 2014, Vol. 25
2014, Vol. 25



2 厦门大学 软件学院, 福建 厦门 361005
2 School of Software, Xiamen University, Xiamen 361005, China
关系数据库在经历多年的发展后,已经是一种非常成熟的数据存储和管理技术,在各个领域得到广泛的应用.在关系数据库中,数据存储在“关系”中,具有规则的数据结构.因此,这类数据通常被称为结构化数据.针对存在于关系数据库中的结构化数据,可以借助于功能强大的结构化查询语言(比如SQL语句)来查找满足特定要求的记录集合.由于已经存在很多的针对SQL查询的性能优化算法,因此,利用SQL语句进行查询可以获得很高的性能.但是,SQL查询也有一个明显的缺陷,那就是要求用户必须具有一定的数据库专业知识,能够熟练掌握SQL语句的书写方法,并且需要了解底层的数据结构.很显然,这对于普通用户而言,是一个不小的障碍,因而也就无法灵活地为普通用户提供个性化的查询服务.与此同时,为了适应激烈的市场竞争,企业越来越需要普通员工能够灵活访问企业数据库中的各种数据,提升服务质量和工作效率,因而需要开发面向普通用户的关系数据库数据查询技术.
关键词查询可以很好地解决SQL查询面临的这个问题.关键词查询是互联网中普遍采用的信息检索方式(比如Google和百度),它不需要用户具备任何专业知识,只需要用户提供查找的关键词,系统就可以为用户返回相关的查询结果.受此启发,研究人员开始采用关键词进行关系数据库查询的各种探索工作.
对于关系数据库的关键词查询,绝大多数研究都可以归为两大类,即基于数据图的方法(比如文献[1-4])和基于模式图的方法(比如DBXplorer[5]、DISCOVER[6]以及文献[7]等).前者把数据库建模成数据图,然后从数据图中寻找包含查询关键词的多棵Steiner树[8],经过评分排序后,输出top-k棵Steiner树作为查询结果;后者利用数据库模式创建连接表达式,然后在DBMS上执行连接表达式对应的SQL语句得到结果.基于模式图的方法只能应用于关系型数据的搜索;而基于数据图的方法则可以用于关系型、XML和HTML数据,因为这些数据都可以用数据图的形式表示.
但是已有的研究存在一个明显的不足:无法根据不断变化的用户查询兴趣而动态地优化查询结果.在日常的应用中,用户查询的兴趣有时候会发生突然变化,比如发生了突发事件,会迅速转移大量用户的查询兴趣.针对这种突变的用户兴趣,不能使用基于长期的概率统计来衡量.比如用户的查询兴趣突然从A转到B,即在查询结果中突然更多选择B而很少选择A,导致B的访问量急剧增加.但是由于历史上有很多用户曾经访问过A,使得A的绝对访问次数远远高于B.因此,如果仍然采用基于长期概率统计的方法,就会给出错误的查询结果.因此,必须研究一种可以有效衡量用户查询兴趣突变的方法,并设计相应的查询结果动态优化算法.对于已有的研究方法,每次查询都是根据事先确定的评分排序(score and rank)方法对大量候选结果进行排序,生成top-k个结果推荐给用户,用户的访问情况不会对这些算法产生动态的影响,自然也就无法实现根据用户查询兴趣的动态查询优化.因此,本文提出一种高效的、基于概念漂移和蚁群优化算法的关键词查询新方法,可以根据突变用户兴趣而不断地动态优化查询结果.
需要指出的是,本文的研究重点在于采用概念漂移理论解决查询结果优化问题,而不在于如何采用蚁群优化算法提高查询响应速度.本文的关键是发现了蚁群算法和概念漂移理论的巧妙结合,可以较好地解决用户查询结果动态优化问题.首先,本文使用蚁群算法解决从数据图中搜索Steiner树(查询结果)的问题;其次,采用概念漂移理论跟踪用户兴趣变化,指导蚁群优化算法的结果生成过程,使得查询结果更加符合用户预期.实际上,采用蚁群算法得到查询结果的过程,就是数据图中各个节点上的蚂蚁爬向目标节点(包含查询关键词)的过程,而目标节点就是用户的查询兴趣所在,因为包含了用户查询关键词.用户查询兴趣的变化就会导致目标节点的变化,概念漂移理论可以有效跟踪用户的当前兴趣节点,从而改变蚂蚁的爬行目标,动态给出不同的、更加满足用户需求的查询结果.因此在本文中,蚁群优化算法是基础,采用概念漂移理论探测用户兴趣变化和指导蚁群算法执行过程是核心内容.
总的来说,本文的主要贡献是:
· 提出了基于蚁群优化算法的、关系数据库关键词查询新算法ACOKS(ant-colony-optimization-based keyword search),为基于概念漂移理论的查询结果动态优化提供基础;
· 提出了基于概念漂移理论的用户查询兴趣突变探查方法,可以及时发现用户兴趣的突变;
· 提出了基于概念漂移理论和ACOKS算法的查询结果动态优化算法ACOKS*,可以根据突变的用户兴趣,动态优化查询结果,使其更加符合用户查询预期;
· 构建了原型系统并进行了大量实验,结果表明,本文的方法可以比已有的方法取得更好的性能.
本文第1节给出问题描述.第2节详细阐述如何用蚁群优化算法解决关键词查询问题,描述了ACOKS算法.第3节介绍基于概念漂移和ACOKS算法的查询结果动态优化算法ACOKS*.第4节展示大量实验结果,从而证明本文方法的良好性能.第5节讨论本研究领域的主要相关工作.最后,第6节总结并展望未来的研究方向.
1 问题描述关系数据库中的关键词查询的核心思想,就是从数据库中枚举简化子树.枚举简化子树的算法主要包括两类:基于数据图的方法和基于模式图的方法.由于本文采用基于数据图的方法,因此这里将描述采用这类方法如何解决关系数据库中的关键词查询问题.下面首先给出数据图[8]的定义.
定义1(数据图). 数据图G包含一个节点集合和一个边的集合.图G中存在两种类型的节点,即结构化节点和关键词节点.关键词节点只有入射边,而结构化节点既有入射边也有出射边.因此,一条边不可以连接两个关键词.图G中存在两种类型的边:一种是前向边(u,v),表示节点u和v之间存在主外键关联;一种是后向边(v,u),它与边(u,v)相对应,并且只有图中存在前向边(u,v)时才存在对应的后向边(v,u).一个数据图G的边可以具有权重,权重函数wG为每条边e分配一个正的权重wG(e).数据图G的权重用w(G)表示,就是图G中所有边的权重之和.一个数据图G是有根的,如果它包含某个节点r,并且从图G中的任何节点都可以通过一条有向路径到达节点r,这个节点r就被称为图G的根.
数据图的边具有方向性,可以反映不同方向上连接的强弱,因为两个节点之间的连接在不同方向上的连接强度不是对称的.比如在反映主外键关联的边中,外键到主键方向的边和其反方向的边是具有不同的重要性的.数据图中的节点和边都可以具有权重,这些权重都是预先被赋值的,从而可以更好地支持关键词查询.本文采用了BANKS[1]中的方法确定权重值.节点u的权重w(u)是一个关于节点u的入度的函数,边(u,v)的权重是根据边的类型来确定的,比如对于一个反映主外键关系的前向边(u,v),权重w(u,v)为1;而对于一个后向边(v,u)而言,其权重w(v,u)=w(u,v)xlog2(1+Din(v)),其中,Din(v)表示节点v的入度.
