 2014, Vol. 25
2014, Vol. 25



2. 淮海工学院 计算机工程学院, 江苏 连云港 222005
2. School of Computer Engineering, Huaihai Institute of Technology, Lianyungang 222005, China
微博作为目前最为流行社会媒体,为公众传递信息、参与话题讨论、表达自己的见解提供了前所未有的服务功能.微博网络是一种包含多种复杂实体关系的新型网络,它之所以有别于以往博客、论坛等传统网络平台,在于其构建了一种新的交互关系,即关注(follow)关系.所谓关注关系是指一个用户通过对其感兴趣的用户标注“关注”而形成的关系.通过关注关系,用户可即时获得他所关注用户的博文.关注关系为信息流动构建了强大的管道,使微博链式信息推送变得格外强劲.由于关注关系的引入,微博网络不同于现实中的其他网络结构,并显著区别于传统的用户-话题二部网络,因此被视为多模网络.目前,从多模网络的视角研究微博社群关系的研究尚不多见.微博上的 社群结构体现为典型的重叠社群模式——用户依据自身的话题兴趣和人物关注关系同时参与多个不同的社群,通过关注关系接受特定用户的博文,参与特定话题的转发与评论.由于用户关注的用户与话题又是多方面的,由此形成了多个社群共同参与的微博网络关系.
微博现象在学术界引起了关注,吸引研究者从不同角度开展相关的研究工作,包括微博网络结构特征[1,2]、社群特征[3, 4, 5]、意见领袖发现、消息传播与舆情演化等.Zhang等人[3]利用反映用户兴趣的文本内容、社会结构等特征来计算不同微博用户间的相似性,并利用K-means聚类识别微博群体.Tang等人[4]利用基于正则化时间的多模型聚类算法发现动态的网络群体.而Yu等人[5]使用归一化切割方法(normalized cut)求解模块化聚类并解决群体发现问题.Huberman等人[6]从微观角度结合马尔可夫链和聚类算法将微博用户划分为不同社群.Gao等人[7]以用户作为节点、关系作为边,利用MSCC(maximal strongly connected components)方法将微博用户划分为具有不同拓扑结构的社群,并且在不同用户社群上对用户的关系形成进行了分析.
在重叠社群发现研究方面,Palla[8]于2005年首先讨论了重叠社群发现问题,提出通过滚动K-完全图发现重叠社群的CPM(clique procolation method)方法.文献[9]提出了一种能够探测层次化社群结构的凝聚算法BGLL.文献[10]同样提出了一种用于探测社群结构重叠性的算法CONGA.文献[11]没有单纯从网络节点及其连接关系的角度出发,转而将个体-话题关系弧转化为图节点,把用户-话题二模网络转化为以个体-话题关系为节点,个体-话题相似性表示节点链接度的加权单模网络社群分析模型,能够较自然地解释和发现重叠社群,为重叠社群发现提供了 新的思路.OSLOM[12]则基于求解节点度统计量局部最优的图聚类算法,尽管能够实现重叠社群的发现,但因其计算复杂性而难以应用于大规模网络.
在社群形态的定性研究方面,Gruzd等人[13]认为,微博用户虽然处于一种虚拟网络社群之中,但这些虚拟社群能够体现用户的真实社会关系,提出微博社群具有成员性、影响性、整合需求性及分享性等特点.Java等人[1]通过研究Twitter网络的拓扑属性和地理属性,发现具有高度相关性或强互动性的用户会逐渐聚合形成群体. Ryan等人[14]的研究指出,社群核心用户会对整个社群的群体行为产生主导作用.
用户与话题热点的动态变化,是影响微博社群结构的主要因素.Kivran等人[2]通过对群体结构的动态分析,总结并提出了判断微博用户间关系持续性的因素.Meeder等人[15]利用时间戳信息分析微博社群的动态变化规律.Li等人提出了一种事件演化脉络识别框架(event storyline from microblogs,简称ESM)[16],该框架能够有效识别目标事件随时间演化所形成的话题脉络,从而更有利于分析网络社群的结构演化.Chen等人[17]针对微博文本的海量性和话题发散性特征,研究了基于动态伪相关反馈思想的微博话题提取方法.袁毅等人[18]通过跟踪微博用户在时间周期内就某一话题的交流数据,发现用户在信息交流过程中形成关注、评论、转发和引用等4种社会关系网络,研究了4种关系网络不同的结构形态.Teutle等人[19]则从网络动态性角度对Twitter进行分析,包括出入度增长、网络密度和介数等参数在微博网络中的变化等.
隶属矩阵(belongingness matrix)是表达个体相对于聚类隶属度的常用方法[8, 20, 21],其中,隶属矩阵的每行代表一个个体,行的第i个(非负)分量代表个体对第i类的隶属度,总和为1.隶属矩阵为定量研究重叠聚类结构及变化提供了定量表达方法,但是在面对真实社会网络时,该表示方法存在明显缺陷.主要体现在隶属矩阵要求“所有个体的社群隶属度和全为1”的限制,即个体对所有社群贡献的总和相等.该限制使其无法真实反映现实网络中个体的行为差异.例如:微博“意见领袖”博文的质与量及与其他用户的交互程度都与普通用户不同;而学术合作网中,著名学者对合作网络结构及变化的影响力也与一般学者显著不同.如果简单地将网络划分为若干社群,并给每个用户赋以等同社群隶属和值,则无法体现个体在网络中的实际地位和作用.如何恰当地描述个体在网络社群中的地位和关系以真实反映个体在网络中的角色,对网络社群研究发挥重要作用.
