 2014, Vol. 25
2014, Vol. 25



2. 江苏省计算机网络重点实验室, 江苏 南京 210096
2. Jiangsu Provincial Key Laboratory of Computer Network Technology, Nanjing 210096, China
往返时延(round-trip time,简称RTT)是刻画网络性能的一项重要指标,传统的RTT可以被定义为一个报文发送时戳与收到这个报文对应的应答报文时戳的间隔.一个RTT的值,是对特定的两个IP地址之间的传输性能的重要衡量标准之一.
对于网络管理,周期性的RTT测量可为网络管理员提供网络的整体性能视图.例如:一个ISP在评估自己的服务质量时,需要了解与其他ISP的时延情况;对于分布在各地的企业网,需要测量它们之间的网络延迟来评估业务的运行状况;对于一个大型的网络内容提供商(ICP),管理人员需要监测各地区访问这个网站的RTT以评估服务质量.
RTT的估计是一个经典问题,已有大量的相关研究,大体上可分为基于主动测量或基于被动测量两类方法.
对于主动测量,最常见的是使用发送ICMP回显请求和收到ICMP回显应答的间隔[1],或者是发出TCP SYN报文与收到TCP SYN-ACK报文的间隔作为对RTT的估计.主动测量方法能达到很高的精度,但是测量只能在端系统中进行,而目前的网络管理一般的测量环境在中间的网络上.更进一步地,随着网络安全问题的日益突显,对于非协作的对端网络管理者,很可能会将这种周期性的测量流量视为恶意流量而予以过滤,使测量不能正常进行.
被动测量基于对实际流量的观测,经典的方法有SA算法和SS算法[2].SA算法通过TCP请求连接时,访问端(caller)向被访问端(callee)发送的最后一个SYN报文与第1个ACK报文的间隔对RTT进行估计;而SS算法的基本思想是,认为第1轮(burst)TCP报文与第2轮的间隔可以近似地等于这个TCP连接的RTT,文献[3]也使用了类似的思想.Zhang等人[4]提出一种非统计的RTT估计方法:他们生成一系列候选的IP间RTT值,然后用最符合当前TCP会话行为的候选值来估计真正的RTT.Jaiswal等人[5]先计算出拥塞窗口(cwnd),再根据拥塞窗口找出发送端发出的触发接收端发送ACK报文的特定报文,而它们之间的间隔即为RTT的估计值.张佚博等人[6]提出的PRE算法根据在同一轮次的报文间隔与轮次间的报文间隔显著不同这一特点来区分两种不同的间隔,进而得出RTT的估计值.上述几种被动测量方法都是基于全报文的,在大型高速网络中,采集全报文进行分析需要特殊的解决方案,这些方案需要专用设备的支持.同时,采集到的数据必须通过离线分析,不能用于网络性能实时监控.
如今,大多数主流的路由器均提供了采集流记录的机制,如NetFlow[7],sFlow[8]等,也出现了相应的互联网标准IPFIX[9].Strohmeier等人[10]提出基于流记录的RTT测量模型,利用符合一定条件的两条方向相反的流记录的起始时间的间隔作为对RTT的估计,这种方法不允许使用抽样的流记录,而且需要在流记录之间进行流关联,因此缺乏可扩展性和实用性.从精细化网络管理的需要出发,基于实际主干网环境中路由器设备提供的抽样流记录,本文提出了一种RTT测量的新方法.之前有大量的工作对于存在丢包的TCP传输行为进行建模[11, 12],本文借鉴它们的思想,对于每一条符合条件的单向TCP流记录,得出相应的关于RTT的计算模型,从而得到对这条流整个传输过程中的RTT平均值的估计.
图 1所示为一个TCP流的会话过程.本文把TCP传输抽象成3部分:发送端、接收端和中间的网络,而流记录的采集发生在中间的网络中的观测点.在TCP传输期间,发送端发送报文的密度是非均匀的,而接收端发送报文的密度受其影响,也是非均匀的.在有充足数据要发送的情况下,发送端连续发送一簇(burst)n1个报文到接收端,并达到拥塞窗口的最大值后不再发送报文;报文到达后,接收端经过t1时间的处理,发送ACK报文给发送端确认;发送端经过t2时间的处理,发送一簇n2个报文,同时发送端再一次达到拥塞窗口的最大值.以此类推,直至传输完成.如图 1中虚线框所示,本文称TCP每次发送一簇报文并收到相应的ACK的过程为一个轮次.
