}表示数据集中的移动对象集合,包括了|O|个产生位置的移动目标;T为观察数据集的时间;|T|天内总共获得|P|个位置记录.
定义2. 单个位置数据记录p主要包含移动目标o和位置的地理坐标áx,yñ和记录时刻t,可以用一个四元或五元组表示.如果是车辆轨迹数据,一般还包含车辆的速度v以及一组状态信息S=áS1,S2,…ñ,如行驶方向、油耗值、载客状态等,记为p=áo,x,y,t,v,Sñ,其中,一个具体的状态Si可能有多个状态取值;如果是用户在社交网络等媒体上主动分享的位置数据,则还包括与位置相关的媒体信息I,可记为p=áo,x,y,t,Iñ.一般地,将移动目标oi的第j条位置记录记为![]() ,在不影响理解的情况下也可直接写作pj.
,在不影响理解的情况下也可直接写作pj.
位置大数据分析一般需要基于地图或路网数据展开.通常,平面地图被认为是一个连续的二维空间,为方便分析,需将其离散化,即,将地图划分为多个区域.这也是位置大数据预处理分析中普遍采用的方法,常见的包括:
(2) 依道路网分区[16].这种分区方法能够很好地保留地图语义.为了精简操作,一般按照城市主干道进行划分,如图 1(b)所示;
(3) 依位置密度分区[5, 17, 18].这种方法主要依据LBD中p的密度,将在一定范围内的位置点进行聚集,继而将地图划分为大小不同的网格或不规则图形(凸包),如图 1(c)所示.常见的密度聚类算法如DBSCAN[19]等;
(4) 依参考点分区[7].这种分区方法主要是选取LBD中若干位置点或地图上即有的若干兴趣点(point of interesting,简称POI)作为参考点,按照Voronoi多边形(又称为泰森多边形)的方式划分区域.使其每个分区内的任意一点到相应参考点的距离比到其他参考点的都近,从而很好地保留了参考点的代表性位置语义,如图 1(d)所示.
 | Fig. 1 Preprocessing method of map segmentation图 1 地图分区预处理方法 |
通过地图离散化,将地图划分为多个区域,完成对位置大数据分析的第1步预处理.在后文的分析中,我们不强调具体的分区方式,统一表述.
定义3. 一个地图区域集合记为Â={r1,r2,…,rn},其中,||Â||=n表示一共划分有n个区域,ri.ref为区域ri的参考点.
1.2 位置轨迹数据的预处理(1) 轨迹插值
在对位置大数据尤其是轨迹数据进行分析时,一般会要求数据集具有较高的采样率.当原始观察数据无法满足这样的要求时,可以对其进行简单线性插值[15].
(2) 地图匹配
地图匹配(map matching)是进行位置大数据研究的十分重要的预处理步骤,其目的是将原始观察数据与地图中的道路网信息联系起来,在使定位更加精确的同时,获取移动目标的移动轨迹.目前已存在一些经典算法,将位置数据、路网数据以及道路特征(如限速)等信息加以融合,能够较为准确地还原移动对象的轨迹.如ST-Matching算法、IVMM算法、Passby算法等[20,21,22,23].
定义4. 移动对象oi的一条轨迹j记为![]() ,||traj||表示轨迹上位置数据p的数量,称为轨迹长度.在不影响理解的情况下也可直接写作trajj.
,||traj||表示轨迹上位置数据p的数量,称为轨迹长度.在不影响理解的情况下也可直接写作trajj.
大数据分析的首要任务是从局部研究对象中提取出价值,建立单个区域ri或单个移动对象oi的若干特征模式.根据特征模式的提取方法,我们将其划分为如下两类:
(1) 一阶特征:是指从区域内的位置记录、地图数据或移动对象历史轨迹中可简单计算获得的特征,如均值、方差等;
(2) 二阶特征:是指需要经过一些高阶统计处理才能获得的模式特征.这些特征经过统计处理,能够在一定程度上消除原始观察数据混杂性所带来的影响,是本文归纳的重点.
2.1 区域静态特征js区域静态特征主要统计的是区域内与地图地貌相关的一些指标,可用于对不同区域进行聚/分类处理,常见的区域静态特征包括[14]:
(1) 路网特征(road feature,fRN)
fRN是由区域内快速路的长度、普通路段的长度、道路交叉口数量、区域道路弯曲度、道路基质质量等特性所构成的特征向量.
(2) POI特征(POI feature,fPOI)
fPOI可以为一个有关区域内POI信息的多维向量,包含各类型POI的数量及其变化率以及没有准确POI信息覆盖的区域面积等.
2.2 个体移动模式特征jmp个体移动模式(mobility pattern,简称MP)以单个移动对象o为观察目标,包括其在一段时间内的移动独一性、随机性、周期性、转移性、动静间歇性和移动期望性等方面.
(1) 移动独一性(uniqueness feature,funiq)
移动独一性可用来区别移动对象,定义为通过给定地图区域个数||r||、区域平均大小![]() 和统计时间间隔
和统计时间间隔![]() ,唯一确定一条轨迹trajj的概率,即:
,唯一确定一条轨迹trajj的概率,即:
![]() (1)
(1)
实证研究表明,当![]() 和
和![]() 相对合适时(比如当
相对合适时(比如当![]() =0.15km2,
=0.15km2,![]() =1 hour),仅需4个左右的区域(即||r||=4)便可以在茫茫人海中以很高的概率确定一条唯一的轨迹[7].当||r||固定时,这一概率与
=1 hour),仅需4个左右的区域(即||r||=4)便可以在茫茫人海中以很高的概率确定一条唯一的轨迹[7].当||r||固定时,这一概率与![]() 和
和![]() 分别呈现相似的幂律关系,即:
分别呈现相似的幂律关系,即:
![]() (2)
(2)
其中,b为幂指数,与||r||呈线性关系,满足:
b=l1-l2×||r|| (3)
这说明:参与决策的区域越多,幂指数越小,越容易确定移动独一性.文献[7]通过实证拟合,计算得到l1= 0.157,l2=0.007.