总之,微博网络重叠社群研究对于揭示这一新型社交网络内在结构及其演化规律,提高对显著影响微博网络演化关键节点和要素的识别能力具有重要意义.因此,微博网络重叠社群发现及其表示框架是本文研究工作的着眼点,主要创新点在于:
(1) 提出将用户-话题连接关系作为维系微博网络的关键节点集,用户-话题对间相似关系为连边的加权多模网络结构模型.通过综合考虑个体对话题兴趣和对特定用户的关注关系,实现网络重叠社群结构的发现,能够真实反映网络用户的社群多重性;
(2) 研究了微博多模网络实体间相似关系度量方法,全面覆盖该网络各类实体间的内在联系,并基于优势集聚类给出社群发现方法,实现以话题群-用户群为社群划分标准的重叠网络社群.所提出算法具有类团核心性度量功能,能够实现社群核心成员的发现;
(3) 在分析现有隶属矩阵表示方法不足的基础上,提出新的能够反映个体对网络全局参与度与社群核心度的隶属矩阵表示方法.新的隶属矩阵表示模型是定量研究网络社群及其演化规律的基础. 1 微博网络上的实体关系 1.1 微博网络与用户的形式化描述
微博平台可以表示为如下的五元组:
W=(U,BLog,ET,EU,F,C) (1)
其中,U为全体用户的集合,U={u|uÎ注册微博用户},BLog为全体用户博文的有限集合.类似地,一条博文可以视为一个四元组:
BLogi={Bid BLogi_message,BLogi_topic,t} (2)
其中Bid为唯一标识符;BLogi_message为博文主体;t为发布时间;BLogi_topic为从微博内容中抽取的话题信息,需要通过专门的分析技术提取获得.由于用户发表的博文可能很多,不妨对一个用户的全部博文加以分析,从而抽取出其博文关注的主要话题信息.实验中,将一个用户博文的全部话题限制在10个以内.
定义ETÍUxT为全体用户到其发表博文所属主题的连接弧的集合:
ET={e=(ui,tj)|uiÎU,tjÎT} (3)
而EUÍUxU为用户通过加关注所形成的连接关系集.这里,关注关系是从关注者i到被关注者j的有向弧.
EU={ui¬uj|uj follows ui} (4)
集合EU存在一个虚拟伴随集,记为![]() ,它是由用户j关注用户i所形成的被
,它是由用户j关注用户i所形成的被
关注关系.在观察一个具体用户(例如i)时,这一虚拟边集合可以方便地计算用户i的粉丝数.
定义FÍUxBLog为由全体用户与其所转发博文之间关系的集合:
F={(ui,BLogj)|uiÎU,ui forwarded BLogj} (5)
定义CÍUxBLog为由全体用户与其所评论的博文之间关系的集合:
C={(ui,BLogj)|uiÎU,ui commented on BLogj} (6)
与微博平台的表述类似,可以进一步定义微博用户为七元组:
u=(BLog,Topic,Follow,Followed,forward,Comment,t) (7)
其中,u.BLog为用户发表的博文集,u.Topic为从该用户u.BLog中学习获得的话题集,u.Follow为用户关注的其他用户集,nFollow=|u.Follow|为关注用户数,u.Followed为关注该用户的其他用户集,nFollowed=|u.Followed|为被关注用户数(粉丝数),u.forward为用户转发其他用户的博文合集,u.Comment为其评论博文集,t为用户注册时间. 1.2 微博网络中的实体关系模型
现实世界中,许多网络都可以表征为二部图(bipartite graph network)结构.如演员合作网中的演员-电影关系,科学研究中的共同发表论文关系等.二部图由两类性质不同、互不相交的节点构成:一类称为用户节点集X,另一类称为事件节点集Y(如图 1(a)所示),且同一个集合内的节点间无连边.即,X中元素可与Y中元素间存在连边,但X或Y内部节点间均无连边.由于只在不同类型节点间存在连边,二部图网络中不存在三角关系.
传统意义上,用户-话题二部图网络能够描述十分丰富的网络模型,如科研合作网络等.但是微博网络关系表现更为复杂,这是因为用户间可以用他们的博文作为联系的纽带,通过对博文的推送、转发和评论形成按话题的社会关系.同时,用户之间还存在关注与被关注关系,即使是关注某个用户,也并不意味着关注他所发表的全部话题,而是有选择地加以阅读、评论和转发.因此,本文研究将其拓展为融合多种实体关系的多模网络.微博网络上的社会关系可如图 1(b)所示.
 | Fig. 1 Illustration of a Bi-mode network and the micro-blog multi-mode network 图 1 简单的二部网络(a)与微博多模网络(b)示意图 |
图 1(b)中,4个微博用户的话题集包含话题1~话题k,可以构成标准的话题-用户二部图.但同时,4个用户间还存在关注与被关注关系.此外,网络中还存在用户对特定博文的转发、评论关系(未在图中标识).显然,微博网络的这种复合关系无法直接转化为单模网络.如何综合考虑用户节点的话题属性和用户间的关注属性,既在统一的框架下解决微博社群发现问题,又能恰当刻画节点在社群中的地位,是本文研究的关键问题.它显著区别于传统的二部网络领域的研究工作.
为此,本文拓展文献[11]将二模网络转化为单模加权网络的研究方法,通过综合权衡微博网络中存在的多种实体关系,以最基本的用户-话题关系为主线,综合考虑关注、评论与转发关系,构建该复杂多模网络向单模加权网络的映射方法,并据此实现微博网络上的重叠社群发现.