本文中RTT估计的数据来源于在中间路由器(图 1中的观测点位置)上测量到的TCP(抽样的)流记录,因此,测量只能是对相邻两次发送连续报文的间隔(如图 1中的RTT2)的平均值进行估计,而这与真实的RTT(如图 1中的RTT1)存在一定的差距,这主要是发送端和接收端的处理时间(图 1中的t1,t2)的影响所致.为了提高估计精度,必须使这些时间尽可能地短.
 | Fig. 1 Basic model for RTT estimation 图 1 RTT估计的基本模型 |
TCP的流主要分成两类,那些包含块状数据(如FTP协议、HTTP协议的数据)的流称为TCP块状流,而包含交互数据(如Telnet和Rlogin的数据)的流称为TCP交互流[1].TCP交互流中,t1通常包含系统处理命令(如Telnet),t2通常包含等待用户的键入等时间,这些时间相对于RTT的值不能被忽略;而对于TCP块状流,一旦发送端准备好数据,之后的传输过程一般没有数据处理和人为干预的时间,能很好地避免t1,t2的影响.因此,本文选取TCP块状流作为估计RTT的数据源.
本文估计RTT的基本思想是:TCP块状流传输时,在有数据的情况下,均是以当前的拥塞窗口作为簇长来传输的,因此,图 1中的n1,n2,…,nk即对应了每个轮次中的cwnd大小.令w(r)是关于轮次r的表示cwnd大小的函数,那么,当传输的总报文数为N、传输持续时间为T时,传输过程中的平均RTT为t,总轮次数为T/t,则有:
![]() (1)
(1)
因此,如果可以估计出函数w(r),即可通过解方程(1)来求出平均RTT的估计值t.
本文通过分析TCP块状流的传输特性,分别建立了以下3种情况下的RTT估计模型:
1) 当套接字缓冲区大小相对于带宽延迟积BDP(bandwidth-delay product)较小时;
2) 当套接字缓冲区大小相对于BDP较大时;
3) 当套接字缓冲区大小与BDP相近时.
实验结果表明,在3种不同的情况下,各自的模型都能很好地完成RTT估计.同时,由于在估计当中只使用了流持续时间和总报文两个变量,因此,本方法同样适用于以抽样流记录为输入的环境,能够有效地应用于大规模高速网络的检测与管理.
本文第1节列出关于TCP的几点主要假设.第2节讨论TCP块状流的传输行为.在此基础上,第3节分3种情况分别建立估计RTT的模型,同时讨论抽样对于估计的影响.第4节通过仿真和实测对各种估计模型进行评估.第5节总结本文的工作.
1 关于TCP的主要假设 1.1 关于TCP块状流传输过程的假设基于上述讨论,本文假设在TCP块状流传输过程中,发送端和接收端的处理时间为0.同时,由于TCP块状流的传输机理,簇内的相邻报文的时间差相较于簇间的时间差很小,因此假设同一簇的报文是同时从发送端发出的,且同时到达观测点,并假设每一簇报文从发送端到观测点(流采集点)所耗费的时间基本相同,因此,可以认为在观测点上观测到的簇间的时间差即为RTT.
1.2 忽略TCP接收端影响在网络的协议栈中有两个重要的缓冲区:一个是在内核用于存储数据的“套接字缓冲区(socket buffer)”,一个是应用层用于存储数据的“应用层缓冲区(application buffer)”.当应用程序需要发送数据时,通过调用send(×)函数将应用层缓冲区的数据复制到套接字缓冲区中,再由内核依据拥塞控制策略传输数据.当套接字缓冲区的数据全都发送完后,再从应用层缓冲区继续复制数据至套接字缓冲区,继续发送数据.我们假设发送端的套接字缓冲区长度始终不大于接收端的套接字缓冲区长度.这是一个合理的假设,因为在多数系统中,发送端的套接字缓冲区的默认长度都小于接收端缓冲区(如在Linux 2.6.27中,发送端的套接字缓冲区的长度为16K字节,而接收端的套接字缓冲区长度为85K字节).因此在之后的讨论中,忽略接收端的影响,只考虑发送端.
1.3 流传输过程中丢包率恒定假设网络中,丢包主要包括链路层丢包和路由器队列丢包两种,由于现在的网络设施可靠性有所增加,链路层丢包出现的概率已经很低,可以忽略不计,因此,本文主要讨论的是传输经过的路由器中队列的丢包,这种丢包主要是由于传输的数据压力超过了传输路径中的某个路由器的处理能力造成的.宏观来说,这种丢包情况与传输压力存在一定的相关性,传输压力大时,丢包情况增多,相应的丢包率增大;反之,丢包率减小.正常情况下,网络中的数据传输压力在小时间粒度上,例如分钟级,是基本稳定的.因此,可以假设在这样的时间粒度上丢包率也是基本稳定的.进一步地,假设在一条流的传输时间内,丢包是一个强度(intensity)恒定的泊松过程(Poisson process),这个假设在文献[13]中同样用到,此时,丢包发生的次数即假设为这个过程在传输时间的期望值.
