 2014, Vol.25
2014, Vol.25 

2 新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;
3 科技部 高技术研究发展中心,北京 100044

 , WANG Sheng-Yuan1, DONG Yuan1, JI Zhi-Yuan3, GAN Yuan-Ke1, ZHANG Ling-Bo1, ZHANG Yu-Cheng1, WANG Lei1, YANG Fei1
, WANG Sheng-Yuan1, DONG Yuan1, JI Zhi-Yuan3, GAN Yuan-Ke1, ZHANG Ling-Bo1, ZHANG Yu-Cheng1, WANG Lei1, YANG Fei1 2 School of Information Science and Engineering, Xinjiang University, Urumqi 830046, China;
3 High Technology Research and Development Center, Ministry of Science and Technology, Beijing 100044, China
随着计算机控制系统在人们生活中的普及,软件自身的可靠性也越来越受到重视.在航空、高铁、核电及军事等高安全要求领域的软件系统——安全关键系统(safety-critical system,简称SCS)[1]更是受到高度的重视.而随着软件系统的复杂度越来越高,软件系统的安全性保证也变得越来越困难.这些系统的开发,仅仅依靠过程规范、代码审核和系统测试来保证软件安全还远远不够,通常需要采用形式化验证方法来保证软件可靠性.在某些安全性严格要求的领域,不但对目标系统的开发需要形式化方法来保证,而且开发过程所需工具,如编译器等,也必须经过形式化验证.
(1) 同步模型与同步数据流语言
工业生产中的很多实时系统(如控制系统)都是响应系统,它是以环境决定的速率对环境做出连续响应的系统.此环境可以随时提供新的输入,系统通过运算产生新的输出,使得程序不断地与环境进行交互,且以并发的方式体现.
同步模型是为了适应响应系统而开发的程序运行模型.它把响应系统分成连续的原子时间片(响应周期),每个时间片又分成事件采集、逻辑运算和事件发射这3个阶段,从而有效地满足响应系统的要求.在同步模型中,事件的采集、逻辑运算和事件的发射必须在同一个响应周期内完成,这称为同步模型的同步假设.时间片的大小是由响应系统的环境决定的.同步假设的有效性检查,就是评估系统对环境的最大响应时间能否满足环境要求.图 1为同步模型示意图.
 | Fig. 1 Synchronous model图 1 同步模型 |
关于同步模型编程范型的理论工作30多年前已经开始[2],之后出现了许多得到广泛应用的同步语言[3, 4, 5],最著名的如Esterel[6, 7],Lustre[8, 9]和Signal[10, 11].同步语言的范型主要可分为两类:命令式(imperative)和陈述式(declarative).Esterel是命令式同步语言,侧重于描述控制流;Lustre和Signal是陈述式同步语言,具有数据流特征,常称为同步数据流语言.Lustre是一种函数式(functional)风格的语言,具有确定语义;Signal是关系型(relational)语言,具有非确定语义.
(2) 编译器的可信
对于编译器来说,可信的具体指标就是其正确性,要保证从源程序到目标程序的翻译过程正确,即,保证源语言的特征被正确、完整地实现,能够实现语义保持性,杜绝误编译.
为了保障编译器实现的正确性,传统的方法是通过大量的测试.例如,GCC(4.7版)的torture测试集包含2 853个C源程序用例[12],商用的Plum Hall Standard Validation Suite for C有29 424个用例[13],Lustre V6[14]的开源软件包中含有140个左右的源程序用例,等等.还有一些Bug-hunting工具(如Csmith[15])可能产生更多或更独特的源程序用例.
然而和其他软件一样,通过测试只能发现错误,并不能保证编译器是正确的.Scade[16]工具的代码生成器KCG或许是获得民用航空软件生产许可的第一个商用编译器,其设计开发过程(很严格的V&V过程)符合民航电子系统的国际标准DO-178B,并成功应用于空客(airbus)A340和A380的设计中.尽管如此,这并不足以说明Scade的编译器不存在“误编译”.事实上,业界已经发现Scade KCG的某些翻译漏洞.
为增加编译器的安全和可信程度,仅通过测试和严格的过程管理都是不够的,人们很自然地会想到形式化验证的途径.在CC(common criteria)安全评估标准[17]中,将可信性分为7个级别(EAL1~EAL7),级别越高,形式化规范和验证的程度越高.航空无线电委员会(RTCA)近期也已推出民航电子系统的国际标准DO-178C,与DO-178B相比,增加的内容包括了对形式化规范和验证的要求[18].
人们在几十年前就开展了编译器形式化验证的工作:McCarthy等人在1967年手工证明了一个简单编译器(从算术表达式翻译到栈式机目标代码)的正确性[19];随后,Milner等人在1972年给出了相应的机械化证明[20];Dave于2003年的综述列举了从1967年~2003年的大部分相关工作[21],包含从针对简单语言的单遍编译器到较成熟的代码优化遍等形形色色的工作.近年来,随着技术的不断进步,已经可以验证较为复杂的编译器.例如,Leroy等人开发的验证过的C编译器CompCert[22],Chlipala给出一个从非纯函数式的语言到汇编语言的一个经过验证的编译器[23],Klein等人验证了一个从Java核心子集到Java虚拟机的编译器[24].
CompCert编译器[22]是经过验证的可信编译器的杰出代表.该编译器将C的一个重要子集Clight翻译为PowerPC汇编代码(目前也支持IA32后端),使其可以直接用于范围广泛的嵌入式应用开发.该编译器包含了许多分析与优化,所生成的代码可与gcc-0产生的代码匹敌.该编译器将编译过程划分为多个阶段,每个阶段的翻译正确性(语义保持性)都借助辅助定理证明器Coq[25, 26]进行了证明,且这些证明可由独立的证明检查器检查,这使得CompCert的中间层转换过程达到了我们所能期望的最高可信程度[27].最近,Yang等人在关于Csmith的研究工作[15]中对主流的C编译器进行测试,共报告了325个bugs,其中包括Intel CC,GCC和LLVM等.在所比较的11种开源或商用的C编译器中,CompCert表现较为突出,在6个CPU年中,其中间转换过程没有发现bugs.
编译器验证的另外一种可选方案是翻译确认(translation validation).翻译确认(translation validation)是 Pnueli等人首先提出来的[28].他们采用翻译确认的方法来验证同步数据流语言的翻译(或编译)过程[28, 29],所给示范例子的源语言是Signal特征的多时钟同步数据流语言,目标语言是C.翻译确认的方法不是直接验证翻译程序,而是用统一的语义框架为某一翻译过程的源和目标代码建模,两个模型之间定义一种求精(refining)等价关系,设计一种可自动证明二者等价性的分析程序(成功时可给出证明脚本,不成功时给出反例),再给出一种独立的证明检查器(proof checker),可最后确认翻译的正确性.
Ngo等人基于翻译确认的思想开展了同步数据流语言Signal到C的编译器验证工作[30],其最新的进展是:对源和目标代码用统一语义框架PDS(polynomial dynamical system)建模,给出一种源和目标之间的抽象时钟等价关系,从而证明编译器可保持时钟语义的一致性[30, 31, 32].求精等价关系的证明采用SMT求解器[33]自动完成.