通过观察很少的区域,便能唯一确定一条用户轨迹.这既说明个体移动具有高度的规律性,也说明两两间移动行为具有很大的差异性.这种实证拟合的方法同样适用于分析其他任何LBD数据集.个体移动独一性funiq可以用在大数据环境下的个人隐私发掘或保护工作.独一性大小反映出数据集所在人群的整齐划一程度,因此在不同数据集上分析个体移动独一性,将有助于通过位置大数据分析其背后人群的自由程度、政治体制和生活情态,这将是很有趣的.
(2) 移动随机性(randomness feature,frand)
个体移动的随机性可用位置熵(location entropy)来度量.设px为访问一个位置的随机变量,参照信息熵的定义,可以给出多类位置熵:
① 假设移动对象oi共访问了||r||个不同的位置区域,其随机熵有:
H1=Hi(px)ºlog2||r|| (4)
② 进一步地,统计其在各个位置区域Â={r1,r2,…,r||r||}上出现的概率,记为{Pr(r1),Pr(r2),…,Pr(r||r||)},则其标准位置熵[24]有:
![]() (5)
(5)
③ 再进一步,考虑到移动对象oi位置记录的时序性traj=áp1®p2®…ñ,则位置时序熵有:
![]() (6)
(6)
通过比较不同移动对象的位置熵的相似性,可用来进行朋友关系预测等[24].此外,在LBD中,通过对O中所有的对象分别计算其位置熵H(×),继而获得熵的概率分布Pr{H(×)},便可对整体数据集中的移动随机性进行度量.位置熵还可以在不同时间尺度下(如将工作日和休息日分开)分别计算,这样可以对混杂的位置数据提取更多、更准确的知识.
(3) 移动周期性(periodic feature,fperi)
对一个移动对象oi来说,将其访问区域rj的序列二值化(1表示访问,0表示未访问),继而将该二值化序列进行离散傅立叶变换(discrete Fourier transform,简称DFT),通过观察傅立叶系数最大的频率,即可获得该位置点被访问的周期![]() [15].
[15].
假设一组位置区域Â={r1,r2,…,r||r||}具有相同的被访问周期TP={t1,t2,…,tk},划分到k个时间槽,从而可以得到一个个体移动详细的概率分布矩阵P=[r1,r2,…,rk],其中,每一个列概率向量rj=[Pr(r1|t=tj),Pr(r2),…,Pr(r||r||)].将LBD中T时段的位置记录按照周期TP分别生成![]() 个概率分布矩阵{P1,P2,…,Pm},则可通过计算两两间分布的KL散度(Kullback-Leibler divergence)来分析移动对象的周期行为.
个概率分布矩阵{P1,P2,…,Pm},则可通过计算两两间分布的KL散度(Kullback-Leibler divergence)来分析移动对象的周期行为.
将公式(6)细粒化,可以得到一个更为精细的标准位置熵:
![]() (7)
(7)
![]() (8)
(8)
对连续m个位置概率分布{P1,P2,…,Pm}按照相对熵大小进行层次聚类,可以得到频繁集最大的几个簇,代表移动对象oi的几个典型周期行为[18],如图 2所示.在聚类过程中,合并两个簇Ci和Cj的位置概率分布可简单计算为
![]() (9)
(9)
 | Fig. 2 Hierarchical clustering of periodic behaviour图 2 周期行为的层次聚类 |
(4) 移动转移性(transition feature,ftrans)
衡量移动对象oi在两个相邻时间段Tbef和Taft中是否存在区域集合Â={r1,r2,…,r||r||}上的转移行为,可以很方便地借助Jaccard相似性来统计[8].
设移动对象oi在Tbef和Taft时间段内在Â上的访问概率分别为F={Pr(r1),Pr(r2),…,Pr(r||r||)}和F ¢,则其Jaccard系数满足:
![]() (10)
(10)
ai越小,说明移动对象的转移性越明显.如果进一步对T内前后相邻的两个时间段分别计算ai,其期望![]() 可表示移动对象oi的整体转移性.
可表示移动对象oi的整体转移性.
转移性的另外一种常见的度量方法是计算移动对象oi在Â={r1,r2,…,r||r||}的转移概率,使用马尔可夫过程对用户的行为进行预测,相关的方法在我们早前的论文中有详细描述[2].
(5) 移动间歇性(intermittent feature,finte)
考虑到移动目标并不总是处于运动状态,则有必要从一段连续位置记录中发现其静止状态,以及估计造成这种静止状态的原因:分为被动静止(如车辆遇到红绿灯停车)和移动目标主动静止.
给定一条轨迹traj=áp1®p2®…ñ,若其中存在静止状态,则会出现较密集的几个连续位置点ápi®pi+1®…® pjñ.用密度聚类的方式将其归并,再根据归并后位置点所在区域的时空特征jÂ可分类判定[3, 14].
(6) 移动期望性(expectation feature,fexp)
假设移动对象有一组伴随移动的状态S=áS1,S2,…ñ(见定义1),每一类状态存在多种可能的状态值![]() .通过历史位置记录获得移动对象发生状态转换的相关统计特征,称为移动期望性.为了方便起见,我们将只阐述移动目标oi的状态S1发生转换的情况.
.通过历史位置记录获得移动对象发生状态转换的相关统计特征,称为移动期望性.为了方便起见,我们将只阐述移动目标oi的状态S1发生转换的情况.
定义5. 移动目标从T0时刻起,在路径path=árd1,rd2,…,rd|path|ñ上发生1次状态转换![]() 记为事件W.由于在一条路径path上可能包括停顿和移动过程两部分,不妨设存在m个停顿点{c1,c2,…,cm}.假设该状态转换恰好发生在路段rdi上,记为子事件
记为事件W.由于在一条路径path上可能包括停顿和移动过程两部分,不妨设存在m个停顿点{c1,c2,…,cm}.假设该状态转换恰好发生在路段rdi上,记为子事件![]() ;发生在停顿点ci上记为事件
;发生在停顿点ci上记为事件![]() .rdi.l表示路段rdi的长度,rdi.t表示经过路段rdi需花费的时间,ci.t表示在停顿点ci的平均停留时间.