首先给出描述微博网络的图表示为:微博网络图G=(V,E)是一个复合图,其中,节点集V=UÈT满足UÇT= Æ,U为全体用户节点的集合,T为全体用户博文所涉话题的集合,T={t1,…,tm}.连边集E=ETÈEU,ETÇEU=Æ.其中,连边集ET为用户节点到其微博所涉话题节点的连边,它可以视为一个映射函数ET:UxT®{0,1},即:
![]() (8)
(8)
连边集EU是全体用户间由关注(follow)而引发的关系集,即EU:UxU®{0,1},满足:
![]() (9)
(9)
定义1. 给定图G中用户-话题关系集合ET中的任意两条连边eip(ui,tp)和ejq(uj,tq),其相似度定义为
sim(eip,ejq)=a×sim(ui,uj)+(1-a)sim(tp,tq) (10)
上述定义将两条用户-话题连边之间的相似关系定义为对应用户之间的相似度与话题之间相似度的线性组合,a(0<a<1)为权重调节系数.这既考虑了话题间的接近程度,同时又兼顾了用户间的同质性,具有现实意义与理论上的合理性.
值得注意的是,由于e(u,topic)是用户与话题间的连边,因此既存在多个用户联向同一话题的连边,又存在一个用户向多个不同话题的连边.前者对应于多个用户博文涉及同一话题,而后者对应于一个用户博文涉及多个不同话题域.正是由于多对多的关系,为发现重叠社群提供了可能.为了实现诸如公式(10)所定义的用户-话题相似度计算,以下分别讨论用户相似度与话题相似度的定义与计算方法. 1.3 博文话题相似性度量
为了建立用户博文间的相似性,首先必须从博文中提取相应的话题.有关文本话题提取的方法主要有TF-IDF算法[22]和LDA算法[23]等,在此不再赘述,仅假设通过对用户博文集的分析处理获得了用户的话题集.然而对于海量的微博用户,简单汇聚所有用户的话题形成用户话题集显然将非常庞杂并存在大量冗余.为此,可以利用话题间的语义相似性和概念聚类方法对用户话题集加以压缩,形成规模适度的话题集.
事实上,虽然存在海量的用户共享着微博网络,其话题也涉及现实社会生活各个领域,但从统计学角度看,网络用户所涉话题同样符合幂率分布,即少量热门话题吸引了大量用户,而大量冷门话题则相对稳定地只被少数人关注.因此,可以利用话题语义间相似性实现话题压缩,将博文所涉主要话题控制在一定范围内.
设T为从全体用户博文中提取的主题词集,T={t1,…,tn},![]() 为由T中话题组成的隐语义网络空间的基,则对网络中任一个体u,其所涉话题子集uT={ti1,…,tik}可通过如下映射转化为T*中的话题子集:
为由T中话题组成的隐语义网络空间的基,则对网络中任一个体u,其所涉话题子集uT={ti1,…,tik}可通过如下映射转化为T*中的话题子集:
![]() (11)
(11)
奇异值分解(singular value decomposition,简称SVD)方法是常用于实现上述话题集压缩映射的有效工具.设m阶对角矩阵S的全体对角元素为由话题词t1,…,tn构成的语义相似矩阵的前m个特征值,L与R为相应的左右奇异特征向量组成的矩阵,则有M=LSRT.此时,![]() .于是,
.于是,
![]() .
.
这里,uT(ti1,…,tik)与![]() 分别为用户话题在原话题空间及其在压缩空间中的映像.考虑到微博话题的发散性和高动态性,微博话题选择与时间跨度之间应建立一定的联系.根据Dumais等人的研究[24]:随时间跨度的不同,微博热门话题可选择在50~1000范围内.因此,本文实验中将话题总数控制在100个范围内.
分别为用户话题在原话题空间及其在压缩空间中的映像.考虑到微博话题的发散性和高动态性,微博话题选择与时间跨度之间应建立一定的联系.根据Dumais等人的研究[24]:随时间跨度的不同,微博热门话题可选择在50~1000范围内.因此,本文实验中将话题总数控制在100个范围内.
根据上述讨论,两个用户讨论的话题尽管可能略有不同,但当对话题进行高度浓缩后,这些细微的差异已无法区分.因此,公式(10)中两话题的相似度定义为
![]() (12)
(12)
以下讨论用户博文所涉话题时,均假设其为对全体用户博文集话题经奇异值分解压缩后的话题集合. 1.4 用户关注相似性度量
本节从用户行为的维度探讨其与微博社群结构形成该关系.袁毅等人[18]通过跟踪微博用户在特定时间周期内的话题交流数据,发现用户在信息交流过程中形成关注、评论、转发和引用这4种关系网络,指出4种网络具有不同的结构形态. Teutle等人[19]则从网络动态性的角度对Twitter加以分析,包括出入度的增长、网络密度和介数等参数来描述微博网络特征.本文依据文献[18]的相关结论,综合构造用户行为相似度的描述方法.
关注网络是由用户间因关注关系而构成的级联式网络.由于博文随关注关系自动即时到达一级关注用户,因此信息传播快,关注网络通过关注对象的转发、引用和评论而使信息进一步转播给各自的关注用户,形成更大的多级关注网络.转发网络是在时间周期内用户间因博文转发形成的网络,其规模远比关注网络小得多.这是因为关注用户中仅有一部分对当前博文内容具有转发动机,其他关注者对当前博文并不感兴趣,转发大多发生在一次范围内,二次转发衰减显著.评论网络是通过对博文评论形成的关系网络,其规模更小于转发网络,说明用户更愿意做较为省力的简单转发而不加评论,只有当用户对话题具有更大兴趣时,才会加以评论[18].