对于翻译(或编译)程序的验证来说,翻译确认有时是一个很好的选择[22],这种方法适用于翻译前后语义保持性的确认过程较容易构造,并且比翻译程序的验证更简单的情形.我们认为,翻译确认方法的最大优点是不放弃现有编译器,比如,基于一些大型编译器也可以有类似的工作[34].这种方法的可扩性(scalability)较好.
在L2C项目中,我们选择了对编译器本身进行验证.当源语言和目标语言的语义定义达到认可的程度时,原理上可以保证源程序的一般性质都可以保持到目标程序.与上述翻译确认的做法相比,这是一种彻底的做法;而基于翻译确认的方法往往只是关注部分性质的保持性(当然,也可以逐步逼近一般性质).然而,这项工作相当艰巨,正如前述Pouzet等人的项目,是一项长期的工作.然而,我们的考虑是:1) 实际中有值得这样做的需求; 2) 如果在面向验证的编译器结构上下功夫,加强证明过程的局部化和模块化研究,可减轻需要扩展和维护时的负担;3) 在某些扩展和维护工作量过大的翻译阶段,还可以采用翻译确认的方法作为补充,比如CompCert项目,也有个别阶段采用了翻译确认方案;4) CompCert项目的成功,告诉我们这一选择的重要价值和可行性.
受CompCert项目[22]的启发,Paulin等人于2006年启动了一个有关同步数据流语言编译器验证的长线项 目[35],源语言接近Scade的Lustre语言且具有Lucid Synchrone[36]的特征.该项目的工作目标与本课题组的L2C项目相似.就我们所了解,该项目的工作进展目前仍集中于前端,完成了类型检查和时钟演算相关过程的验证,后续又在开展因果性分析程序的验证工作[37].Biernacki等人在文献[38, 39]中描述了该项目的一些相关工作.他们将Lustre语言的一个较早版本翻译至Java和C代码,采用了一种基于对象的中间语言.然而,拟采用的语义模型以及翻译过程的正确性(即语义保持性)验证的工作尚未见诸报道.
本文第1节给出可信编译器的总体设计框架.第2节介绍翻译过程正确性相关的核心内容.第3节是关于现状及后续工作计划.第4节是本文的一个简短总结.
L2C项目和CompCert项目一样,源语言、目标语言和各阶段中间语言的语法、语义、翻译过程的定义以及正确性证明都在交互式辅助定理证明工具Coq[25, 26]中实现.在Coq中,程序、性质和证明可用同一种语言来描述. Coq系统用OCaml实现,完全开源,其核心很小且常年稳定,被广泛应用于工业界和研究领域.
为了方便,同时考虑到今后从C代码到可执行目标代码的可信翻译需求,L2C项目可信编译器的目标语言C直接借用了CompCert编译器中Clight的语法和语义定义[40].
L2C项目的可信编译器结构几经改变才趋于稳定,目前的总体结构如图 2所示.目前所定义的源语言原型Lustre*是Lustre语言的一个核心子集,综合参考了Scade工具的Lustre语言版本和Lustre V6[41],能够体现同步数据流语言的主要特征.为了方便,本文以附录形式给出了当前Lustre*语言的语法定义(附录A)以及Lustre*程序的一个样例(附录B),仅供读者必要时参考.
 | Fig. 2 Architecture of the trustworthy compiler L2C 图 2 L2C项目的可信编译器总体结构 |
在项目开展初期,编译器仅包含4个语言层次:Lustre* Source,Well-Typed Lustre* AST,Lustre- AST以及Clight AST.然后,为方便语义定义,我们将串行化的任务提前,而不是在最后生成Clight AST时进行;这样,引入了S-Lustre AST*;该中间语言及其后续中间语言均具有串行语义.然后,为确保翻译至Lustre- AST后仍可保持原有因果性,增加了一个针对时态运算(pre,FBY)的预处理过程,引入了Preprocessed Lustre* AST.接着,由于Lustre-与Clight之间仍有很大语义差距,所以引入中间语言LustreF AST,以便消去时态算子.当项目进行了相当长的一个阶段后,实践表明,若考虑多时钟/时钟层次,这些语言层次翻译过程的语义保持性的证明相当困难.同时也考虑到今后扩展的需求,所以引入中间语言Clock-Normalized Lustre* AST.
图 2中编译器各翻译步骤的工作分别是:
(A) Lustre*源程序,经过一个语法解析过程(其间穿插常量/类型展开或求值的工作),被翻译至Lustre* AST.
(B) 对Lustre* AST进行类型检查(含普通类型检查、因果性检查、时钟检查以及初始化检查)的过程,得到Well-Typed Lustre* AST.
(C) Well-Typed Lustre* AST经过预处理后得到Preprocessed Lustre* AST(其中,pre,FBY等时态算子的操作数简化为变量或常量).
(D) Preprocessed Lustre* AST经时钟的归一化处理,消去when取样算子,得到只包含默认时钟的Clock- Normalized Lustre* AST.
(E) 经过串行化过程之后,所得到的S-Lustre* AST是Clock-Normalized Lustre* AST的一个拓扑排序.
(F) S-Lustre* AST经进一步简化得到Lustre- AST(类似三地址码).
(G) 消去时态运算后,从Lustre- AST得到LustreF AST.
(H) 最后,将LustreF AST转换至CompCert项目所定义的C语言子集Clight的抽象语法树Clight AST.
在L2C可信编译器总体结构中,除了第(A)步以外,第(B)步~第(H)步都需要形式化证明各阶段源语言到目标语言的语义保持性.目前,全部完成的步骤是第(E)步~第(H)步.
在图 2所示的可信编译器总体结构中,除了语法解析过程(穿插常量/类型展开或求值)以外,其余各翻译步骤都需要形式化证明各阶段源语言到目标语言的语义保持性.
如图 3所示,S语言程序P被翻译至T语言程序T(P).SS是S语言的语义函数,ST是T语言的语义函数.从语言S至语言T的语义保持性是指:
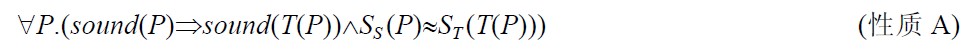
这里,sound(P)和sound(T(P))意味着可以正常得到SS(P)和ST(T(P)).≈是单向模拟等价关系.SS(P)≈ST(T(P))意味着:P的所有环境变量在T(P)都有匹配对象,且SS(P)对环境的改变可以通过ST(T(P))对相匹配环境的改变进行模拟.
 | Fig. 3 Semantics preserving图 3 语义保持性 |
对于合法的Lustre*程序,求值结果总是确定的(对每一层语言的语义都要证明这个性质),这意味着语义计算的确定性(并发语义的情形也只是求值过程的并发,而不同求值过程的结果是确定的).在这种特殊情形下,我们证明上述单向模拟关系就可以了.
以下从具有代表性的几个侧面来展开说明.
串行化之后的中间语言,包括S-Lustre*,Lustre-,LustreF以及Clight等,均具有串行语义.Clight的语法和语义同CompCert编译器中的定义[40].S-Lustre*和Lustre-的语义框架一致,只是因语法成分不同而导致了语义规则的差异.LustreF由于已消除时态算子,因而语义环境比起Lustre-有了很大的简化,拉近了与Clight语义的差距.
下面主要对S-Lustre*或Lustre-语义框架(简称串行Lustre语义)的核心部分进行半形式化的解释.
Lustre串行语义与常规顺序语言的语义的最大差别,就是需要处理好时钟以及时态算子,这些都体现在语义环境和语义规则的定义中.
首先介绍语义环境.由于要考虑时钟和时态算子,加之与node的调用纠结起来,使得Lustre串行语义环境比起常规顺序语言的语义环境要复杂许多.语义环境由全局和局部环境组成.由于不含全局量,全局环境(global environment)ge可简单地定义为