1.4 流传输过程中RTT恒定假设RTT在流传输中具有波动性,但在宏观的网络性能监测中,观测这种波动意义很有限,与测量这种波动性所需花费的代价不成比例.事实上,由于流传输的时间相对较短,在这么短的时间内,网络性能反映在RTT上的差异较小,波动性的主要成因是端系统的处理时间,通过上一节的分析,用于本文测量的流记录的端系统处理时间很短,因此,RTT在流传输中的波动性不大.
综上,在测量中,本文关注的是在流传输过程中的RTT的平均值.为了建模方便,本文假设在一条流的传输过程中RTT是恒定的,而这个RTT就是本文需要估计的测度.
2 丢包和带宽延迟积BDP对TCP块状流传输的影响由于假设中忽略了接受端的影响,因此本文主要对发送端进行讨论.令发送端的套接字缓冲区大小为B字节,则对应的报文数W为
![]() (2)
(2)
其中,MSS为最大段长(maximum segment size).
图 2所示的是TCP传输过程中,两种情况下发生丢包时拥塞窗口变化的典型曲线.拥塞窗口长度(方便起见,本文中的拥塞窗口大小用报文个数来描述)反映的是没有收到任何应答情况下能传输的最大的报文个数.传输开始时,首先是慢启动阶段,拥塞窗口呈指数增长.当发生丢包时,拥塞窗口下降一定的比例,同时进入拥塞避免阶段,并按照AIMD的策略,若无丢包,则待当前的报文全部被确认后,窗口长度增加一个常数;若有丢包发生,则窗口立即下降一定的比例.但是cwnd的增长会受到W的限制,当cwnd到达了W后,如果不发生丢包,则会保持在W,直到发送丢包降低一定比例为止(如图 2(b)所示).
 | Fig. 2 Typical window curve for TCP with packet loss when cwnd is less than W and equal to W图 2 当拥塞窗口小于W和等于W时发生丢包,TCP拥塞窗口变化曲线 |
实际的TCP传输行为与带宽延迟积BDP有关.当套接字缓冲区大小(W)相对于BDP较大时,可以认为TCP传输中拥塞窗口总是小于套接字缓冲区大小,因此几乎不会受到套接字缓冲区大小的限制,即,传输行为如图 2(a)所示.
而当套接字缓冲区大小相对于BDP较小时,拥塞窗口将会很容易达到套接字缓冲区大小(W),并保持这个大小,直到丢包发生.当出现丢包后,拥塞窗口下降一定比例.但是由于BDP很大,拥塞窗口又迅速地恢复到原来的大小,如图 2(b)所示.
最后,当套接字缓冲区大小与BDP相近时,则图 2(a)和图 2(b)所示两种情况均有可能出现.
3 RTT的估计模型本文分3种情况来讨论相应的RTT的估计:(1) 当套接字缓冲区大小相对于BDP较小时;(2) 当套接字缓冲区大小相对于BDP较大时;(3) 当套接字缓冲区大小与BDP相近时.
3.1 当W相对于BDP较小时因W较小,连续发送的报文数相应较少,更不易形成突发拥塞.因此可以假设,在慢启动阶段直至cwnd增长为W之前不存在丢包;同时,每次丢包的恢复阶段直至cwnd增长为W之前不会发生新的丢包,直至cwnd恢复到W.
由于丢包率稳定这一假设,可令一个TCP连接的传输过程中稳定的丢包率为p;同时,总报文数为N,则可以估计出丢包数Nloss:
Nloss=Np (3)
图 3是当W相对于BDP较小时,TCP传输过程中cwnd变换的示意图(图中,横轴的单位为轮次),图中实线以下的面积为传输过程中的总报文数,而SSS和SCA分别对应于慢启动区域(图 3中SSS所在的阴影区域)和丢包区域(图 3中SCA所在的阴影区域)的面积.当发生了Nloss次丢包时,则共会出现Nloss个面积为SCA的区域.由此,以W为长、以传输持续时间T为宽的长方形总面积可以表示为
![]() (4)
(4)
 | Fig. 3 Sketching RTT estimation when W is small compared with BDP图 3 当W相对于BDP较小时RTT估计示意 |
在慢启动阶段,第r(相对于慢启动阶段的开始时的轮次)轮次的拥塞窗口大小wSS为
wSS(r)=2r (5)
又,wSS(RSS)等于W,则慢启动的总轮次RSS为
RSS=log2W (6)
则SSS的计算如下:
![]() (7)
(7)
在拥塞避免阶段中,每隔一个RTT时间,拥塞窗口增加一个常数k(如1[14]),则第r(相对于当前的拥塞避免阶段的开始时的轮次)轮次的拥塞窗口wCA(r)为
wCA(r)=aW+kr (8)
其中,a表示发现丢包后,拥塞窗口调整后的值与原值的比.