以下着手构建用户行为维度上的相似关系度量.首先,两用户间的关注对象集的交叠性反映了其在社会网络中社群角色的异同.因此,基于关注关系的用户相似性度量可以如下定义:
定义2. 设ui,ujÎU为微博用户,ui.Follow,uj.Follow分别为ui,uj的关注对象集,而ui.Followed,uj.Followed分别为ui,uj的粉丝集,则ui,uj的关注相似度为
![]() (13)
(13)
式(13)右端第1项表示两用户共同关注用户在他们关注的所有用户集的比例,而后者表示两者的粉丝集内共同粉丝所占的比值.显然,前一指标值越大,说明他们在网络上共同关注的对象越相似;而后一项指标越大,则说明其被同一群人追捧的程度越高.公式(13)通过调节bÎ(0,1)的值,调整关注行为和被关注状态在用户相似度中的比值.由于“关注”属于用户的自主行为,因此其在自我认同中的比重较大.本文实验中,选取b=0.6. 1.5 转发和评论关系引入的用户-话题相似性增量
由用户间转发和评论行为所引起的相似性既不能简单归结到用户间的相似性,也不能视为用户间的话题认同.这是因为一个用户未必会转发或评论另一个用户涉及所有话题的博文,而只会就自己感兴趣的话题博文进行转发或评论.因此,转发或评论反映的是两用户间感兴趣话题上的相似性.为此,可以采用以下策略在考虑用户-话题相似性时加入用户转发、评论的因素:
定义3. 设用户ui转发了用户uj话题为tp的博文,即:存在ui的某篇评论ui.commentlÎui.cmt,使得uj.tpÎ (ui.cmt).t,则按以下策略定义一对用户-话题弧间的评论相似性增量sim(eip,ejq):
 (14)
(14)
其中,(uj.cmt).topic表示uj所有评论所涉及话题的集合.
上述相似性定义策略的含义是:如果ui评论用户uj话题为tp的博文,而其本身也是话题tp的博文原创者(即tq=tp),则可不需考虑这一转发关系,直接设置该对用户-话题弧的话题相似度为1;反之,尽管tq¹tp,但因ui评论了话题为tq的博文或uj评论了话题为tp的博文,这种评论关系反映该对用户话题弧上两用户间在话题上具有相似的兴趣,因此提高了这对用户-话题弧的相似度.最后,如果两用户间不存在相同话题的评论关系,则该对用户-话题弧的话题相似度为0.公式(14)中,本文用参数dcmt调节因评论关系形成的相似度增量.
同样地,对用户参与其他用户博文的转发行为也可以采用类似的策略,在一对用户-话题弧的话题相似关系上通过设置参数dfwd加以体现.
综合公式(12)~公式(14),由公式(10)形式定义的用户-话题关系对eip和ejq之间的相似度最终定义为
sim(eip,ejq)=a×sim(ui,uj)+b(1-a) (15)
其中,b的取值可分为如下几种情况:
(1) 当tq=tp时,b=1;
(2) 当tq¹tp,但ui或uj评论且转发对方弧上对应的话题时,b=dfwd+dcmt;
(3) 当tq¹tp,但ui或uj评论或转发对方弧上对应的话题时,b=dfwd或b=dcmt;
(4) 当tq¹tp,ui,uj不存在对方弧上对应的话题的评论或转发,b=0.
显然,用户对博文发表评论较之简单转发更能反映其对相关话题的兴趣度.因此,实验中将由转发和评论行为导出的用户-话题相似度调节系数dfwd,dcmt分别设为dfwd=0.25,dcmt=0.5. 2 微博网络重叠社群发现 2.1 基于优势集划分的加权图聚类方法
优势集(dominant set)聚类是由Pavan和Pelillo首次给出确切定义的图聚类方法[25],该方法源于聚类直觉观念和主导集合之间的类比关系,优势集将最大类团的概念推广到边赋权图中.文献[26]则证明了优势集检测与标准单纯形的二次规划极大值问题之间的对应关系,使得算法可应用连续最优技术,并可在局部交互计算单元的并行网格上简单实现.本文采用优势集聚类的方法主要基于两点考虑:(1) 该方法具有扎实的理论基础,并能够清晰地反映网络图上节点的类团隶属关系;(2) 在实现类团划分的同时还标识了节点在类团中的核心度,具有描述网络个体角色属性的便利.以下我们给出基于优势集聚类算法实现上述用户-话题连接关系为节点的加权图聚类相关的定义与算法过程.
给定无向加权图W=(ET,L),其中,节点集ET为由公式(10)定义的用户-话题关系集,L为由公式(15)定义的用户-话题对间相似度构成的加权边.而全体边上的权值构成用户-话题关系集上的相似矩阵A=[aij]:
aij=sim(ei,ej),ei,ejÎET (16)
定义4. 设S为ET的非空子集,ET中任意元素eiÎET相对于子集S的平均权值相似度定义为
![]() (17)
(17)
注意到,由于图ET中不存在自连边,因此有![]() .进一步地,对ejÏS,定义:
.进一步地,对ejÏS,定义:
jS(ei,ej)=aij-dgS(ei) (18)
定义5. 设S为ET的非空子集,则S中任意元素ei相对于S的权定义为
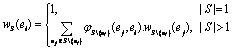 (19)
(19)
S的总权值定义为
![]() (20)
(20)
根据上述定义,wS(ei)的计算过程仅需在由S导出的子图上进行.值wS(ei)直观地表示在S中添加节点ei前后该集合平均相似度的变化情况.