例1:如图 1所示,数据库中包含4个表,分别是Author,Paper,Citation和Paper-Author.其中:Author表记录了作者的标识(AID)和姓名(name);Paper表记录了论文的标识(PID)和标题(title);Paper-Author表记录了论文(PID)和作者(AID)之间的对应关系,PID和AID都是外键,分别引用了Paper表的PID属性和Author表的AID属性; Citation表记录了引用论文(cite)和被引用论文(cited)之间的对应关系,Cite和Cited也都是外键,都引用了Paper表的PID属性.
 | Fig. 1 An example of database图 1一个数据库实例 |
图 2显示了图 1中的数据库所对应的数据图,这里不包括边的方向和权重.
 | Fig. 2An example of data graph 图 2一个数据图的实例 |
目前,大多数基于数据图的方法[1, 4]都把简化子树枚举问题看成Steiner树问题,即从数据图中寻找包含了所有关键词的Steiner树.这里给出一个关于Steiner树的简单例子.假设有4个查询关键词k1=database,k2=XML, k3=Jim,k4=Steiner,我们使用这4个关键词在图 2的数据库中进行搜索,就可以得到如图 3所示的一棵可能的Steiner树,它包含了全部的4个关键词,从图 3中可以看出,树中每个节点所包含的关键词的具体情况.
 | Fig. 3An example of Steiner tree图 3Steiner树实例 |
在关系数据库中,关键词查询的一个最优结果,就是数据库对应的数据图中包含关键词的一棵最小Steiner树.最小Steiner树问题的任务如下:对于给定的顶点集合V,使用一个最短的路径把这些顶点连接起来,其中,路径的总长度是各条边的路径的长度之和.Steiner树问题和最小生成树问题看起来十分相似,但是二者有本质的不同,根本区别在于:在Steiner树问题中,为了减少生成树的路径总长度,可以在图中增加额外的顶点(不属于V)和边,这些不属于集合V的顶点,通常被称为Steiner点.下面给出最小Steiner树问题[4, 9]的形式化定义.
定义2(最小Steiner树). 给定一个图G(V,E)以及V¢ÍV,如果T是图G中的一棵连通子树,并且T包含了V¢
中的所有节点,那么我们就说T是图G中关于V¢的一棵Steiner树.假设用![]() 表示T的代价,其中,
E(T)表示树T中边的集合,w(e)表示边e的权重.如果在所有图G中关于V¢的Steiner树中c(T)最小,我们就说T是一棵最小Steiner树.
表示T的代价,其中,
E(T)表示树T中边的集合,w(e)表示边e的权重.如果在所有图G中关于V¢的Steiner树中c(T)最小,我们就说T是一棵最小Steiner树.
最小Steiner树的一种扩展形式是最小分组Steiner树,关键词查询问题也可以看成最小分组Steiner树问题.
定义3(最小分组Steiner树). 给定一个图G(V,E)和分组V1,V2,…,VnÍV,如果T是一棵最小Steiner树,并且T中包含了分组Vi(1≤i≤n)中至少一个节点,则称T是图G中关于这些给定分组的最小分组Steiner树.
下面我们来解释关键词查询问题为何可以看成是最小分组Steiner树问题.假定一个查询包含m个关键词k1,k2,…,km.为了回答这个查询,第一步工作就是定位与查询关键词匹配的节点,这个可以通过符号表技术或者数据库内嵌的全文索引功能来获得.对于查询中的每个关键词ki,都可以找到和ki相关的节点集合Si.一个查询的答案是一棵有根有向树,并且树中包含了来自每个Si的至少一个节点.很显然,这里的集合Si就对应定义3中的分组Vi,因此,关键词查询的最优结果就是一棵最小分组Steiner树.
最小分组Steiner树问题可以给出代价最小(与用户给定的关键词集合K相关性最大)的简化子树,当需要返回top-k个代价最小的简化子树时,这个问题被称为top-k分组Steiner树问题,具体定义如下:
定义4(top-k分组Steiner树问题). 给定一个关键词查询k1,…,km,为该查询寻找top-k个代价最小的分组Steiner树T1,T2,…,Tk,这些树之间根据代价函数c进行排序,并且有c(T1)≤c(T2)≤…≤c(Tk).
2 用蚁群优化算法求解关键词查询问题本节内容将首先介绍蚁群优化算法的基本原理,然后介绍如何用蚁群优化算法求解关键词查询问题,并详细阐述基本算法以及其中所涉及的蚂蚁的移动规则、信息素的更新等问题,最后给出了算法的空间代价分析.需要指出的是,本文采用了与BANKS一样的评分方法,因此这里不再介绍评分方法.
2.1 蚁群优化算法的基本原理蚁群算法[10]是意大利学者Dorigo等人于20世纪90年代提出来的,是一种模仿自然界蚂蚁搜索食物行为的启发式智能进化算法,可以用来在图中寻找优化路径.自然界中的蚂蚁在寻找食物的时候,事先没有任何关于食物位置的信息,每只蚂蚁在开始寻找食物的过程中,对路径的选择会表现出随机的行为.一旦一只蚂蚁找到食物以后,它就会向环境中释放信息素,其他蚂蚁遇到信息素以后,就会沿着信息素指引的方向寻找食物,最终会有越来越多的蚂蚁找到食物.由于不同蚂蚁会发现不同的食物寻找路径,并且会分别释放出信息素,信息素的浓度与路径长度相关,路径越短,信息素浓度越大.蚂蚁在前进时,会优先选择信息素浓度大的方向移动.因此经过一段时间以后,就可能会出现一条最短路径被大多数蚂蚁重复着.所以总的来说,单只蚂蚁的行为都非常简单,但是不同蚂蚁之间通过信息素进行沟通合作,却可以快速发现全局最优解.
蚁群优化算法最初主要用于解决旅行商问题(traveling salesman problem,简称TSP),并且取得了很好的效果.此后,经过研究人员的努力,产生了大量的研究成果[11],蚂蚁算法也进一步发展成为通用的优化技术,即蚁群优化(ant colony optimization,简称ACO)算法,适合解决传统搜索算法难以解决的一些复杂问题.蚁群优化算法具有正反馈性,个体蚂蚁通过信息素把路径信息传递给环境,而周围环境反过来又通过信息素指导蚂蚁进行最优的路径选择.这个性质意味着,问题的解越优,通过调整相关参数值,就可以增强它被找到的概率.蚁群算法的另一个特性是适合于分布式环境.
2.2 用蚁群优化算法求解关键词查询问题关系数据库中的关键词查询问题,可以转化为Steiner树问题.已有的研究证明,Steiner树问题是一个NP-hard问题[1],因此,已有的研究通常都采用启发方法来减少搜索空间.研究人员通过大量实验发现,蚁群算法对大量的NP-complete和NP-hard问题进行求解都表现出了高效性.因此,本文引入蚁群优化算法求解关键词查询问题,核心思想就是利用蚁群算法求解Steiner树问题.目前已经有一些利用蚁群优化算法求解Steiner树问题的研究[12-14],不同研究采用的策略也不尽相同,但是这些研究都只是针对Steiner树这个理论问题本身或者其他应用场景进行探讨,并没有考虑关系数据库中的关键词查询这个具体应用环境,因而,直接把这些方法应用到本文的研究问题上将无法取得好的效果.比如:文献[12]研究的问题有一个确定的目标点作为蚂蚁前进的目的地,而在本文中则无法给定一个明确的蚂蚁前进目标点;文献[14]研究的图只能严格包含水平和竖直两个方向上的边,与本文研究的数据图有很大的区别;文献[13]需要首先采用特定分区方法对图进行分区,然后采用蚁群优化算法寻找最优路径,最后对不同分区的结果进行合并,这种方法无法在本文的关键词查询问题中使用.
2.3 用蚁群优化算法求解关键词查询问题的基本算法用蚁群算法求解关系数据库中的关键词查询问题的基本思路是,通过多只蚂蚁的不断沟通与合作,找到包含了所有关键词的Steiner树.如果要给出关键词查询的最优答案,就找出一颗最小Steiner树;如果是top-k关键词查询,就找出代价最小的前k棵Steiner树.蚂蚁求解Steiner树的过程,采用常见的覆盖清除法(spanning and cleanup),即从分组vi中的任意一个节点出发,一步步向周围扩展,直到覆盖了每个分组vi中的至少一个节点,最后清除结果中多余的节点.