.rdi.l表示路段rdi的长度,rdi.t表示经过路段rdi需花费的时间,ci.t表示在停顿点ci的平均停留时间.
设移动对象在路段rdi上发生状态转换的概率为![]() ,则以其达到路段rdi的时间
,则以其达到路段rdi的时间![]() 为参考,取其前后各kxt时间段内整体移动对象o的历史数据进行统计,则有:
为参考,取其前后各kxt时间段内整体移动对象o的历史数据进行统计,则有:
![]() (11)
(11)
若移动对象在停顿点发生状态转换,则其概率不仅与停止时刻有关,与停止时间长短也有关.到达停顿点ci前经过了![]() 个路段以及
个路段以及![]() 个停顿点,则到达ci的时刻为
个停顿点,则到达ci的时刻为![]() 以此为参考,取其前后各kxt时间段内整体移动对象o的历史数据进行统计,则有:
以此为参考,取其前后各kxt时间段内整体移动对象o的历史数据进行统计,则有:
![]() (12)
(12)
因此,事件![]() 发生的概率为
发生的概率为
![]() (13)
(13)
同理,可得![]() ,到达路段rdi前经过了
,到达路段rdi前经过了![]() 个路段以及
个路段以及![]() 个停顿点.
个停顿点.
因此,在一个存在|path|路段和m个停顿点的路径上,发生事件![]() 的概率为
的概率为
![]() (14)
(14)
根据公式(14),可以进一步计算从T0时刻开始到事件W发生时,移动对象所花费的时间期望E[T|W]和距离期望E[L|W],以及事件W发生后到下次再次发生状态转换时的时间E[TN|W]和距离期望E[LN|W]:
![]() (15)
(15)
![]() (16)
(16)
在计算E[TN|W]和E[LN|W]时,仍然依照partition-and-group的思想,将距离(0,lmax]以g为单位划分为若干个连续的区间.设rc={rdi,cj|i=1,…,|path|;j=1,…,m},则移动对象在rci上发生![]() 后到再次发生状态转换,其间移动的距离为g的j倍,其概率
后到再次发生状态转换,其间移动的距离为g的j倍,其概率![]() .同样,以到达rci的时间
.同样,以到达rci的时间![]() 为参考,取其前后各kxt时间段内整体移动对象o的历史数据进行统计,则有:
为参考,取其前后各kxt时间段内整体移动对象o的历史数据进行统计,则有:
![]() (17)
(17)
因此,事件W发生后,到下一次发生状态转换,其间移动的距离为jg的概率为
![]() (18)
(18)
移动距离的期望为
![]() (19)
(19)
同理,也可以求得时间期望值E[TN|W].
2.3 区域交通动力学特征jd区域交通动力学特征以位置区域为观察对象,对区域内多个移动目标的动态移动行为进行抽取.
定义6. 假设位置区域ri内存在着多个移动对象的历史记录,记为![]() 为该区域内被观察到的移动对象的个数.
为该区域内被观察到的移动对象的个数.
(1) 区域混杂性(diversity feature,fdiv)
统计一个区域内被访问的移动对象个体分布的差异,可以很好地区分不同位置区域的社会功能.设移动对象oj在区域ri内被观察到的次数为![]() 则其访问区域ri的概率为
则其访问区域ri的概率为
![]() (20)
(20)
那么,参照公式(5)可以定义该区域的访问熵.很显然:fdiv越大,说明该区域人员流动越混杂,一般出现在商场、银行等公共区域;反之,则说明该区域更加具有私密性[24].
(2) 区域流动性(traffic feature,ftraf)
① 路段上的转移花费时间
一个区域或一个路段上的转移时间花费是位置大数据分析中的重要特征.在定义5中,我们曾直接给出rdi.t为经过路段rdi所有移动目标所花费的期望时间,但由于移动目标在移动工具、驾驶习惯等方面的差异巨大,导致简单的期望时间往往不够精确,因此需要引入一个特征时间向量átc0,tc1,tc2,…,tckñ(tc0=0),用k+1个特征时间来反映路段rdi的转移时间特性.设![]() 为路段rdi上观察到的所有转移时间,经过特征时间向量átc0,tc1,tc2,…,tckñ可将
为路段rdi上观察到的所有转移时间,经过特征时间向量átc0,tc1,tc2,…,tckñ可将![]() 划分为k+1个子集合,记为T j={tcj-1<ti≤tcj},Ñ(T×)为其统计方差,átc1,tc2,…,tckñ满足:
划分为k+1个子集合,记为T j={tcj-1<ti≤tcj},Ñ(T×)为其统计方差,átc1,tc2,…,tckñ满足:
![]() (21)
(21)
如何确定k的大小及各个特征时间,是其中的关键问题.一般来说,不同的路段有不同的k值.文献[26]采用了一种贪婪二分法去求取特征向量átc0,tc1,tc2,…,tckñ,并将其所得到的特征转移时间分布来训练导航引擎,取得了很好的效果.
在各个路段转移时间特征提取的基础上,进一步对位置区域ri内的流动性进行分析,几个常见的指标[14, 27]包括:
② 区域内移动速度的期望E(v)和方差D(v)
假定在一个时间段T内,区域ri内的交通特征稳定不变,则可通过对这个时段在区域上的所有轨迹数据{traj1,traj2,…,trajn}进行统计分析.设定轨迹![]() 的总长度
的总长度![]() ,时长
,时长![]() ,其中,dist(pj,pj+1)表示pj与pj+1的距离,则有:
,其中,dist(pj,pj+1)表示pj与pj+1的距离,则有:
![]() (22)
(22)
进一步地,很容易计算方差D(v).
③ 区域交通流动性的时间演化性
进一步引入时间维度,可以对区域流动性的时间演化性[15]进行分析.