由于wCA(RCA)等于W,则拥塞避免阶段经历的总轮次为
![]() (9)
(9)
则SCA的计算如下:
![]() (10)
(10)
最终,综合上述各式可得RTT的估计值t:
![]() (11)
(11)
其中,W为发送端Socket缓冲区大小,T为流持续时间,N为总报文数,p为丢包率,a,k为TCP具体拥塞控制策略中的相关常量.
3.2 当W相对于BDP较大时当W相对于BDP较大时,传输有两个阶段:慢启动阶段直至发送第1次丢包以及之后的拥塞避免阶段(如图 2(a)所示).慢启动阶段的模型和上一节一致,但是拥塞避免阶段的模型却较为复杂,因为拥塞窗口将随着丢包的发生而变化,虽然丢包率是恒定的,但是丢包的发生是随机的,因此可使用随机过程进行建模.
令丢包是一个强度(intensity)为l的泊松过程(Poisson process):{L(t)},则在总传输时间为T、总报文数为N、丢包率为p的TCP传输中,假设丢包数为L(t=T)的期望值,则有:
E(L(T))=lT=Np (12)
即:
![]() (13)
(13)
定义随机过程{Xn},表示第n次丢包前瞬间拥塞窗口的大小.令b为在拥塞避免阶段中,每隔一个RTT时间,拥塞窗口增加的常数与RTT的比值(k/t),则有:
![]() (14)
(14)
其中,Sn为第n次丢包与第n+1次丢包的时间间隔.根据文献[15]中的定理2.1,有Sn(n=1,2,3,…)是i.i.d.的;同时,服从于参数为l的指数分布.
文献[16]对形如:
Yn+1=AnYn+Bn (15)
的随机等式进行了深入的讨论,其中,文中定理1为:当{An},{Bn}是平稳的(stationary)、遍历的(ergodic)随机过程,同时满足条件(其中,(×)+表示取max(×,0)):
-¥≤Elog|A0|<0 and E(log|B0|)+<¥,
或者满足条件:
P(A0=0)>0,
则公式(15)存在唯一稳定解(stationary solution):
![]()
即下式成立:
![]()
对于公式(14),{An=a},{Bn=bSn},假设RTT恒定,a(0<a<1)、b是常数,而{Sn}是i.i.d的,显然有{An},{Bn}是平稳的、遍历的随机过程,且Elog|A0|=loga<0,E(log|B0|)+=(logbl)+<¥,因此,存在一个稳定解xn:
![]() (16)
(16)
使得:
![]() (17)
(17)
对于xn的期望计算如下:
![]() (18)
(18)
由于当n足够大时,Xn会收敛到xn,因此当n足够大时,可以用xn的期望去估计Xn的期望.如图 4所示,使用图中的虚线来估计图中的实线表示的真实情况.
 | Fig. 4 Sketching RTT estimation when W is larger compared with BDP图 4 当W相对于BDP较大时RTT估计示意 |
虚线部分包含两个阶段:慢启动阶段和稳定阶段.与上一小节类似,慢启动经历的总轮次数为
R¢SS=log2E (19)
则慢启动阶段发送的报文数NSS为
![]() (20)
(20)
稳定阶段时,可以计算出平均传输速率为
![]() (21)
(21)
其中,b=k/t.
稳定阶段发送的报文数NS为
![]() (22)
(22)
其中,T为传输总时间.
对于总报文数为N的TCP传输,有:
![]() (23)
(23)
将l=Np/T,b=k/t带入公式(23),则可转化为关于RTT的估计值t的方程,即可求得对RTT的估计.
由于上式较为复杂,在实际测量中,当用于计算的流记录的总报文数足够多时,可以忽略图 4所示的慢启动阶段以达到简化的目的.此时,公式(23)可转化为
![]() (24)
(24)
则RTT的估计值t为
![]() (25)
(25)
其中,T为流持续时间,N为总报文数,p为丢包率,a,k为拥塞控制策略中的相关常量.
3.3 当W与BDP相近时当W与BDP相近时,cwnd的增长将有可能达到W从而停止增长,因此有:
![]() (26)
(26)
其中,运算min(x,y)表示取x,y中较小的一个值,其他变量的定义如上一小节.又因为Xn的取值范围为[0,W],则有:
![]() (27)
(27)
考虑随机过程{Yn}定义如下:
![]() (28)
(28)
易知,随机等式(28)右边的后半部分同样是i.i.d.的,并且期望的对数小于正无穷,因此同样满足文献[16]中的定理1的条件,从而有唯一的稳定解yn:
![]() (29)
(29)
满足:当n趋向于正无穷时,yn等于Yn的概率为1.