具体来说,假定一个查询K包含m个关键词k1,k2,…,km,可以通过倒排索引找到数据图G中和每个关键词ki相关的节点集合Si,Si中的节点包含了关键词ki.在每次迭代时,从每个Si中都随机选取一个节点,并为每个节点放置p只蚂蚁,所有蚂蚁构成集合S_ant.每只蚂蚁放出后,会根据转移概率在数据图中寻找前进的路径.这里为每只蚂蚁设置一个集合变量S_visited,里面存放这个蚂蚁已经访问过的节点,为了避免产生回路,蚂蚁不会再次访问S_visited中的节点;同时,也为每只蚂蚁设置了集合变量S_spanned,表示这个蚂蚁爬过的节点已经包含的查询关键词.蚂蚁a前进一步以后,就把新到达的节点v加入到已访问节点集合S_visited中,这样,蚂蚁a对应的树又增加了一个树枝.如果蚂蚁a到达的点v,发现节点v的属性ant_visited不为空,例如,ant_visited记录了蚂蚁b的信息,说明节点v已经被蚂蚁b访问过,则销毁蚂蚁a,并把蚂蚁a的S_visited的所有元素都加入到蚂蚁b的S_visited中,同时把蚂蚁a的覆盖集合S_spanned加入到蚂蚁b的覆盖集合S_spanned.如果蚂蚁b的覆盖集合S_spanned已经包含了所有查询关键词,就说明找到一个结果,那么就输出包含蚂蚁b的S_visited中元素的Steiner树s_tree,并把s_tree放入结果堆resultHeap中.如果resultHeap中已经有k棵Steiner树,则把当前的s_tree和resultHeap中的其他树进行比较,丢弃代价最大的树,然后销毁蚂蚁b.蚂蚁自身有个属性stepNum,在前进的过程中会记录自己已经走过的步数,当stepNum值超过门槛值maxStepNum时,查询的结果就没有意义.因此,蚂蚁就不用继续搜索,被销毁.随着蚂蚁的销毁,蚂蚁数量会逐渐减少,最终当蚂蚁数量为0时,就停止本次迭代,开始下一次迭代.当迭代次数达到允许的最大值maxIterlationTime时,就停止程序执行,输出堆resultHeap中的查询结果.
算法1. ACOKS算法.
Input: 1. 数据图G,倒排索引I,迭代次数最大值maxIterlationTime,蚂蚁最大前进步数maxStepNum;
2. 查询关键词集合K={k1,k2,…,km};
Output: 1. 前k个最好的查询结果.
Begin
对于所有iÎ[1,m],使用倒排索引I查找与关键词ki相关的节点集合Si;
iteration_time¬0; //初始化迭代次数
初始化信息素矩阵M;
t=0; //记录当前时刻
while (iteration_time<maxIterlationTime) do
从每个Si中分别随机选取一个节点,并为每个节点放置p只蚂蚁,所有蚂蚁构成集合S_ant;
ant_num¬m*p; //求出系统中所有蚂蚁的数量
把数据图G中的所有节点的属性ant_visited初始化为NULL;
//ant_visited表示已经访问过该节点的蚂蚁
for each antÎS_ant do
stepNum¬0; //初始化为0,属性stepNum表示蚂蚁爬过的步数;
S_visited(ant)¬Æ; //表示蚂蚁ant已经访问的节点集合
S_spanned(ant)¬{ki}; //表示蚂蚁ant爬过的节点已经包含的查询关键词集合
endfor
while (ant_num>0) do
for each antÎS_ant do //每只蚂蚁都独立并行执行
if (ant.stepNum>maxStepNum) then //经过maxStepNum步,再往前走即使得到结果意义不大
销毁蚂蚁ant;
对于S_visited(ant)中所有节点的属性ant_visited,删除ant的信息;
else
ant.stepNum¬ant.stepNum+1; //蚂蚁往前走一步
t¬t+1; //当蚂蚁往前走一步,更新时刻t
ant根据t-1时刻的转移概率确定即将移动到的下一个节点v,并且使得vÏS_visited(ant);
if (v.ant_visited=NULL) then //该节点v未被其他蚂蚁访问过
S_visited (ant)¬S_visited (ant)Èv;
v.ant_visited¬ant;
else
S_visited(ant_visited)¬S_visited(ant_visited)ÈS_visited(ant);
S_spanned(ant_visited)¬S_spanned(ant_visited)ÈS_spanned(ant);
销毁蚂蚁ant;
if (S_spanned(ant_visited)=K) then //蚂蚁爬过的节点已经包含了所有查询关键词
对于S_visited(ant_visited)中所有节点的属性ant_visited为NULL;
输出由S_visited(ant_visited)中所有节点构成的Steiner树s_tree; //删除多余节点
计算s_tree的评分score(s_tree);
if (score(s_tree)>score(s_tree_min)) then //s_tree_min表示堆resultHeap中评分最小的树
从堆resultHeap中删除s_tree_min,并把s_tree加入堆resultHeap中;
else
丢弃s_tree;
endif
销毁蚂蚁ant_visited;
endif
endif
更新t时刻的信息素矩阵M;
endif
endfor
endwhile
iteration_time¬iteration_time+1;
endwhile
输出堆resultHeap中的结果;
end
2.4 蚂蚁的移动规则当算法ACOKS每次迭代执行开始时,t=0.此后,每当t增加1,每只蚂蚁都同时往前移动1步,即同时从一个节点移动到下一个节点.由于每只蚂蚁的最大允许移动步数是maxStepNum,因此,算法每次迭代最终都会在t=maxStepNum时刻停止.
在t时刻,当一只蚂蚁ant从一个节点u移动到下一个节点v时,为了避免产生回路,首先要保证下一个节点vÏS_visited(ant),其中,vÏS_visited(ant)表示ant已经访问过的节点集合.然后,蚂蚁从节点u的所有满足上述禁忌条件的相邻节点中选择一个转移概率最大节点v作为下一个访问目标.蚂蚁从节点u爬向节点v的概率计算方法如公式(1)所示:
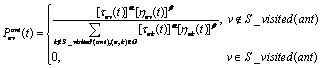 (1)
(1)
其中,tuv(t)表示在t时刻节点u和v之间的信息素浓度;a是信息启发式因子,表示轨迹的相对重要性;huv(t)表示t时刻节点u和v之间的能见度,huv(t)=1/duv,duv表示节点u到v的代价;b是期望启发式因子,表示能见度的相对重要性.
2.5 信息素的更新在每次迭代开始后,每条边上的信息素就随着时间的流逝逐步挥发,浓度逐渐降低.因此,蚂蚁每向前移动一步,就需要更新一次信息素矩阵M.每次更新时,要考虑两个方面的内容:第一,每条边上的信息素会随着时间挥发;第二,对于有助于找到结果的路径,要增强它们的信息素浓度.
假设蚂蚁a包含关键词ka,已经走过的节点构成的树为Ta;蚂蚁b包含关键词kb,已经走过的节点构成的树为Tb,蚂蚁a即将到达的下一个节点v已经被蚂蚁b访问过.对于这种情形,算法ACOKS就会把Ta合并到Tb中,得到新的树T=TaÈTb.T中包含了查询关键词ka和kb,很显然,这对于找到最终结果是有很大的帮助的.如果一个查询包含3个关键词ka,kb和kc,那么从T上的节点出发,只要再找到包含kc的树Tc即可(Tc由另一只蚂蚁c负责构造).因此,每当出现两个蚂蚁构造的树存在交集的情形时,就应该为合并得到的新树T中的所有边增强信息素的浓度.信息素的计算公式见公式(2)、公式(3).
![]() (2)
(2)
![]() (3)
(3)
其中,rÎ(0,1),表示信息素的挥发程度;Dtuv(t)表示信息素的增加量.
两棵树之间的合并会发生多次,每次合并都会对树中的边的信息素进行增强操作,这里假设一共发生了m次合并,在第i次合并中(iÎ[1,m]),需要对合并得到的结果树Ti中的边(u,v)增加信息素,这个信息素的增加量在公式(3)中用![]() 表示,其计算方法见公式(4).
表示,其计算方法见公式(4).
![]() (4)
(4)
其中,|Ti|表示树Ti的边的代价之和.
这里需要指出的是,每次合并得到的不同的结果树,其优劣程度是不同的.假设第i次合并得到的结果树为Ti,它的评分为Score(Ti),第j次合并得到的结果树为Tj,它的评分为Score(Tj),如果有Score(Ti)>Score(Tj),很显然, Ti要优于Tj.为了让后来的蚂蚁更多地靠近Ti中的节点,应该让Ti中的节点比Tj中的节点获得更大的信息素增量,即给Ti一个额外的奖励s.