设区域流动性随时间变化的函数Traffici(t)满足:
Traffici(t)=ai×Traffici(t-ti)+(1-ai)×(1-Pr{o.u≤E(t)(v)}) (23)
其中,ai和ti是反映演化特性的两个参数.t是区域交通流量的观察时间窗口,一般可以将一段时间内连续的N个位置记录p.v构造成一个时序信号V(t),对其进行DFT,获得其频率分布
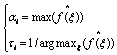 (24)
(24)
(3) 区域聚散性(arriving-departure feature,farr-dep)
聚散性反映了一个位置区域中移动对象整体进入及离开的动力学模式,一般通过将一天划分为k个时段,继而统计LBD历史记录中该天每个时段“来到区域”和“离开区域”这两个行为的次数,以构造两个统计向量![]() 和
和![]() ,dayi表示第i天.在这两个向量统计的基础上,可以构造一批区域聚散性的二阶特征指标[5],如聚散比等:
,dayi表示第i天.在这两个向量统计的基础上,可以构造一批区域聚散性的二阶特征指标[5],如聚散比等:
![]() (25)
(25)
此外,我们也经常需要对移动目标离开(或到达)一个区域的时间进行估计.较为常见的方法是将其看作一个非齐次泊松过程(non-homogeneous Poisson process),对特征参数l(t)进行估计[28].对路段k天内同一个时间片DT内的聚散事件E的数量进行观察,可得到似然函数:
![]() (26)
(26)
![]() (27)
(27)
结果说明:可以根据多天内到达/离开区域的平均数量来对l(t)进行建模,构建一个线性分段函数.
3 位置大数据降维分析及全局建模 3.1 位置大数据建模定义7. 参考定义3,我们可以将LBD所在的地图划分为n个区域,Â={r1,r2,…,rn},分别计算1天内各个时间片Ts={t1,t2,…,tm}下的局部特征r.j,j=ájs,jmp,jdñ中的全部或部分特征,可以得到一个mxn的特征矩阵M1.再引入时间维度T={d1,d2,…,dD},则可得到一个特征立方体C1.
M1和C1是一种常见的LBD建模方式[27],其缺点是无法直观反映两两区域间的联系.因此将其变形,可以得到位置大数据网络LBDN.这是一种利用网络科学[29, 30]思想建立的有关位置大数据的全局模型,其主要目的就是为了通过网络全局特征建模[31],获得LBD数据的全局知识,从而参与到相关关联应用的分析中.
定义8. 位置大数据网络为N={Â,L,j},其中,Â={r1,r2,…,rn}为LBD对应的地图的区域集合,L表示连接各区域的边的集合L={lij}.因此,N也可以用一个nxn的邻接矩阵M2={lij}表示,lij=1表示区域ri和rj之间存在移动性联系.
定义9. lij的权值反映了区域ri和rj之间移动性的关联,可根据具体情况定义不同的函数Wári.j,rj.jñ进行衡量,比如,Wári.j,rj.jñ可以表现为ri和rj之间的交通流量.
图 3给出了用户轨迹、道路和lij的关系.一般地,在一个分区域地图上,一条用户轨迹traj=áp1®p2®…ñ可以被粗粒化为traj=ári®rj®…ñ,如图 3(a)所示.依据轨迹的起止点可以建立LBDN,如图 3(b)所示.
 | Fig. 3 Illustration of LBDN图 3 LBDN示意图 |
定义10. 将时间维度Ts={t1,t2,…,tm}引入位置大数据网络为N={Â,L,j},则可得到一个nxnxm位置立方体C2,其每个纵切面为一个时间尺度下的邻接矩阵,记为![]() ;每个横切面即M1,如图 4所示.
;每个横切面即M1,如图 4所示.
 | Fig. 4 Global model of LBD (C1,C2)图 4 位置大数据全局模型(C1和C2) |
下面将阐述如何综合使用M1和M2这两类矩阵模型,构建LBD全局特征的方法.
3.2 空间尺度上的降维处理降维分析(dimensionality reduction analysis)在大数据处理中是非常重要的环节,对于LBDN在空间尺度上的降维处理,其核心就是希望减少Â={r1,r2,…,rn}中的区域或减少L中的边,通过关键分量的分析获得全局特征(如图 5所示).
 | Fig. 5 Dimensionality reduction of LBDN图 5 LBDN的降维处理 |
一种直观的方法是比较r.j,选取特征显著的区域作为关键区域[32].考虑到LBDN主要是用来反映区域间移动特性的(这样的LBDN又被称为“交通网络”),下面我们着重介绍另外两种针对交通网络的空间降维方法.
① 依超介数进行降维
在交通网络中,结点ri的介数(betweenness centrality)是反映结点交通重要性的标志特征[30],一般定义为网络中所有经过ri的最短路径数量(因为大部分交通行为是按照最短路径原则展开的).
介数是以单条路径逐次计算而实现的,忽视了多条路径在交通中存在的关联性.所以我们对介数指标进行了改进,其核心思想是:
i) 如果网络中大量交通行为会同时选择两个结点ri和rj作为其最短路径的传播点,那么这两个结点的重要性是共生关系,记为zij>0.原始介数指标将这二者共同承担的那一部分重要性重复计算到各自结点中去,造成了重要性的高估;
ii) 如果对网络中结点ri进行摘除后可以发现,原本那些以ri为最短路径的链路大部分“取道”结点rj,说明结点rj对结点ri具有潜在的替代作用,记为zij<0.这种替代性在原始介数指标中未能体现,从而造成了结点交通重要性的低估.
定义11. 结点ri的重要性![]() 一部分由自身的介数Ii所决定,而另一部分则通过其他结点与它的关联性来衡量,有:
一部分由自身的介数Ii所决定,而另一部分则通过其他结点与它的关联性来衡量,有:
![]() (28)
(28)
② 依主分量进行降维
依超介数降维的方法针对的是LBDN中的Â,此外,还可以通过主分量分析(principal components analysis,简称PCA)法对L进行空间降维分析[4].