显然,若X0=Y0,对于任意的自然数n,有Yn≤Xn,则:
![]() (30)
(30)
又,对于任意的n,Sn为参数为l的指数分布,因此,
![]() (31)
(31)
因此有:
![]() (32)
(32)
同理,对于{Zn}:
![]() (33)
(33)
进行同样的分析,可得:
![]() (34)
(34)
又,当忽略慢启动阶段时,有:
![]() ,
,
则可得到不等式:
![]() (35)
(35)
考察函数f(x):
![]() (36)
(36)
其中,a>0,b>0,x>0.f(x)的导数为
![]() (37)
(37)
考虑函数g(x)=2eax-ax-2,g(x)的导数为g¢(x)=2aeax-a,当x≥0且a>0时,则有g¢(x)>0.因此,当x>0且a>0时,有:g(x)>g(0)=0,即ax+2-2eax<0,即f¢(x)<0.因此,f(x)在x>0上是单调递减函数.
由以上分析可知:对于关于t的不等式方程(35),有且只有一个解:
t1≤t≤t2 (38)
其中,t1,t2可以通过如下两个方程求得:
 (39)
(39)
其中,W为发送端Socket缓冲区大小,T为流持续时间,N为总报文数,p为丢包率,a,k为拥塞控制策略中的相关常量.
3.4 抽样下的讨论上述3种情况下的RTT估计只是涉及到一个TCP流的持续时间T与总报文数N两个变量,在抽样环境中,关于已知抽样后的报文数NS,获得实际传输中的报文数N可以通过如下方法[17, 18]来估计:
对于一个流记录,令X表示原始报文数,Y表示抽样后的报文数,假设对于每个报文,被抽到的事件相互独立,且概率为一个定值(抽样比s),则Px=P(X=x|Y=NS)的计算如下所示:
 (40)
(40)
研究表明[17],网络中的流服从重尾分布,故使用Pareto分布来估计原始流长的分布,并且使用参数为1的Pareto分布来估计未知原始流分布中的流长分布[18],即b=1,且Xmin为NS,则有:
 (41)
(41)
则原始的报文数N的估计为
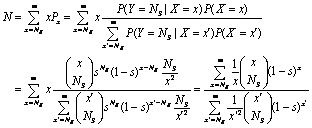 (42)
(42)
其中,s为抽样比,NS为抽样后的报文数.虽然上式中分子和分母的展开式有无穷多项,但是由于越往后的项值越小,因此可以根据精度要求计算前几项.而若知道抽样后的持续时间TS,则可用TS粗略地估计原始持续时间T.
通过以上讨论可知,本节讨论的各种方法在抽样环境中仍然可以使用.
4 模型评估 4.1 仿真评估本文使用ns-2[19]进行仿真实验,采用的TCP版本是TCP NewReno[20],此时,a为0.5,k为1.分别对第3节中的3种情况进行仿真,每种参数下采用多次(50次)实验取平均的方法,以提高实验结果的可信度.
4.1.1 当W相对于BDP较小时的仿真图 5是ns-2的仿真结果,仿真的基本参数:MSS为1 024,带宽为1Gb/s,传输持续时间为200s,RTT为200ms, TCP窗口(模拟套接字缓冲区大小)为100个报文,丢包率为0.01%.
 | Fig. 5 Simulation result when W is small compared with BDP图 5 当W相对于BDP较小时的仿真结果 |
由于ns-2中的带宽仅在计算延迟时才使用,并不影响TCP传输,因此在仿真中,使用丢包率来模拟真实情况下的BDP.这是因为,在真实传输中,当BDP较小时,必然丢包率较大;反之也成立.实验中,使用公式(11)对RTT进行估计.
图 5(a)为改变传输时间进行仿真时,传输时间与估计结果的关系.可以发现,传输时间对估计结果影响不大.图 5(b)为改变丢包率进行仿真时,丢包率与估计结果的关系.可以发现:随着丢包率的增大,估计的结果越来越差.这是因为当丢包率过大时,假设“每次丢包的恢复阶段直至cwnd增长为W之前不会发生新的丢包”在大部分情况下不再成立,此时,真实的Sloss比公式(4)中估计的NlossxSCA要小很多,故导致RTT估计值偏小.图 5(c)为改变TCP窗口进行仿真时,TCP窗口与估计结果的关系.可以发现:随着TCP窗口的增大,估计的结果越来越差.与图 5(b)的情况类似,当TCP窗口,即套接字缓冲区大小增大时,假设在大部分情况下不再成立,此时,真实的Sloss比公式(4)中估计的NlossxSCA要小很多,故导致RTT估计值偏小.图 5(d)为改变真实的RTT进行仿真时,真实的RTT与估计结果的关系.可以发现:真实的RTT对估计结果影响不大.
从以上结果可知:当丢包率较小,同时,套接字缓冲区大小较小时,估计结果较为准确,这正符合W相对于BDP较小时的情形.