定义6. 非空子集S称为优势集,如果该集合满足以下两个条件:
(1) 对S中的每个元素ei,均有wS(ei)>0;
(2) 对任意的eiÏS,![]() .
.
定义6描述了类团的两个基本特征,即,类团内部同质性及类团成员与外部个体的异质性.它说明:如果在S加入某个节点ei后,集合S仍然保持为同质的,则可以认为该点是类团成员;否则,应剔除该节点.
根据文献[26]的证明,在加权图上寻找优势集的问题可以转化为求解标准单纯形二次型极值问题:
![]() (21)
(21)
其中,D={xÎRn,x≥0,||x||=1}.上述单纯形上求解二次型极大值问题可转化为繁殖方程法求解:
![]() (22)
(22)
其中,ui(t)是向量x(t)的分量,t为迭代步数.迭代结果值的大小,表示分量对应的节点属于当前类团的可能性.向量ui(t)的支持集即为优势集对应的顶点,每一分量ui(t)对应原图中节点集ET中一个节点的特征向量,数值越大的分量之间相似性越高.因此可以利用该信息,按照ui(t)值从大到小对原始节点排序,直到完成当前类成员的搜索.基于优势集的图聚类算法描述见算法1.
算法1. 优势集聚类算法(dominant sets clustering algorithm).
输入:图G的节点集和节点间的相似度矩阵A;
输出:类团及成员列表.
1. 初始化Ak=A,k=1
2. 利用迭代方程(22)求解方程(21)获得解uk
3. 计算f(uk)的值
4. 求解uk对应的特征向量获得矩阵对应行向量,输出为clusterk=r(uk)
5. 从矩阵Ak中删除clusterk元素对应的行和列,形成新的相似矩阵Ak+1
6. 若Ak+1不为空矩阵,Ak¬Ak+1,k=k+1;转步骤2
7. 否则,程序终止. 2.2 用户-话题重叠社群发现
尽管算法1将节点划分为互不重叠的类团,但这些节点事实上包含的是用户与其博文话题之间的连接信息.因此,仍需将类团的节点转化为对应的用户-话题关系,从而可得到该类团相应的社群信息.
给定类团S={e1,…,ek},将节点集转化为用户-话题关系后的集合为S={(ui,ti),i=1,…,k},于是可得社群用户集
为![]() ,S的话题集为
,S的话题集为![]()
显然,由此得到的用户话题关系集是一个多用户、多话题复合集,且TS中存在重复话题,通过剔除重复项,即可得到一个社群涉及的话题集.当然,判别算法的有效性在于检验所发现的社群是否包含相对集中的话题.
注意到:在对用户的博文进行话题聚合时,每个用户涉及同一话题的连边进行了归并.因此,通过预处理后得到的用户-话题数据中,每个用户相对于一个话题要么没有连接关系,要么仅有一条连接.但当类团中存在多个话题时,同样存在用户的重复,也需要加以剔除.
以下总结并给出完整的用于面向用户-话题复合网络的重叠社群检测模型(overlapping community detection on multi-mode network,简称OCDM)的完整步骤如下:
输入:有限用户集U,微博网络W=(U,Blog,ET,EU,F,C);
输出:用户-话题(重叠)社群列表、每个社群核心成员集.
1. 对每个用户ui,从ui.BLog博文集合中提取用户话题集Ti(本文采用TF-IDF算法)
2. 对全体话题集![]() ,采用SVD算法压缩形成新的全局话题集T
,采用SVD算法压缩形成新的全局话题集T
3. 依据话题集T,剔除用户-博文关系中重复连接,压缩形成用户-话题关系集Et
4. 依据公式(12)~公式(14)计算Et中元素的两两相似度,构建加权网络W=(ET,L).
5. 采用DS-Cluster算法划分W=(ET,L)上的类团{Si}.
6. 剔除Si中的重复话题和重复用户,依次输出用户-话题社群Si.
7. 采用颜色标注算法提取每个重叠社群Si的核心成员集. 3 网络社群隶属关系的全局表示
以上我们研究了微博网络上的重叠社群发现问题.为了从全局层面上研究所有社群及其个体的演化行为,必须给出网络成员相对于社群的隶属关系.
隶属矩阵是表达个体相对于聚类隶属度的常用方法[8,20,21].在隶属矩阵中,每行表示一个数据对象,而每列代表一个聚类.于是,可将N个成员相对于k个类团的隶属关系表示为如下的形式:
![]() (23)
(23)
上述隶属矩阵表达方法在描述空间数据点对重叠聚类的隶属关系时具有合理性,这是因为在聚类时每个点在数据集中的地位是等同的,不存在数据对象在聚类中地位的差异.但是,直接将这种描述方法应用于现实网络中的社群关系描述则具有明显的缺陷.以下我们以微博网络为例,说明公式(23)在描述个体社群隶属关系时的不合理性.