可以通过node的id在全局环境ge中查找node的具体定义.局部环境e的定义比较复杂:

这里,我们定义了一个3层的局部环境.底层环境le与传统语言语义的局部环境类似,刻画了node在某个时钟周期的局部环境,它将局部变量的id映射到当前时钟下的取值v以及时钟ck和类型t.由于在之前的翻译阶段增加了时钟归一化处理,ck一定是指全局时钟,因而可省略.中间层的te刻画一种时态环境,是le的一个列表,该列表的第n个元素表示第n个时钟周期的le.由于每个node在任何时钟周期都被执行,所以在每个时钟周期开始的时刻,所有node的te的长度均相等.一个node实例的顶层环境e是一个复杂的树状结构,其数据域te维护了该node实例中局部变量、输入和输出参量的历史取值,其每个子树本身又是新node实例的顶层环境,第n个子树代表该node中第n个调用的子node实例的顶层环境.
图 4刻画了node A调用node B两次、调用node C一次,而node C调用node B一次的情形下,node A实例所形成的局部环境.
 | Fig. 4 An example of node local environment图 4 Node局部环境示意 |
限于篇幅,本文仅以if表达式和fby**表达式为例说明串行Lustre表达式求值的语义规则.虽然S-Lustre*和Lustre-的语义在框架上是一致的,但由于Lustre-的普通表达式中不含node调用,所以二者的if表达式语义规则大不相同.而二者的fby表达式语法上相同,所以fby表达式的语义规则很相似.
S-Lustre*中if表达式的语义规则:

S-Lustre*的并发特征,if表达式的子表达式c,ex1,ex2是并发执行的,这不同于命令式语言的if控制语句.
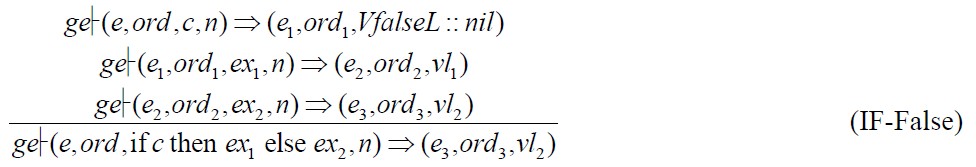
其中,VtrueL和VfalseL是布尔语义常值;形式断言(judgement):

其含义为:在全局环境ge中,某个node实例中的表达式expr(可以是表达式列表)于第n个时钟周期在局部环境e下进行求值,求值结果为vl(值的列表),同时,环境e被修改为e',所执行的子节点次序编号由ord变为ord'.再详细一些解释,这里的e是当前执行点的环境,即,第n个周期下expr求值之前的树形局部环境;而e'则是当前执行点之后的环境,即,第n个周期下expr求值之后的树形局部环境.次序编号ord对应于将被调用的子node实例的环境,而ord'则对应于该表达式求值之后将被调用的子node实例的环境.换句话说,次序编号用于标记树形局部环境中子环境的位置.
在Lustre-的语义中,对于表达式求值,形式断言可简化为
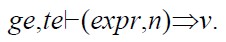
其含义为:在全局环境ge及某个node实例的时态环境te中,表达式expr(单个表达式,而非表达式列表)于第n个时钟周期进行求值,求值结果为v(单个值,而不是值的列表).局部环境以及所执行的子节点次序编号均不发生改变.实际上,总有|te|=n.这里重复使用n,主要考虑到方便性.
在Lustre-中,if表达式的语义规则如下:
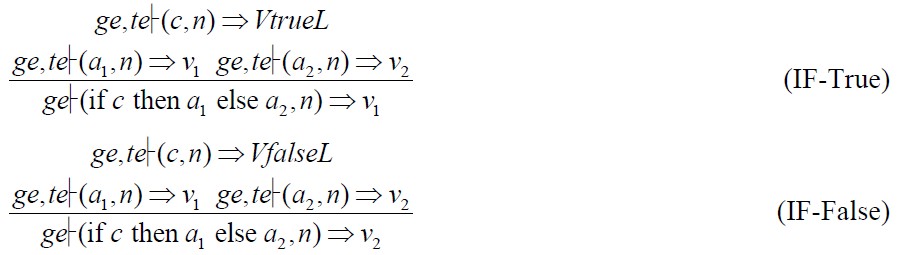
其中,a1,a2为原子表达式.
在Lustre-中,fby表达式的语义规则如下:
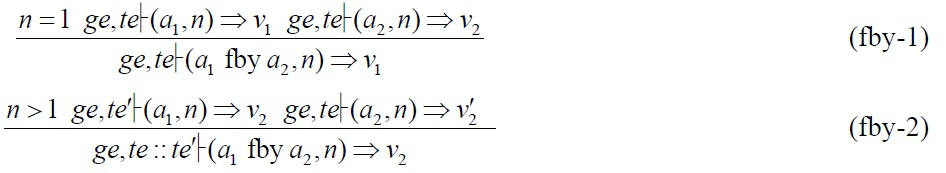
在S-Lustre*中,fby表达式的语义与Lustre-中fby表达式的语义本质上没有什么差异,只是语义规则采用了不同的形式断言,使得二者的语义规则形式上有所不同.在S-Lustre*中,fby表达式的语义规则:

S-Lustre*与Lustre-中都可以包含call表达式,所不同的是:在S-Lustre*表达式中,call表达式可以作为子表达式;而在Lustre-中,call表达式一定是一个单独的表达式,不会出现在其他表达式中.因为这种差异,我们在定义上述if和fby表达式的语义规则时,针对S-Lustre*与Lustre-使用了不同的形式断言.其他非call表达式的情形也是类似的.然而对于call表达式,在Lustre-中使用了与S-Lustre*中相似的形式断言.由于call表达式的语义规则比较繁琐,本文不对此进行叙述.下面我们通过等式(equation)的语义规则,也可以体会到二者使用了相似的形式断言.
在S-Lustre*中,等式的语义规则如下:

其中,使用了形式断言:

其含义为:在全局环境ge和局部环境e中,等式列表eqs于第n个时钟周期进行计算,计算结果使环境e被改变为e',所执行的子节点次序编号由ord变为ord'.
在这一规则中,使用了语义函数localenvL_setvars(le,lhs,vl),它用值列表vl重置lhs中所有变量的状态,并返回新的(底层)局部环境.
在Lustre-中,等式的语义规则使用同样的形式断言:

这个语义规则只适用于普通等式lh=expr,而不适用于expr为call表达式的情形,所以,se和ord均未发生改变.语义函数localenvL_setvars(le,lhs,vl)的含义不变.
对于等式列表(可以包含expr为call表达式的等式),S-Lustre*和Lustre-中使用了相同的语义规则:
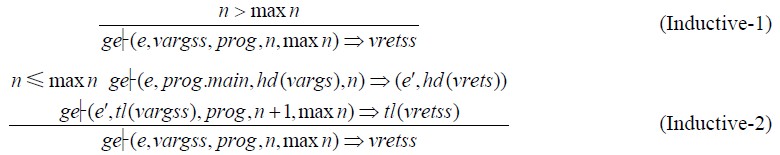
在等式列表语义的基础上,可进一步定义node/function的语义,这里不再详述.一个程序prog是由多个node/function组成的,如果指定某个node是主node,那么我们可以定义整个程序的语义.由于Lustre程序处理的是流数据对象,所以其语义本质上在无穷流上执行,因此很适合通过CoInductive的方式来处理.然而出于技术上的考虑,我们采用的是用Inductive的方式来模拟这种效果.采用这种方法,定义整个程序的语义规则为

其中,vargss和vretss分别是从第n个时钟周期开始的input和output流.当n>maxn时,vargss和vretss实际上不被计算,假设其取值为任意未定义值的流.hd(s)表示取流s的首元素,tl(s)用于获取流s去掉首元素后的流.形式断言:
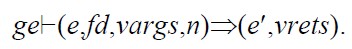
其含义为:在全局环境ge中,由fd定义的node/function于第n个时钟周期进行计算,实参值列表为vargs,返回值列表为vargs,计算结果使环境e被改变为e'.形式断言:

其含义为:在全局环境ge中,程序prog于第n个时钟周期开始逐个周期反复执行,直至第maxn个时钟周期结束,主node的初始局部环境为e,input和output分别始于第n个周期的输入值列表和输出值列表的流(始于第maxn+1个时钟周期的输入值列表和输出值列表均取未定义值).
以上我们描述了S-Lustre*和Lustre-语义定义的主要思想.对于LustreF来说,由于已消去时态算子(fby,arrow等),所以其语义定义中可以不考虑时态环境(如图 4所示的te).此外,其语义类似于Lustre-,这里不再赘述.
我们仅给出S-Lustre*到Lustre-的语义保持性定理及证明概要,以此为例说明语义保持性的基本含义,其余层次之间的证明框架大致相似.这是一种单向的语义保持,之前已经说过,由于Lustre语义是确定的,所以足以达到我们证明翻译正确性的目标.

其中,S-Lustre*程序progS经过trans翻译函数后得到Lustre-程序progM.initial_stateS将progS的执行环境eS初始化为空环境,将主节点置为mainS;initial_stateM将progM的执行环境eM初始化为空环境,将主节点置为mainM.iter_exec_programS的定义对应第2.1节的Iuductive-1和Iuductive-2.iter_exec_programM也类似.语义保持性的含义:如果progS在环境eS下的执行对输入实参的流vargss返回值的流vretss,那么progM在环境eM下的执行对输入实参的流vargss同样是返回值的流vretss;而eS和eM从初始化为空环境后自然匹配,然后从第1个周期到之后任何一个周期皆保持匹配关系.
为便于归纳证明,我们将定理trans_programS_correct推广到更一般的定理:

其中,trans_node为主节点翻译函数,envL_match是环境的匹配关系.iter_exec_programS和iter_exec_programM分别是源和目标程序语义执行关系式.
从定理trans_programS_correct_general可知,我们实际是需要证明:同样的输入/输出在LustreS中满足执行关系式iter_exec_programS,那么在LustreM中仍然满足执行关系式iter_exec_programM,而执行可以理解为一个周期一周期主节点函数的串行执行.我们可以将程序执行的等级性转化为求节点函数的环境匹配的问题,即证明:

其中,Trans_node是节点翻译函数,eval_nodeS和eval_nodeM分别是源和目标节点的语义求值函数.
引理trans_nodeS_all_correct是整个语义保持性证明的核心,其证明也比较复杂.由于eval_nodeS是互归纳定义的,因此需要用到互归纳证明.
在引理trans_nodeS_all_correct的证明中,需要在不同阶段不断分析修改其表现形式.比如,我们需要用到从S-Lustre*表达式转换到Lustre-等式列表、从S-Lustre*表达式列表转换到Lustre-等式列表、从S-Lustre*等式转换到Lustre-等式列表、从S-Lustre*等式列表转换到Lustre-等式列表等一系列转换的语义保持性.
这些语义保持性都可以描述成:翻译前后的程序单元执行时,对于语义环境的改变是相一致的.不同类别的程序单元,根据其翻译前后的特征,其语义保持性的表述形式会有所不同.比如,对于表达式翻译前后的语义保持性,我们需要分别就原子表达式、一元表达式、二元表达式、条件表达式、fby表达式以及call表达式等相应的语义规则分别加以证明.
诸如原子表达式、fby表达式的情形比较简单,由于前端的预处理步骤(图 2中的Pre-Processing),使得S-Lustre*和Lustre-中的fby表达式形式上没有差别,它们的操作数都只可能是原子表达式.此类表达式翻译后不会引入新的中间变量,也不会引入新的等式列表.
条件表达式就要复杂一些,要引入新的中间变量和新增等式列表.
下面我们仅以条件表达式为例,来简单说明其语义保持性的证明.
先看S-Lustre*中条件表达式if ex then ex1 else ex2的翻译过程:将ex,ex1和ex2分别递归翻译到Lustre-中的等式列表eqs,eqs1和eqs2.设ex,ex1和ex2的结果分别对应到eqs,eqs1和eqs2中某等式的左端id,id1和id2,则if ex then ex1 else ex2对应到Lustre-中就对应于表达式if id then id1 else id2.然而,除了id,id1和id2以及ex,ex1和ex2中的变量外,eqs,eqs1和eqs2中还有许多其他的中间变量.
首先,我们要证明翻译前后程序中id的相关性质:翻译前环境中的id会保留至翻译后,并且新添的id不会与原环境中id相交.如果翻译前后环境中的id之间满足这一性质,并且同一名称的id在两个环境中的取值相等,则称翻译前后的环境是匹配的.
这样,我们的目标成为:if ex then ex1 else ex2在S-Lustre*语义中对环境的改变,能够匹配依次执行eqs,eqs1, eqs2和if id then id1 else id2在Lustre-语义中对环境的改变,并且if ex then ex1 else ex2求值的结果与if id then id1 else id2的求值结果相同.
具体到语义规则,我们仅以If-False为例,If-True的情形类似.
证明思路是:设任意可以匹配的S-Lustre*环境e和Lustre-环境eM.
假设在S-Lustre*中,在环境e和实例编号ord下执行if ex then ex1 else ex2的结果为vl2以及ord改变为ord3.可以根据两个规则If-True或If-False得出这个结果,我们假设是If-False.那么,根据S-Lustre*中If-False规则,存在e1,e2,e3以及ord1,ord2,ord3,满足:1) 在环境e下执行ex的结果为Vfalse(为了简洁,我们忽略周期编号n以及列表形式的值Vfalse::nil,下同),环境改变为e1,代表当前节点实例号的ord改变为ord1;2) 环境e1下执行ex1的结果为vl1,环境改变为e2,ord由ord1变为ord2;3) 环境e2下执行ex2的结果vl2,环境改变为e3,ord由ord2变为ord3.
然后我们证明:1) 在eM环境下执行等式列表eqs后,环境变为可与e1匹配的eM1,eM1中id的取值为Vfalse, ord改变为ord1;2) 在eM1环境下执行等式列表eqs1后,环境变为可与e2匹配的eM2,eM2中id1的取值为vl1,ord由ord1变为ord2;3) 在eM2环境下执行等式列表eqs2后,环境变为可与e3匹配的eM3,eM3中id2的取值为vl2,ord由ord2变为ord3.这个过程会递归用到第2.1节中的equations规则以及其他规则.
最后,我们可由第2.1节中关于Lustre-的If-False规则得出结论:在环境eM和实例编号ord下,依次执行eqs, eqs1,eqs2和if id then id1 else id2的结果使环境变为eM3,ord改变为ord3.
如图 2所示,在L2C项目的设计方案中,串行化(sequentializing)之前的各语言层次采用并发语义,其后的各语言层次采用顺序语义.串行化的正确性意味着语义过渡是合理的.
执行串行化算法的结果就是使程序的每个node/function内部的等式确定一个满足因果关系的计算序列(即,前面的求值不依赖于后面的变量).串行化正确性证明的目标是:(A) 先要证明串行化前后不会造成等式或者节点的缺失,前后代码相互之间是一种重新排列的关系;(B) 串行化前的程序根据并发语义得到的求值结果,与串行化后的程序根据顺序语义得到的求值结果是相同的.
串行化前的程序P满足性质sound(P),其中包括了并发语义求值结果的确定性.对于后者的证明,需要验证所有交叉执行(interleaving)结果的一致性.在现阶段的L2C项目实现中,并发粒度是等式,即,串行化算法中的拓扑排序是以单个等式为单位.
虽然以单个等式为单位的并发粒度可以满足合作企业目前的实际需求,但在L2C项目的总体规划中,将采用更细的并发粒度(以单个基本操作为单位),这会在理论上更加合理.当然,工作量会加大不少.
时态消去对应图 2中的folding过程,它将Lustre- AST翻译至LustreF AST.Lustre-和LustreF的语法相近,只是后者没有了时态算子(arrow和fby).在对arrow和fby进行翻译时,需要引进两种变量:一种是自定义变量,作为缓存变量存在用来保存上个周期的值;另一种是标志变量,区别为是否第1个周期.
arrow的翻译相对简单,我们将lh=a1→a2翻译为lh=if flagid then a2 else a1,其中,flagid为标志变量.对于fby的翻译,则需要保存上一周期的值,我们将lh=a1 fby a2翻译为两个等式:
lhs=if flagid then preatom else a1
…
preatom=a2
其中,第2个等式preatom=a2比较特殊,将它放在所有其他等式的后面,这样做才能保证语义的等价性,其作用主要是用来保存上一个周期的值.这样的翻译给证明带来了困难,翻译不再是线性到线性的对应翻译,而是线性的翻译到两段隔开的程序,因此在证明中需要额外的定义来描述分割的程序.
需要证明的从Lustre-到LustreF翻译的语义保持性与之前S-Lustre*到Lustre-的语义保持性定理类似,此处不再赘述.
图 2中的translation过程将LustreF AST翻译到Clight AST,后者可输出为C代码.
从LustreF到Clight的翻译难度不大,但语义保持性证明较为困难,工作量也较大.为了可以直接使用CompCert项目中的Clight语义定义,需要在执行方式、特别是存储模式方面进行很好的适应.
时钟归一化(对应图 2中的Clock-Normalizing过程)可以消去程序中的when算子,使得从Clock-Normalized Lustre*开始往后的中间语言程序中只含单一时钟,即,默认的全局时钟.这使得后续的翻译阶段有所简化,特别是使之后各个阶段的翻译正确性证明大大降低了难度.
从任意一个时钟转化到默认全局时钟的基本思路是:
首先,把每个子表达式expr的时钟用一个基本时钟的数据流cc表示出来.为了方便,称cc为expr的时钟流.举个例子,如果expr_a的时钟为when (c when d),那么这个数据流的时钟流为cc_a=if d then c else false.
其次,定义一个运算cur,它将任意时钟的数据流转化到基本时钟的数据流.假设有一个数据流expr,其本来的时钟流为cc.将expr本身的定义扩展到任意时钟周期上.再定义一个新的数据流y=if cc then expr else pre y.它们之间的关系示意:

先定义一个cf'=true→(pre cf') and not (pre cc),有:
cf' t t t t f f f f f f f f f f f ...
然后,再由它得到cf=cur(cf',cc)即可.
目前已完成一个原型系统,用于验证这个时钟归一化算法.首先定义了一个具有代表性的小语言,然后定义该语言的一种并发操作语义,然后证明这一算法满足语义保持性.整个过程已在Coq中实现.
图 2所示的Type-Checking过程除了传统的静态语义检查以外,还包括时钟演算、因果性以及初始化等检查工作.这个过程的正确性主要是确保类型检查后的Well-Typed Lustre AST满足这些语义规则所刻画的性质,同时,这些处理前后需保持所处理程序信息的完整性.
在目前的实现中,有关因果性检查的部分是在Sequentializng阶段完成的.有关普通类型检查和时钟演算的内容,包含正确性证明也已经完成.然而,这个阶段,包括后续的Pre-processing,Clock Normalizing以及Sequentializng等阶段的正确性证明工作还没有连贯起来.在此之前,需要先完善并发操作语义的工作.
对于不包含when,FBY以及array的Lustre*语言(见附录A),目前已实现如图 2总体设计所描述的完整编译过程,并且从串行化(等式粒度)开始的各阶段的翻译正确性证明均已完成.Parsing阶段直接通过OCaml代码实现,其余阶段都在Coq工具中实现,包含各阶段的语法、语义、翻译过程以及翻译正确性证明.从翻译过程相关的Coq代码抽取的OCaml代码、Parsing阶段的OCaml代码、驱动及配置相关的OCaml代码联编后,生成一个完整的编译程序.
在目前的工作基础上,扩充对FBY、高阶运算以及array的支持即可满足安全关键系统开发的要求.相关的产品化工作正在进行中,企业方已完成一个扩展语言的编译器试用版本(扩展部分仅完成了翻译过程,验证工作正在进行),2012年9月开始在非安全级系统中进行降级试用,所生成的代码由质量监督部门通过人工代码审核、与国外同类复合航空标准的生成工具(SCADE)对比及大量测试实验等方法进行对比,至今表现优秀,没有发现任何与编译过程相关的错误.
从研究角度来看,正在进行的工作还包括完善并发操作语义定义,并将Type-Checking,Pre-processing,Clock Normalizing以及Sequentializng等阶段连贯起来.相关原型系统已基本完成.
未来我们将进一步扩充Lustre*的语言成分,完成对高阶运算、数组及FBY算子的验证工作,并与企业方合作完成产品的验收工作.
本文对正在开展的同步数据流语言Lustre*到C的可信编译器项目进行了介绍.该编译器的核心翻译过程借助辅助定理证明工具Coq,经过严格的形式化验证.已完成的部分在扩充数组、高阶运算和FBY时态运算之后能够满足国内安全关键领域的实际需求.相关研究工作在某些方面取得了突破.
致谢 在此,我们向对本文的工作给予支持和建议的同行表示感谢.
| [1] | Knight JC. Safety critical systems: Challenges and directions. In: Proc. of the 24th Int’l Conf. on Software Engineering (ICSE 2002). IEEE Xplore, 2002. 547-550 . |
| [2] | Milner R. Calculi for synchrony and asynchrony. Theoretical Computer Science, 1983,25(3):267-310. |
| [3] | Halbwachs N. Synchronous programming of reactive systems, a tutorial and commented bibliography. In: Proc. of the 10th Int’l Conf. on Computer-Aided Verification (CAV’98). LNCS 1427, Springer-Verlag, 1998 . |
| [4] | Halbwachs N. A synchronous language at work: The story of Lustre. In: Proc. of the 2nd ACM/IEEE Int’l Conf. on Formal Methods and Models for Co-Design (MEMOCODE 2005). Washington: IEEE Computer Society, 2005 . |
| [5] | Benveniste A, Caspi P, Edwards SA, Halbwachs N, Le Guernic P, de Simone R. The synchronous languages twelve years later. Proc. of the IEEE, 2003,91(1):64-83 . |
| [6] | Berry G, Gonthier G. The esterel synchronous programming language: Design, semantics, implementation. Science of Computer Programming, 1992,19(2):87-152 . |
| [7] | Berry G. The foundations of esterel. In: Proc. of the Proof, Language and Interaction: Essays in Honour of Robin Milner. Cambridge: The MIT Press, 2000. 425-454. |
| [8] | Caspi P, Pilaud D, Halbwachs N, Plaice J. Lustre: A declarative language for programming synchronous systems. In: Proc. of the 14th ACM Symp. on Principles of Programming Languages (POPL’87). New York: ACM, 1987 . |
| [9] | Halbwachs N, Caspi P, Raymond P, Pilaud D. The synchronous dataflow programming language LUSTRE. Proc. of the IEEE, 1991,79(9):1305-1320. |
| [10] | Le Guernic P, Gautier T, Le Borgne M, Le Maire C. Programming real time applications with SIGNAL. Proc. of the IEEE, 1991, 79(9):1321-1336 . |
| [11] | Le Guernic P, Talpin JP, Le Lann JC. Polychrony for system design. Journal for Circuits, Systems and Computers, 2003,12(3): 261-304 . |
| [12] | http://gcc.gnu.org/ |
| [13] | http://www.plumhall.com/stec.html |
| [14] | http://www-verimag.imag.fr/Lustre-V6.html |
| [15] | Yang XJ, Chen Y, Eide E, Regehr J. Finding and understanding bugs in C compilers. In: Proc. of the 2011 ACM SIGPLAN Conf. on Programming Language Design and Implementation (PLDI 2011). New York: ACM, 2011.283-294 . |
| [16] | http://www.esterel-technologies.com/products/Scade-suite/ |
| [17] | http://www.commoncriteriaportal.org/cc/ |
| [18] | Summary of difference between DO-178B and DO-178C. http://faaconsultants.com/html/do-178c.html |