4.1.2 当W相对于BDP较大时的仿真图 6是ns-2的仿真结果,仿真的基本参数:MSS为1 024,带宽为1Gb/s,传输持续时间为200s,RTT为200ms, TCP窗口(模拟套接字缓冲区大小)为1 000个报文,丢包率为1%.实验中,使用公式(25)对RTT进行估计.
 | Fig. 6 Simulation result when W is large compared with BDP图 6 当W相对于BDP较大时的仿真结果 |
图 6(a)为改变传输时间进行仿真时,传输时间与估计结果的关系.可以发现:传输时间较小时,估计结果不理想.这是因为估计时忽略了慢启动过程,当传输时间较短时,将会带来较大的误差.同时,根据第3.2节中的讨论,必须在n较大,即传输时间较长的情况下,才能用E(xn)去估计E(Xn),因此导致结果误差较大;而当传输时间较大时(>20s),传输时间对估计结果影响不大.图 6(b)为改变丢包率进行仿真时,丢包率与估计结果的关系.可以发现:随着丢包率的增大,估计的结果越来越好.这是因为,当丢包率较小时,发生丢包的次数较少,而使用公式(25)对RTT进行估计,是建立在随机过程的模型上的,因此估计结果变化剧烈.图 6(c)为改变TCP窗口进行仿真时,TCP窗口与估计结果的关系.可以看到:当TCP窗口较小时,估计的结果较差.这是因为,当TCP窗口较小时,cwnd的增长迅速地达到了TCP窗口,此时,cwnd不再增长;而在估计中假设不会出现这种情况,因此导致估计的平均传输速率v偏大.根据公式(24),导致RTT的估计值偏大.图 6(d)为改变真实的RTT进行仿真时,真实的RTT与估计结果的关系.可以发现,真实的RTT对估计结果影响不大.
从以上结果可知:当丢包率较大,并且套接字缓冲区大小较大时,估计结果较为准确.这正符合W相对于BDP较大时的情形.同时,如果传输时间较短,不可忽略慢启动的影响,并且在丢包率特别低的情况下估计效果不好.但也应注意到,实际传输中几乎不会存在BDP较小、同时丢包率也较小的情况.因此,这种方法在实际情况下能得到较好的结果.
图 7为一个典型情况的示意,可以发现:虽然在单一时间点上误差较大,但是总体来看,误差很小.
 | Fig. 7 Sketching simulation when W is large compared with BDP图 7 W相对于BDP较大时的仿真示意 |
取仿真的基本参数:MSS为1 024,带宽为1Gb/s,传输持续时间为200s,RTT为200ms,TCP窗口(模拟套接字缓冲区大小)为50个报文进行仿真,变化丢包率从0.02%~1%,共50组.其中,不等式方程(38)是通过牛顿迭代法(Newton’s method)[21]来计算的,结果精确到1ms.最终结果如图 8所示.
 | Fig. 8 Simulation result when W is comparable to BDP图 8 当W与BDP相近时的仿真结果 |
由图 8可知:当丢包率较小时,通过公式(25)计算的RTT明显偏大,但是通过公式(38)计算的RTT区间仍能有效地估计RTT;而当丢包率增大后,公式(38)计算的RTT区间与公式(25)计算的RTT趋于一致.
4.1.4 对于抽样的仿真取仿真的基本参数:MSS为1 024,带宽为1Gb/s,丢包率为0.5%,RTT为200ms,TCP窗口(模拟套接字缓冲区大小)为1 000个报文进行仿真,变化传输持续时间从20s~1000s,共50组.分别采用抽样比1,1/4,1/16,1/64,1/256进行结果对比,如图 9所示.
 | Fig. 9 Simulation result for sampled flow data图 9 对抽样流的仿真结果 |
从图中可以看出:随着传输时间的增长,抽样后的结果与未抽样的结果越来越接近.因此,对于传输时间较长的抽样流记录,本文方法的精度同样较高.
4.2 实测数据评估由第4.1节可以看出:在仿真实验中,第3节提出的模型能够很好地估计RTT.为了进一步测试估计效果,本文使用实际数据估计,并使用SA算法[2]和文献[6]提出的PRE算法作为对比数据.
实验用来自于IPTAS系统[22]采集的两个CERNET节点间3个小时的实际trace组成的流,并且筛选出源主机运行Window系统(TCP版本为TCP NewReno)的、源端口为80(HTTP)和20(FTP数据)的TCP流.同时,使用一个流中的报文的TCP序列号的错序次数来估计这个流传输过程中的丢包数,进而计算丢包率.为了简化实验,当丢包率较小时,采用第3.1节中的方法估计RTT;而当丢包率较大时,采用第3.2节中的方法估计RTT.