假设用户A是微博网络的积极参与者,并在3个社群S1,S2,S3中因博文数、被关注数、被评论和转发数领先而具有核心地位.显然,该用户应成为网络社群中的重点研究对象.但从社群隶属关系来说,由于该用户同时是多个社群的成员,因此在总隶属度值为1的限制下,该用户在3个社群中的平均隶属度只有1/3.再假设用户B仅是社群S1的普通用户,在社群划分时仅被归入S1.根据前述,则B对社群S1的隶属度为1,远远高于用户A对该社群的隶属度.在研究社群演化时,如果B在下一时刻离开社群S1而加入到社群S2,则在两个相邻的隶属矩阵视图间,用户B对应的分量从(1,0,0,…)转化为(0,1,0,…).显然,个体B的社群隶属度变化导致的演化异动量较之个体A要显著得多,这一情景体现了传统隶属矩阵描述方式的被忽略的不合理性.
为改进隶属矩阵表示方法的缺陷,有必要依据社群个体在社群中的差异性设计新的社群隶属度描述方法,以便真实反映个体对社群的隶属度及其社群地位.改进后的隶属矩阵表达模型应具备以下几项特征:
(1) 一个社群对整个社会网络的影响与其所包含个体的数量正相关,即社群规模越大,该社群的隶属矩阵总权值越大.事实上,有关网络社群的统计研究结果表明[1,2],网络社群在规模上符合幂率分布.即网络中存在少量的庞大社群,而绝大多数社群是局部的和小规模的;
(2) 个体在一个社群中的影响和地位与其在社群中的核心度存在正相关性.这一现象同样得到社会网络研究相关成果所证实,即网络社群中的少量个体对社群结构起到关键作用(如节点的连接度),而大量其他个体通过他们而形成社群;
(3) 为了保持隶属矩阵的行归一性质,可假设在网络外部存在一个虚拟社群,使得除了网络中综合权值最大的个体对真实社群的隶属度和为1(相当于全力参与社会网络)外,其他个体因为参与这一虚拟社群(如与社会网络无关的学习工作等)而没有将全部的精力投入到实际网络中,其对实际社群的隶属度总和d<1,而对虚拟社群的隶属度为1-d.在研究社群演化时,通过对所有网络个体在实际社群的隶属度评价值自动调节d的大小,以反映每个个体对实际社群的综合影响力.
基于上述假设,我们给出改进后的网络社群隶属矩阵的定义如下:
定义7. 给定由N个成员组成的社会网络G及其上的k个社群S1,…,Sk,设|Sj|为第j个社群的成员数,而
![]() 为Sj成员ei的核心度权值,
为Sj成员ei的核心度权值,![]() .则社群Sj的全局影响力权值定义为log|Sj|,ei基于社群Sj的全局影响力权值定义为
.则社群Sj的全局影响力权值定义为log|Sj|,ei基于社群Sj的全局影响力权值定义为![]() .
.
根据上述定义,网络个体ei相对于全体社群的影响力向量可以表示为
![]()
定义8. 设e*为社会网络G中具有最大影响力向量和值的成员,即
![]() (24)
(24)
则定义G中全体成员的社群隶属度向量为
![]() (25)
(25)
其中,||×||1代表向量的1-范数(分量绝对值之和).
易见:经归一化后,除网络中全局影响力最大的网络成员e*的社群隶属度值之和![]() 外,其他成员的社群隶属度值之和均小于或等于1.
外,其他成员的社群隶属度值之和均小于或等于1.
定义9. 设![]() 为成员ei相对于全体k个社群的隶属度向量,
为成员ei相对于全体k个社群的隶属度向量,![]() ,称矩阵PÎ[0,1]Nx(k+1)为G的社群隶属
,称矩阵PÎ[0,1]Nx(k+1)为G的社群隶属
矩阵:
 (26)
(26)
其中,矩阵P的前k列由N个k维行向量![]() 给出,而最后一列为全体成员对前k个社群隶属度总和的剩余分量组成的列向量.
给出,而最后一列为全体成员对前k个社群隶属度总和的剩余分量组成的列向量.
由定义9给出的社会网络社群隶属矩阵在形式上与传统的表达方式保持一致,即矩阵元素非负性和行归一性.而改进后的隶属矩阵不仅能够反映个体相对于社群的隶属状态,同时能够更加真实地反映个体在社会网络中的地位和作用.在改进后的隶属矩阵中,每列仍代表一个社群,但其元素的取值不仅与社群的相对规模正相关,而且与个体在该社群的核心度正相关. 4 实验结果与讨论
本文以数据堂公司提供的微博用户数据5 000条用户数据集为基础[27],通过清洗并补充必要的相关用户数据,然后采用网络爬虫获取上述用户集的微博语料信息,系统地分析和论证本文模型和算法的有效性.
该数据集包含5 000个微博用户的用户名、关注用户数、粉丝数和发表的微博数等信息,同时还包含每个用户所关注的用户id列表.经去除无效用户及关注数、粉丝数、博文数小于10的用户后,有效用户信息为3 839条.由于该数据是发布者随机抽取的,其成员间相互加关注的比例极低(<7%),而大多数关注数最多的用户恰恰不包含在该数据集内,因此,如果不将这些被高关注用户纳入到数据集合中,就无法反映该用户集的真实关注关系.为此,从全体用户的关注列表中统计出前50名被关注数最多的外部用户加入到用户列表中(均为微博标V用户,3 839个用户对其总加关数6 460次.限于篇幅,所添加用户列表及关注统计信息表从略).此时,总用户数达到3 889名.
首先,设计程序利用新浪API接口从所有3889名用户的微博网页中抓取其2012年1月1日~2012年4月25日(该数据集采集时间为2012年4月23日~2012年4月25日)的全部博文数据和转发、评论信息,所得语料总规模约47.5万条(去除了与本数据集无关的其他用户相关博文信息).