3.3 时间尺度上的降维处理在前文中,我们提及Ts={t1,t2,…,tm},通常表示将一天划分到m个时间片去观察LBD.事实上,只有观察到移动对象的整体移动模式在各自时间片下具有显著不同的差异时,划分的时间片才有意义.那么如何找寻和量化这种“显著差异”呢?不失一般性,我们在一天24小时内观察O中的每一个移动对象的某种移动行为特征f.设f=áe1,e2,…,emñ有m个取值,则对每个移动对象可以用二元组átimei,ejñ表示,得到全体样本集合S={átimei,ejñ},其中, timei表示观察时刻.那么,在该样本下移动行为特征f的熵为
![]() (29)
(29)
假设将一天分为两个时间片,则按公式(29)分别计算各自时间片下各观察样本特征f的概率分布,记为P(f)和Q(f).二者的距离仍然可以用KL散度来度量,有:
![]() (30)
(30)
那么,只有当时间片由ti=argmaxtKL(P||Q)划分时才是最有意义的.同样地,这种划分可以采用一种贪婪二分法继续深入下去,直到所划分的两个特征f的概率分布的距离差异小于阈值即可[26].
至此,可以得到一个灵活且相对精确的时间片划分Ts={t1,t2,…,tm}(所得到的每个时间片不一定与整点时刻对齐),同时使得m最小且有意义.
3.4 全局特征分布的模型生成首先,在对M1和M2(C1和C2)进行适当降维处理后,即可采用生成模型(generative model)的思路,从LBD观察样本数据构建整体的概率模型;然后,将这些模型中的参数当作一种更高阶的特征参与到具体的关联应用中,作为聚类、分类或关联挖掘的依据.
近几年来,随着自然语言处理(natural language processing,简称NLP)技术的发展,其中很多经典的生成模型如隐含狄利克雷分配模型(latent Dirichlet allocation,简称LDA)等已在社交网络计算、推荐系统等多个领域广泛应用[35,36,37].在位置大数据分析中,这一类生成模型也有很好的应用前景,比如,文献[16]将LDA模型用于通过用户行为模式发掘城市各区域的土地功能,取得了相当好的效果.
站在位置社会感知的角度,可以认为人们的移动行为(MP)都是与所在位置区域的社会语义上下文密切相关的,可以用jmp去度量.也就是说,每个MP的产生都可以看作是“先以一定概率选择了区域的某个社会语义特征(social semantic feature,简称SSF),然后再从这个特征中以一定概率选择了特定MP”而得到的,如图 6所示.LDA的目的之一就是通过观察样本去学习隐分布q和f.![]() 是区域ri的社会语义分布的非负归一化向量,表明该区域满足每种社会语义(共Y种)的概率.Pr(q|a)是q的分布,被设置成为狄利克雷分布(Dirichlet distribution)形式,具体用来生成q,由参数a确定.f是一个条件分布Pr(MP|SSF),表明各种社会语义下各类移动行为发生的概率,是一个x×Y的矩阵,由参数b确定[35].
是区域ri的社会语义分布的非负归一化向量,表明该区域满足每种社会语义(共Y种)的概率.Pr(q|a)是q的分布,被设置成为狄利克雷分布(Dirichlet distribution)形式,具体用来生成q,由参数a确定.f是一个条件分布Pr(MP|SSF),表明各种社会语义下各类移动行为发生的概率,是一个x×Y的矩阵,由参数b确定[35].
 | Fig. 6 LDA based generative model of location data图 6 基于LDA的位置数据生成模型 |
这种方法所最终确定的两个分布q和f在位置大数据分析中具有相当重要的作用:
· f表明了位置的社会语义与移动行为模式之间的关系.比如,文献[5]将移动模式行为(类似区域聚散性行为)与城市区域的功能用途联系起来.同样地,也可以使用其他移动模式特征与其他社会语义关联,从而达到通过位置大数据分析人类社会的目的;
· q是位置区域满足社会语义概率,这种概率向量其实也可以被进一步看作是区域移动模式特征.因此,q一方面可以作为位置社会感知的量化结果;另一方面,也可以作为一种区域位置特征的精炼表达形式,参与到其他数据挖掘的工作中去.
此外,通过对LBDN的观察,还可以获得社群整体移动的规律.尤其是在特殊时段或特殊事件发生前后,对社群整体移动行为建模,也是位置大数据建模的重要任务.
设在某特殊时段或事件发生时(记为事件E)的社群移动行为是L=árs®ri®…®rdñ,人群在各个位置区域上的移动轨迹称为route x.各个位置区域上存在着一组特征向量j=áf1,f2,…ñ,每种特征都与人群的转移有内在联系,则在一个route x上移动的开销函数有:
![]() (31)
(31)
假设事件E发生时,观察到人群具有初步的移动![]() ,计算其最终达到区域rd的概率满足贝叶斯公式:
,计算其最终达到区域rd的概率满足贝叶斯公式:
![]() (32)
(32)
![]() (33)
(33)
运用拉格朗日乘数法,很容易求得满足条件最大熵原则的Pr(x|Vl),有:
![]() (34)
(34)
Z是归一化因子,定义为
![]() (35)
(35)
求解公式(34)的方法在马尔可夫决策过程(Markov decision process,简称MDP)中经常会碰到,一般采用GIS,IIS等迭代算法[8, 38, 39],直到Pr(x|Vl)收敛,获得Vl.那么,公式(32)中的![]() 也就可以很容易获得:
也就可以很容易获得:
![]() (36)
(36)
在LDBN实际运算过程中,可以用Bellman-Ford算法列举出rs®rd的若干最短路径即可.
通过上述MDP建模,我们可以观察多种事件E条件下社群的移动规律.在较早的论文中[2],我们还提到了使用隐马尔可夫模型(hidden Markov model,简称HMM)或动态贝叶斯网络(dynamic Bayesian network,简称DBN)的移动行为预测方法,对于社群行为推测仍然适用.