为方便统计与结果对比,本文将流长(流内报文数)以100为间隔分组,第i个区间的流长范围为[100x(i-1), 100xi].注意到:对于PRE算法,在流长较小的情况下不能计算;同时,在采集到的数据中,当流长大于2 500时,每组的流数较小(小于100),结果意义不大.因此,只筛选出流长大于10且小于2 500的流,分为25个流长区间(第1个区间的范围为[10,100]).在这个trace中,符合条件的有96 190个流.具体分布如图 10所示.
 | Fig. 10 Flow length distribution图 10 流长分布 |
为了测试抽样对本文提出算法的影响,我们使用抽样比分别为1(未抽样),1/4,1/16,1/64的流记录来计算RTT估计值.由于SA算法和PRE算法均不支持抽样,所以采用这些抽样的流记录对应的未抽样的流记录中的报文序列作为这两种算法的输入,计算对比数据.注意:在抽样情况下,数据分组的标准仍然是原始的流长而不是抽样后的流长.
由于每一组中的计算结果是对不同主机间的RTT的估计结果,而基于统计的误差分析是对同一实验的多次实验结果进行分析,因此在这里并不适用.为了衡量本文提出的算法与SA算法和PRE算法的结果的差异性,使用余弦相似性(cosine similarity)[23]进行计算,取值从-1到1,越接近1,代表两组数据越相似.对于两组数据A={ai}n,B={bi}n.它们的余弦相似性Scos的定义为
 (43)
(43)
图 11所示的是在4种抽样比下,将所有流按上述的流长区间分组,并分别计算各分组内的估计结果与SA算法和PRE算法的余弦相似性的结果.
 | Fig. 11 Experiment results of real flow data图 11 实际数据的实验结果 |
可以发现:随着流长越来越长,估计的效果也越来越好.但是随着抽样比的增大,结果的波动性也在增大.这主要是由于在抽样比较大的情况下,对于流长估计的偏差比较大引起的.但是通过第3.4节的讨论可知,估计结果的期望并不会受到抽样的影响.因此,如果能在一定时间内对特定主机间的足够多的抽样流记录进行估计,并对结果取平均值,可以有效地消除高抽样比带来的结果的波动性.为了更进一步地证明这个结论,本文在上述条件相同的情况下,分别对3小时、6小时和9小时的trace进行1/64抽样的实验,结果只采用PRE算法进行对比,结果如图 12所示.可以发现:当数据增加后,确实能够有效地降低估计结果的波动性.
 | Fig. 12 The influence of the amount of data on estimation result图 12 数据的数量对估计结果的影响 |
往返时延是刻画网络性能的一项重要指标.一个RTT的值是对特定两个IP地址之间的传输性能的重要衡量标准之一.传统的RTT测量方法不是基于全报文的就是基于未抽样的流记录,随着网络的规模越来越大,对于大规模主干网环境下,即使采集未抽样的流记录也变得越来越困难.
为了适应大规模主干网环境下的RTT测量,本文提出一种基于抽样流记录的RTT测量方法,通过对AIMD型的TCP块状流的传输特性进行分析,分别建立了以下3种情况下的RTT估计模型:(1) 当套接字缓冲区大小相对于BDP较小时;(2) 当套接字缓冲区大小相对于BDP较大时;(3) 当套接字缓冲区大小与BDP相近时.
实验结果表明:在3种不同的情况下,各自的模型都能较好地完成RTT估计.在带宽较大、丢包率较低的情况下,使用第3.1节中的方法进行计算RTT更精确;而在带宽较小、丢包率较高的情况下,使用第3.2节中的方法计算RTT更精确;当链路情况介于两者之间时,可以使用第3.3节介绍的方法来估计出RTT区间.由于在估计当中只使用了流持续时间和总报文两个变量,因此,本方法同样适用于以抽样流记录为输入的环境.
在实际网络测量中,TCP块状流的发送端通常是服务器(Web服务器或FTP服务器),所以套接字缓冲区大小几乎不变;同时,主机间的网络状态也相对固定,因此一旦确定了测量目的,通过一次性收集相关的参数,即可判断出适用每个端系统对的计算模型,很少情况下会由于套接字缓冲区大小与BDP的对比发生改变而需要对模型进行更换.另一方面,虽然由于只有块状流记录能作为测量的源数据可能会导致测量需求中的某些主机不能被测量到,但是分别与要测量的两个主机在相似的网络拓扑结构(如分别在相同子网中)的两个主机间的测量所得数据,能在一定程度上代表未被测量到的主机的网络性能.本文所设计的RTT测量方法适用于在主干网中对网际的时延进行持续地观测,以满足网络运行管理系统日常网络服务质量监测的需要.它可以替代传统的使用大规模主动测量平台的方法,避免周期性主动测量的开销.在进行性能诊断时,本文方法与传统的主动性能测量方法构成互补,网络管理人员可以在这种宏观测量的基础上进行有针对性的主动测量来获得进一步的诊断信息.