本文确定的奖励方法是:假设在一次迭代结束后,堆resultHeap中包含了k棵Steiner树T1,T2,…,Tk,那么对于所有(u,v)ÎTi(1≤i≤k),都执行公式(5):
tuv(t+1)=tuv(t)+s (5)
2.6 空间代价分析在理论上,蚁群算法需要为所有查询关键词对存储信息素矩阵,空间复杂度是O(m2n2),其中,m为数据库中所有关键词总数,n为数据图中节点的个数.然而实际上,蚁群算法并不需要维护如此大的信息素矩阵空间.这是因为:首先,并不是任何两两关键词之间都存在联系;其次,因为评分过低的结果树并没有太大意义,所以也不需要维护距离关键词太远的节点;最后,由于大部分路径都不会有蚂蚁经过,因此这些路径的信息素是相同的,所以可以采用一个值代替.为了说明实际空间消耗要远远小于理论情况,我们在DBLP数据集上进行了实验分析,数据图的节点数是n=7270404.理论上,一个关键词查询的信息素矩阵的大小为72704042个矩阵元素,但是实际上,算法在运行过程中生成的信息素矩阵只有90 735个矩阵元素,即压缩率达到了1.71x10-9.
3 基于概念漂移的查询结果动态优化本文前面提出,采用基于蚁群优化算法的ACOKS算法来解决关键词查询问题可以取得很好的性能,但是ACOKS算法却无法解决查询结果的动态优化问题.因此,在前面ACOKS算法的基础上,本文进一步提出结合概念漂移理论的优化算法ACOKS*,实现查询结果的动态优化,提高查询结果的有效性.下面首先介绍已有研究在查询结果有效性方面的不足,然后介绍基于概念漂移的查询结果优化的核心思想.
3.1 已有研究在查询结果有效性方面的不足在日常应用中,用户的查询兴趣是不断发生变化的.用户查询兴趣的变化可以包括缓慢变化的兴趣和快速变化(突变)的兴趣.本文重点研究如何针对突变的用户兴趣对查询结果进行动态优化,提高查询结果的有效性.
用户查询的兴趣有时候会发生突然变化,比如发生了突发事件,会迅速转移大量用户的查询兴趣.针对这种突变的用户兴趣,不能使用基于长期的概率统计来衡量.比如,用户的查询兴趣突然从A转到B,即在查询结果中突然更多选择B而很少选择A,导致B的访问量急剧增加.但是由于历史上有很多用户曾经访问过A,使得A的绝对访问次数远远高于B.因此,如果采用基于长期概率统计的方法,那么蚁群优化算法仍然会选择A而不是B.因此,必须研究一种可以有效衡量用户查询兴趣突变的方法,并设计相应的查询结果动态优化算法,让蚁群优化算法选择B而不是A.已有的方法没有关于这个方面的研究.
3.2 基于概念漂移的查询结果动态优化的核心思想概念漂移(concept drift)是机器学习领域研究的重要问题之一.概念漂移是指数据的分布随着时间而发生变化,这些变化就使得在旧数据上建立的模型不再能适用于新的数据特性,因而需要对模型进行更新调整.目前,概念漂移理论的研究成果已经应用到许多领域中,比如在大型零售公司里,可以使用概念漂移理论对顾客的购买行为进行分析,及时发现顾客购买行为的变化,采取应对措施.用户查询兴趣变化的过程,相当于一个“概念漂移”过程.由此,我们引入机器学习领域的概念漂移方面的已有研究成果来探测用户查询兴趣的变化.
基于概念漂移的查询结果动态优化方法的核心思想是,利用概念漂移理论及时发现用户兴趣的突变,并据此动态优化查询结果,使其更加符合用户查询预期.具体而言,首先,利用概念漂移理论确定用户的兴趣节点集(由用户有兴趣访问的查询结果树中的节点构成的集合);然后,只需要对ACOKS算法做简单改进即可得到新的ACOKS*算法.即,引导蚂蚁在移动过程中以较大的概率向兴趣节点集中的节点移动,以较小的概率向非兴趣节点集中的节点移动,从而使得查询结果当中出现更多的兴趣节点集中的内容,更加符合用户兴趣.
3.3 动态优化过程图 4显示了基于概念漂移的查询结果动态优化过程.
 | Fig. 4Process of search result dynamic optimization图 4查询结果动态优化过程示意图 |
我们采用用户兴趣节点集来反映用户的查询兴趣,具体而言,当把多个查询结果呈现给用户时,每个查询结果是一棵由多个元组连接得到的元组树,即Steiner树,树中的节点包含了查询关键词;当用户点击访问某个查询结果时,就表明该用户对这个结果感兴趣,因此,就可以把这个查询结果对应的元组树的所有节点都放入用户兴趣节点集I.我们设计的系统界面包含了两个子窗口:左窗口和右窗口,前者包含了系统采用ACOKS算法得到的初步查询结果,后者包含了采用ACOKS*算法得到的动态优化查询结果.系统设置了一个样本窗口,可以记录一定数量的历史用户兴趣节点集,在样本数据基础上,可以训练得到分类模型,从而预测用户未来的查询兴趣.假设样本窗口内包含了n个用户兴趣节点集I1,I2,…,In,根据上述兴趣节点集中的样本节点,可以对分类模型进行训练,得到一个分类器.假设新到达的用户为Un+1,提交查询后,系统采用ACOKS算法得到初步查询结果(包含多条记录),这些结果在左窗口中显示,因此被称为左结果.系统将等待用户开始第1次点击查看自己感兴趣的一个结果.在用户第1次点击发生后,系统将新弹出一个窗口,并在新窗口中显示被点击的这条查询结果(即一棵包含查询关键词的Steiner树),同时,系统立即可以确定用户当前点击的访问节点集FCS(first click set),即该Steiner树中包含的节点的集合.系统把FCS作为分类器的输入,判定FCS的分类标记,然后,系统根据该分类标记预测该用户的兴趣节点集PS(predicting set),再以PS为输入,调用ACOKS*算法,生成优化的查询结果,这些优化的结果将显示在右窗口中,因此被称为右结果.用户将根据右窗口的结果,选择自己感兴趣的结果进行点击访问.需要指出的是,如果右窗口的推荐优化结果都不是用户感兴趣的,用户将全部都不点击,而是继续在左窗口中寻找自己感兴趣的结果.当用户发生后续的多次点击后,系统会跟踪记录这些点击所生成的访问节点集MCS(more click set),它可以真实记录用户的访问兴趣.概念漂移探测器会对MCS和PS两个集合进行重合度计算,当MCS和PS重合度较大时,说明预测准确;当二者重合度较小时,用户系统根据历史样本预测,已经发生了较大的错误,用户查询兴趣发生了较大的变化(即发生了概念漂移),这时就需要根据新的样本对分类器的分类模型进行重新训练.
3.4 分类器的构建用户查询提交给系统以后,系统会返回很多结果,每个查询结果都是一棵Steiner树,用户只访问其中感兴趣的一部分结果,这部分结果当中包含的所有节点,就构成了用户兴趣节点集合.针对每次用户查询,系统会自动跟踪记录兴趣节点集的内容,从而为分类器的构建提供样本数据.
假设当前样本窗口内包含了用户针对某个查询K={k1,k2,…,km}的n次查询所对应的兴趣节点集I1,I2,…,In,这里令I=I1ÈI2È…ÈIn.为了建立分类器所需要的类标记,我们首先使用基于距离的聚类算法对集合I中的节点进行聚类,从而得到关于集合I的多个类标记C1,C2,…,Cy.然后,就可以采用基于距离的分类算法把集合FCS作为分类器的输入(如图 4所示),确定集合FCS中的每个节点的类标记,从而为计算集合PS提供依据.这里,用函数C=Classifier(u)表示一个分类器,即输入一个节点u,输出u对应的分类标记C.在不产生歧义的前提下,本文以后的内容中,将把类标记C同时用来表示一个类集合,即由类标记为C的所有节点构成的集合.
3.5 预测节点集的生成
预测节点集PS是根据集合FCS来确定的.集合FCS中包含了用户在“左窗口”中进行第1次点击以后所访问的所有节点,它可以大致反映用户的当前查询兴趣.根据FCS生成PS,需要首先确定预测目标类Cp,再根据预测目标类Cp确定预测目标类延伸节点集![]() ,最终,预测目标类Cp中的节点和其延伸节点集
,最终,预测目标类Cp中的节点和其延伸节点集![]() 中的节点,共同构成预测节点集,即
中的节点,共同构成预测节点集,即![]() .