4 特征关联及协同挖掘大数据研究中还有一个突出问题,即,数据稀疏性导致的结果失真.比如文献[15]发现,通过城市出租车轨迹密度所绘制的城市交通热点图与真实情况存在很大的偏差.原因是出租车群体往往比较喜欢在一些特定场所聚集,从而造成这些地方的观察数据密度过高.而真正需要密度数据的区域,由于缺少采集手段,却又无法获得真实的位置记录.
造成位置大数据稀疏的主要原因与采集手段和采集对象都有关:
(1) 一些位置区域天然地缺少移动对象访问(比如新修路段、偏远地区等);
(2) 特定的采集对象群体的移动偏好,使得有些位置区域很少被这一群体访问,而其他那些经常访问的群体又难以采集;
(3) 受到通信、存储等客观条件制约,使得采集数据在时间尺度上不连续,也会造成时间尺度上的稀疏.针对这些问题,需要有效借助一些协同挖掘的方法,还原整体样本.
4.1 空间尺度上的协同挖掘① 空间区域聚类
位置区域的关联聚类是解决空间数据稀疏的主要手段之一.主要采用区域的静态特征js构成一组特征向量,用向量间的欧式距离(Euclidean distance)、马氏距离(Mahalanobis distance)、余弦相似性等常见的手段度量各特征向量的差异,并运用一种层级聚类方法,将特征相似的区域归于一类,从而用数据样本较多的区域去“替代”数据样本较少的区域[3, 16].
② 协同过滤
与区域聚类思想不同,用协同过滤(collabora-tive filtering)算法对数据整体性进行补充.不妨设M1矩阵记录了各时间片下各位置区域的交通流量(如某种ftraf),由于数据采集的问题造成了一定的区域数据缺失,如图 7(a)所示.下面介绍用协同过滤的思想对缺失数据进行估计.
协同过滤实际上是在PCA的基础上基于矩阵分形而得到的一种数据项聚类(item clustering)方法,被广泛应用于推荐系统(recommender systems)中.常见的矩阵分形有UV分解(如图 7(a)所示)、SVD分解等.
 | Fig. 7 Collaborative filtering of location data图 7位置数据的协同过滤 |
以UV分解为例,设M1=UxV.首先假设U,V矩阵内全为1,得到一个![]() ,计算M1和
,计算M1和![]() 的方均根误差(root meansquare error,简称RMSE),有:
的方均根误差(root meansquare error,简称RMSE),有:
![]() (37)
(37)
注意到:如果对uxy进行猜测,则仅会影响![]() 的第x行元素.于是,只需对
的第x行元素.于是,只需对![]() 与M1所有第x行的已知元素进行计算,便可得到由uxy而带来的误差:
与M1所有第x行的已知元素进行计算,便可得到由uxy而带来的误差:
![]() (38)
(38)
![]() (39)
(39)
同理,对V的一个元素vxy进行改变,使RMSE最小的值为
![]() (40)
(40)
依据公式(39)、公式(40)的显式解,可以直接完成最优解的搜索过程.
一般地,为了突出位置区域的局部特征在协同过滤中的作用[27],可以将空间区域聚类的思想引入协同过滤算法中.不妨构造一个辅助矩阵Z=Âxj,如图 7(b)所示,其每个行向量记为ji.将各个位置区域的局部特征量化后形成一组特征向量,并构造一个过滤因子函数![]() (在实际计算中,不一定采用线性函数形式).将各个区域的Wi加入到
(在实际计算中,不一定采用线性函数形式).将各个区域的Wi加入到![]() 中,得到
中,得到![]() .反复调整参数向量Vl,并通过目标函数
.反复调整参数向量Vl,并通过目标函数![]() 控制优化搜索的方向,恢复更为准确的全局数据.
控制优化搜索的方向,恢复更为准确的全局数据.
注意到,UV分解或SVD分解得到的分形矩阵,在维度上要远远小于原矩阵,十分有利于大数据分析.最后,在位置大数据实际分析中,如果引入时间维度,则可能是对C1或C2进行协同过滤,这就需要使用高阶奇异值分解(high order singular decomposition,简称HSVD)[27].同时,如果矩阵M1或M2中的“值”是一个由多个局部特征构成的特征向量,则公式(37)需要重新定义,引入向量距离的计算方法来度量整体差异.
4.2 时间尺度上的协同挖掘将从LBD中提取的特征与某一特定应用关联,在时间尺度上很容易建立起概率图模型(graphical model).因此,时间尺度上的协同挖掘可以灵活地选择HMM[40]、条件马尔可夫模型(conditional Markov model,简称CMM)或条件随机场模型(conditional random fields,简称CRF)[14]来处理.
在位置数据的概率图模型中,一般将状态序列s1,s2,…定义为需要透过位置大数据获得的知识(比如区域内人的情感、区域的环境污染情况等),将观测序列定义为位置特征j1,j2,…,其中,j1,j2,…,=f1,f2,…,运用图模型的3个基本问题,可以完成尺度上的协同挖掘.
5 位置大数据的应用框架 5.1 位置大数据的关联应用分析在大数据科学研究中,一些与数据本身的来源和主体看似无关的对象,在经过数据价值提取和协同挖掘后往往会呈现出密切关联性.同样地,位置大数据的应用分析,将不仅仅被用来进行交通问题的分析,还能够提升我们对更为广泛的人类社会经济活动和自然环境的认识,从而体现其真正价值.事实上,LBD完全可以与城市生活的经济运行情况(如CPI指数、绿色GDP指数、房价指数、城市投资与负债情况)、城市资源与环境情况(如PM2.5)[14, 27]、城市土地规划[5, 16],甚至政府执政水平等联系起来,以位置数据特征作为观测值,以地理国情情况作为隐变量,进行全局建模和协同挖掘.