通过分析仿真数据和实际数据进行实验可以发现:无论输入数据是未抽样的流记录还是抽样的流记录,估计的准确性均随着流长的增长而有所提高.但是,随着抽样比的增大,结果的波动性也增大.抽样并不会影响结果的期望,故当有足够多的数据时,就可以在高抽样比的情况下估计RTT.因此,在有大量数据的大规模骨干网络情况下,本文提出的方法在抽样的环境中可以具有很好的实用性.
| [1] | Stevens WR. TCP/IP Illustrated, Vol.1: The Protocol. Reading: Addison Wesley, 1993. |
| [2] | Jiang H, Dovrolis C. Passive estimation of TCP round-trip Times. In: Proc. of the SIGCOMM 2002. 2002. 75-88 . |
| [3] | Veal B, Li K, Lowenthal D. New methods for passive estimation of TCP round-trip times. In: Proc. of the PAM 2005. 2005. 121-134 . |
| [4] | Zhang Y, Breslau L, Paxson V, Shenker S. On the characteristics and origins of Internet flow rates. In: Proc. of the SIGCOMM 2002. 2002. 309-322 . |
| [5] | Jaiswal S, Iannaccone G, Diot C, Kurose J, Towsley D. Inferring TCP connection characteristics through passive measurements. In: Proc. of the INFOCOM 2004. 2004. 1582-1592 . |
| [6] | Zhang YB, Lei ZM. A passive RTT estimate algorithm for TCP. Journal of Beijing University of Posts and Telecommunications, 2004,27(5):85-89 (in Chinese with English abstract) . |
| [7] | Claise B. Cisco systems NetFlow services export version 9. RFC 3954, 2004. |
| [8] | sFlow. http://www.sflow.org/index.php |
| [9] | Claise B. Specification of the IP flow information export (IPFIX) protocol for the exchange of IP traffic flow information. RFC 5101, 2008. |
| [10] | Strohmeier F, Dorfinger P, Trammell B. Network performance evaluation based on flow data. In: Proc. of the IWCMC 2011. 2011.1585-1589 . |
| [11] | Altman E, Avrachenkov K, Barakat C. A stochastic model of TCP/IP with stationary random losses. In: Proc. of the SIGCOMM 2000. 2000.231-242 . |
| [12] | Tomita N, Valaee S. Data uploading time estimation for CUBIC TCP in long distance networks. Computer Networks, 2012,56(11): 2677-2689 . |
| [13] | Bao W, Wong VWS, Leung VCM. A model for steady state throughput of TCP CUBIC. In: Proc. of the Global Telecommuni-cations Conf. (GLOBECOM 2010). 2010.1-6 . |
| [14] | Allman M, Paxson V, Blanton E. TCP congestion control. RFC 5681, 2009. http://tools.ietf.org/html/rfc5681 |
| [15] | Karlin S, Taylor HM. A First Course in Stochastic Processed. 2nd ed., Singapore: Elsevier Pte Ltd., 2007. |
| [16] | Brandt A. The stochastic equation Yn+1=AnYn+Bn with stationary coefficients. In: Advances in Applied Probability. 1986. 211-220. http://www.jstor.org/discover/10.2307/1427243 |
| [17] | Duffield N, Lund C, Thorup M. Estimating flow distributions from sampled flow statistics. In: Proc. of the SIGCOMM 2003. 2003. 325-336 . |
| [18] | Zhang XY, Gong J, Wu H. A method of estimating average round-trip latency based on specific flow records in NetFlow. Computer Applications and Software, 2010,27(5):64-67 (in Chinese with English abstract) . |
| [19] | McCanne S. The network simulator—ns-2. 1997. http://www.isi.edu/nsnam/ns/ |
| [20] | Floyd S, Henderson T, Gurtov A. The NewReno modification to TCP’s fast recovery algorithm. RFC 3782, 2004. http://tools.ietf. org/html/rfc3782 |
| [21] | Wikipedia. Newton’s method. 2013. http://en.wikipedia.org/wiki/Newton%27s_method |
| [22] | Jiangsu Key Laboratory of Computer Networking Technology. IP trace distribution system (IPTAS). 2013. http://iptas.edu.cn/src/system.php |
| [23] | Wikipedia. Cosine similarity. 2013. http://en.wikipedia.org/wiki/Cosine_similarity |
| [6] | 张轶博,雷振明.一种被动式RTT测量算法.北京邮电大学学报,2004,27(5):85-89 . |
| [18] | 张晓宇,龚俭,吴桦.一种基于NetFlow特定流记录的平均往返时延估计方法.计算机应用与软件,2010,27(5):64-67 . |