.
定义5(预测目标类). 对于查询K={k1,k2,…,km},假设前n次查询所对应的兴趣节点集I1,I2,…,In,令I=I1È I2È…ÈIn.根据I构建分类器后,得到的分类标记为C1,C2,…,Cy.对于第n+1次用户查询,已知它的第1次点击节点集是FCS={f1,f2,…,fi},FCS中的每个节点所属的分类标记为Classifier(fi).这里,为每个分类C1,C2,…,Cj设置一个计数器counter,当fi属于某个分类Ct时,Ct.counter增加1.预测目标类Cp是满足如下条件的类:
Cp.counter=MAXiÎ(1,j)(Ci.counter).
定义6(预测目标类延伸节点集). 假设有一个数据图G,预测目标类Cp(ÎG),两个节点u和v,其中,uÎG且uÏCp,vÎCp.如果在节点u和v之间存在一条长度不大于c的路径u«v,就称路径上的所有节点构成的集合为预测目标类覆盖节点集,记为![]() .预测节点集PS定义为集合
.预测节点集PS定义为集合![]() .
.
这里给出一个实例介绍预测节点集PS的确定方法.如图 5所示,有一个数据图G(用虚线空心圆圈表示G中的若干节点)和集合I(图中用实线曲线表示集合边界,用s表示集合中的节点),I被分成3个分类:CA,CB,CC(图中用虚线曲线表示类的边界).用户第1次点击节点集FCS={f1,f2,f3,f4,f5,f6}(图中用黑色实心圆圈表示),并且有:
Classifier(f1)=CA,Classifier(f2)=CA,Classifier(f3)=CB,
Classifier(f4)=CB,Classifier(f5)=CB,Classifier(f6)=CB.
因此,CA.counter=2,CB.counter=4,CC.counter=0.可以看出,CB.counter最大,因此,CB被判定作为预测目标类Cp.如果c取值为3,则预测目标类延伸节点集就是图中用t标记(图中用黑色实线空心圆圈表示)的节点,这些节点可以从CB类中的节点出发到达,并且路径长度不大于3.最终,预测节点集的内容就是类CB中的节点和延伸节点集中的节点的并集.
 | Fig. 5Identification method of predicting node set图 5预测节点集的确定方法 |
ACOKS*算法和ACOKS算法在很大程度上是相同的,因此这里不再给出ACOKS*算法伪代码.二者的区别在于,ACOKS*算法需要解决两个额外的问题:
· 增加节点能见度:在ACOKS*算法中,对数据图的各个节点进行能见度计算时(见公式(1)),对于那些满足条件vÎPS的所有节点v,增加其他节点到节点v的能见度,让蚂蚁以更大的概率爬向集合PS中的节点,从而使得结果树中包含了更多的PS中的节点,更加符合用户的兴趣.根据传统的方法,huv(t)=1/duv, duv表示节点u到v的代价.经过优化以后,从节点u到节点v的能见度计算方法见公式(6):
![]() (6)
(6)
其中,w>0,表示能见度增强系数.调整后的能见度![]() 就会比原来的能见度huv(t)大,这样,当节点vÎPS时,蚂蚁就会以更大的概率向节点v移动;
就会比原来的能见度huv(t)大,这样,当节点vÎPS时,蚂蚁就会以更大的概率向节点v移动;
· 增加节点评分:对一棵结果树进行评分时,对于结果树中那些满足条件vÎPS的所有节点v,增加节点v的节点分值,即让Nscore(v)*=(1+j)Nscore(v),从而使得包含节点v的结果树具有更高的评分,排序尽量靠前,显示给用户.
正是因为ACOKS*算法解决了上述两个方面的问题,它得到的查询结果中就可以比ACOKS算法包含更多的来自集合PS的节点,从而更好地符合用户的查询兴趣.
3.7 概念漂移的判定概念漂移探测器对MCS和PS两个集合进行重合度计算,当二者重合度较小或者没有重合时,就说明发生了概念漂移.图 6描绘了在两种情形下的两个集合之间的关系.
 | Fig. 6Identification of concept drift图 6概念漂移的判定 |
但是我们通过大量实验发现,在少数情况下,由于分类模型误差的存在,会导致根据FCS(第1次点击节点集)生成的PS(预测节点集)存在一定的误差,这个时候,虽然PS和MCS具有一定的重合度,但是实际上已经发生了概念偏移.为了最大程度减少这种误判,我们引入了另一个指标,即集合距离.当两个集合距离大于一定程度时,就可以更加确定已经发生了概念漂移.不过,计算机集合距离需要一定的代价,因此在PS和MCS具有较大重合度时,本文没有采用集合距离,只有当PS和MCS重合度低于预设门槛值时才引入集合距离的计算,增加概念漂移判定的准确性.
对于两个兴趣结点集![]() ={a1,a2,…,am}和
={a1,a2,…,am}和![]() ={b1,b2,…,bn},则
={b1,b2,…,bn},则![]() 和
和![]() 的集合距离
的集合距离![]() 定义如下:
定义如下:
![]() (7)
(7)
其中,Cost(ai,bj)表示由在数据图中从节点bj到ai的代价,如果ai=bj,则Cost(ai,bj)=0;如果无法从bj到ai,则Cost(ai,bj)=¥.MIN(×)函数返回代价的最小值.
最朴素的方式是,对于一个指定的查询K,假设当前时间窗口内包含的兴趣节点集合是Scur,新到达的查询对应的兴趣结点集是Snew.如果D(Scur,Snew)≥e(e是一个阈值),那么我们就说用户查询行为发生了变化.
图 7展示了一个概念漂移的实例,这里以此为例来解释公式(7)的计算方法.假设在图 7中的数据图上发起查询K={k1,k2},其中,k1=“Wang”,k2=“XML”,节点a1包含了关键词k1=“Wang”,节点t1,t2和t6包含了关键词k2=“XML”,并假设所有边的权重都是1.先后有3个用户发起相同的查询,但是在查询结果中,不同用户的兴趣节点集是不同的.用户U1的兴趣节点集![]() ={a1,w1,t1},用户U2的兴趣节点集
={a1,w1,t1},用户U2的兴趣节点集![]() ={a1,w2,t2},用户U3的兴趣节点集
={a1,w2,t2},用户U3的兴趣节点集![]() ={a1,w4,t5,c4,t6},这里使用公式(7)分别计算不同兴趣节点集之间的距离:
={a1,w4,t5,c4,t6},这里使用公式(7)分别计算不同兴趣节点集之间的距离:
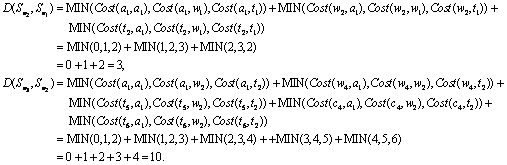
 | Fig. 7An example of concept drift图 7一个概念漂移的实例 |
如果假设e=5,![]() ,则可以认为U2和U1的查询兴趣大致相同;而
,则可以认为U2和U1的查询兴趣大致相同;而![]() ,则可以认为U3和U2的查询兴趣发生了突变,即二者之间存在概念漂移.
,则可以认为U3和U2的查询兴趣发生了突变,即二者之间存在概念漂移.
本文实验全部基于我们开发的原型系统,底层采用ORACLE11g数据库,用JAVA语言编写,并以网页的形式提供对外服务.当前运行的环境是:英特尔i7-2600处理器(3.40GHz),16GB内存,1TB硬盘和Windows Server2003操作系统.