首先,采用本文方法对粗语料进行预处理后,采用第1.3节所述的TF-IDF和SVD技术对文本集合进行话题提取.图 2(a)为上述时间段内该用户集的前100个博文话题云图.
 | Fig. 2 Word cloud (a) and the frequency curve of hot topic phrases (b) of the user dataset (4.1~4.25,2013)图 2 用户微博话题词云图(a)及高频话题短语词频统计曲线(b) |
进一步地,分析加入50名高关注用户微博语料对用户话题聚类的影响,分别对合并前后的语料进行话题词频统计.实验结果表明:加入名人微博语料后,热门话题出现的频率发生了显著的变化.原随机抽取3 839名用户语料约31万条博文中话题较为分散,而加入高关注用户博文语料后话题聚集度显著提升.分析原因:主要在于普通用户间重叠话题较少,而加入高关注对象的博文后,拥有共同话题的比率大幅提高.图 2(b)为加入50个网络名人语料前后,前500个高频话题词出现的频率对比(粗线为加入前,细线为加入后).
其次,运用本文构建的社群发现模型构建了用户-话题网络,结合用户-用户关注关系、用户-博文评论关系和转发关系形成了一个完整的多模网络.采用本文算法开展社群发现研究,在用户关注关系与话题相似性相等(a=0.5)、关注关系参数b=0.6、转发参数dfwd=0.25、评论参数dcmt=0.5的条件下,分别就不含50名高关注对象和包含50名高关注对象的两个数据集上获得以下结果:
(1) 在未加入高关注用户数据和博文语料前,社群结构高度分散,几乎无法形成有意义的社群结构(如图 3所示).图 3中得到的较大规模社群,是因为该数据集本身包含一个受关注的微博用户(香港TVB音乐总监邓智伟),而大量孤立个体存在于网络中.在包含50名高关注对象的情况下,社群检测结果发生了显著变化,规模化社群发现数与社群成员之间的链接关系强度显著增长.图 4为本文方法检测获得的一个典型的由537个用户组成的社群示例图.该图中,社群当前的话题是{泰坦尼克3D;甄嬛传;平行回忆演唱会},在7个具有高入度(被关注度)的节点中,除用户“1697364500”外,其中7个用户均来自后加入的高关注用户数据.
 | Fig. 3 Graph of clustering result before 50 highly followed users’ data added图 3 不包含50个微博名人时的社群聚类结果 |
 | Fig. 4 A typical community clustered after highly followed users’ data added 图 4 包含50个微博名人时检测的典型社群 |
通过对该实现的分析表明:由于高关注对象的加入,不仅显著提升了博文话题聚焦度,同时也因为关注关系拉近了用户之间的关系,相关的转发与评论的博文显著增加.所有这些都有效提升了用户之间的相似度,从而对社群的发现发挥了显著的提升作用.
(2) 把由优势集聚类DS-Cluster算法发现的类团转化为用户话题重叠社群后,分析各个社群中话题和用户的重合率.所采用的数据为加入50名高关注用户的数据集,过程中忽略了一些小型社群.实验结果表明,重叠社群在用户规模上同样服从幂率分布.即大规模社群仅占全部社群的极少数,但具有较集中的公共话题集;而小规模社群占绝大多数,且话题相对分散.图 5(a)为所发现的前30个社群包含的用户数.
 | Fig. 5图 5 |
(3) 依据第3节的社群全局隶属度表示模型,本文将全部3 889个用户依据其相对于前30个社群的隶属度形成3889x30的隶属矩阵.然后,依次统计每个用户对全部社群的隶属度累计值.统计结果表明:依据第3节的社群隶属表示模型,个体对社群隶属度(可以认为是参与度)同样符合幂率分布(如图 5(b)所示).即少量个体的社群参与度总值较大(0.5~1.0之间),而大部分个体的隶属度较小(d<0.2).图 5(b)中横坐标表示按降序排列的用户编号,纵坐标为其社群全局隶属度和值,横坐标上位于51处出现隶属值突变的原因是由用户样本本身造成的(前50个用户是其余用户的高关注对象,他们在社群形成中比其余用户发挥了更大的作用).
综上所述,本文通过系统采集和分析微博实验数据,并综合运用所提出的模型与分析方法,全面验证了所提模型与算法的有效性.实验结果能够真实反映微博数据所包含的重叠社群,并能够对实验结果进行合理的解释. 5 结论与展望
微博社会网络是新兴的覆盖海量用户、涉及广泛话题并具有高度动态性的复杂网络.本文以微博社会网络为研究对象,针对多模社会网络重叠社群发现问题展开相关工作,提出了以用户-话题关系为主要划分原则的多模网络重叠社群关系表达模型及相应的社群结构发现算法.该方法不仅考虑网络中的用户-话题关系,还融合了网络特有的关注关系、博文转发与评论关系所形成的复合网络关系.本文同时改进了传统的社群隶属矩阵表述模型,通过引入虚拟社群,使隶属矩阵不仅合理反映个体对社群的隶属度,还标识了个体在社群中的核心度.后续研究工作将拓展到基于本文方法和表示模型的社群演化定量研究等领域.