5.2 应用框架描述我们在上述思路的基础上,提出了一种位置大数据管理应用分析的框架(location big data relational analysis framework,简称LRAF),并将其实施到一个在线车联网位置服务系统iWISE[41]中,作为一种位置数据的智能处理中间件[42].图 8描述了其基本结构和步骤:
 | Fig. 8 Location big data relational analysis framework图 8 位置大数据关联应用分析的框架 |
i) 将社会经济及自然环境有关的数据与位置区域的特征数据进行相关分析,通过散点图绘制和Pearson相关等常见相关系数的计算和分析,找出人类行为和这些待分析事务间的关联性;
ii) 将这些关联性知识引入LBDN中,进行协同挖掘和全局数据建模,重点是对整体概率分布等参数进行学习,获得社会经济运行情况或自然环境分布情况的整体知识;
iii) 运用学习后得到的大数据整体知识,发现社会问题,引导社会行为.
6 结束语本文以位置大数据为对象,针对其混杂性、复杂性和稀疏性,系统综述了如何进行价值提取和协同挖掘的方法.大数据科学研究强调“重关联,轻因果”,如何将位置数据与人类社会生活关联起来,是本文阐述的重点.这些方法被引入到一个位置服务软件框架中,将为智慧城市建设等提供支撑.
传统测绘强调对物理世界的测量.如果能够将对物理世界的测量结果(即位置)引申到对人类社会的测量中去,将极大地促进计算机和测绘科学的联系,形成一种智能化、社会化的泛在测绘计算[43].因此,本文所归纳和阐述的位置大数据分析方法具有重要的意义.
| [1] | Liu JN. The recent progress on high precision applications of Beidou navigation satellite system. Report of the Stanford’s 2012 PNT Challenges and Opportunities Symp. (SCPNT 2012), 2012. http://scpnt.stanford.edu/pnt/pnt2012.html . |
| [2] | Guo C, Fang Y, Liu JN, Wan Y. Study on social awareness computation methods for location-based services. Journal of Computer Research and Development, 2013,50(12):2531-2542 (in Chinese with English abstract). |
| [3] | Yuan NJ, Zheng Y, Zhang LH, Xie X. T-Finder: A recommender system for finding passengers and vacant taxis. IEEE Trans. on Knowledge and Data Engineering, 2012,25(10):2390-2403 . |
| [4] | Chawla S, Zheng Y, Hu J. Inferring the root cause in road traffic anomalies. In: Proc. of the IEEE 12th Int’l Conf. on Data Mining (ICDM). Piscataway: IEEE, 2012. 141-150. |
| [5] | Pan G, Qi GD, Wu ZH, Zhang DQ, Li SJ. Land-Use classification using taxi GPS traces. IEEE Trans. on Intelligent Transportation Systems, 2012, 14(1):113-123 . |
| [6] | Song C, Qu Z, Blumm N, et al. Limits of predictability in human mobility. Science, 2010,327(5968):1018-1021 . |
| [7] | de Montjoye YA, Hidalgo CA, Verleysen M, Blondel UD. Unique in the CROWD: The privacy bounds of human mobility. Scientific Reports, 2013,3 . |
| [8] | Song X, Zhang QS, Sekimoto Y, Horanont T, Ueyama S, Shibasaki R. Modeling and probabilistic reasoning of population evacuation during large-scale disaster. In: Proc. of the 19th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2013. 1231-1239 . |
| [9] | Sadilek A, Kautz HA, Silenzio V. Modeling spread of disease from social interactions. In: Proc. of the 6th Int’l AAAI Conf. on Weblogs and Social Media (ICWSM). Menlo Park: AAAI, 2012. 322-329. http://www.aaai.org/ocs/index.php/ICWSM/ICWSM12/paper/viewFile/4493%26lt%3B/4999 . |
| [10] | Li GJ. The scientific value of the study in big data. Communications of the China Computer Federation, 2012,8(9):8-15 (in Chinese with English abstract). |
| [11] | Wang S, Wang HJ, Qin XP, Zhou X. Architecting big data: Challenges, studies and forecasts. Chinese Journal of Computers, 2011, 34(10):1741-1752 (in Chinese with English abstract) . |
| [12] | Wang YZ, Jin XL, Cheng XQ. Network big data: Present and future. Chinese Journal of Computers, 2013,36(6):1-15 (in Chinese with English abstract). |
| [13] | Meng XF, Ci X. Big data management: Concepts, technique and challenges. Journal of Computer Research and Development, 2013, 50(1):146-169 (in Chinese with English abstract). |
| [14] | Zheng Y, Liu F, Hsie HP. U-Air: When urban air quality inference meets big data. In: Proc. of the KDD. 2013. http://research.microsoft.com/pubs/193973/U-Air-KDD-camera-ready.pdf . |
| [15] | Liu SY, Liu YH, Ni LM, Fan JP, Li ML. Towards mobility-based clustering. In: Proc. of the 16th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2010. 919-928 . |
| [16] | Yuan J, Zheng Y, Xie X. Discovering regions of different functions in a city using human mobility and POIs. In: Proc. of the 18th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2012. 186-194 . |
| [17] | Zhu B, Huang QX, Guibas L, Zhang L. Urban population migration pattern mining based on taxi trajectories. 2013. http://sensor.ee.tsinghua.edu.cn/mediawiki/images/b/b1/2013.Migration.BingZhu.pdf . |
| [18] | Li ZH, Ding BL, Han JW, Kays R, Nye P. Mining periodic behaviors for moving objects. In: Proc. of the 16th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2010.1099-1108 . |
| [19] | Ester M, Kriegel H-P, Sander J, Xu XW. A density-based algorithm for discovering clusters in large spatial databases with noise. In: Proc. of the KDD, Vol.96. 1996. 226-231. http://www.aaai.org/Papers/KDD/1996/KDD96-037.pdf . |
| [20] | Lou Y, Zhang CY, Zheng Y, Xie X, Wang W, Huang Y. Map-Matching for low-sampling-rate GPS trajectories. In: Proc. of the 17th ACM SIGSPATIAL Int’l Conf. on Advances in Geographic Information Systems. New York: ACM Press, 2009.352-361 . |
| [21] | Yuan J, Zheng Y, Zhang CY, Xie X, Sun GZ. An interactive-voting based map matching algorithm. In: Proc. of 2010 the 11th Int’l Conf. on Mobile Data Management (MDM). Kansas City: IEEE, 2010.43-52 . |