图 8显示了我们设计实现的原型系统的架构.使用RDBMS管理测试数据集,通过调用RDBMS的ODBC接口访问底层的数据集,并转换得到数据图供概念漂移检测算法和ACOKS*算法使用.原型系统提供了用户界面,界面包含左窗口和右窗口,用户输入查询关键词以后,系统在左窗口显示初步结果,并根据用户对左窗口结果的访问情况捕捉用户查询兴趣,在右窗口生成优化后的结果.
 | Fig. 8Prototype system architecture图 8原型系统架构 |
我们从网络上下载了DBLP(http://dblp.uni-trier.de/xml/)数据库,这是目前大多数研究都采用的实验数据库.DBLP数据库以XML文件的形式一共包含了860MB的数据,通过我们自己编写的数据库加载工具把XML文件导入到ORACLE中,建立一个DBLP关系数据库,生成的数据库中的各个表及其所包含的元组数量请见表 1.原型系统从ORACLE中访问DBLP数据库,生成相应的数据图,存放到内存中,一共包含了7 270 404个节点和9 047 382条边.生成数据图过程耗时89s.原型系统会从DBLP数据库中自动解析并抽取其中包含的词汇信息,经过解析,一共获得534 124个词汇,然后,基于这些词汇构建倒排索引,该过程耗时105s.实验将对本文算法和BANKS,BLINKS进行各种性能指标的比较,从而证明本文算法的高效性和有效性,同时具有比其他方法更好的性能.
| Table 1 Test data set 表1 测试数据集 |
这里选取大量关键词查询对ACOKS*算法性能进行测试,这些查询包含的关键词数量分布在2~5之间.从实验结果来看,ACOKS*算法在不同的关键词查询上均表现出了很好的收敛性.这里首先展示其中的两个查询的算法收敛曲线,其他查询都表现出了类似的特性.选取的2个关键词查询分别为K1={zhang,ullman}, K2={alfred,zhang,ullman}.表 2给出了ACOKS*算法的参数设置,参考了已有蚁群算法中对各个参数的经验取值.图 9显示了ACOKS*算法在处理这两个关键词查询时生成的最优Steiner树的评分(采用和BANKS的评分方法)和迭代次数的关系,可以看出,ACOKS*算法可以取得很快收敛,最快时只需要经过5次迭代就可以达到收敛,找到全局最优解.另外,从图 9中也可以看出,当ACOKS*算法找到全局最优解以后,在少数情况下,还可能跳出最优解,然后再回归到最优解,这也恰好反映了蚁群优化算法的特性.因为蚁群优化算法中的蚂蚁在前进路径的选择上,是一种基于概率的选择,在找到全局最优路径以后,大部分蚂蚁都会以较大的概率沿着全局最优路径前进,但是仍然会有少量蚂蚁以较小的概率选择其他路径.实际上,这也是蚁群优化算法的创新机制,可以保证算法在外部环境发生变化后(比如数据图发生了更新),可以寻找到新的最优解.
| Table 2 Parameter setting of ACOKS* 表2 ACOKS*算法的参数设置 |
 | Fig. 9Convergence curve of the ACOKS* algorithm图 9ACOKS*算法的收敛曲线 |
算法的效率(查询响应时间)是最小Steiner树求解算法的重要性能指标,由于Steiner树问题是一个NP-hard问题,即使采用启发式算法,通常也具有很高的代价.虽然本文的研究重点不是提高查询算法的效率,但是我们通过实验发现,在数据图不发生变化的情况下,结合了蚁群优化和概念漂移理论的ACOKS*算法确实可以比已有的其他方法取得更好的查询效率,这主要得益于蚁群优化算法具有保留信息素的功能.需要指出的是,本文中查找速度的提升,并没有牺牲查询准确度,这种速度的提升只是信息素累积的自然结果.为了比较不同算法的性能,我们设计了50个查询,每个查询所包含的关键词数量l分布在2个~6个之间.实验对ACOKS*算法进行性能测试,在分别计算出每个查询的响应时间以后,再对这些响应时间求平均值作为评测指标.图 10显示了不同算法的查询响应时间比较.从中可以看出,ACOKS*算法在不同关键词数量下,性能都要优于BANKS和BLINKS算法.对于关键词数量为2的查询,BANKS算法平均响应时间超过6000ms,BLINKS算法平均响应时间超过3000ms,而ACOKS*算法只需要450ms,具有明显的性能优势.同时也可以看出,ACOKS*算法具有很好的可扩展性.当关键词的数量从2增加到6时,ACOKS*算法的平均响应时间并没有大幅度明显增加,在关键词数量为6时,ACOKS*算法的平均响应时间也只有1170ms,而此时,BANKS和BLINKS算法分别达到了8000ms和5500ms.图 11是l=2时,top-k查询的效率对比情况.可以看出ACOKS*算法相对于BANKS和BLINKS算法的明显性能优势.ACOKS*算法能够取得上述性能优势的原因是,该算法具有很好的并发性,多只蚂蚁可以在数据图中并行执行图的遍历.
 | Fig. 10Search response time图 10查询响应时间 |
 | Fig. 11Top-k search response time图 11Top-k查询响应时间 |
查询结果的有效性评测指标是准确率.为了进行对比,这里设计两种情形:在第1种情形中,用户查询兴趣不发生变化;在第2种情形中,用户查询兴趣不断变化,并且包含多个兴趣突变.为了生成第2种情形中不断变化的用户查询兴趣,我们首先编写JAVA程序,使用网络上的开源代码lucene,解析出数据集中包含的所有词汇,然后编写程序,从所有词汇中随机抽取若干词汇作为查询关键词构成若干个查询.对于每个查询,使用程序去完成搜索,如果不存在搜索结果,或者搜索结果少于3个,就舍弃这个查询,因为查询结果太少,用户选择结果的余地也小,无法充分反映用户的不同查询兴趣.对于包含3个以上结果的查询而言,我们设计一个连续的查询序列,使之能够反映用户兴趣的变化,并通过程序事先设置了用户感兴趣的结果,从而帮助确定算法查询结果的有效性.这里把查询关键词的数量l从2变化到6,对于某个特定的l值,我们查询得到top-100结果,确定top-100结果中正确结果的个数,并用正确的个数除以总数100,计算得到查询结果的准确率.图 12显示了在第1种情形下,不同关键词数量时查询的准确率.图 13显示了在第1种情形下,当l=2时,top-k查询的准确率.从中可以看出,在查询结果的有效性方面,ACOKS*明显比BANKS和BLINKS具有更高的准确性.这是因为BANKS算法和BLINKS都是采用固定的评分机制来反映用户的查询兴趣,不能真实反映用户的查询兴趣;而ACOKS*则是根据用户真实的近期访问数据判断用户的查询兴趣,可以取得更好的效果.图 14和图 15分别显示了在第2种情形下,不同关键词数量时查询的准确率和当l=2时top-k查询的准确率.可以看出,当用户兴趣存在突变时, ACOKS*,BANKS和BLINKS算法的准确性都下降了一些,但是ACOKS*下降幅度最小,BLINKS下降幅度最大.这是因为ACOKS*算法采用的用户兴趣探查方法,可以及时有效探查到用户兴趣的突变,并生成相应的兴趣节点集,从而使得查询结果更好地符合用户预期.
 | Fig. 12Search accuracy for various keyword number without interest mutation图 12没有兴趣突变时,不同关键词数量时查询的准确率 |
 | Fig. 13Search accuracy for top-k search without interest mutation, l=2图 13没有兴趣突变且当l=2时,top-k查询的准确率 |
 | Fig. 14Search accuracy for various keyword number ,with interest mutation图 14存在兴趣突变时,不同关键词数量时查询的准确率 |
 | Fig. 15Search accuracy for top-k search,with interest mutation, l=2图 15存在兴趣突变且当l=2时,top-k查询的准确率 |
基于关键词的关系数据库查询是近年来的研究热点.DBExplorer[5],DISCOVER[6],BANKS[1]是最早一批具有代表性的研究工作,此后,不断有新的成果诞生,其中很多成果都发表在VLDB,SIGMOD,ICDE等学术会议和期刊(比如TODS)上,比如文献[2-4,15-18].我们在文献[19]详细阐述了该领域的研究问题,并详细介绍了各种方法的原理以及各自的优缺点.