| [1] | Java A, Song XD, Finin T, Tseng B. Why we Twitter: An analysis of a microblogging community. In: Zhang H, et al., eds. Proc. of the WebKDD/ SNA-KDD. LNCS 5439, Berlin, Heidelberg: Springer-Verlag, 2009. 118-138 . |
| [2] | Kivran-Swaine F, Govindan P, Naaman M. The impact of network structure on breaking ties in online social networks: Unfollowing on Twitter. In: Desney ST, ed. Proc. of the Annual Conf. on Human Factors in Computing Systems. New York: ACM Press, 2011. 1101-1104 . |
| [3] | Zhang Y, Wu Y, Yang Q. Community discovery in Twitter based on user interests. Journal of Computational Information Systems, 2012,8(3):991-1000. |
| [4] | Tang L, Liu H, Zhang JP. Identifying evolving groups in dynamic multimode networks. IEEE Trans. on Knowledge and Data Engineering, 2012,24(1):72-85 . |
| [5] | Yu LB, Ding C. Network community discovery: Solving modularity clustering via normalized cut. In: Brefeld U, ed. Proc. of the 8th Workshop on Mining and Learning with Graphs. New York: ACM Press, 2010. 34-36 . |
| [6] | Huberman BA, Romero DM, Wu F. Social networks that matter: Twitter under the microscope. ArXiv e-prints.http://arxiv.org/abs/0812.1045 . |
| [7] | Gao Q, Qu Q, Zhang XH. Mining social relationships in micro-blogging systems. In: Ant OA, Panayiotis Z, eds. Book: Online Communities and Social Computing. Berlin, Heidelberg: Springer-Verlag, 2011. 110-119 . |
| [8] | Palla G, Derienyi I, Farkas I, Vicsek T. Uncovering the overlapping community structure of complex networks in nature and society. Nature, 2005,435(7043):814-818 . |
| [9] | Blondel VD, Guillaume JL, Lambiotte R, Lefebvre E. Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008,10:10008 . |
| [10] | Gregory S. Finding overlapping communities in networks by label propagation. New Journal of Physics, 2010,12(10):103018 . |
| [11] | Wang XF, Tang L, Gao HJ, Liu H. Discovering overlapping groups in social media. In: Geoffrey I, ed. Proc. of the 10th IEEE Int’l Conf. on Data Mining. IEEE Computer Society, 2010. 569-578 . |
| [12] | Lancichinetti A, Radicchi F, Ramasco J. Finding statistically significant communities in networks. PLoS One, 2011,6(4):e18961 . |
| [13] | Gruzd A, Wellman B, Takhteyev YJ, Fortunate S. Imagining Twitter as an imagined community. American Behavioral Scientist, 2011,55(10): 1294-1318 . |
| [14] | Hazlewood WR, Makice K, Ryan W. Twitterspace: A co-developed display using Twitter to enhance community awareness. In: Simonsen J, ed. Proc. of the Participatory Design Conf. The Trustees of Indiana University, 2008.230-234 . |
| [15] | Meeder B, Karrer B, Sayedi A, Ravi R, Borgs C, Chayes J. We know who you followed last summer: Inferring social link creation times in Twitter. In: Sadagopan S, ed. Proc. of the 20th Int’l Conf. on World Wide Web. New York: ACM Press, 2011. 517-526 . |
| [16] | Lin C, Lin C, Li JX, Wang DD, Chen Y, Li T. Generating event storylines from microblogs. In: Chen XW, ed. Proc. of the 21st ACM inter. Conf. on Information and knowledge management. Maui. ACM Press, 2012.175-184 . |
| [17] | Lin C, Lin C, Lin ZY, Quan Z. Hybrid pseudo relevance feedback for microblog retrieval. Journal of Information Science, 2013, 39(6):773-788. |
| [18] | Yuan Y, Yang CM. Empirical analysis of all kinds of social networks and their relationships formed by information communication among microblog users. Library and Information Service, 2011,55(12):11-25 (in Chinese with English abstract). |
| [19] | Teutle ARM. Twitter: Network properties analysis. In: Palomares RA, ed. Proc. of the Int’l Conf. on 20th Electronics, Communications and Computer. Cholula: IEEE, 2010.180-186 . |
| [20] | Gupta M, Gao J, Sun YZ, Han JW. Integrating community matching and outlier detection for mining evolutionary community outliers. In: Yang Q, ed. Proc. of the 18th ACM SIGKDD Int’l Conf. on Knowledge Discovery & Data Mining. New York: ACM Press, 2012. 859-867 . |
| [21] | Jakobsson M, Rosenberg NA. CLUMPP: A cluster matching and permutation program for dealing with label switching and multimodality in analysis of population structure. Bioinformatics, 2007,23(14):1801-1806 . |
| [22] | Salton G, Buckley C. Term-Weighting approaches in automatic text retrieval. Information Processing & Management, 1988,24(5): 513-523 . |
| [23] | Blei DM, Ng AY, Jordan MI. Latent dirichlet allocation. Journal of Machine Learning Research, 2003,3:993-1022 . |
| [24] | Adar E, Teevan J, Dumais ST. Large scale analysis of Web revisitation patterns. In: Czerwinski M, ed. Proc. of the ACM Conf. on Human Factors in Computing Systems (CHI 2008). Florence: ACM Press, 2008. 1197-1206 . |
| [25] | Pavan M, Pelillo M. Dominant sets and hierarchical clustering. In: Proc. of the 9th IEEE Int’l Conf. on Computer Vision. Nice: IEEE, 2003. 362-369 . |
| [26] | Pavan M, Pelillo M. Dominant sets and pairwise clustering. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2007,29(1): 167-172 . |
| [27] | http://www.datatang.com/data/45081 |
| [18] | 袁毅,杨成明.微博客用户信息交流过程中形成的不同社会网络及其关系实证研究.图书情报工作,2011,55(12):11-25. |