| [22] | Liu KE, Li YG, He FC, Xu JJ, Ding ZM. Effective map-matching on the most simplified road network. In: Proc. of the 20th Int’l Conf. on Advances in Geographic Information Systems. New York: ACM Press, 2012. 609-612 . |
| [23] | Tang YZ, Zhu AD, Xiao XK. An efficient algorithm for mapping vehicle trajectories onto road networks. In: Proc. of the 20th Int’l Conf. on Advances in Geographic Information Systems. New York: ACM Press, 2012.601-604 . |
| [24] | Cranshaw J, Toch E, Hong J, Kittur A, Sadeh N. Bridging the gap between physical location and online social networks. In: Proc. of the 12th ACM Int’l Conf. on Ubiquitous Computing. New York: ACM Press, 2010.119-128 . |
| [25] | Lee JG, Han J, Whang KY. Trajectory clustering: A partition-and-group framework. In: Proc. of the 2007 ACM SIGMOD Int’l Conf. on Management of Data. New York: ACM Press, 2007. 593-604 . |
| [26] | Yuan J, Zheng Y, Xie X, Sun GZ. T-Drive: Enhancing driving directions with taxi drivers’ intelligence. IEEE Trans. on Knowledge and Data Engineering, 2013,25(1):220-232 . |
| [27] | Zhang FZ, Wilkie D, Zheng Y, Xie X. Sensing the pulse of urban refueling behavior. In: Proc. of the 2013 ACM Int’l Joint Conf. on Pervasive and Ubiquitous Computing. New York: ACM Press, 2013.13-22 . |
| [28] | Zheng XD, Liang X, Xu K. Where to wait for a taxi? In: Proc. of the ACM SIGKDD Int’l Workshop on Urban Computing. New York: ACM Press, 2012.149-156 . |
| [29] | Barabási AL, Albert R. Statistical mechanics of complex networks. Reviews of Modern Physics, 2002,74(1):47-97 . |
| [30] | Newman MEJ. The structure and function of complex networks. Society for Industry and Applied Mathematics, 2003,45(2): 167-256. |
| [31] | Yin CY, Wang BH, Wang WX, Zhou T, Yang HJ. Efficient routing on scale-free networks based on local information. Physics Letters A, 2006, 351(4):220-224 . |
| [32] | Zheng Y, Liu YC, Yuan J, Xie X. Urban computing with taxicabs. In: Proc. of the 13th Int’l Conf. on Ubiquitous Computing. New York: ACM Press, 2011.89-98 . |
| [33] | Guo C, Wang LN, Zhang XY. Study on network vulnerability identification and equilibrated network immunization strategy. IEICE on Information and System, 2012,E95-D(1):46-55 . |
| [34] | Zhang XY, Wang LN, Guo C. Using game theory to reveal vulnerability for complex networks. In: Proc. of the 10th IEEE Int’l Conf. on Computer and Information Technology (CIT 2010). Bradford: IEEE, 2010. 978-984 . |
| [35] | Blei DM, Ng AY, Jordan MI. Latent dirichlet allocation. The Journal of Machine Learning Research, 2003,3:993-1022. |
| [36] | Wang Y, Agichtein E, Benzi M. Tm-Lda: Efficient online modeling of latent topic transitions in social media. In: Proc. of the 18th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2012. 123-131. http://dl.acm.org/citation.cfm?id=2339552 . |
| [37] | Porteous I, Newman D, Ihler A, Asuncion A, Smyth P, Welling M. Fast collapsed gibbs sampling for latent dirichlet allocation. In: Proc. of the 14th ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining. New York: ACM Press, 2008. 569-577 . |
| [38] | Song X, Zhang QS, Sekimoto Y, Horanont T, Ueyama S, Shibasaki R. An intelligent system for large-scale disaster behavior analysis and reasoning. IEEE, 2013 . |
| [39] | Ziebart BD, Maas AL, Bagnell JA, Dey AK. Maximum entropy inverse reinforcement learning. In: Proc. of the 23th AAAI Conf. on Artificial Intelligence. AAAI, 2008. 1433-1438. http://www.aaai.org/Papers/AAAI/2008/AAAI08-227.pdf . |
| [40] | Sadilek A, Kautz H, Bigham JP. Finding your friends and following them to where you are. In: Proc. of the 5th ACM Int’l Conf. on Web Search and Data Mining. New York: ACM Press, 2012.723-732 . |
| [41] | Guo C, Liu JN. iWISE: A location-based service cloud computing system with content aggregation and social awareness. In: Proc. of the 10th Int’l Symp. on Location Based Services (LBS 2013). Shanghai, 2013. |
| [42] | Wang ZH, Li JZ, Gao H. Data model for dirty databases. Ruan Jian Xue Bao/Journal of Software, 2012,23(3):539-549 (in Chinese with English abstract). http://www.jos.org.cn/1000-9825/4042.htm |
| [43] | Liu JN. The concept and progress of ubiquitous mapping and ubiquitous position. Digital Communication World, 2011,4:28-30 (in Chinese). |
| [2] | 郭迟,方媛,刘经南,万怡.位置服务中的社会感知计算方法研究.计算机研究与发展,2013,50(12):2531-2542. |
| [10] | 李国杰.大数据研究的科学价值.中国计算机学会通讯,2012,8(9):8-15. |
| [11] | 王珊,王会举,覃雄派,周烜.架构大数据:挑战、现状与展望.计算机学报,2011,34(10):1741-1752 . |
| [12] | 王元卓,靳小龙,程学旗.网络大数据:现状与发展.计算机学报,2013,36(6):1-15. |
| [13] | 孟小峰,慈祥.大数据管理:概念、技术与挑战.计算机研究与发展,2013,50(1):146-169. |
| [42] | 王志宏,李建中,高宏.一种非清洁数据库的数据模型.软件学报,2012,23(3):539-549. http://www.jos.org.cn/1000-9825/4042.htm |
| [43] | 刘经南.泛在测绘与泛在定位的概念与发展.数字通信世界,2011,4:28-30. |