已有的研究方法可以分成两大类,即基于数据图的方法和基于模式图的方法.许多研究[1-4,8]都采用基于数据图的方法来生成简化子树,即直接对数据图进行处理,从中枚举简化子树.BANKS系统使用了一种图搜索算法,即反向扩展搜索(backward expanding search)算法,直接对数据图进行搜索.但是,当一个查询关键词匹配非常大量的节点时,或者当算法遭遇一个入度非常大的节点时,反向扩展算法的性能就会非常糟糕.为此, BANKS-II[2]提出了一种新的搜索方法——双向搜索,它允许从可能的根节点出发朝着叶子节点进行前向搜索,从而改进了后向搜索的性能.BLINKS[20]采用了一个基于代价均衡扩展(cost-balanced expansion)的反向搜索策略,并且使用了额外的双层索引来加快搜索速度.双层索引明显减少了运行最优反向搜索算法的开销,并且可以支持前向搜索,从而有效地实现类似BANKS-II中的双向搜索.与BANKS-II双向搜索方法相比,BLINKS在搜索过程当中可以实现更大的前向跳跃,加快了搜索速度.文献[8]描述了一个关于结构化数据的关键词查询的形式化框架,该形式化框架明确定义了枚举简化子树问题的3个变种,其中,有一个变种用来处理有向简化子树,另外两个变种用来处理无向简化子树.作者发现了简化子树的枚举和Steiner树优化问题这二者之间存在的复杂关系.文献[21]提出的枚举算法则可以采用任意顺序进行枚举,而且作者把枚举问题分解成几个小的子问题,从而可以提前对每个子问题进行测试,判断它的结果是否非空.最后,对子问题的结果进行组合就可以得到原问题的答案.文献[9, 22]提出了一种动态编程方法,它可以近似给出top-k个元组连接树.文献[3]提出了“r-半径Steiner树”的概念,把关键词查询问题转化成为“r-半径Steiner树问题”,可以从数据库中发现一些复杂且有意义的结构.文献[17]认为,简化子树还不能充分表达不同元组之间的关系,因此提出了“社区(community)”的概念,它是一个数据图中的多中心有向图,作者认为,“社区”比简化子树更能代表用户的查询兴趣.
基于模式图的方法主要包括3个步骤:第1步,利用数据库模式来枚举可能包含查询结果的所有连接表达式;第2步,根据一系列规则把连接表达式转换成SQL语句,并在数据库上执行,得到所有可能的候选结果;第3步,对结果进行排序并把相关内容返回给用户.在第2步中,执行SQL的方式可以分为两种:一种是使用SQL语句直接在RDBMS(relational database management system)上执行;另一种是采用中间件方法,在中间件上执行SQL语句,而中间件层位于RDBMS层之上.由于需要处理大量的关系代数表达式,许多现有的研究[7]都采用基于中间件的方法,而没有充分利用RDBMS的能力,只有早期的少量研究[5, 6]采用直接在RDBMS上执行SQL语句.文献[16]证明了:当前的商业数据库系统是足够强大的,可以高效地支持关键词查询,而不需要增加和维护额外的索引.因此,文献[16]采用了直接在RDBMS上执行SQL语句的方法,并且用实验证明了可行性.实际上,对于一些基于数据图的方法[4],也强调采用数据库自身的强大SQL查询能力实现关键词查询.DBXplorer和DISCOVER关注的是算法的效率,而忽视了算法的有效性,算法得到的有些结果虽然也包含了所有关键词,却未必是用户感兴趣的,这些结果就是无效的.因此,文献[23]重点研究了算法的有效性,它也是第一个采用大量实验来验证算法有效性的研究;同时,作者也提出了一个新的排序策略,通过采用精炼的加权模式对排序公式进行了优化,它可以对结果进行有效排序,并返回具有基本语义的结果.文献[24-26]主要讨论在关系数据库中如何支持高效的top-k关键词查询.很多基于模式图的方法大都采用即席的方式确定元组之间的关系,由于元组之间存在大量关系,这种方式通常效率较低.为此,文献[27]提出了元组单元(tuple unit)的概念,并为关键词查询增加了数据预处理阶段,在这个离线处理阶段,需要搜索元组单元并对这些单元进行物化,在关键词查询时,就可以直接利用这些元组单元加速关键词查询的在线处理.但是,文献[27]只能使用单个元组回答查询,因此,文献[28]进一步提出了结合多个元组回答查询的新方法.
在关键词查询结果优化方面,文献[29]提出了采用CourseCloud形式展现查询结果,而不是以元组连接树的形式呈现.CourseCloud把关键词查询的灵活性和标记云的概括、可视化能力相结合,来帮助用户更好地查询数据库内容.云包含了查询结果中最重要和最具有代表性的术语(概念),被称为数据云.数据云可以引导用户的搜索,帮助用户优化查询.数据云当中的每个术语都有超链接,用户可以点击超链接来优化查询结果;同时,数据云的内容也会根据最新的查询结果进行相应的更新.不同的用户可以从数据云中选择不同的术语,从而以不同的方式来优化查询.但是,CourseCloud这种对查询结果的优化方式与本文所说的查询结果优化完全不同. CourseCloud是在前端展示结果时,通过标记的方式引导用户点击访问合适的关键词,从而获得更好的查询结果;而本文的算法是在指定关键词的前提下,生成更好的查询结果.
查询的高效性和结果的有效性是本领域研究必须重点解决的问题,没有高效性的保证,查询响应时间就会超出用户的容忍范围,查询结果不具备很好的有效性,会让用户看到很多无用的结果,降低用户对系统的使用兴趣.已有的研究侧重点各有不同,比如,文献[30]等侧重于提高算法的效率,而文献[23]等则着力于提高结果的质量.本文则同时保证了查询的高效性和有效性,前者是通过蚁群优化算法实现的,后者是通过基于概念漂移理论的优化实现的.
6 结束语本文把关系数据库中的元组建模成数据图,把关键词查询问题转换成等价的最小Steiner树问题,引入了已经被证明具有良好性能的蚁群优化算法求解该问题.此外,还提出了基于概念漂移理论的用户查询兴趣突变探查方法,能够及时发现用户兴趣的变化,并提出结合概念漂移理论和蚁群优化算法的ACOKS*算法,可以根据用户兴趣的变化确定新到达查询的兴趣节点集,引导蚁群优化算法在生成结果的过程中,尽可能多地包含兴趣节点集中的内容,从而实现查询结果的动态优化,使得查询结果更加符合用户的预期,保证了查询结果的有效性.大量的实验结果证明了本文的算法具有很好的性能.
本文后续的研究工作将重点解决如何把算法进行拓展,应用于云计算环境中,从而可以充分利用大量的廉价工业服务器资源,并行处理多个用户的大量查询请求.