| [19] | McCarthy J, Painter J. Correctness of a compiler for arithmetical expressions. In: Proc. of the Symposia in Applied Mathematics, Vol.19: Mathematical Aspects of Computer Science. Washington: AMS, 1967. 33-41. |
| [20] | Milner R, Weyhrauch R. Proving compiler correctness in a mechanized logic. In: Proc. of the 7th Annual Machine Intelligence Workshop, Vol.7. Edinburgh: Edinburgh University Press, 1972. 51-72. |
| [21] | Dave MA. Compiler verification: A bibliography. ACM SIGSOFT Software Engineering Notes, 2003,28(6):2-5 . |
| [22] | Leroy X. Formal verification of a realistic compiler. Communications of the ACM, 2009,52(7):107-115 . |
| [23] | Chlipala A. A certified type-preserving compiler from lambda calculus to assembly language. In: Proc. of the 2007 ACM SIGPLAN Conf. on Programming Language Design and Implementation (PLDI 2007). New York: ACM, 2007.54-65 . |
| [24] | Klein G, Nipkow T. A machine-checked model for a Java-like language, virtual machine, and compiler. ACM Trans. on Programming Languages and Systems, 2006,28(4):619-695 . |
| [25] | The Coq Development Team. The Coq proof assistant reference manual. Version V8.3, 2010. http://coq.inria.fr/ |
| [26] | Bertot Y, Castéran P. Interactive theorem proving and program development—Coq’art: The calculus of inductive constructions. In: Proc. of the Texts in Theoretical Computer Science. Springer-Verlag, 2004. |
| [27] | Morrisett G, Technical perspective: A compiler’s story. Communications of the ACM, 2009,52(7):106-106 . |
| [28] | Pnueli A, Siegel M Singerman E. Translation validation. In: Proc. of the TACAS’98. LNCS 1384, Springer-Verlag, 1998. 151-166. |
| [29] | Pnueli A, Shtrichman O, Siegel M. Translation validation for synchronous languages. In: Proc. of the ICALP’98. LNCS 1443, Springer-Verlag, 1998.235-246 . |
| [30] | Ngo VC, Talpin JP, Gautier T, Le Guernic P, Besnard L. Formal verification of synchronous data-flow compilers. Project-Team ESPRESSO Research Report, No.7921, 2012. |
| [31] | Ngo VC, Talpin JP, Gautier T, Le Guernic P. Formal verification of transformations on abstract clocks in synchronous compilers. Project-Team ESPRESSO Research Report, No.8064, 2012. |
| [32] | Ngo VC, Talpin JP, Gautier T, Le Guernic P, Besnard L. Formal verification of compiler transformations on polychronous equations. In: Latella D, Treharne H, eds. Proc. of the IFM 2012. LNCS 7321, Springer-Verlag, 2012.113-127 . |
| [33] | Dutertre B, de Moura L. The YICES SMT solver. 2009. http://yices.csl.ri.com |
| [34] | Tristan JB, Govereau P, Morrisett G. Evaluating value-graph translation validation for LLVM. In: Proc. of the 32nd ACM SIGPLAN Conf. on Programming and Language Design Implementation (PLDI 2011). New York: ACM, 2011.295-305 . |
| [35] | Paulin C, Pouzet M. Certified compilation of Scade/lustre. 2006. https://www.lri.fr/~paulin/lustreincoq.pdf |
| [36] | LUCID SYNCHRONE home. http://www.di.ens.fr/~pouzet/lucid-synchrone/ |
| [37] | Bertails A, Biernacki D, Paulin C, Pouzet M. A certified compiler for the synchronous language Lustre. In: Proc. of the TYPES 2007. 2007. http://users.dimi.uniud.it/types07/slides/Bertails.pdf |
| [38] | Biernacki D, Colaco JL, Hamon G, Pouzet M. Clock-Directed modular code generation of synchronous data-flow languages. In: Proc. of the ACM Int’l Conf. on Languages, Compilers, and Tools for Embedded Systems (LCTES). New York: ACM, 2008 . |
| [39] | Biernacki D, Colaco JL, Pouzet M. Clock-Directed modular code generation from synchronous block diagrams. In: Proc. of the Workshop on Automatic Program Generation for Embedded Systems (APGES 2007). New York: ACM, 2007.78-89 . |
| [40] | Blazy S, Leroy X. Mechanized semantics for the Clight subset of the C language. Journal of Automated Reasoning, 2009,43(3): 263-288 . |
| [41] | http://www-verimag.imag.fr/DIST-TOOLS/SYNCHRONE/lustre-v6/doc/lv6-ref-man.pdf |
 | |