| [1] | Bhalotia G, Hulgeri A, Nakhe C, Chakrabarti S, Sudarshan S. Keyword searching and browsing in databases using BANKS. In: Agrawal R, Dittrich KR, eds. Proc. of the 18th Int’l Conf. on Data Engineering (ICDE 2002). New York: IEEE, 2002.431-440 . |
| [2] | Kacholia V, Pandit S, Chakrabarti S, Sudarshan S, Desai R, Karambelkar H. Bidirectional expansion for keyword search on graph databases. In: Böhm K, Jensen CS, Haas LM, eds. Proc. of the 31st Int’l Conf. on Very Large Data Bases (VLDB 2005). New York: ACM Press, 2005. 505-516. http://www.informatik.uni-trier.de/~ley/db/conf/vldb/vldb2005.html |
| [3] | Li GL, Ooi BC, Feng JH, Wang JY, Zhou LZ. EASE: An effective 3-in-1 keyword search method for unstructured, semi-structured and structured data. In: Tsong J, Wang L, eds. Proc. of the 2008 ACM SIGMOD Conf. on Management of Data (SIGMOD 2008). New York: ACM Press, 2008. 903-914 . |
| [4] | Li GL, Feng JH, Zhou XF, Wang JY. Providing built-in keyword search capabilities in RDBMS. VLDB Journal, 2011,20(1):1-19 . |
| [5] | Agrawal S, Chaudhuri S, Das G. DBXplorer: A system for keyword-based search over relational databases. In: Agrawal R, Dittrich KR, eds. Proc. of the 18th Int’l Conf. on Data Engineering (ICDE 2002). New York: IEEE, 2002. 5-16 . |
| [6] | Hristidis V, Papakonstantinou Y. DISCOVER: Keyword search in relational databases. In: Proc. of the 28th Int’l Conf. on Very Large Data Bases (VLDB 2002). New York: Morgan Kaufmann Publishers, 2002. 670-681. http://www.informatik.uni-trier.de/~ley/db/confvldb/vldb2002.html |
| [7] | Markowetz A, Yang Y, Papadias D. Keyword search on relational data streams. In: Chan CY, Ooi BC, Zhou AY, eds. Proc. of the 2007 ACM SIGMOD Conf. on Management of Data (SIGMOD 2007). New York: ACM Press, 2007. 605-616 . |
| [8] | Kimelfeld B, Sagiv Y. Efficient engines for keyword proximity search. In: Doan AH, Neven F, McCann R, eds. Proc. of the 8th Int’l Workshop on the Web & Databases (WebDB 2005). New York: ACM Press, 2005. 67-72. http://www.informatik.uni-trier.de/~ley/db/conf/webdb/webdb2005.html |
| [9] | Ding B, Yu JX, Wang S, Qin L, Zhang X, Lin XM. Finding top-k min-cost connected trees in databases. In: Chirkova R, Dogac A, Özsu MT, Sellis TK, eds. Proc. of the 23rd Int’l Conf. on Data Engineering (ICDE 2007). New York: IEEE, 2007.836-845 . |
| [10] | Colorni A, Dorigo M, Maniczzo V. Distributed optimization by ant colonies. In: Varela FJ, Bourgine P, eds. Proc. of the 1st European Conf. on Artificial Life (ECAL’91). Cambridge: MIT Press, 1991. 134-142. |
| [11] | Gutjahr WJ. A graph-based ant system and its convergence. Future Generation Computer Systems, 2000,16(8):873-888 . |
| [12] | Yang WG, Guo TD. An ant colony optimization algorithm for the minimum Steiner tree problem and its convergence proof. Acta Mathematicae Applicatae Sinica, 2006,29(2):352-361 (in Chinese with English abstract) . |
| [13] | Prossegger M, Bouchachia A. Ant colony optimization for Steiner tree problems. In: Proc. of the 5th Int’l Conf. on Soft Computing as Transdisciplinary Science and Technology (CSTST 2008). New York: ACM Press, 331-336. |
| [14] | Hu Y, Jing T, Hong XL, Feng Z, Hu XD, Yan GY. An efficient rectilinear Steiner minimum tree algorithm based on ant colony optimization. In: Proc. of the Int’l Conf. on Communications, Circuits and Systems (ICCCAS 2004). New York: IEEE, 2004.1276-1280 . |
| [15] | Peng ZH, Zhang J, Wang S. S-CBR: Presenting results of keyword search over databases based on database schema. Ruan Jian Xue Bao/Journal of Software, 2008,19(2):323-337 (in Chinese with English abstract). http://www.jos.org.cn/1000-9825/19/323.htm |
| [16] | Qin L, Yu JX, Chang LJ. Keyword search in databases: The power of RDBMS. In: Cetintemel U, Zdonik SB, Kossmann D, Tatbul N, eds. Proc. of the 2009 ACM SIGMOD Conf. on Management of Data (SIGMOD 2009). New York: ACM Press, 2009. 681-694 . |
| [17] | Qin L, Yu JX, Chang LJ, Tao YF. Querying communities in relational databases. In: Ioannidis YE, Lee DL, Ng RT, eds. Proc. of the 25th Int’l Conf. on Data Engineering (ICDE 2009). New York: IEEE, 2009. 724-735 . |
| [18] | Thein MM. Querying connected tuple trees for relational keyword search. In: Mahmod R, Abdullah R, Abdullah LN, Sembok TMT, Smeaton AF, Crestani F, Doraisamy S, Kadir RA, Ismail M, eds. Proc. of the Int’l Conf. on Information Retrieval & Knowledge Management (CAMP 2012). New York: IEEE, 2012.285-289 . |
| [19] | Lin ZY, Yang DQ, Wang TJ, Zhang DZ. Keyword search over relational databases. Ruan Jian Xue Bao/Journal of Software, 2010,21(10):2454-2476 (in Chinese with English abstract). http://www.jos.org.cn/1000-9825/3913.htm |
| [20] | He H, Wang HX, Yang J, Yu PS. BLINKS: Ranked keyword searches on graphs. In: Chan CY, Ooi BC, Zhou AY, eds. Proc. of the 2007 ACM SIGMOD Conf. on Management of Data (SIGMOD 2007). New York: ACM Press, 2007. 305-316 . |
| [21] | Kimelfeld B, Sagiv Y. Efficiently enumerating results of keyword search over data graphs. Information System, 2008,33(4-5): 335-359 . |
| [22] | Wang S, Peng ZH, Zhang J, Qin L, Wang S, Yu JX, Ding BL. NUITS: A novel user interface for efficient keyword search over databases. In: Dayal U, Whang KY, Lomet DB, Alonso G, Lohman GM, Kersten ML, Cha SK, Kim YK, eds. Proc. of the 30th Int’l Conf. on Very Large Data Bases (VLDB 2006). New York: Morgan Kaufmann Publishers, 2006. 1143-1146. http://www.informatik.uni-trier.de/~ley/db/conf/vldb/vldb2006.html |
| [23] | Liu F, Yu CT, Meng WY, Chowdhury A. Effective keyword search in relational databases. In: Chaudhuri S, Hristidis V, Polyzotis N, eds. Proc. of the 2006 ACM SIGMOD Int’l Conf. on Management of Data (SIGMOD 2006). New York: ACM Press, 2006.563-574 . |
| [24] | Luo Y, Lin XM, Wang W, Zhou XF. Spark: Top-k keyword query in relational databases. In: Chan CY, Ooi BC, Zhou AY, eds. Proc. of the 2007 ACM SIGMOD Conf. on Management of Data (SIGMOD 2007). New York: ACM Press, 2007.115-126 . |
| [25] | Luo Y, Wang W, Lin XM, Zhou XF, Wang JM, Li KQ. SPARK2: Top-k keyword query in relational databases. IEEE Trans. on Knowledge and Data Engineering, 2011,23(12):1763-1780 . |
| [26] | Xu YW, Guan JH, Ishikawa Y. Scalable top-k keyword search in relational databases. In: Lee SG, Peng ZY, Zhou XF, Moon YS, Unland R, Yoo J, eds. Proc. of the 17th Int’l Conf. on Database Systems for Advanced Applications (DASFAA 2012). Berlin: Springer-Verlag, 2012. 65-80. http://www.informatik.uni-trier.de/~ley/db/conf/dasfaa/dasfaa2012-2.html |
| [27] | Li GL, Feng JH, Zhou LZ. Retune: Retrieving and materializing tuple units for effective keyword search over relational databases. In: Li Q, Spaccapietra S, Yu ES, Olivé A, eds. Proc. of the 27th Int’l Conf. on Conceptual Modeling (ER 2008). Berlin: Springer-Verlag, 2008.469-483 . |
| [28] | Feng JH, Li GL, Wang JY. Finding top-k answers in keyword search over relational databases using tuple units. IEEE Trans. on Knowledge and Data Engineering, 2011,23(12):1781-1794 . |
| [29] | Koutrika G, Zadeh ZM, Garcia-Molina H. Data clouds: Summarizing keyword search results over structured data. In: Kersten ML, Novikov B, Teubner J, Polutin V, Manegold S, eds. Proc. of the 12th Int’l Conf. on Extending Database Technology (EDBT 2009). New York: ACM Press, 2009.391-402 . |
| [30] | Hristidis V, Gravano L, Papakonstantinou Y. Efficient IR-style keyword search over relational databases. In: Freytag JC, Lockemann PC, Abiteboul S, Carey MJ, Selinger PG, Heuer A, eds. Proc. of the 29th Int’l Conf. on Very Large Data Bases (VLDB 2003). New York: Morgan Kaufmann Publishers, 2003. 850-861. http://www.informatik.uni-trier.de/~ley/db/conf/vldb/vldb2003.html |
| [15] | 彭朝晖,张俊,王珊.S-CBR:基于数据库模式展现数据库关键词检索结果.软件学报,2008,19(2):323-337. http://www.jos.org.cn/1000-9825/19/323.htm |
| [19] | 林子雨,杨冬青,王腾蛟,张东站.基于关系数据库的关键词查询.软件学报,2010,21(10):2454-2476. http://www.jos.org.cn/1000-9825/3913.htm |